neuspell
1.0.0
Neuspell: um kit de ferramentas de correção de ortografia neural
neuspell está agora disponível através do PIP . Veja a instalação através do PIPBERT pré-terenciado de Neuspell está agora disponível como parte dos modelos HuggingFace como murali1996/bert-base-cased-spell-correction . Fornecemos um exemplo de snippet de código em ./scripts/huggingface para profissionais curiosos.git clone https://github.com/neuspell/neuspell ; cd neuspell
pip install -e .Para instalar requisitos extras,
pip install -r extras-requirements.txtou individualmente como:
pip install -e .[elmo]
pip install -e .[spacy]Nota: Para Zsh , use ". [Elmo]" e ". [Spacy]" em vez disso
Além disso, spacy models podem ser baixados como:
python -m spacy download en_core_web_sm Em seguida, faça o download de modelos pré -traidos de neuspell após o download dos pontos de verificação
Aqui está um snippet de código de partida rápida (uso da linha de comando) para usar um modelo de verificador. Consulte test_neuspell_correctors.py para obter mais padrões de uso.
import neuspell
from neuspell import available_checkers , BertChecker
""" see available checkers """
print ( f"available checkers: { neuspell . available_checkers () } " )
# → available checkers: ['BertsclstmChecker', 'CnnlstmChecker', 'NestedlstmChecker', 'SclstmChecker', 'SclstmbertChecker', 'BertChecker', 'SclstmelmoChecker', 'ElmosclstmChecker']
""" select spell checkers & load """
checker = BertChecker ()
checker . from_pretrained ()
""" spell correction """
checker . correct ( "I luk foward to receving your reply" )
# → "I look forward to receiving your reply"
checker . correct_strings ([ "I luk foward to receving your reply" , ])
# → ["I look forward to receiving your reply"]
checker . correct_from_file ( src = "noisy_texts.txt" )
# → "Found 450 mistakes in 322 lines, total_lines=350"
""" evaluation of models """
checker . evaluate ( clean_file = "bea60k.txt" , corrupt_file = "bea60k.noise.txt" )
# → data size: 63044
# → total inference time for this data is: 998.13 secs
# → total token count: 1032061
# → confusion table: corr2corr:940937, corr2incorr:21060,
# incorr2corr:55889, incorr2incorr:14175
# → accuracy is 96.58%
# → word correction rate is 79.76%Como alternativa, uma vez pode selecionar e carregar um verificador ortográfico de maneira diferente da seguinte maneira:
from neuspell import SclstmChecker
checker = SclstmChecker ()
checker = checker . add_ ( "elmo" , at = "input" ) # "elmo" or "bert", "input" or "output"
checker . from_pretrained ()Atualmente, esse recurso da adição do modelo ELMO ou BERT é suportado para modelos selecionados. Consulte a lista de modelos neurais no kit de ferramentas para obter detalhes.
Se estiver interessado, siga os requisitos adicionais para a instalação de verificadores ortográficos não neurais- Aspell e Jamspell .
pip install neuspell Na v1.0, a biblioteca allennlp não é instalada automaticamente, usada para modelos que contêm ELMO. Portanto, para utilizar esses damas, faça uma instalação de fonte como na instalação e início rápido
O Neuspell é um kit de ferramentas de código aberto para correção de ortografia sensível ao contexto em inglês. Este kit de ferramentas é composto por 10 verificadores ortográficos, com avaliações sobre errôneas que ocorrem naturalmente de várias fontes (disponíveis ao público). Para tornar os modelos neurais para a verificação de ortografia dependente do contexto, (i) treinamos modelos neurais usando erros de ortografia no contexto, sinteticamente construídos por spellings incorretos isolados de engenharia reversa; e (ii) usar representações mais ricas do contexto. Este kit de ferramentas permite que os profissionais de PNL usem nossos sistemas de correção de ortografia propostos e existentes, tanto através de uma linha de comando unificada simples quanto para uma interface da Web. Entre muitas aplicações em potencial, demonstramos a utilidade de nossos verificadores de ortografia no combate aos erros de ortografia adversários.
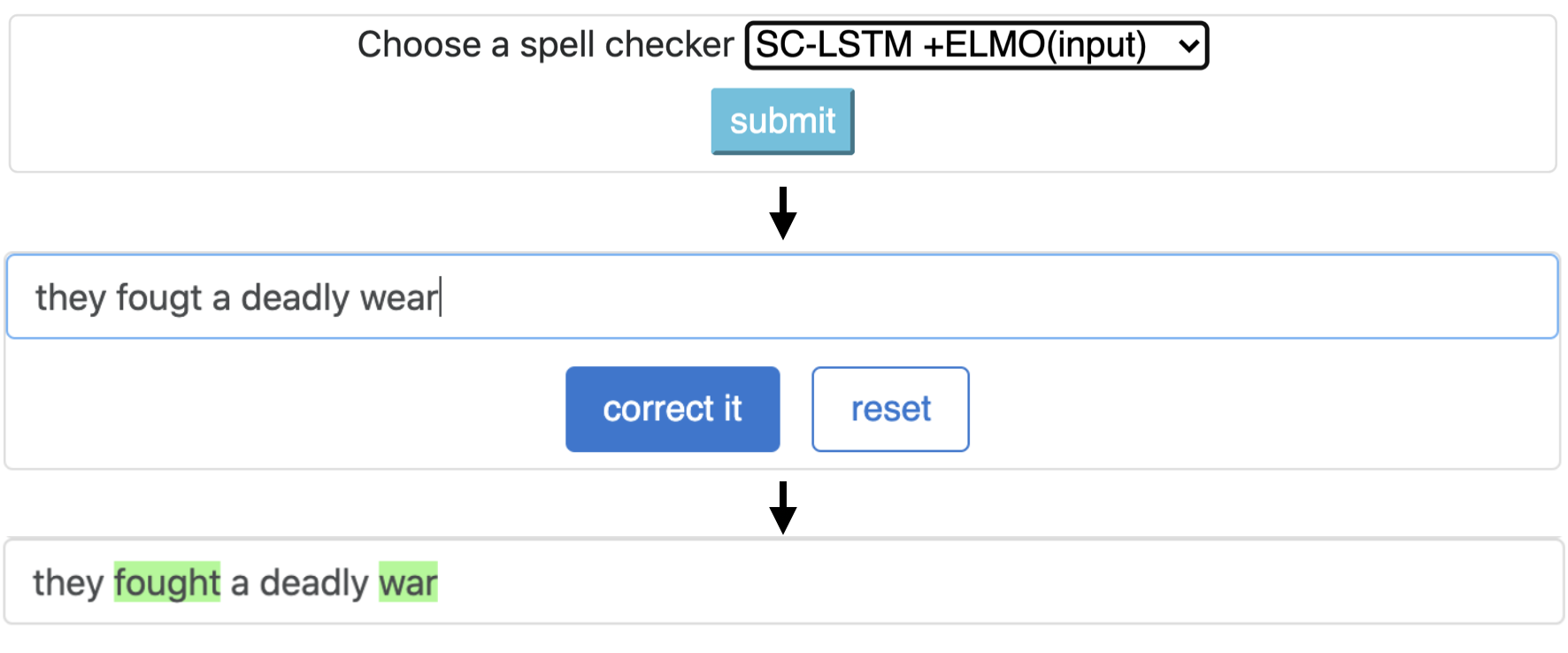
CNN-LSTMSC-LSTMNested-LSTMBERTSC-LSTM plus ELMO (at input)SC-LSTM plus ELMO (at output)SC-LSTM plus BERT (at input)SC-LSTM plus BERT (at output)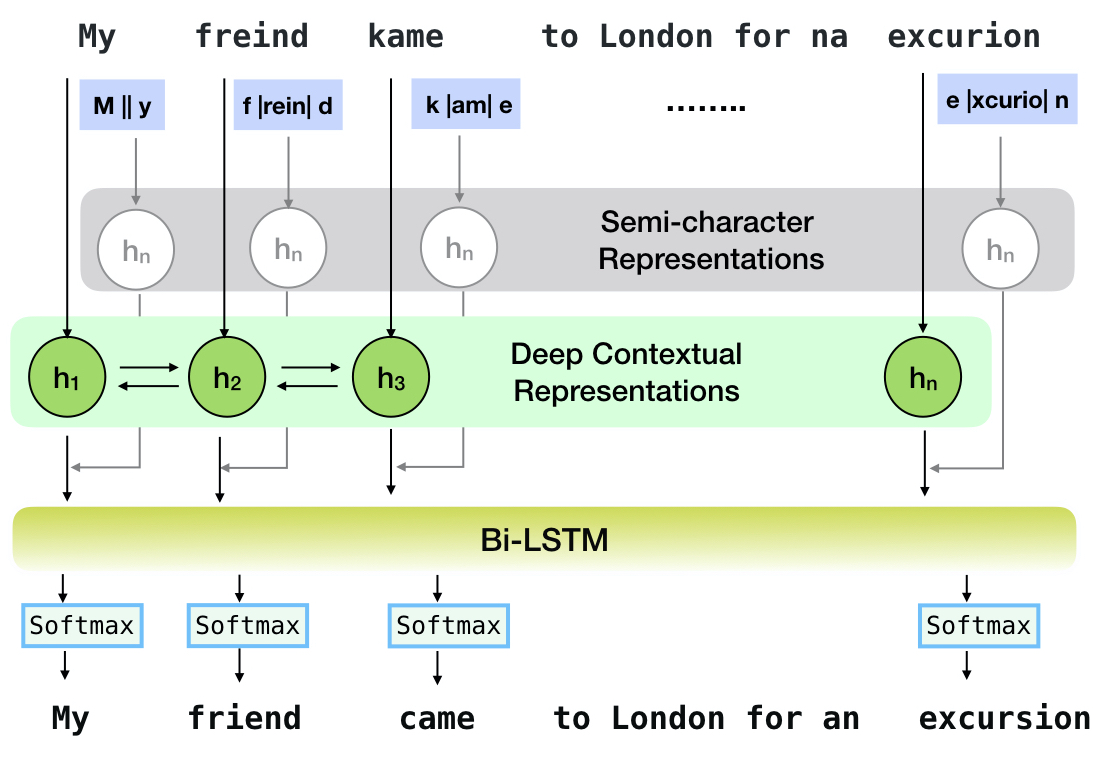
Este pipeline corresponde ao modelo `sc-lstm mais elmo (na entrada)`.
| Soletrar Verificador | Palavra Correção Avaliar | Tempo por frase (em milissegundos) |
|---|---|---|
Aspell | 48.7 | 7.3* |
Jamspell | 68.9 | 2.6* |
CNN-LSTM | 75.8 | 4.2 |
SC-LSTM | 76.7 | 2.8 |
Nested-LSTM | 77.3 | 6.4 |
BERT | 79.1 | 7.1 |
SC-LSTM plus ELMO (at input) | 79.8 | 15.8 |
SC-LSTM plus ELMO (at output) | 78.5 | 16.3 |
SC-LSTM plus BERT (at input) | 77.0 | 6.7 |
SC-LSTM plus BERT (at output) | 76.0 | 7.2 |
Desempenho de diferentes corretores no kit de ferramentas Neuspell no conjunto de dados BEA-60K com erros de ortografia do mundo real. ∗ Indica avaliação em uma CPU (para outros, usamos uma GPU GeForce RTX 2080 TI).
Para baixar pontos de verificação selecionados, selecione um nome de ponto de verificação abaixo e execute o download. Cada ponto de verificação está associado a um verificador de ortografia neural, conforme mostrado na tabela.
| Verificador ortográfico | Aula | Nome do ponto de verificação | Espaço de disco (aprox.) |
|---|---|---|---|
CNN-LSTM | CnnlstmChecker | 'CNN-LSTM-ProbwordNoise' | 450 MB |
SC-LSTM | SclstmChecker | 'scrnn-probwordnoise' | 450 MB |
Nested-LSTM | NestedlstmChecker | 'LSTM-LSTM-ProbwordNoise' | 455 MB |
BERT | BertChecker | 'Subwordbert-proBwordNoise' | 740 MB |
SC-LSTM plus ELMO (at input) | ElmosclstmChecker | 'Elmoscrnn-ProbwordNoise' | 840 MB |
SC-LSTM plus BERT (at input) | BertsclstmChecker | 'Bertscrnn-proBwordNoise' | 900 MB |
SC-LSTM plus BERT (at output) | SclstmbertChecker | 'scrnnbert-probwordnoise' | 1,19 GB |
SC-LSTM plus ELMO (at output) | SclstmelmoChecker | 'scrnnelmo-probwordnoise' | 1,23 GB |
import neuspell
neuspell . seq_modeling . downloads . download_pretrained_model ( "subwordbert-probwordnoise" )Como alternativa, faça o download de todos os modelos neurais Neuspell, executando o seguinte (disponível nas versões após a v1.0):
import neuspell
neuspell . seq_modeling . downloads . download_pretrained_model ( "_all_" )Alternativamente,
Curatamos vários conjuntos de dados sintéticos e naturais para treinamento/avaliação de modelos de neuspell. Para detalhes completos, verifique nosso artigo. Execute o seguinte para baixar todos os conjuntos de dados.
cd data/traintest
python download_datafiles.py
Consulte data/traintest/README.md para obter mais detalhes.
Os arquivos de trem são apelidados de nomes .random , .word , .prob , .probword para diferentes startegies de inquietação usados para criá -los. Para cada estratégia (consulte a criação de dados sintéticos), rugem ~ 20% dos tokens no corpus limpo. Utilizamos 1,6 milhão de frases do conjunto de dados One billion word benchmark como nosso corpus limpo.
Para configurar uma demonstração, siga estas etapas:
pip install -e ".[flask]"CUDA_VISIBLE_DEVICES=0 python app.py (na GPU) ou python app.py (na CPU) Este kit de ferramentas oferece três tipos de estratégias de barulho (identificadas na literatura existente) para gerar dados de treinamento paralelo sintético para treinar modelos neurais para correção de feitiços. As estratégias incluem uma simples substituição de ortografia barulhenta baseada em pesquisa ( en-word-replacement-noise ), uma indução de ruído em nível de caractere, como trocar/excluir/adicionar/substituir caracteres ( en-char-replacement-noise en-probchar-replacement-noise e um substituto da matriz baseado em um grande número. Para detalhes completos sobre essas abordagens, consulte nosso artigo.
A seguir, estão os mapeamentos de classe correspondentes para utilizar as curações de ruído acima. Como alguns arquivos de dados pré-criados são usados para alguns dos ruídos, também fornecemos seu espaço aproximado em disco.
| Pasta | Nome da classe | Espaço de disco (aprox.) |
|---|---|---|
en-word-replacement-noise | WordReplacementNoiser | 2 MB |
en-char-replacement-noise | CharacterReplacementNoiser | - |
en-probchar-replacement-noise | ProbabilisticCharacterReplacementNoiser | 80 MB |
A seguir, é um trecho para usar esses barulhentos-
from neuspell . noising import WordReplacementNoiser
example_texts = [
"This is an example sentence to demonstrate noising in the neuspell repository." ,
"Here is another such amazing example !!"
]
word_repl_noiser = WordReplacementNoiser ( language = "english" )
word_repl_noiser . load_resources ()
noise_texts = word_repl_noiser . noise ( example_texts )
print ( noise_texts ) Coming Soon ...
neuspell from neuspell import BertChecker
checker = BertChecker ()
checker . from_pretrained ()
checker . finetune ( clean_file = "sample_clean.txt" , corrupt_file = "sample_corrupt.txt" , data_dir = "default" ) Esse recurso está disponível apenas para BertChecker e ElmosclstmChecker .
Agora, apoiamos a inicialização de um modelo de Huggingface e o Finetuning em seus dados personalizados. Aqui está um trecho de código demonstrando que:
Primeiro marque seus arquivos que contêm textos limpos e corruptos em um formato com seleção de linha
from neuspell . commons import DEFAULT_TRAINTEST_DATA_PATH
data_dir = DEFAULT_TRAINTEST_DATA_PATH
clean_file = "sample_clean.txt"
corrupt_file = "sample_corrupt.txt" from neuspell . seq_modeling . helpers import load_data , train_validation_split
from neuspell . seq_modeling . helpers import get_tokens
from neuspell import BertChecker
# Step-0: Load your train and test files, create a validation split
train_data = load_data ( data_dir , clean_file , corrupt_file )
train_data , valid_data = train_validation_split ( train_data , 0.8 , seed = 11690 )
# Step-1: Create vocab file. This serves as the target vocab file and we use the defined model's default huggingface
# tokenizer to tokenize inputs appropriately.
vocab = get_tokens ([ i [ 0 ] for i in train_data ], keep_simple = True , min_max_freq = ( 1 , float ( "inf" )), topk = 100000 )
# # Step-2: Initialize a model
checker = BertChecker ( device = "cuda" )
checker . from_huggingface ( bert_pretrained_name_or_path = "distilbert-base-cased" , vocab = vocab )
# Step-3: Finetune the model on your dataset
checker . finetune ( clean_file = clean_file , corrupt_file = corrupt_file , data_dir = data_dir )Você pode avaliar ainda mais seu modelo em dados personalizados da seguinte forma:
from neuspell import BertChecker
checker = BertChecker ()
checker . from_pretrained (
bert_pretrained_name_or_path = "distilbert-base-cased" ,
ckpt_path = f" { data_dir } /new_models/distilbert-base-cased" # "<folder where the model is saved>"
)
checker . evaluate ( clean_file = clean_file , corrupt_file = corrupt_file , data_dir = data_dir ) Após o uso acima, uma vez agora pode utilizar perfeitamente modelos multilíngues, como xlm-roberta-base , bert-base-multilingual-cased e distilbert-base-multilingual-cased em um script não inglês.
./applications/Adversarial-Misspellings-arxiv . Consulte Readme.md. Requisitos para verificador Aspell :
wget https://files.pythonhosted.org/packages/53/30/d995126fe8c4800f7a9b31aa0e7e5b2896f5f84db4b7513df746b2a286da/aspell-python-py3-1.15.tar.bz2
tar -C . -xvf aspell-python-py3-1.15.tar.bz2
cd aspell-python-py3-1.15
python setup.py install
Requisitos para o verificador Jamspell :
sudo apt-get install -y swig3.0
wget -P ./ https://github.com/bakwc/JamSpell-models/raw/master/en.tar.gz
tar xf ./en.tar.gz --directory ./
@inproceedings{jayanthi-etal-2020-neuspell,
title = "{N}eu{S}pell: A Neural Spelling Correction Toolkit",
author = "Jayanthi, Sai Muralidhar and
Pruthi, Danish and
Neubig, Graham",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = oct,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.emnlp-demos.21",
doi = "10.18653/v1/2020.emnlp-demos.21",
pages = "158--164",
abstract = "We introduce NeuSpell, an open-source toolkit for spelling correction in English. Our toolkit comprises ten different models, and benchmarks them on naturally occurring misspellings from multiple sources. We find that many systems do not adequately leverage the context around the misspelt token. To remedy this, (i) we train neural models using spelling errors in context, synthetically constructed by reverse engineering isolated misspellings; and (ii) use richer representations of the context. By training on our synthetic examples, correction rates improve by 9{%} (absolute) compared to the case when models are trained on randomly sampled character perturbations. Using richer contextual representations boosts the correction rate by another 3{%}. Our toolkit enables practitioners to use our proposed and existing spelling correction systems, both via a simple unified command line, as well as a web interface. Among many potential applications, we demonstrate the utility of our spell-checkers in combating adversarial misspellings. The toolkit can be accessed at neuspell.github.io.",
}
Link para a publicação. Qualquer dúvida ou sugestão, entre em contato com os autores do Jsaimurali001 [at] Gmail [dot] com


