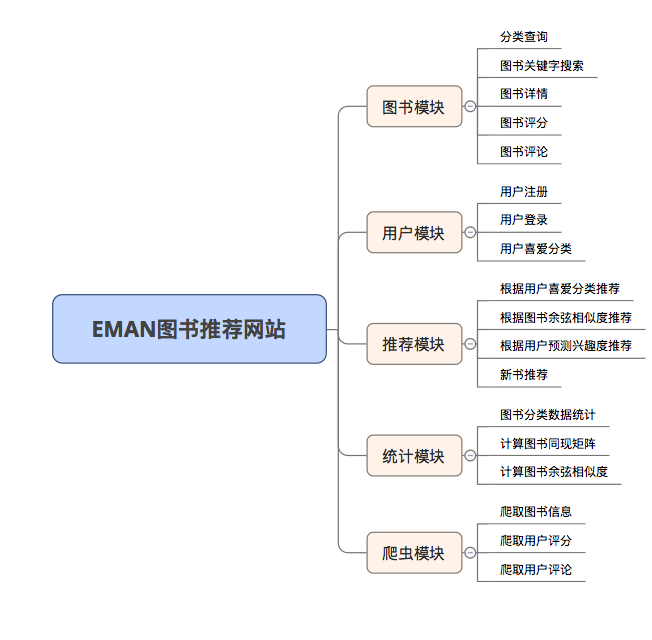
EMAN
1.0.0
一個基於SSM框架與物品的協同過濾算法(ItemCF)的簡單電子書推薦系統
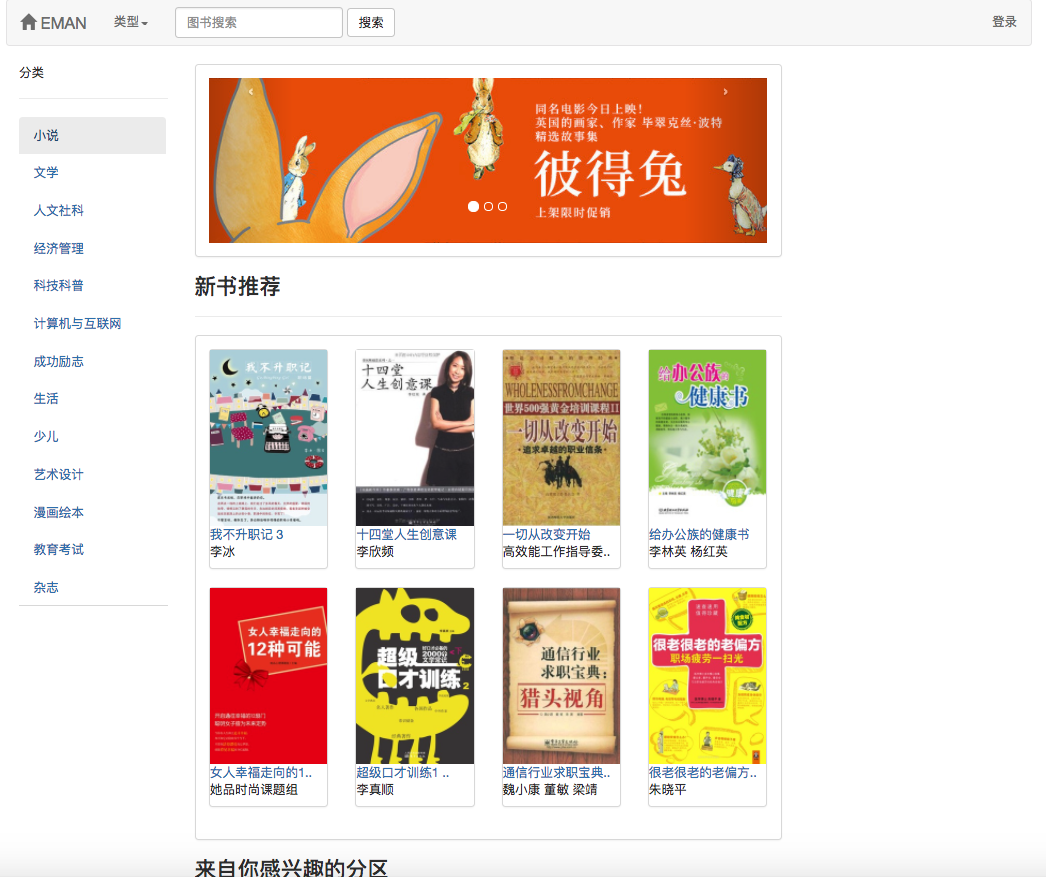
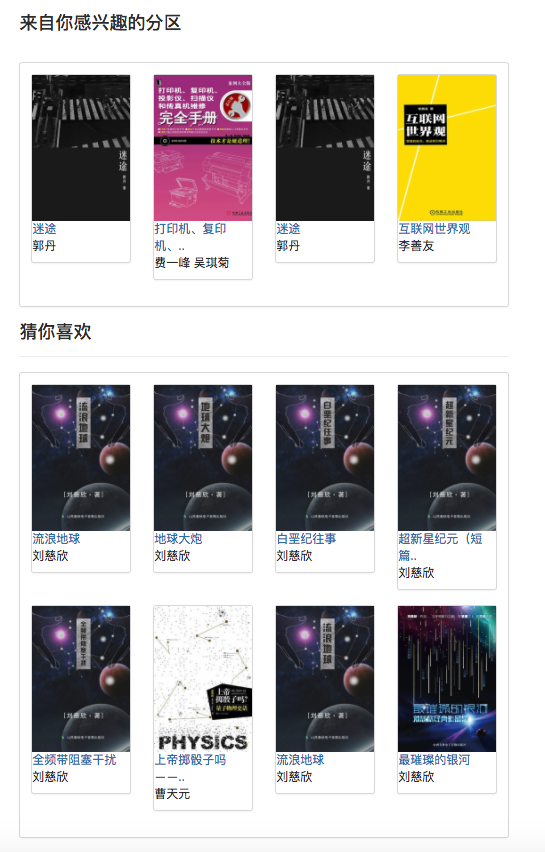
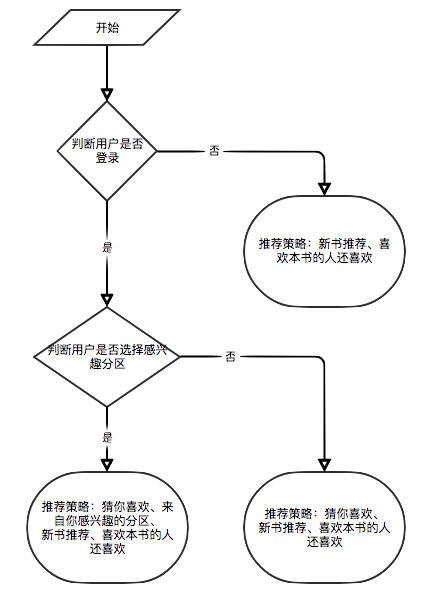
因部分推薦算法需要使用用戶的喜愛數據作為參數。若用戶未登錄就採用對遊客的推薦策略。若用戶已登錄就採用對登錄用戶的推薦策略。其中若登錄用戶在數據庫中存在感興趣的分區記錄的話就會增加一個來自你感興趣的分區的推薦。 所以將推薦策略分為是否登錄兩種情況進行區別。
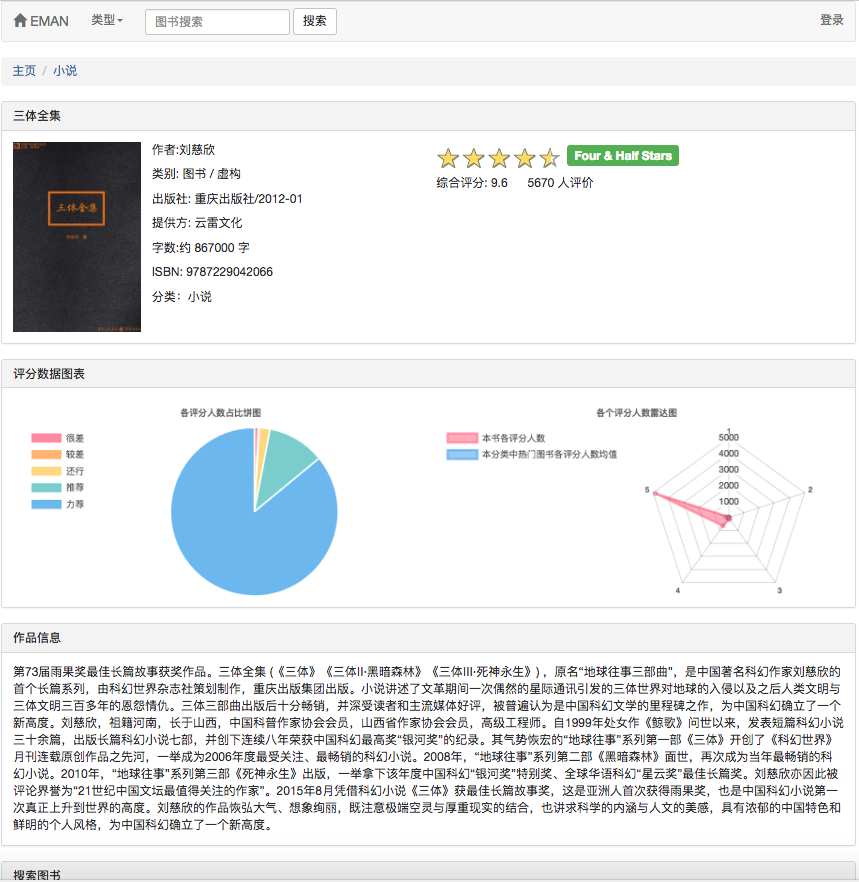
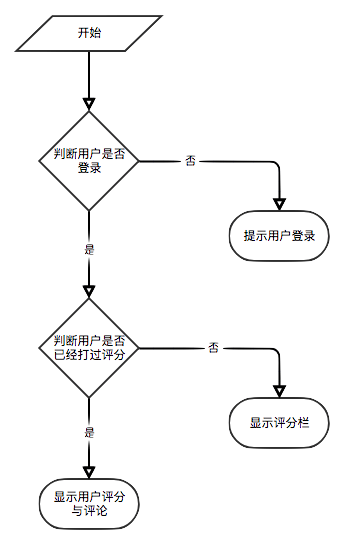
若用戶未登錄就採用對遊客的用戶評分顯示策略。若用戶已登錄就採用對登錄用戶的用戶評分顯示策略。其中若登錄用戶已經對當前詳情頁的電子書進行過評分,則顯示其評分記錄。
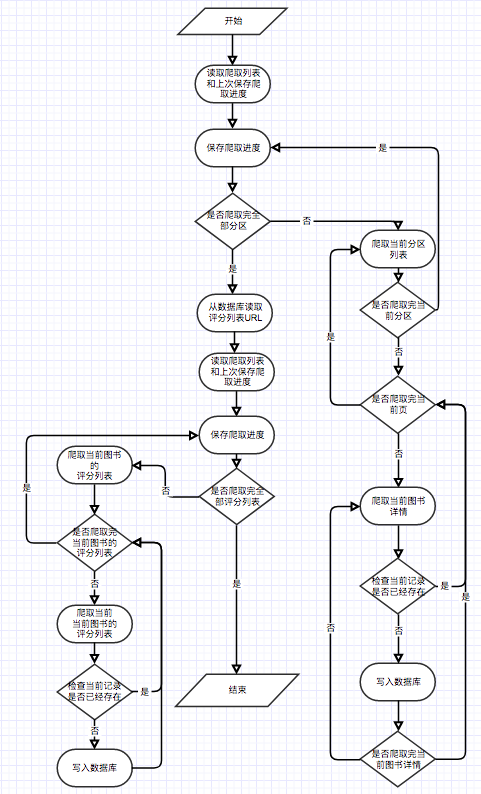
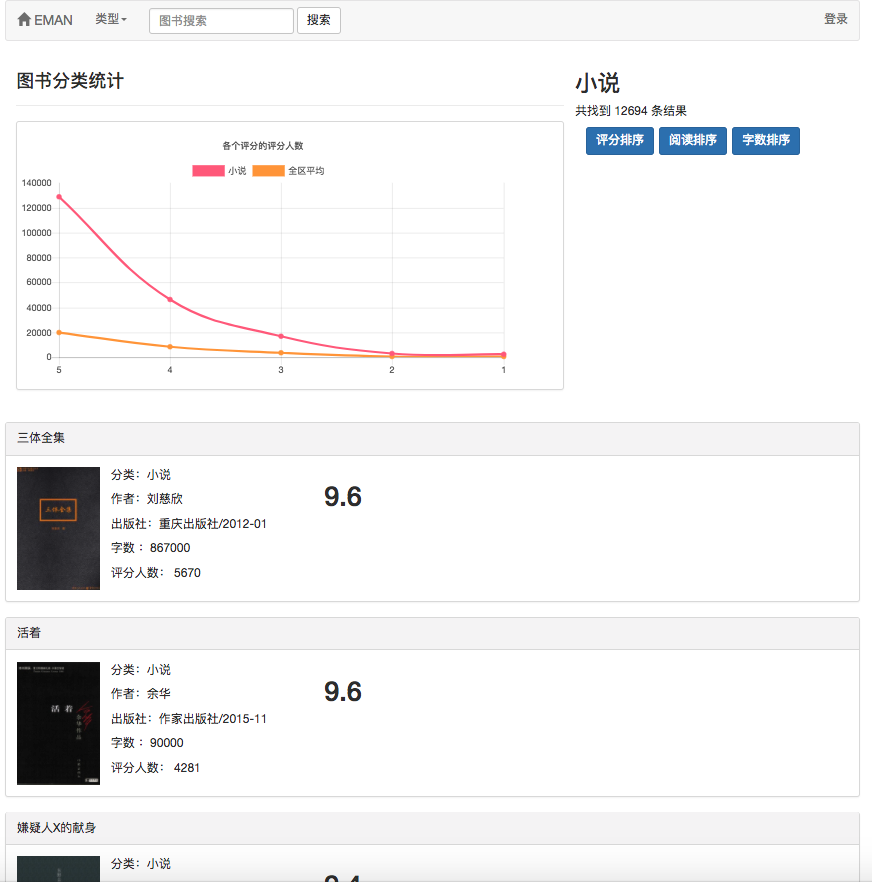
如用例圖所示,本系統中的基本用戶分為3 種。分別是遊客、註冊用戶、管理員。 遊客可以訪問電子書推薦平台的首頁、用戶註冊頁面、查看電子書頁面。註冊用戶比遊客多的功能在於可以對電子書進行評分與評論和由該用戶預測興趣度決定的電子書推薦。而管理員則可以定期使用爬蟲模塊來更新電子書信息和使用統計模塊更新分類統計信息、電子書同現矩陣和電子書餘弦相似度矩陣。

考慮到該算法存在冷啟動問題。即對於新用戶往往缺少評分數據從而導致根據用戶預測興趣度來進行推薦不能順利進行。為解決該問題,我增加了使用餘弦相似度矩陣w 來直接進行相似電子書推薦的模塊,方便未註冊用戶與新用戶更好的獲得推薦。而對於協同過濾算法存在的數據矩陣稀疏問題,即可能存在部分冷門電子書沒有用戶評分、電子書關聯度不高、部分用戶對電子書評分少等情況。為解決該問題,在首頁上增加新書推薦模塊來更好的推薦沒有人評分的電子書;在首頁上增加根據用戶選擇感興趣的分區推薦模塊以增加對具體的用戶的興趣來推薦電子書的擬合度。 值得注意的是,用戶預測興趣度推薦的電子書是在該算法所計算出來的餘弦相似度矩陣W 上使用公式計算而來。並且在計算的時候還需要用戶喜愛的電子書作為輸入參數。 而相似電子書推薦則是直接使用弦相似度矩陣W 進行統計。這就意味著以上兩個推薦需要先完成電子書同現矩陣和電子書餘弦相似度矩陣的計算才可以進行。因為以上兩個矩陣計算量較大且每次計算都需要使用全部數據進行計算,所以在此設置成由管理員定期來執行。
符號→ 表示該類為定期手動運行模塊

基於物品的協同過濾算法主要有兩步:
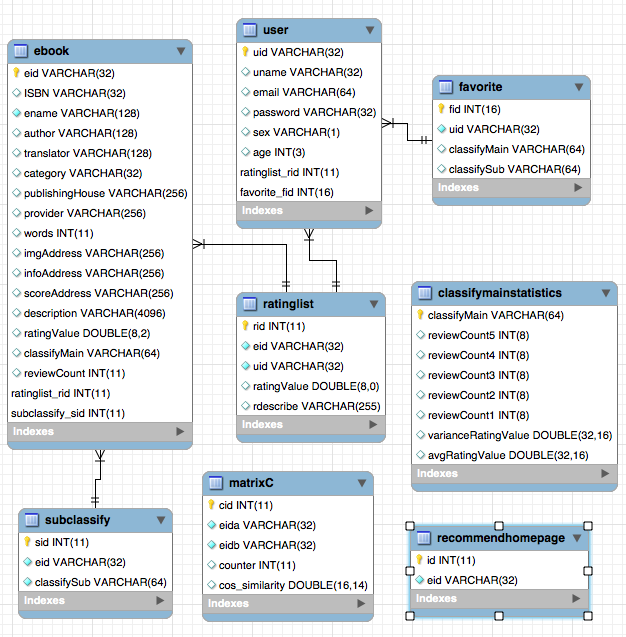
設N(i)是表示喜歡物品i 的用戶數。 N(i)⋂N(j)表示同時喜歡物品i 物品j 的用戶數。則物品i 與物品j 的相似度為:
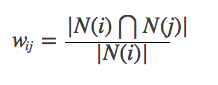
但是上式有一個缺陷:當物品j 是一個很熱門的商品時,人人都喜歡,那麼wij 就會很接近於1,即上式會讓很多物品都和熱門商品有一個很大的相似度,所以可以改進一下公式:
建立用戶物品倒排表(設用大寫字母表示用戶,小寫字母表示物品):

計算共現矩陣C(共現矩陣C 表示同時喜歡兩個物品的用戶數,是根據用戶物品倒排表計算出來的):
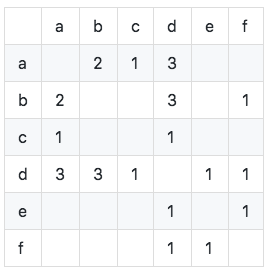
如圖可知共現矩陣的對角線元素全為0,且是實對稱稀疏矩陣。 算法實現如下:
com.statistics.ItemCollaborationFilter
/**
* 计算共现矩阵C
*/
private void computerMatrixC (){
// 建立用户物品倒排表
// 若用户对物品评分大于等于4则认为喜欢(出现)
List < User > allUser = userDao . queryAllUser ();
for ( int i = 0 ; i < allUser . size (); i ++){ // 遍历全部用户
// 获取一个用户的评分列表中>=4的评分记录
List < RatingList > likeList = ratingListDao . selectRatingListByUidAndRatingValue ( allUser . get ( i ). getUid (), 4 );
if ( likeList . size () <= 1 ){ // 若用户只喜欢一本或不喜欢任何图书
continue ;
}
for ( int j = 0 ; j < likeList . size (); j ++){ // 计算likeList中两两出现的图书并写入同现矩阵C
for ( int k = j + 1 ; k < likeList . size (); k ++){
int a = Integer . valueOf ( likeList . get ( j ). getEid ());
int b = Integer . valueOf ( likeList . get ( k ). getEid ());
// 生成key
String key = null ;
if ( a < b ){
key = a + "," + b ;
} else {
key = b + "," + a ;
}
// 检查key是否已经存在
if ( this . matrixC . get ( key ) != null ){
int value = this . matrixC . get ( key );
this . matrixC . put ( key , value + 1 );
} else {
this . matrixC . put ( key , 1 );
}
}
}
System . out . println ( "[" + df . format ( new Date ())+ "]" + "[已完成" + i + ",共" + allUser . size ()+ "]:用户uid=" + allUser . get ( i ). getUid ()+ "的记录以计算完成,共" + likeList . size ()+ "本图书" );
}
}統計可得每個物品出現的次數為:

計算餘弦相似度矩陣W:使用改進後的公式計算可得餘弦相似度矩陣。
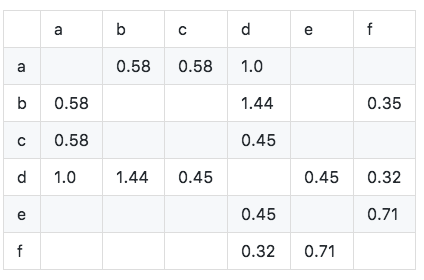
算法實現如下:
com.statistics.ItemCollaborationFilter
/**
* 计算余弦相似度矩阵W
* 计算方法:
* 使用矩阵C的每个value作为分子,key中的两个图书的喜欢人数的积开根号作为分母
*/
private Double computerMatrixW ( String eida , String eidb , int value ){
DecimalFormat df = new DecimalFormat ( "#.##" );
// 查询每个图书有多少人喜欢
try {
Statement statemenet = conn . createStatement ();
ResultSet rs = statemenet . executeQuery ( "select count(rid) from ratinglist where eid = '" + eida + "' and ratingValue >= 4;" );
rs . next ();
int likeANum = rs . getInt ( "count(rid)" );
rs = statemenet . executeQuery ( "select count(rid) from ratinglist where eid = '" + eidb + "' and ratingValue >= 4;" );
rs . next ();
int likeBNum = rs . getInt ( "count(rid)" );
if ( likeANum == 0 )
likeANum = 1 ;
if ( likeBNum == 0 )
likeBNum = 1 ;
// 开始计算
Double answer = value * 1.0 / Math . sqrt ( likeANum * likeBNum );
// 精确到小数点后两位
Double result = Double . parseDouble ( df . format ( answer ));
// 返回计算结果
return result ;
} catch ( SQLException e ) {
e . printStackTrace ();
}
return null ;
}最終推薦的是什麼物品,是由預測興趣度決定的。
物品j預測興趣度= 用戶喜歡的物品i的興趣度× 物品i和物品j的相似度。
例如:某個用戶喜歡物品a、b 和c。對其興趣度分別為1、2、2。那麼物品c、d、e、 f 的預測興趣度分別為:
所以應當向該用戶推薦物品d。 算法實現如下:
@ Override
public List < EBook > userRecommendedList ( String uid ) {
// 获取用户喜爱图书列表
List < RatingList > likeList = this . ratingListDao . selectRatingListByUidAndRatingValue ( uid , 4 );
// debug
System . out . println ( "uid=" + uid + "用户喜爱图书列表" );
for ( RatingList r : likeList ){
System . out . println ( r . getEid ()+ "," + r . getRatingValue ());
}
System . out . println ( "likeList.size=" + likeList . size ());
// 定义计算用矩阵
List < Item > matrix = new ArrayList <>();
// 将用户喜爱的图书作为矩阵的列
// 将与用户喜爱的图书同现的图书作为矩阵的行
// 建立工作矩阵
for ( int i = 0 ; i < likeList . size (); i ++){ // 遍历用户喜爱的图书
RatingList temp = likeList . get ( i );
// 获取同现图书
List < MatrixC > itemList = this . matrixCDao . selectMatrixCByEidAOrEidB ( temp . getEid (), temp . getEid ());
for ( int j = 0 ; j < itemList . size (); j ++){
MatrixC c = itemList . get ( j );
// 从matrixC的key中选出同现图书的eid
String sEid = null ;
if ( c . getEida (). equals ( temp . getEid ())){
sEid = c . getEidb ();
} else {
sEid = c . getEida ();
}
// 在行中查询同现图书是否存在
if ( matrix . indexOf ( sEid ) == - 1 ){ // 若列中不存在
double [] col = new double [ likeList . size ()];
// 将同现图书所在行对应喜爱图书的数组值设为对应的余弦相似度*用户喜爱程度(4分为1,5分为2)
col [ likeList . indexOf ( temp )] = c . getCos_similarity ()*( temp . getRatingValue ()- 3 );
matrix . add ( new Item ( sEid , col )); // 增加行
} else { // 若列中存在
// 则将同现图书所在行对应喜爱图书的数组值设为对应的余弦相似度*用户喜爱程度(4分为1,5分为2)
matrix . get ( matrix . indexOf ( sEid )). col [ likeList . indexOf ( temp )] = c . getCos_similarity ()*( temp . getRatingValue ()- 3 );
}
}
}
// 计算预测兴趣度
for ( int i = 0 ; i < matrix . size (); i ++){
Item item = matrix . get ( i );
double interestValue = 0 ;
for ( int j = 0 ; j < item . col . length ; j ++){
interestValue += item . col [ j ];
}
matrix . get ( i ). interestValue = interestValue ;
}
// 根据预测兴趣度进行排序
Collections . sort ( matrix );
// 返回推荐图书列表
List < EBook > resultList = new ArrayList <>();
for ( int i = 0 ; i < matrix . size () && i < 20 ; i ++){ // 返回排前10的书
if ( matrix . get ( i ). interestValue > 0 ){
EBook eBook = this . eBookDao . queryEBookByEid ( matrix . get ( i ). eid );
resultList . add ( eBook );
// debug
System . out . println ( matrix . get ( i ). eid + "," + eBook . getEname ()+ ",interestValue=" + matrix . get ( i ). interestValue );
}
}
return EBookServiceImpl . initEBookImgAddress ( resultList );
}推薦模塊使用爬蟲爬取的數據作為輸入,將計算結果輸出到matrixC 表中。整個計算過程分為2 個階段來進行。第一階段計算出共現矩陣C。第二階段計算出兩兩出現的電子書的餘弦相似度w。而對於根據用戶預測興趣度來推薦這一功能因為用戶喜愛電子書數據的實時性和總計算量太大,則採用用戶在訪問頁面時實時進行計算。經過多次測試,用戶平均等待時間在可以接受的範圍。
因為豆瓣電影網頁升級加入反爬措施,所以在此提供用於運行推薦算法的數據


