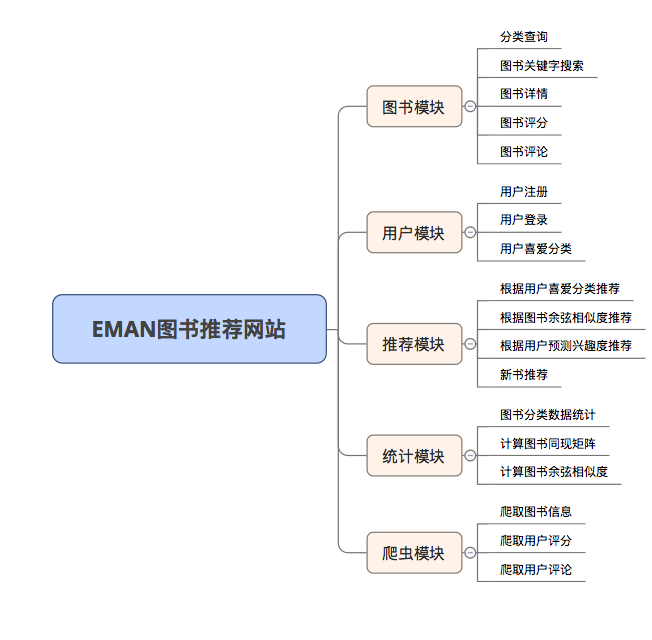
EMAN
1.0.0
Простая система рекомендаций по электронной книге, основанная на алгоритме Framework и Pretment Collaborative Filtering (ITEMCF)
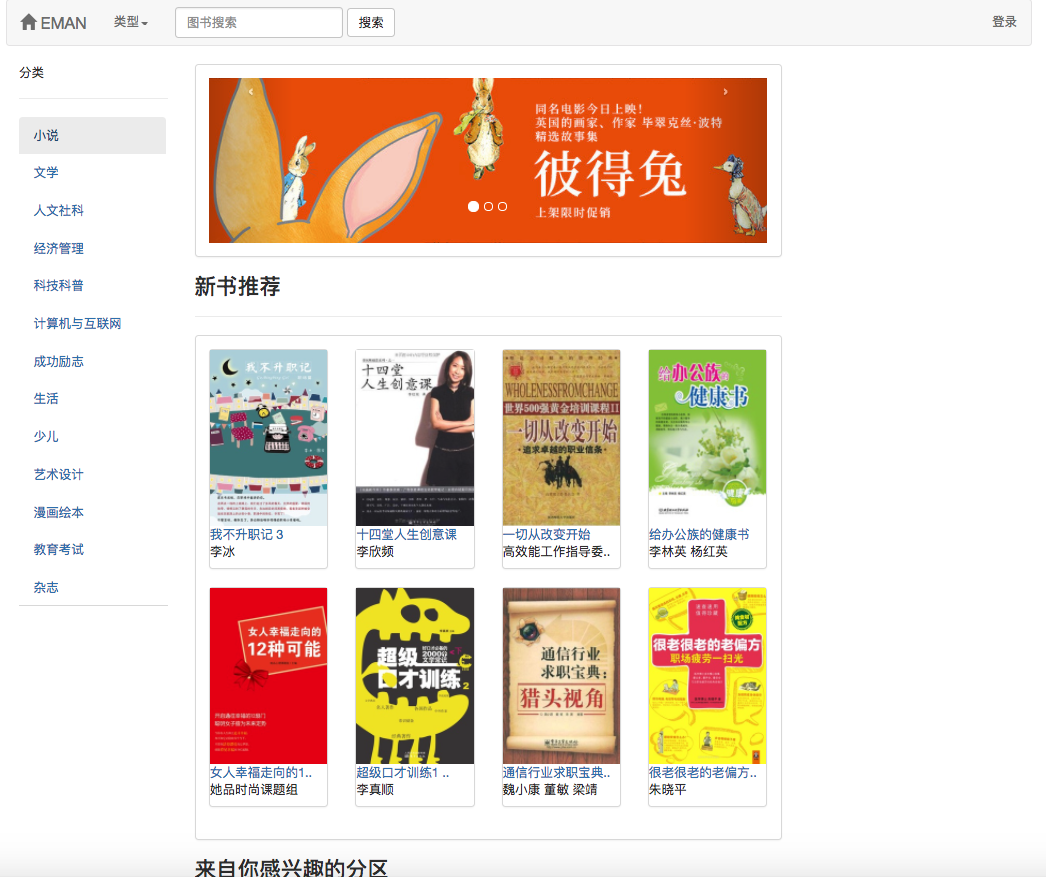
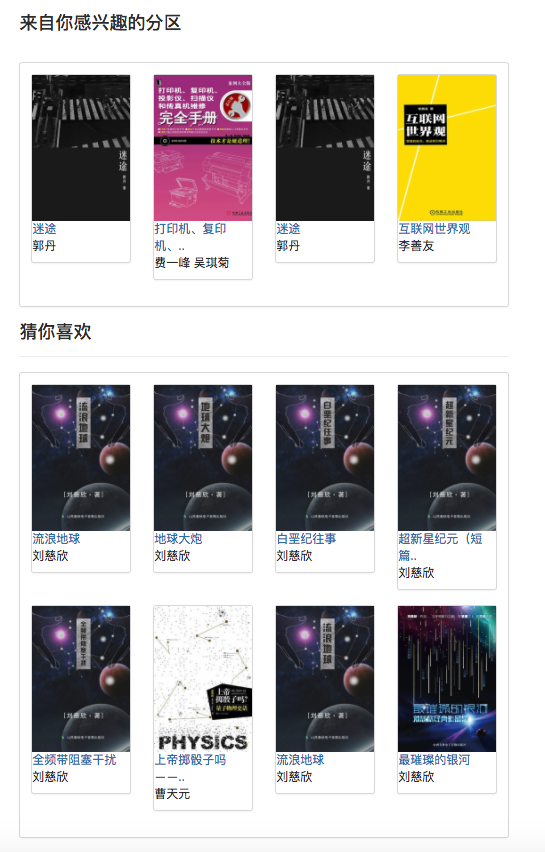
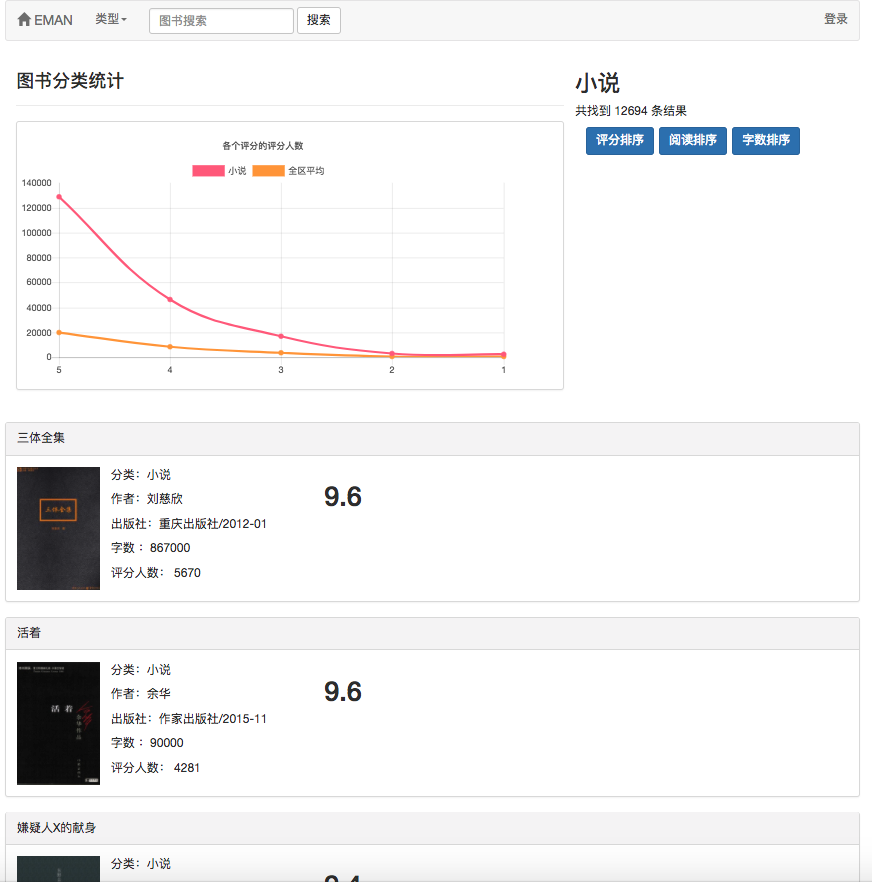
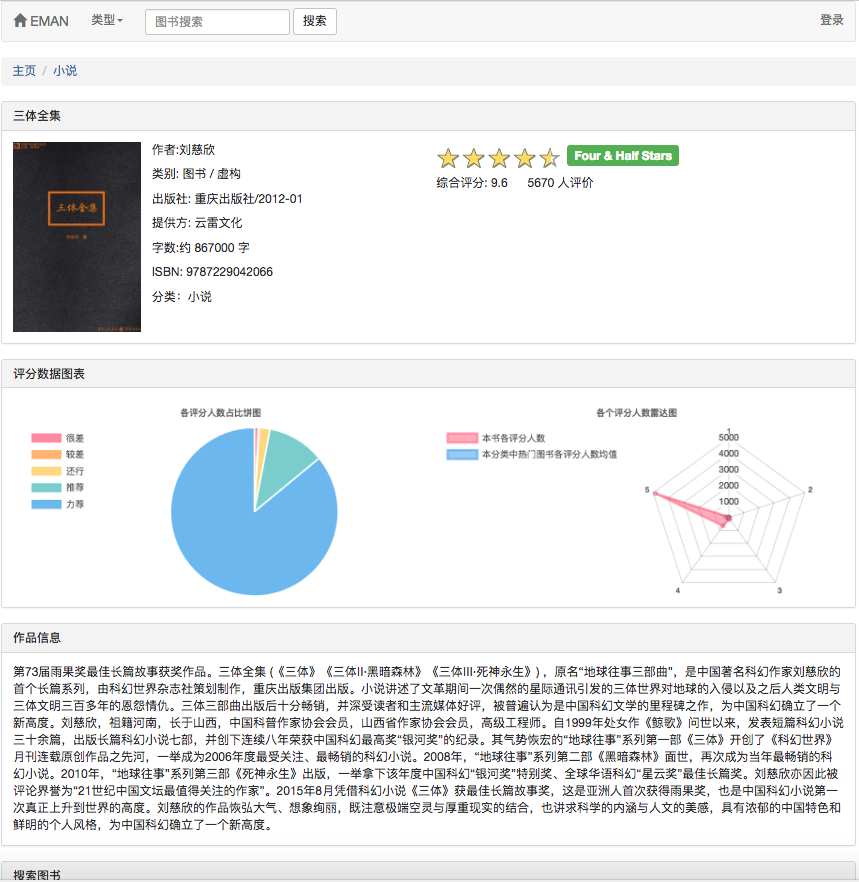
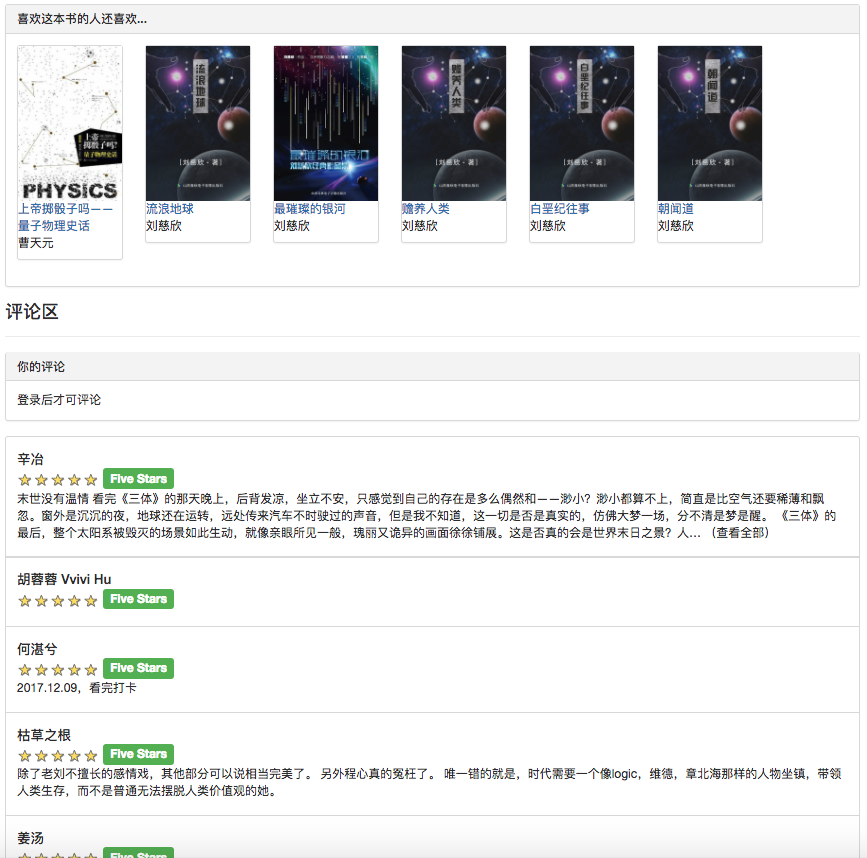
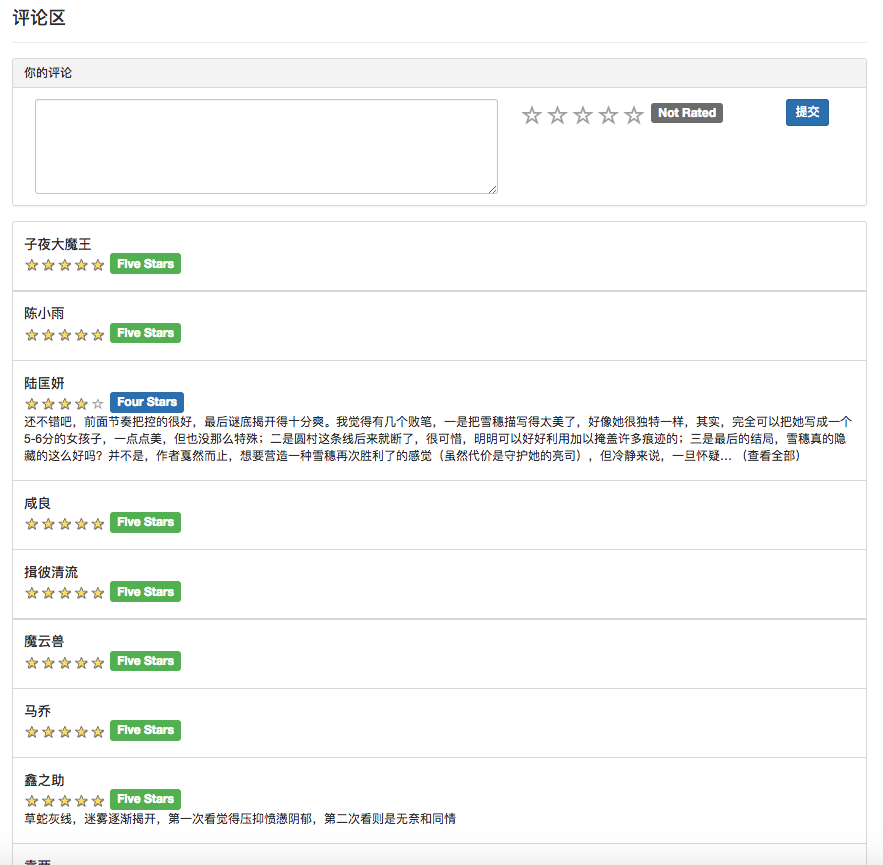
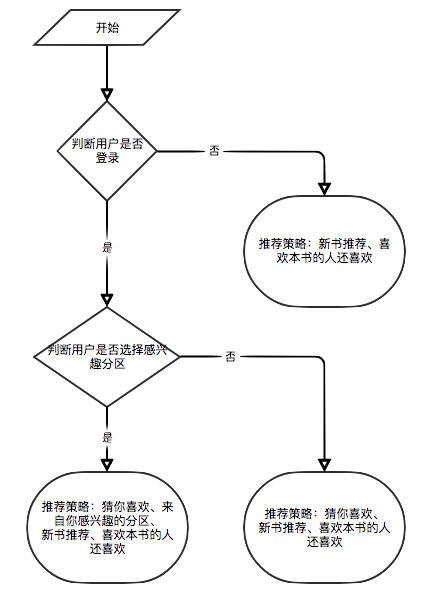
Потому что некоторые алгоритмы рекомендаций должны использовать любимые данные пользователя в качестве параметров. Если пользователь не вошел в систему, будет принята стратегия рекомендаций для туристов. Если пользователь входит в систему, внедрена политика рекомендаций для пользователя зарегистрированного. Если пользователь, зарегистрированный в регистрации, имеет интересующую запись разделения в базе данных, будет добавлена рекомендация из интересующего вас разделения. Поэтому стратегия рекомендации разделена на две ситуации: войти в систему или нет.
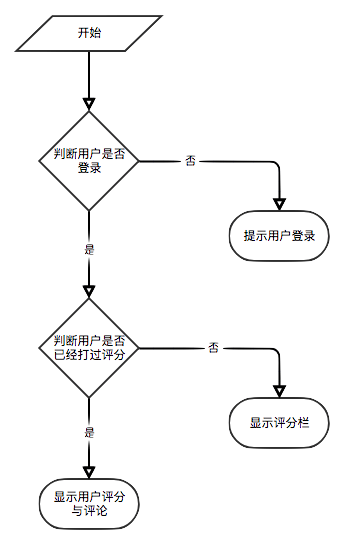
Если пользователь не вошел в систему, будет принята стратегия отображения рейтинга пользователей для туристов. Если пользователь вошел в систему, внедрена политика отображения рейтинга пользователя для пользователя, зарегистрированного в регистрации. Если пользователь, зарегистрированный, уже набрал электронную книгу на странице текущих сведений, будет отображаться его запись.
Как показано на диаграмме вариантов использования, в этой системе есть три основных пользователя. Это туристы, зарегистрированные пользователи и администраторы. Посетители могут посетить домашнюю страницу платформы рекомендаций электронной книги, страницы регистрации пользователей и просмотреть страницу электронной книги. Функция регистрации пользователей заключается в том, что они могут оценивать и комментировать электронные книги и рекомендовать электронные книги, определяемые прогнозируемым процентом пользователя. Администраторы могут регулярно использовать модуль Crawler для обновления информации о электронных книгах и использовать модуль статистики для обновления классифицированной статистики, матрицы совместного появления электронных книг и матрицы сходства косинусов E-книги.
! [User case.png] (/img/user case.png)
Учитывая, что с этим алгоритмом возникает проблема с холодным стартом. То есть для новых пользователей им часто не хватает данных о рейтингах, что приводит к рекомендации, основанной на прогнозируемом уровне процентов пользователя и не может быть гладко. Чтобы решить эту проблему, я добавил модуль для непосредственного использования матрицы сходства косинуса, чтобы непосредственно выполнять аналогичные рекомендации по электронной книге, чтобы незарегистрированные пользователи и новые пользователи могли лучше получить рекомендации. Что касается проблем с редкой матрицы данных в алгоритмах совместной фильтрации, некоторые непопулярные электронные книги могут не иметь рейтингов пользователей, низкой корреляции электронной книги, а у некоторых пользователей мало рейтингов электронной книги. Чтобы решить эту проблему, добавьте новую модуль рекомендаций книги на домашнюю страницу, чтобы лучше рекомендовать электронные книги, которые не имеют оценки; Добавьте модуль рекомендации по разделу, чтобы рекомендовать электронные книги на основе интереса пользователя, чтобы увеличить интерес конкретных пользователей, чтобы рекомендовать электронные книги. Стоит отметить, что электронная книга, рекомендованная пользователями для прогнозирования, рассчитывается с использованием формул на матрице сходства косинуса W, рассчитанной по этому алгоритму. Кроме того, любимая электронная книга пользователя также требуется в качестве входных параметров во время расчета. Рекомендуемая аналогичная электронная книга заключается в использовании матрицы сходства строк для статистики напрямую. Это означает, что две вышеупомянутые рекомендации должны завершить расчет матрицы совместного поступления электронной книги и матрицы сходства косинуса электронной книги. Поскольку вышеупомянутые две матрицы являются вычислительными, и все данные требуются для каждого расчета, он должен быть регулярно выполняться администратором.
Символ → Указывает, что класс является обычной ручной работой модулей

Существует два основных шага для алгоритма совместной фильтрации на основе элементов:
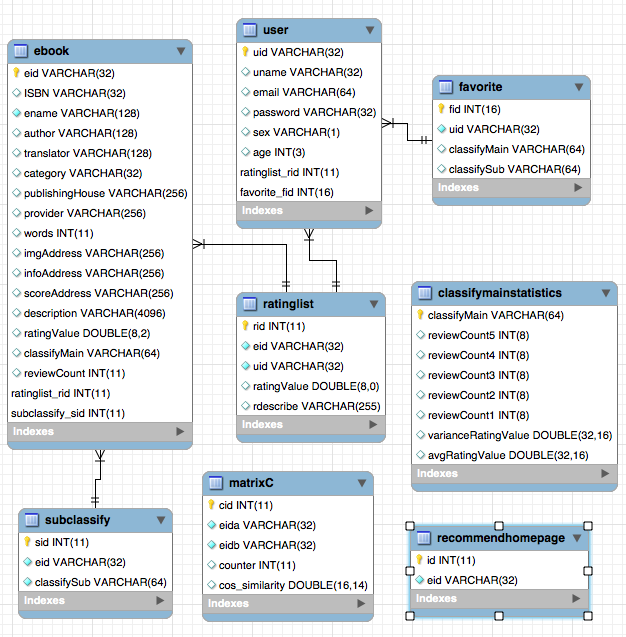
Предположим, N (i) - это количество пользователей, которым нравится пункт i. N (i) ⋂n (j) представляет количество пользователей, которым нравится Item I j одновременно. Тогда сходство между пунктом I и пунктом J:
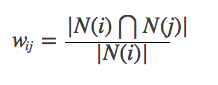
Тем не менее, приведенная выше формула имеет дефект: когда Item J является очень популярным продуктом, и всем нравится, тогда WIJ будет очень близок к 1, то есть вышеуказанная формула сделает много предметов иметь отличное сходство с популярными продуктами, поэтому вы можете улучшить формулу:
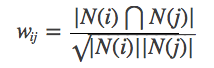
Создайте список пользовательских элементов, перевернутых (предположим, что буквы с заглавными буквами представляют пользователей, строчные буквы представляют элементы):

Рассчитайте матрицу Co-occurrence C (матрица Co-occurrence C представляет количество пользователей, которые, как два элемента одновременно, и рассчитывается на основе таблицы инверсии пользователя):
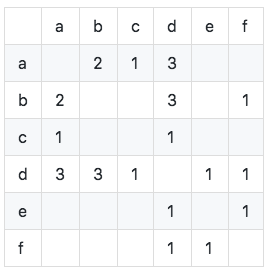
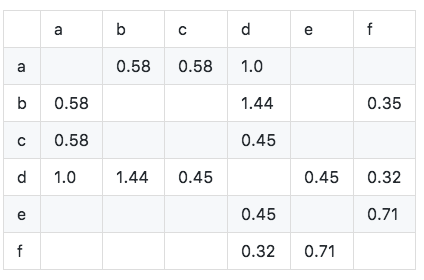
Как показано на рисунке, мы видим, что диагональные элементы матрицы совместного появления-все 0 и являются настоящими симметричными разреженными матрицами. Алгоритм реализуется следующим образом:
com.statistics.itemcollaborationfilter
/**
* 计算共现矩阵C
*/
private void computerMatrixC (){
// 建立用户物品倒排表
// 若用户对物品评分大于等于4则认为喜欢(出现)
List < User > allUser = userDao . queryAllUser ();
for ( int i = 0 ; i < allUser . size (); i ++){ // 遍历全部用户
// 获取一个用户的评分列表中>=4的评分记录
List < RatingList > likeList = ratingListDao . selectRatingListByUidAndRatingValue ( allUser . get ( i ). getUid (), 4 );
if ( likeList . size () <= 1 ){ // 若用户只喜欢一本或不喜欢任何图书
continue ;
}
for ( int j = 0 ; j < likeList . size (); j ++){ // 计算likeList中两两出现的图书并写入同现矩阵C
for ( int k = j + 1 ; k < likeList . size (); k ++){
int a = Integer . valueOf ( likeList . get ( j ). getEid ());
int b = Integer . valueOf ( likeList . get ( k ). getEid ());
// 生成key
String key = null ;
if ( a < b ){
key = a + "," + b ;
} else {
key = b + "," + a ;
}
// 检查key是否已经存在
if ( this . matrixC . get ( key ) != null ){
int value = this . matrixC . get ( key );
this . matrixC . put ( key , value + 1 );
} else {
this . matrixC . put ( key , 1 );
}
}
}
System . out . println ( "[" + df . format ( new Date ())+ "]" + "[已完成" + i + ",共" + allUser . size ()+ "]:用户uid=" + allUser . get ( i ). getUid ()+ "的记录以计算完成,共" + likeList . size ()+ "本图书" );
}
}Количество раз, когда каждый элемент появляется:

Рассчитайте матрицу сходства косинуса w: матрица сходства косинуса может быть получена с помощью улучшенной формулы.
Алгоритм реализуется следующим образом:
com.statistics.itemcollaborationfilter
/**
* 计算余弦相似度矩阵W
* 计算方法:
* 使用矩阵C的每个value作为分子,key中的两个图书的喜欢人数的积开根号作为分母
*/
private Double computerMatrixW ( String eida , String eidb , int value ){
DecimalFormat df = new DecimalFormat ( "#.##" );
// 查询每个图书有多少人喜欢
try {
Statement statemenet = conn . createStatement ();
ResultSet rs = statemenet . executeQuery ( "select count(rid) from ratinglist where eid = '" + eida + "' and ratingValue >= 4;" );
rs . next ();
int likeANum = rs . getInt ( "count(rid)" );
rs = statemenet . executeQuery ( "select count(rid) from ratinglist where eid = '" + eidb + "' and ratingValue >= 4;" );
rs . next ();
int likeBNum = rs . getInt ( "count(rid)" );
if ( likeANum == 0 )
likeANum = 1 ;
if ( likeBNum == 0 )
likeBNum = 1 ;
// 开始计算
Double answer = value * 1.0 / Math . sqrt ( likeANum * likeBNum );
// 精确到小数点后两位
Double result = Double . parseDouble ( df . format ( answer ));
// 返回计算结果
return result ;
} catch ( SQLException e ) {
e . printStackTrace ();
}
return null ;
}Какой предмет в конечном итоге рекомендуется, определяется путем прогнозирования интереса.
Item J прогнозирует процент = процент элемента I, который пользователю любит × сходство между пунктом I и пунктом J.
Например: пользователю нравятся элементы A, B и C. Их интерес составляет 1, 2 и 2 соответственно. Тогда прогнозируемый интерес предметов C, D, E и F - это:
Следовательно, пункт D должен быть рекомендован пользователю. Алгоритм реализуется следующим образом:
@ Override
public List < EBook > userRecommendedList ( String uid ) {
// 获取用户喜爱图书列表
List < RatingList > likeList = this . ratingListDao . selectRatingListByUidAndRatingValue ( uid , 4 );
// debug
System . out . println ( "uid=" + uid + "用户喜爱图书列表" );
for ( RatingList r : likeList ){
System . out . println ( r . getEid ()+ "," + r . getRatingValue ());
}
System . out . println ( "likeList.size=" + likeList . size ());
// 定义计算用矩阵
List < Item > matrix = new ArrayList <>();
// 将用户喜爱的图书作为矩阵的列
// 将与用户喜爱的图书同现的图书作为矩阵的行
// 建立工作矩阵
for ( int i = 0 ; i < likeList . size (); i ++){ // 遍历用户喜爱的图书
RatingList temp = likeList . get ( i );
// 获取同现图书
List < MatrixC > itemList = this . matrixCDao . selectMatrixCByEidAOrEidB ( temp . getEid (), temp . getEid ());
for ( int j = 0 ; j < itemList . size (); j ++){
MatrixC c = itemList . get ( j );
// 从matrixC的key中选出同现图书的eid
String sEid = null ;
if ( c . getEida (). equals ( temp . getEid ())){
sEid = c . getEidb ();
} else {
sEid = c . getEida ();
}
// 在行中查询同现图书是否存在
if ( matrix . indexOf ( sEid ) == - 1 ){ // 若列中不存在
double [] col = new double [ likeList . size ()];
// 将同现图书所在行对应喜爱图书的数组值设为对应的余弦相似度*用户喜爱程度(4分为1,5分为2)
col [ likeList . indexOf ( temp )] = c . getCos_similarity ()*( temp . getRatingValue ()- 3 );
matrix . add ( new Item ( sEid , col )); // 增加行
} else { // 若列中存在
// 则将同现图书所在行对应喜爱图书的数组值设为对应的余弦相似度*用户喜爱程度(4分为1,5分为2)
matrix . get ( matrix . indexOf ( sEid )). col [ likeList . indexOf ( temp )] = c . getCos_similarity ()*( temp . getRatingValue ()- 3 );
}
}
}
// 计算预测兴趣度
for ( int i = 0 ; i < matrix . size (); i ++){
Item item = matrix . get ( i );
double interestValue = 0 ;
for ( int j = 0 ; j < item . col . length ; j ++){
interestValue += item . col [ j ];
}
matrix . get ( i ). interestValue = interestValue ;
}
// 根据预测兴趣度进行排序
Collections . sort ( matrix );
// 返回推荐图书列表
List < EBook > resultList = new ArrayList <>();
for ( int i = 0 ; i < matrix . size () && i < 20 ; i ++){ // 返回排前10的书
if ( matrix . get ( i ). interestValue > 0 ){
EBook eBook = this . eBookDao . queryEBookByEid ( matrix . get ( i ). eid );
resultList . add ( eBook );
// debug
System . out . println ( matrix . get ( i ). eid + "," + eBook . getEname ()+ ",interestValue=" + matrix . get ( i ). interestValue );
}
}
return EBookServiceImpl . initEBookImgAddress ( resultList );
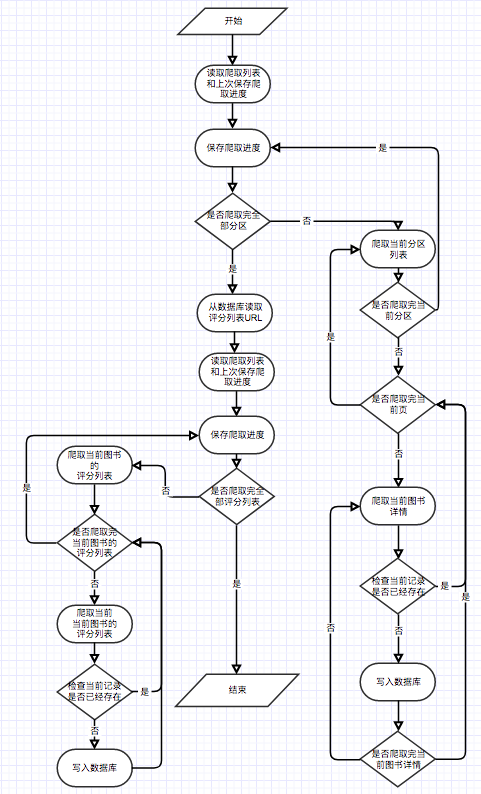
}Рекомендуемый модуль использует данные, ползутые гусеницей в качестве входных данных для вывода результатов расчета в таблице Matrixc. Весь процесс расчета разделен на 2 этапа. На первом этапе рассчитывается матрица совместного появления C. На втором этапе рассчитывает сходство косинуса w из электронных книг, которые появляются парами. Для рекомендуемой функции, основанной на прогнозируемой пользователе, поскольку пользователю нравится в режиме реального времени, и общая сумма расчетов данных электронной книги слишком велика, пользователь будет использовать вычисления в реальном времени при доступе к странице. После нескольких тестов среднее время ожидания пользователя находится в приемлемом диапазоне.
Поскольку обновление веб-страницы Douban Movie добавило меры против развертывания, здесь представлены данные, используемые для запуска рекомендуемого алгоритма.


