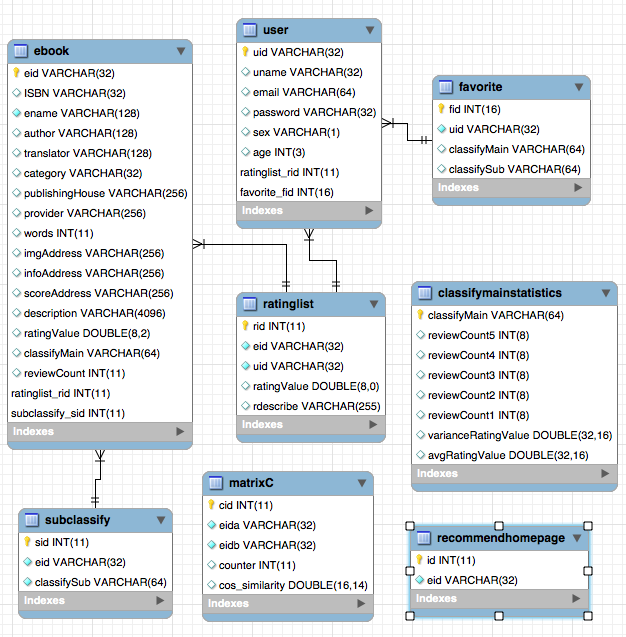
EMAN
1.0.0
Sistem rekomendasi e-book sederhana berdasarkan kerangka kerja SSM dan algoritma penyaringan kolaboratif item (itemCF)
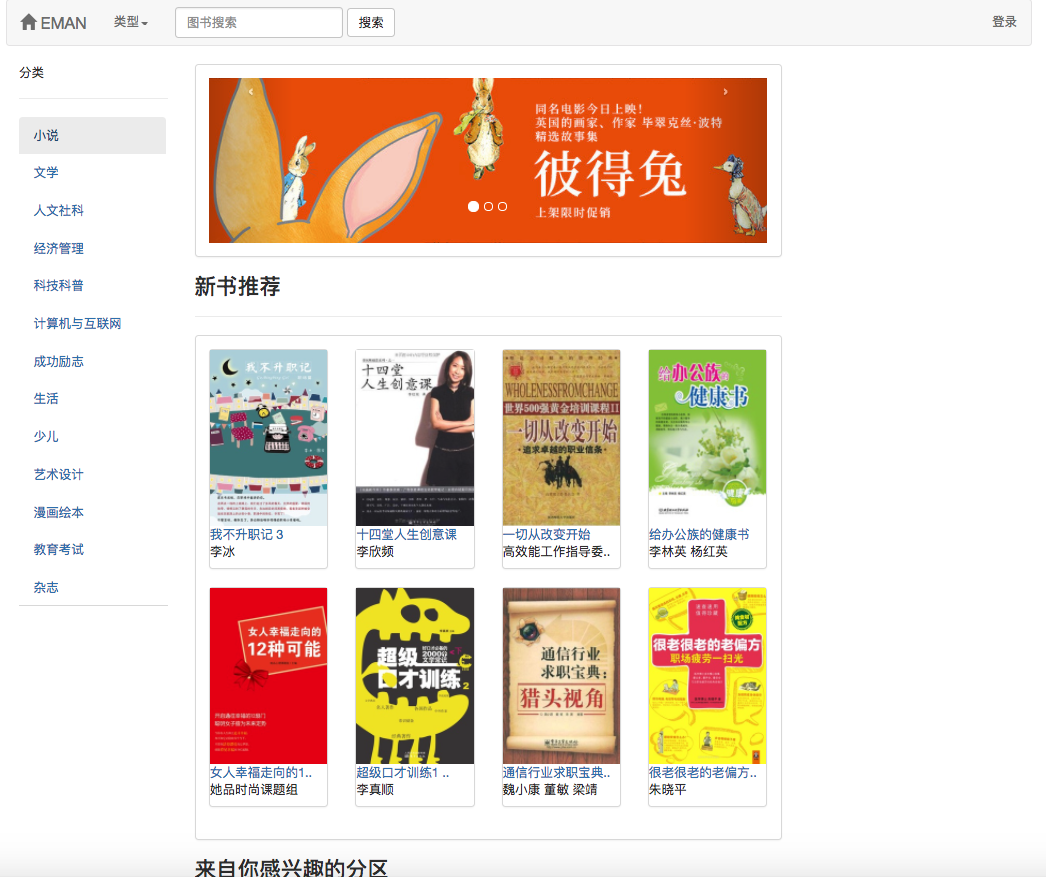
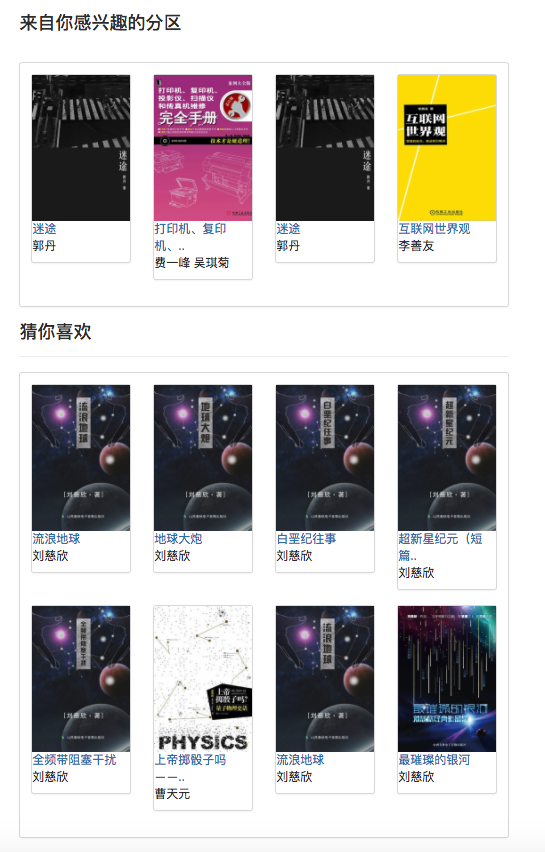
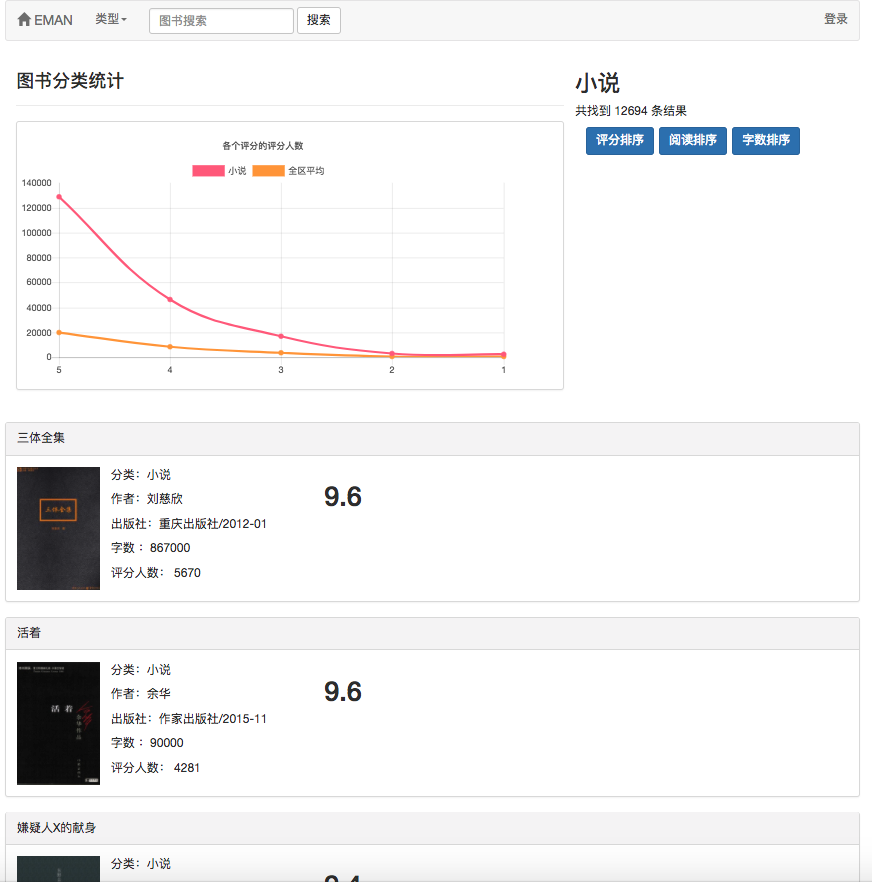
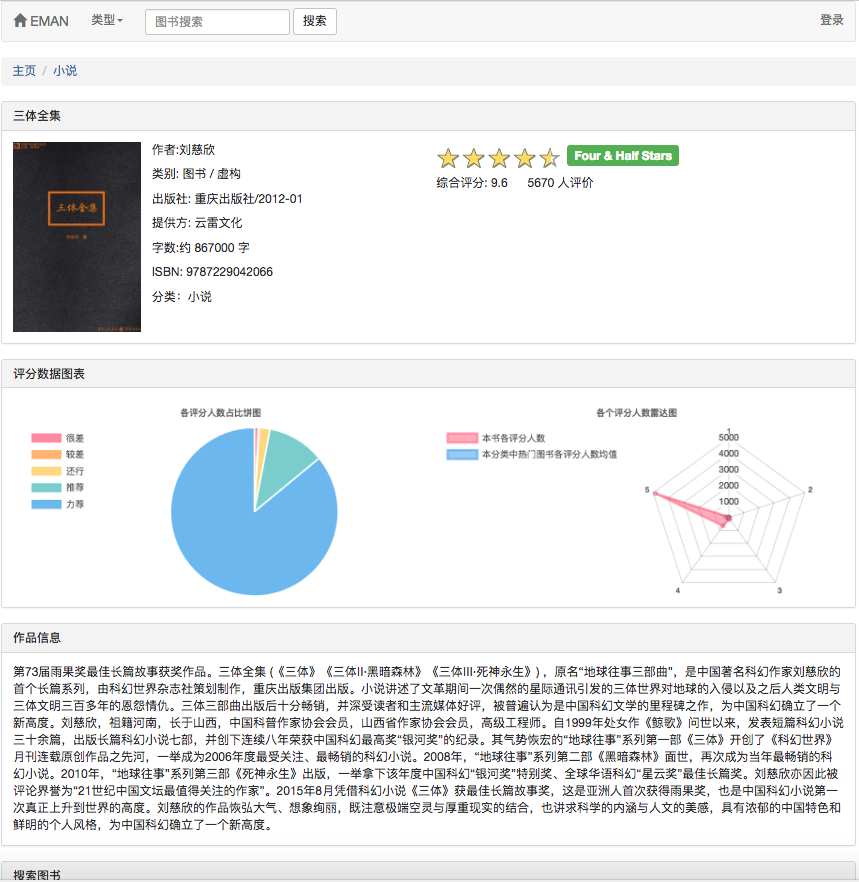
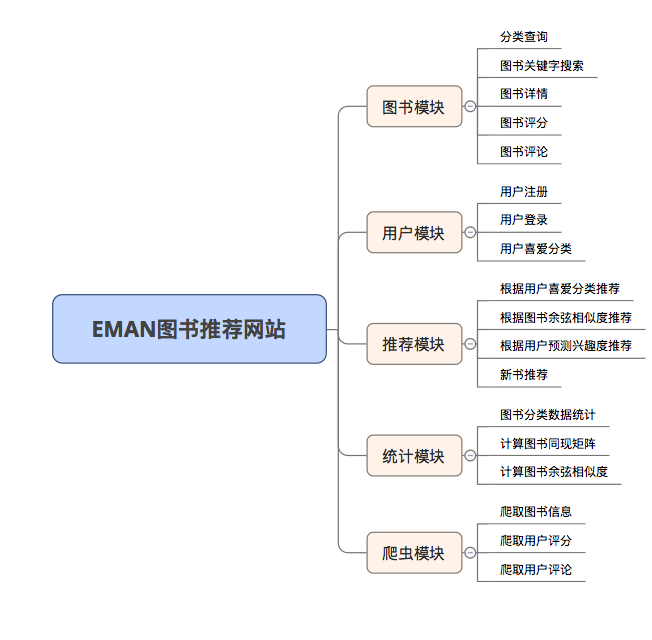
Karena beberapa algoritma rekomendasi perlu menggunakan data favorit pengguna sebagai parameter. Jika pengguna tidak masuk, strategi rekomendasi untuk wisatawan akan diadopsi. Jika pengguna masuk, kebijakan rekomendasi untuk pengguna yang masuk diadopsi. Jika pengguna yang masuk memiliki catatan partisi yang menarik dalam database, rekomendasi dari partisi yang Anda minati akan ditambahkan. Oleh karena itu, strategi rekomendasi dibagi menjadi dua situasi: apakah akan masuk atau tidak.
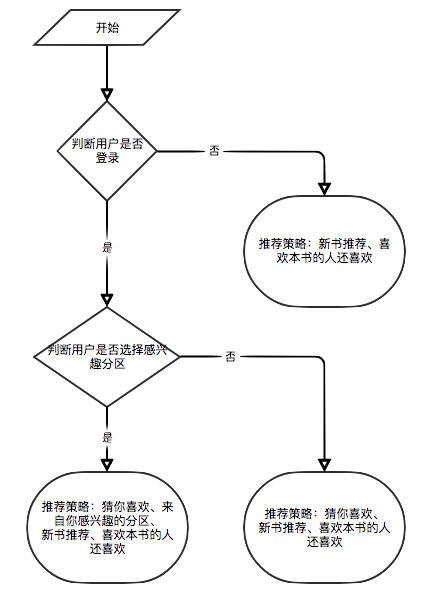
Jika pengguna tidak masuk, strategi tampilan peringkat pengguna untuk wisatawan akan diadopsi. Jika pengguna masuk, kebijakan tampilan peringkat pengguna untuk pengguna yang dicatat diadopsi. Jika pengguna yang masuk telah mencetak e-book pada halaman Detail saat ini, catatan peringkatnya akan ditampilkan.
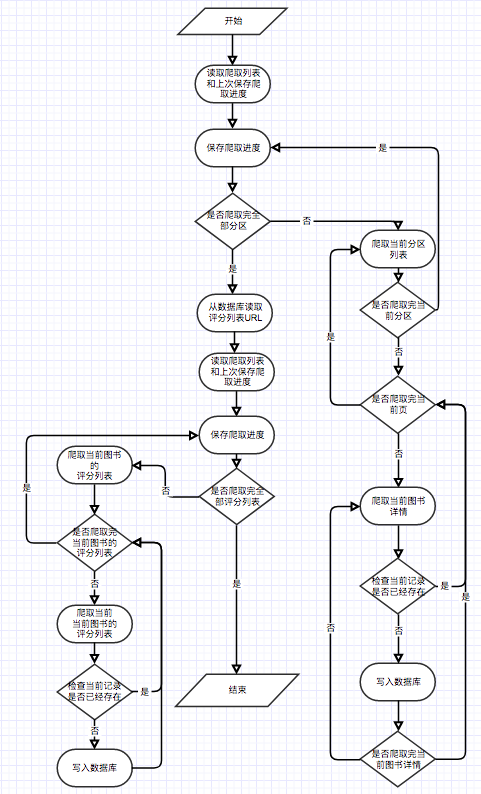
Seperti yang ditunjukkan dalam diagram Use Case, ada tiga pengguna dasar dalam sistem ini. Ini adalah wisatawan, pengguna terdaftar, dan administrator. Pengunjung dapat mengunjungi beranda platform rekomendasi e-book, halaman pendaftaran pengguna, dan melihat halaman e-book. Fungsi mendaftarkan pengguna adalah bahwa mereka dapat menilai dan mengomentari e-book dan merekomendasikan e-book yang ditentukan oleh minat yang diprediksi pengguna. Administrator dapat secara teratur menggunakan modul crawler untuk memperbarui informasi e-book dan menggunakan modul statistik untuk memperbarui statistik rahasia, matriks kemunculan bersama e-book dan matriks kesamaan cosinus e-book.
! [User case.png] (/img/user case.png)
Mempertimbangkan bahwa ada masalah awal yang dingin dengan algoritma ini. Artinya, bagi pengguna baru, mereka sering tidak memiliki data peringkat, yang mengarah pada rekomendasi berdasarkan tingkat bunga yang diprediksi pengguna dan tidak dapat dilakukan dengan lancar. Untuk mengatasi masalah ini, saya menambahkan modul untuk secara langsung menggunakan matriks kesamaan cosinus W untuk secara langsung melakukan rekomendasi e-book yang serupa, sehingga pengguna yang tidak terdaftar dan pengguna baru dapat memperoleh rekomendasi dengan lebih baik. Adapun masalah matriks data yang jarang dalam algoritma penyaringan kolaboratif, beberapa e-book yang tidak populer mungkin tidak memiliki peringkat pengguna, korelasi e-book rendah, dan beberapa pengguna memiliki beberapa peringkat e-book. Untuk mengatasi masalah ini, tambahkan modul rekomendasi buku baru ke beranda untuk lebih merekomendasikan e-book yang tidak memiliki peringkat; Tambahkan modul rekomendasi partisi untuk merekomendasikan e-book berdasarkan minat pengguna untuk meningkatkan minat pengguna tertentu untuk merekomendasikan e-book. Perlu dicatat bahwa e-book yang direkomendasikan oleh pengguna untuk memprediksi minat dihitung menggunakan rumus pada matriks kesamaan kosinus yang dihitung oleh algoritma ini. Selain itu, e-book favorit pengguna juga diperlukan sebagai parameter input selama perhitungan. E-book serupa yang disarankan adalah menggunakan matriks kesamaan string untuk statistik secara langsung. Ini berarti bahwa dua rekomendasi di atas perlu menyelesaikan perhitungan matriks kemunculan bersama dari e-book dan matriks kesamaan cosinus dari e-book. Karena dua matriks di atas secara komputasi besar dan semua data diperlukan untuk setiap perhitungan, itu diatur untuk dilakukan secara teratur oleh administrator.
Simbol → menunjukkan bahwa kelas adalah operasi manual modul reguler

Ada dua langkah utama untuk algoritma penyaringan kolaboratif berdasarkan item:
Misalkan n (i) adalah jumlah pengguna yang menyukai item i. N (i) ⋂n (j) mewakili jumlah pengguna yang menyukai item I item j pada saat yang sama. Kemudian kesamaan antara item I dan item J adalah:
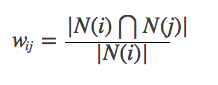
Namun, formula di atas memiliki cacat: ketika item j adalah produk yang sangat populer dan semua orang menyukainya, maka WIJ akan sangat dekat dengan 1, yaitu, formula di atas akan membuat banyak item memiliki kesamaan yang besar dengan produk populer, sehingga Anda dapat meningkatkan formula:
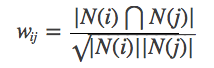
Buat daftar item pengguna terbalik (misalkan huruf besar mewakili pengguna, huruf kecil mewakili item):

Hitung matriks co-kejadian C (matriks co-kejadian C mewakili jumlah pengguna yang menyukai dua item pada saat yang sama, dan dihitung berdasarkan tabel inversi item pengguna):
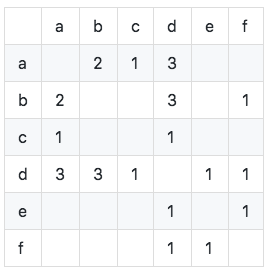
Seperti yang ditunjukkan pada gambar, kita dapat melihat bahwa elemen diagonal dari matriks co-kejadian semuanya 0 dan merupakan matriks jarang simetris nyata. Algoritma diimplementasikan sebagai berikut:
com.statistics.itemCollaborationFilter
/**
* 计算共现矩阵C
*/
private void computerMatrixC (){
// 建立用户物品倒排表
// 若用户对物品评分大于等于4则认为喜欢(出现)
List < User > allUser = userDao . queryAllUser ();
for ( int i = 0 ; i < allUser . size (); i ++){ // 遍历全部用户
// 获取一个用户的评分列表中>=4的评分记录
List < RatingList > likeList = ratingListDao . selectRatingListByUidAndRatingValue ( allUser . get ( i ). getUid (), 4 );
if ( likeList . size () <= 1 ){ // 若用户只喜欢一本或不喜欢任何图书
continue ;
}
for ( int j = 0 ; j < likeList . size (); j ++){ // 计算likeList中两两出现的图书并写入同现矩阵C
for ( int k = j + 1 ; k < likeList . size (); k ++){
int a = Integer . valueOf ( likeList . get ( j ). getEid ());
int b = Integer . valueOf ( likeList . get ( k ). getEid ());
// 生成key
String key = null ;
if ( a < b ){
key = a + "," + b ;
} else {
key = b + "," + a ;
}
// 检查key是否已经存在
if ( this . matrixC . get ( key ) != null ){
int value = this . matrixC . get ( key );
this . matrixC . put ( key , value + 1 );
} else {
this . matrixC . put ( key , 1 );
}
}
}
System . out . println ( "[" + df . format ( new Date ())+ "]" + "[已完成" + i + ",共" + allUser . size ()+ "]:用户uid=" + allUser . get ( i ). getUid ()+ "的记录以计算完成,共" + likeList . size ()+ "本图书" );
}
}Berapa kali setiap item muncul adalah:

Hitung matriks kesamaan kosinus W: matriks kesamaan cosinus dapat diperoleh dengan menggunakan rumus yang ditingkatkan.
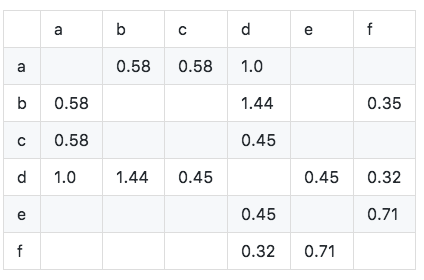
Algoritma diimplementasikan sebagai berikut:
com.statistics.itemCollaborationFilter
/**
* 计算余弦相似度矩阵W
* 计算方法:
* 使用矩阵C的每个value作为分子,key中的两个图书的喜欢人数的积开根号作为分母
*/
private Double computerMatrixW ( String eida , String eidb , int value ){
DecimalFormat df = new DecimalFormat ( "#.##" );
// 查询每个图书有多少人喜欢
try {
Statement statemenet = conn . createStatement ();
ResultSet rs = statemenet . executeQuery ( "select count(rid) from ratinglist where eid = '" + eida + "' and ratingValue >= 4;" );
rs . next ();
int likeANum = rs . getInt ( "count(rid)" );
rs = statemenet . executeQuery ( "select count(rid) from ratinglist where eid = '" + eidb + "' and ratingValue >= 4;" );
rs . next ();
int likeBNum = rs . getInt ( "count(rid)" );
if ( likeANum == 0 )
likeANum = 1 ;
if ( likeBNum == 0 )
likeBNum = 1 ;
// 开始计算
Double answer = value * 1.0 / Math . sqrt ( likeANum * likeBNum );
// 精确到小数点后两位
Double result = Double . parseDouble ( df . format ( answer ));
// 返回计算结果
return result ;
} catch ( SQLException e ) {
e . printStackTrace ();
}
return null ;
}Item apa yang pada akhirnya direkomendasikan ditentukan dengan memprediksi minat.
Item J memprediksi minat = minat item i yang pengguna suka × kesamaan antara item i dan item j.
Misalnya: Pengguna menyukai item A, B, dan c. Minat mereka masing -masing adalah 1, 2 dan 2. Kemudian kepentingan yang diprediksi item C, D, E, dan F adalah:
Oleh karena itu, item D harus direkomendasikan kepada pengguna. Algoritma diimplementasikan sebagai berikut:
@ Override
public List < EBook > userRecommendedList ( String uid ) {
// 获取用户喜爱图书列表
List < RatingList > likeList = this . ratingListDao . selectRatingListByUidAndRatingValue ( uid , 4 );
// debug
System . out . println ( "uid=" + uid + "用户喜爱图书列表" );
for ( RatingList r : likeList ){
System . out . println ( r . getEid ()+ "," + r . getRatingValue ());
}
System . out . println ( "likeList.size=" + likeList . size ());
// 定义计算用矩阵
List < Item > matrix = new ArrayList <>();
// 将用户喜爱的图书作为矩阵的列
// 将与用户喜爱的图书同现的图书作为矩阵的行
// 建立工作矩阵
for ( int i = 0 ; i < likeList . size (); i ++){ // 遍历用户喜爱的图书
RatingList temp = likeList . get ( i );
// 获取同现图书
List < MatrixC > itemList = this . matrixCDao . selectMatrixCByEidAOrEidB ( temp . getEid (), temp . getEid ());
for ( int j = 0 ; j < itemList . size (); j ++){
MatrixC c = itemList . get ( j );
// 从matrixC的key中选出同现图书的eid
String sEid = null ;
if ( c . getEida (). equals ( temp . getEid ())){
sEid = c . getEidb ();
} else {
sEid = c . getEida ();
}
// 在行中查询同现图书是否存在
if ( matrix . indexOf ( sEid ) == - 1 ){ // 若列中不存在
double [] col = new double [ likeList . size ()];
// 将同现图书所在行对应喜爱图书的数组值设为对应的余弦相似度*用户喜爱程度(4分为1,5分为2)
col [ likeList . indexOf ( temp )] = c . getCos_similarity ()*( temp . getRatingValue ()- 3 );
matrix . add ( new Item ( sEid , col )); // 增加行
} else { // 若列中存在
// 则将同现图书所在行对应喜爱图书的数组值设为对应的余弦相似度*用户喜爱程度(4分为1,5分为2)
matrix . get ( matrix . indexOf ( sEid )). col [ likeList . indexOf ( temp )] = c . getCos_similarity ()*( temp . getRatingValue ()- 3 );
}
}
}
// 计算预测兴趣度
for ( int i = 0 ; i < matrix . size (); i ++){
Item item = matrix . get ( i );
double interestValue = 0 ;
for ( int j = 0 ; j < item . col . length ; j ++){
interestValue += item . col [ j ];
}
matrix . get ( i ). interestValue = interestValue ;
}
// 根据预测兴趣度进行排序
Collections . sort ( matrix );
// 返回推荐图书列表
List < EBook > resultList = new ArrayList <>();
for ( int i = 0 ; i < matrix . size () && i < 20 ; i ++){ // 返回排前10的书
if ( matrix . get ( i ). interestValue > 0 ){
EBook eBook = this . eBookDao . queryEBookByEid ( matrix . get ( i ). eid );
resultList . add ( eBook );
// debug
System . out . println ( matrix . get ( i ). eid + "," + eBook . getEname ()+ ",interestValue=" + matrix . get ( i ). interestValue );
}
}
return EBookServiceImpl . initEBookImgAddress ( resultList );
}Modul yang direkomendasikan menggunakan data yang dirangkak oleh crawler sebagai input untuk mengeluarkan hasil perhitungan ke dalam tabel matriks. Seluruh proses perhitungan dibagi menjadi 2 tahap. Tahap pertama menghitung matriks kemunculan bersama C. Tahap kedua menghitung kesamaan kosinus dengan e-book yang muncul berpasangan. Untuk fungsi yang disarankan berdasarkan minat yang diprediksi pengguna, karena pengguna menyukai jumlah waktu real-time dan total data e-book terlalu besar, pengguna akan menggunakan perhitungan waktu-nyata saat mengakses halaman. Setelah beberapa tes, rata -rata waktu tunggu pengguna berada dalam kisaran yang dapat diterima.
Karena upgrade halaman web film Douban telah menambahkan langkah-langkah anti-crawling, data yang digunakan untuk menjalankan algoritma yang disarankan disediakan di sini.


