neuspell
1.0.0
NEUSPELL: une boîte à outils de correction d'orthographe neurale
neuspell est maintenant disponible via PIP . Voir l'installation via PIPBERT de NEUSPELL est désormais disponible dans le cadre des modèles HuggingFace en tant que murali1996/bert-base-cased-spell-correction . Nous fournissons un exemple d'extrait de code sur ./scripts/huggingface pour les praticiens curieux.git clone https://github.com/neuspell/neuspell ; cd neuspell
pip install -e .Pour installer des exigences supplémentaires,
pip install -r extras-requirements.txtou individuellement comme:
pip install -e .[elmo]
pip install -e .[spacy]Remarque: pour Zsh , utilisez ". [Elmo]" et ". [Spacy]" à la place
De plus, spacy models peuvent être téléchargés sous le nom de:
python -m spacy download en_core_web_sm Ensuite, téléchargez des modèles pré-entraînés de neuspell après télécharger des points de contrôle
Voici un extrait de code à démarrage rapide (utilisation de la ligne de commande) pour utiliser un modèle de vérification. Voir test_neuspell_correctors.py pour plus de modèles d'utilisation.
import neuspell
from neuspell import available_checkers , BertChecker
""" see available checkers """
print ( f"available checkers: { neuspell . available_checkers () } " )
# → available checkers: ['BertsclstmChecker', 'CnnlstmChecker', 'NestedlstmChecker', 'SclstmChecker', 'SclstmbertChecker', 'BertChecker', 'SclstmelmoChecker', 'ElmosclstmChecker']
""" select spell checkers & load """
checker = BertChecker ()
checker . from_pretrained ()
""" spell correction """
checker . correct ( "I luk foward to receving your reply" )
# → "I look forward to receiving your reply"
checker . correct_strings ([ "I luk foward to receving your reply" , ])
# → ["I look forward to receiving your reply"]
checker . correct_from_file ( src = "noisy_texts.txt" )
# → "Found 450 mistakes in 322 lines, total_lines=350"
""" evaluation of models """
checker . evaluate ( clean_file = "bea60k.txt" , corrupt_file = "bea60k.noise.txt" )
# → data size: 63044
# → total inference time for this data is: 998.13 secs
# → total token count: 1032061
# → confusion table: corr2corr:940937, corr2incorr:21060,
# incorr2corr:55889, incorr2incorr:14175
# → accuracy is 96.58%
# → word correction rate is 79.76%Alternativement, une fois peut également sélectionner et charger un vérificateur orthographique différemment comme suit:
from neuspell import SclstmChecker
checker = SclstmChecker ()
checker = checker . add_ ( "elmo" , at = "input" ) # "elmo" or "bert", "input" or "output"
checker . from_pretrained ()Cette caractéristique de l'ajout de modèle Elmo ou Bert est actuellement prise en charge pour des modèles sélectionnés. Voir la liste des modèles neuronaux dans la boîte à outils pour plus de détails.
Si vous êtes intéressé, suivez des exigences supplémentaires pour l'installation de vérifications orthographiques non neurales Aspell et Jamspell .
pip install neuspell Dans V1.0, la bibliothèque allennlp n'est pas automatiquement installée qui est utilisée pour les modèles contenant ELMO. Par conséquent, pour utiliser ces dames, effectuez une installation de source comme dans l'installation et le démarrage rapide
Neuspell est une boîte à outils open source pour la correction d'orthographe sensible au contexte en anglais. Cette boîte à outils comprend 10 vérificateurs orthographiques, avec des évaluations sur les dépensations naturelles à partir de plusieurs sources (disponibles publiquement). Pour rendre les modèles neuronaux pour le contexte de vérification des orthographiques dépendants, (i) nous formons des modèles neuronaux en utilisant des erreurs d'orthographe dans le contexte, construites synthétiquement par ingénierie insensée isolée de mauvaise orientation; et (ii) utiliser des représentations plus riches du contexte. Cette boîte à outils permet aux praticiens du PNL d'utiliser nos systèmes de correction d'orthographe proposés et existants, à la fois via une simple ligne de commande unifiée, ainsi qu'une interface Web. Parmi de nombreuses applications potentielles, nous démontrons l'utilité de nos vérificateurs de orthographes dans la lutte contre les fautes d'orthographe contradictoires.
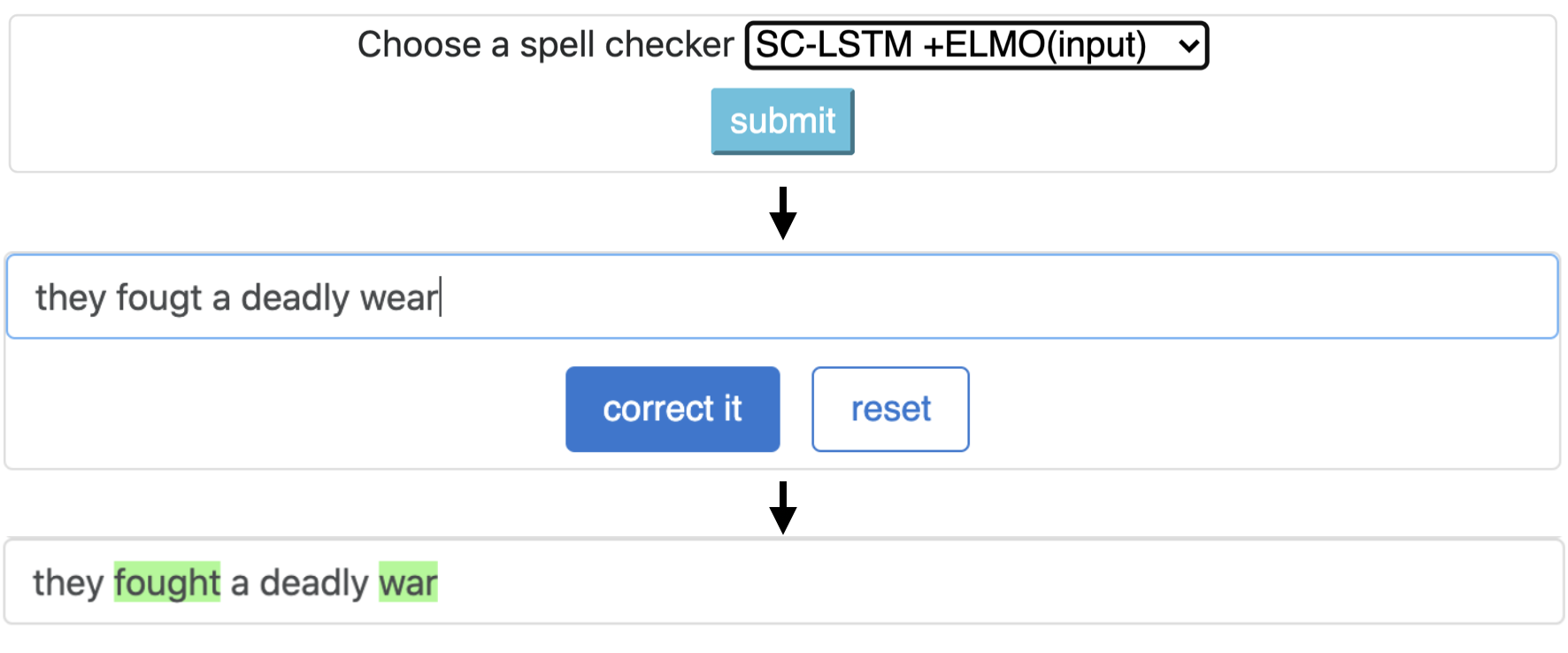
CNN-LSTMSC-LSTMNested-LSTMBERTSC-LSTM plus ELMO (at input)SC-LSTM plus ELMO (at output)SC-LSTM plus BERT (at input)SC-LSTM plus BERT (at output)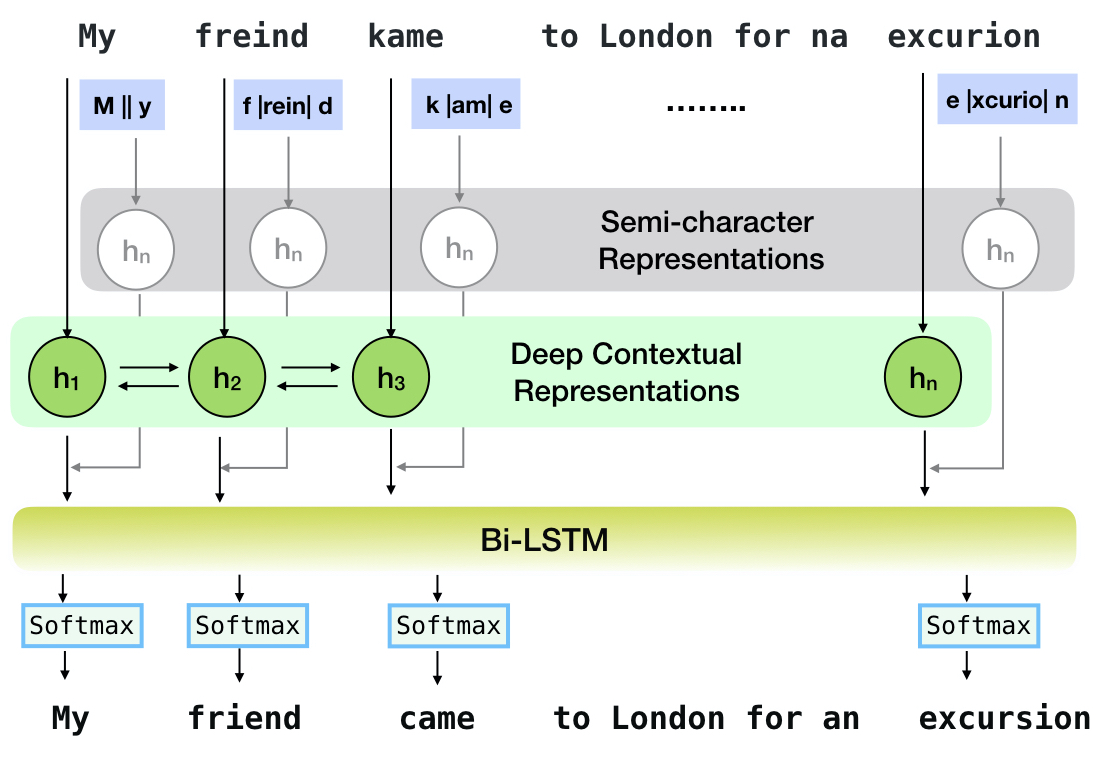
Ce pipeline correspond au modèle `SC-LSTM Plus ELMO (à l'entrée).
| Épeler Vérificateur | Mot Correction Taux | Temps par phrase (en millisecondes) |
|---|---|---|
Aspell | 48.7 | 7.3 * |
Jamspell | 68.9 | 2.6 * |
CNN-LSTM | 75.8 | 4.2 |
SC-LSTM | 76.7 | 2.8 |
Nested-LSTM | 77.3 | 6.4 |
BERT | 79.1 | 7.1 |
SC-LSTM plus ELMO (at input) | 79.8 | 15.8 |
SC-LSTM plus ELMO (at output) | 78.5 | 16.3 |
SC-LSTM plus BERT (at input) | 77.0 | 6.7 |
SC-LSTM plus BERT (at output) | 76.0 | 7.2 |
Performances de différents correcteurs dans la boîte à outils NEUSPELL sur l'ensemble de données BEA-60K avec des erreurs d'orthographe réelle. ∗ indique une évaluation sur un processeur (pour d'autres, nous utilisons un GPU GeForce RTX 2080).
Pour télécharger des points de contrôle sélectionnés, sélectionnez un nom de point de contrôle parmi ci-dessous, puis exécutez le téléchargement. Chaque point de contrôle est associé à un vérificateur orthographique neuronal comme indiqué dans le tableau.
| Vérificateur orthographique | Classe | Nom de point de contrôle | Espace disque (environ) |
|---|---|---|---|
CNN-LSTM | CnnlstmChecker | «CNN-LSTM-PROBWORDNOISE» | 450 Mb |
SC-LSTM | SclstmChecker | «scrnn-probwordnoise» | 450 Mb |
Nested-LSTM | NestedlstmChecker | 'lstm-lstm-probwordnoise' | 455 MB |
BERT | BertChecker | 'Subwordbert-probwordnoise' | 740 MB |
SC-LSTM plus ELMO (at input) | ElmosclstmChecker | «Elmoscrnn-probwordnoise» | 840 MB |
SC-LSTM plus BERT (at input) | BertsclstmChecker | «bertscrnn-probwordnoise» | 900 Mb |
SC-LSTM plus BERT (at output) | SclstmbertChecker | 'scrnnbert-probwordnoise' | 1,19 Go |
SC-LSTM plus ELMO (at output) | SclstmelmoChecker | «scrnnelmo-probwordnoise» | 1,23 Go |
import neuspell
neuspell . seq_modeling . downloads . download_pretrained_model ( "subwordbert-probwordnoise" )Alternativement, téléchargez tous les modèles neuronaux NEUSPELL en exécutant ce qui suit (disponible en versions après V1.0):
import neuspell
neuspell . seq_modeling . downloads . download_pretrained_model ( "_all_" )Alternativement,
Nous organisons plusieurs ensembles de données synthétiques et naturels pour la formation / évaluer les modèles NEUSPELL. Pour plus de détails, vérifiez notre papier. Exécutez ce qui suit pour télécharger tous les ensembles de données.
cd data/traintest
python download_datafiles.py
Voir data/traintest/README.md pour plus de détails.
Les fichiers de train sont surnommés avec des noms .random , .word , .prob , .probword pour différents startegies de NOSIONS utilisées pour les créer. Pour chaque stratégie (voir la création de données synthétiques), nous bruit ∼20% des jetons dans le corpus propre. Nous utilisons 1,6 million de phrases de l'ensemble de données One billion word benchmark comme notre corpus propre.
Afin de configurer une démo, suivez ces étapes:
pip install -e ".[flask]"CUDA_VISIBLE_DEVICES=0 python app.py (sur gpu) ou python app.py (sur CPU) Cette boîte à outils offre 3 types de stratégies de non-liaison (identifiées à partir de la littérature existante) pour générer des données de formation parallèle synthétiques pour former des modèles neuronaux pour la correction des sorts. Les stratégies incluent un remplacement d'orthographe bruyant basé sur la recherche ( en-word-replacement-noise ), une induction de bruit au niveau du caractère tel que l'échange / la suppression / l'ajout / remplacement des caractères ( en-char-replacement-noise en-probchar-replacement-noise ), et un remplacement de caractères probabilistes de confusion basé sur les erreurs). Pour plus de détails sur ces approches, consultez notre article.
Voici les mappages de classe correspondants pour utiliser les curations de bruit ci-dessus. Comme certains fichiers de données prédéfinis sont utilisés pour certains bruyants, nous fournissons également leur espace disque approximatif.
| Dossier | Nom de classe | Espace disque (environ) |
|---|---|---|
en-word-replacement-noise | WordReplacementNoiser | 2 Mb |
en-char-replacement-noise | CharacterReplacementNoiser | - |
en-probchar-replacement-noise | ProbabilisticCharacterReplacementNoiser | 80 Mb |
Voici un extrait pour l'utilisation de ces bruits
from neuspell . noising import WordReplacementNoiser
example_texts = [
"This is an example sentence to demonstrate noising in the neuspell repository." ,
"Here is another such amazing example !!"
]
word_repl_noiser = WordReplacementNoiser ( language = "english" )
word_repl_noiser . load_resources ()
noise_texts = word_repl_noiser . noise ( example_texts )
print ( noise_texts ) Coming Soon ...
neuspell from neuspell import BertChecker
checker = BertChecker ()
checker . from_pretrained ()
checker . finetune ( clean_file = "sample_clean.txt" , corrupt_file = "sample_corrupt.txt" , data_dir = "default" ) Cette fonctionnalité n'est disponible que pour BertChecker et ElmosclstmChecker .
Nous prenons désormais en charge l'initialisation d'un modèle HuggingFace et les entinerant sur vos données personnalisées. Voici un extrait de code démontrant que:
Marquez d'abord vos fichiers contenant des textes propres et corrompus dans un format séparé de ligne
from neuspell . commons import DEFAULT_TRAINTEST_DATA_PATH
data_dir = DEFAULT_TRAINTEST_DATA_PATH
clean_file = "sample_clean.txt"
corrupt_file = "sample_corrupt.txt" from neuspell . seq_modeling . helpers import load_data , train_validation_split
from neuspell . seq_modeling . helpers import get_tokens
from neuspell import BertChecker
# Step-0: Load your train and test files, create a validation split
train_data = load_data ( data_dir , clean_file , corrupt_file )
train_data , valid_data = train_validation_split ( train_data , 0.8 , seed = 11690 )
# Step-1: Create vocab file. This serves as the target vocab file and we use the defined model's default huggingface
# tokenizer to tokenize inputs appropriately.
vocab = get_tokens ([ i [ 0 ] for i in train_data ], keep_simple = True , min_max_freq = ( 1 , float ( "inf" )), topk = 100000 )
# # Step-2: Initialize a model
checker = BertChecker ( device = "cuda" )
checker . from_huggingface ( bert_pretrained_name_or_path = "distilbert-base-cased" , vocab = vocab )
# Step-3: Finetune the model on your dataset
checker . finetune ( clean_file = clean_file , corrupt_file = corrupt_file , data_dir = data_dir )Vous pouvez évaluer davantage votre modèle sur des données personnalisées comme suit:
from neuspell import BertChecker
checker = BertChecker ()
checker . from_pretrained (
bert_pretrained_name_or_path = "distilbert-base-cased" ,
ckpt_path = f" { data_dir } /new_models/distilbert-base-cased" # "<folder where the model is saved>"
)
checker . evaluate ( clean_file = clean_file , corrupt_file = corrupt_file , data_dir = data_dir ) Après l'utilisation ci-dessus, une fois peut maintenant utiliser de manière transparente des modèles multilingues tels que xlm-roberta-base , bert-base-multilingual-cased and distilbert-base-multilingual-cased sur un script non anglais.
./applications/Adversarial-Misspellings-arxiv . Voir Readme.md. Exigences pour Aspell Checker:
wget https://files.pythonhosted.org/packages/53/30/d995126fe8c4800f7a9b31aa0e7e5b2896f5f84db4b7513df746b2a286da/aspell-python-py3-1.15.tar.bz2
tar -C . -xvf aspell-python-py3-1.15.tar.bz2
cd aspell-python-py3-1.15
python setup.py install
Exigences pour le vérificateur Jamspell :
sudo apt-get install -y swig3.0
wget -P ./ https://github.com/bakwc/JamSpell-models/raw/master/en.tar.gz
tar xf ./en.tar.gz --directory ./
@inproceedings{jayanthi-etal-2020-neuspell,
title = "{N}eu{S}pell: A Neural Spelling Correction Toolkit",
author = "Jayanthi, Sai Muralidhar and
Pruthi, Danish and
Neubig, Graham",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = oct,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.emnlp-demos.21",
doi = "10.18653/v1/2020.emnlp-demos.21",
pages = "158--164",
abstract = "We introduce NeuSpell, an open-source toolkit for spelling correction in English. Our toolkit comprises ten different models, and benchmarks them on naturally occurring misspellings from multiple sources. We find that many systems do not adequately leverage the context around the misspelt token. To remedy this, (i) we train neural models using spelling errors in context, synthetically constructed by reverse engineering isolated misspellings; and (ii) use richer representations of the context. By training on our synthetic examples, correction rates improve by 9{%} (absolute) compared to the case when models are trained on randomly sampled character perturbations. Using richer contextual representations boosts the correction rate by another 3{%}. Our toolkit enables practitioners to use our proposed and existing spelling correction systems, both via a simple unified command line, as well as a web interface. Among many potential applications, we demonstrate the utility of our spell-checkers in combating adversarial misspellings. The toolkit can be accessed at neuspell.github.io.",
}
Lien pour la publication. Toutes les questions ou suggestions, veuillez contacter les auteurs de jsaimurali001 [at] gmail [dot] com


