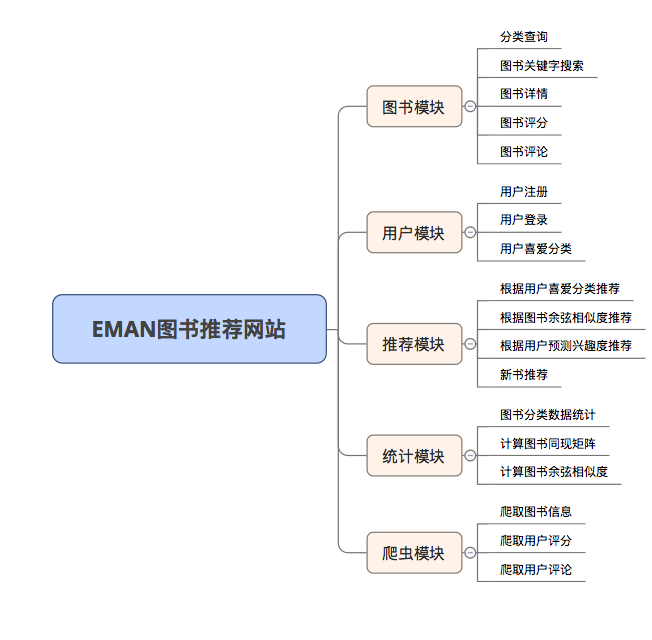
EMAN
1.0.0
Ein einfaches E-Book-Empfehlungssystem basierend auf dem SSM-Framework- und Element Collaborative Filtering Algorithmus (ItemCF)
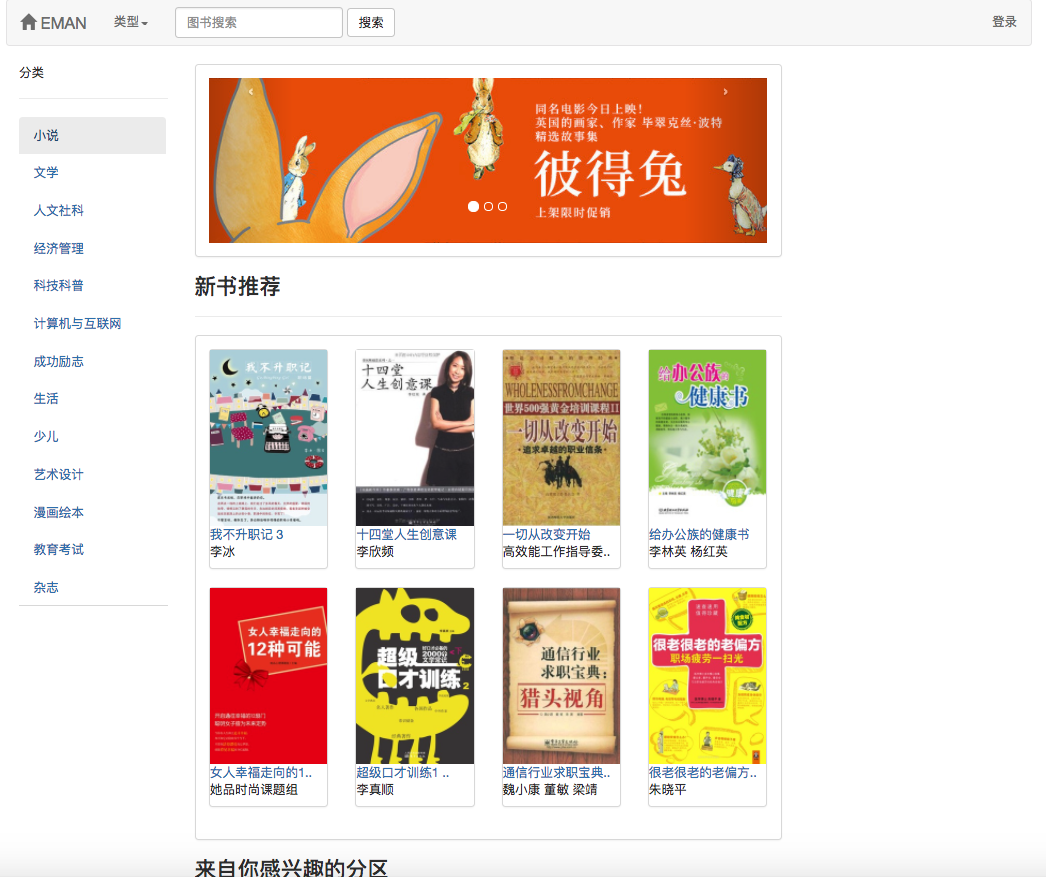
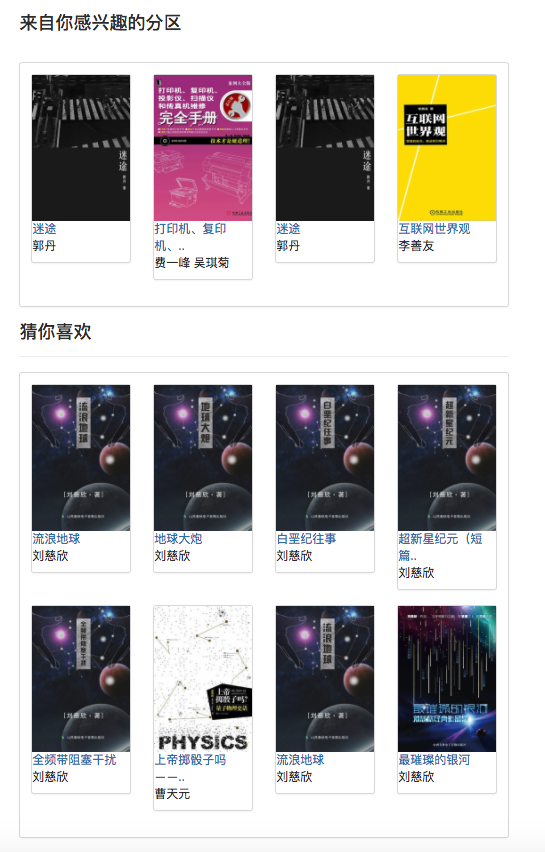
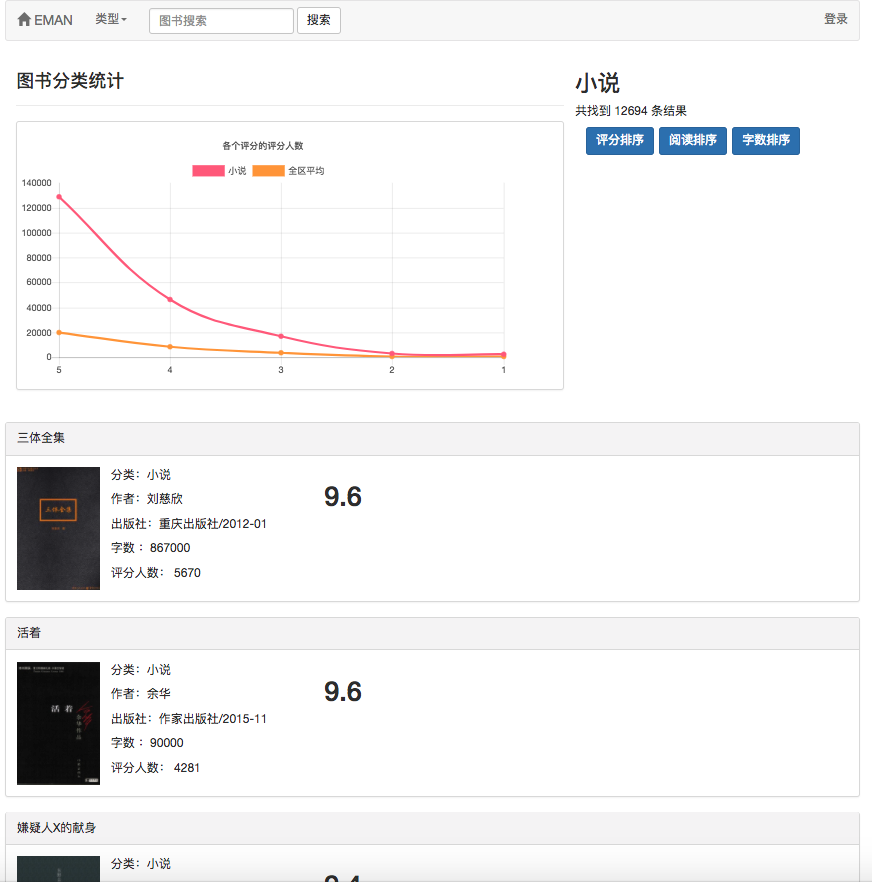
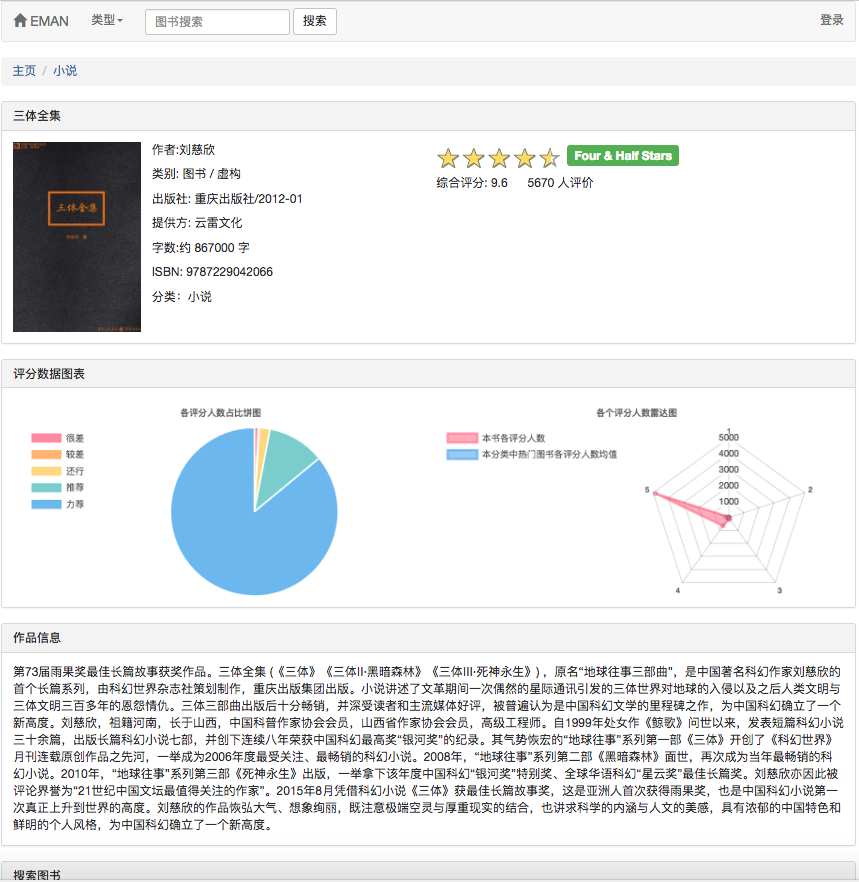
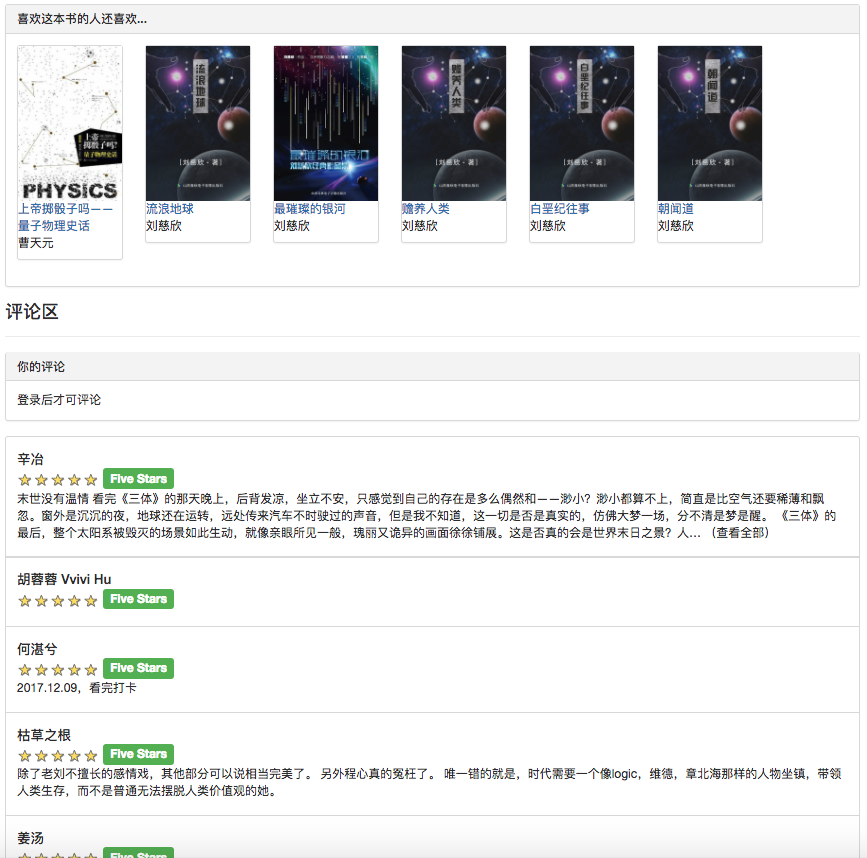
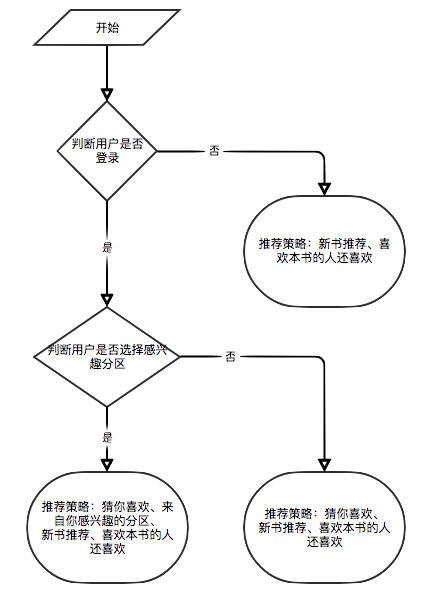
Da einige Empfehlungsalgorithmen die bevorzugten Daten des Benutzers als Parameter verwenden müssen. Wenn der Benutzer nicht angemeldet ist, wird die Empfehlungsstrategie für Touristen übernommen. Wenn der Benutzer angemeldet ist, wird die Empfehlungsrichtlinie für den angemeldeten Benutzer übernommen. Wenn der angemeldete Benutzer einen Interesse an der Datenbank hat, wird eine Empfehlung von der Partition, an der Sie interessiert sind, hinzugefügt. Daher ist die Empfehlungsstrategie in zwei Situationen unterteilt: ob Sie sich anmelden oder nicht.
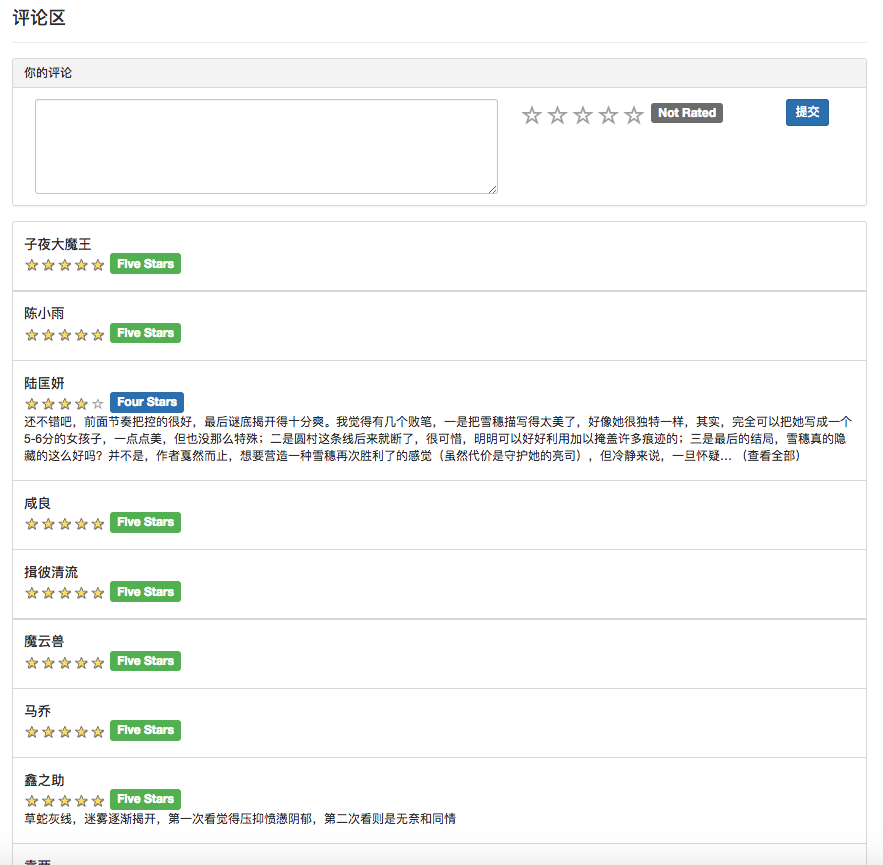
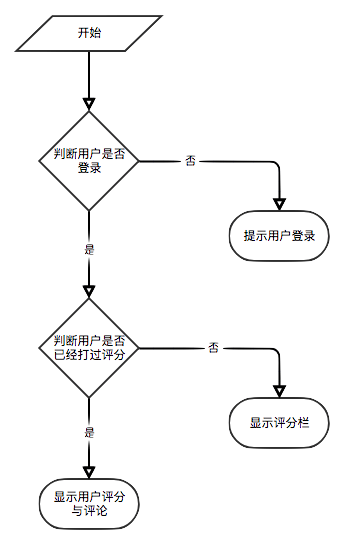
Wenn der Benutzer nicht angemeldet ist, wird die Strategie zur Bewertung der Benutzerbewertung für Touristen übernommen. Wenn der Benutzer angemeldet ist, wird die Benutzerbewertungsanzeige für den angemeldeten Benutzer angegeben. Wenn der angemeldete Benutzer das E-Book bereits auf der aktuellen Detail-Seite bewertet hat, wird der Bewertungsdatensatz angezeigt.
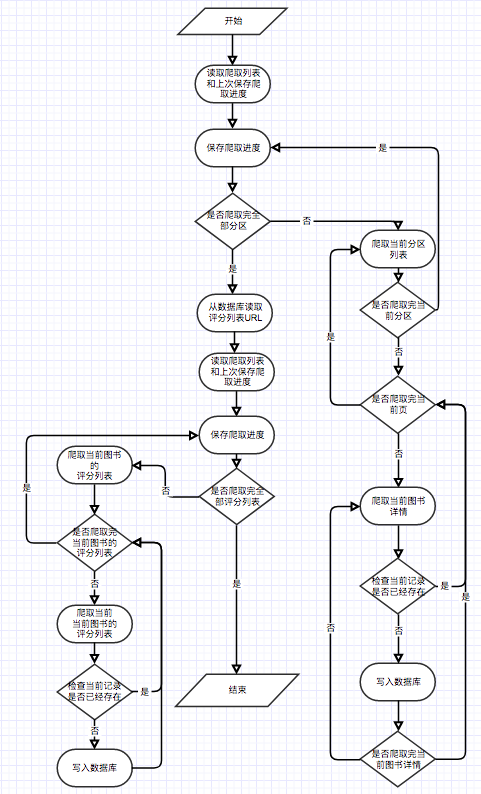
Wie im Anwendungsfalldiagramm gezeigt, gibt es in diesem System drei grundlegende Benutzer. Dies sind Touristen, registrierte Benutzer und Administratoren. Besucher können die Homepage der E-Book-Empfehlungsplattform und die Benutzerregistrierungsseite besuchen und die E-Book-Seite anzeigen. Die Funktion der Registrierung von Benutzern besteht darin, dass sie E-Books bewerten und kommentieren können und E-Books empfehlen können, die durch das vorhergesagte Interesse des Benutzers bestimmt werden. Administratoren können das Crawler-Modul regelmäßig verwenden, um E-Book-Informationen zu aktualisieren und das Statistikmodul zu aktualisieren, um klassifizierte Statistiken, E-Book-Co-Auftreten-Matrix und E-Book-Cosinus-Ähnlichkeitsmatrix zu aktualisieren.
! [User Case.png] (/IMG/Benutzer case.png)
In Anbetracht der Tatsache, dass es ein kaltes Startproblem mit diesem Algorithmus gibt. Das heißt, für neue Benutzer fehlen ihnen häufig Bewertungsdaten, was zu der Empfehlung auf der Grundlage des vorhergesagten Interessenniveaus des Benutzers führt und nicht reibungslos durchgeführt werden kann. Um dieses Problem zu lösen, habe ich ein Modul hinzugefügt, um die Cosinus-Ähnlichkeitsmatrix W direkt zu verwenden, um ähnliche E-Book-Empfehlungen direkt durchzuführen, damit nicht registrierte Benutzer und neue Benutzer besser Empfehlungen erhalten können. In Bezug auf die Probleme mit spärlichen Datenmatrix bei kollaborativen Filteralgorithmen haben einige unpopuläre E-Books möglicherweise keine Benutzerbewertungen, eine geringe E-Book-Korrelation und einige Benutzer haben nur wenige E-Book-Bewertungen. Um dieses Problem zu lösen, fügen Sie der Homepage ein neues Buchempfehlungsmodul hinzu, um E-Books, die keine Bewertung haben, besser zu empfehlen. Fügen Sie ein Partitionsempfehlungsmodul hinzu, um E-Books basierend auf dem Interesse des Benutzers zu empfehlen, um das Interesse bestimmter Benutzer für die Empfehlung von E-Books zu erhöhen. Es ist erwähnenswert, dass das von den Benutzern empfohlene E-Book, das zur Vorhersage von Interesse empfohlen wird, unter Verwendung von Formeln auf der Kosinus-Ähnlichkeitsmatrix W berechnet wird, die durch diesen Algorithmus berechnet wurde. Darüber hinaus ist das bevorzugte E-Book des Benutzers als Eingabeparameter während der Berechnung erforderlich. Das empfohlene ähnliche E-Book besteht darin, die String-Ähnlichkeitsmatrix W für Statistiken direkt zu verwenden. Dies bedeutet, dass die beiden oben genannten Empfehlungen die Berechnung der Co-Auftreten-Matrix des E-Books und der Cosinus-Ähnlichkeitsmatrix des E-Books abschließen müssen. Da die beiden oben genannten Matrizen rechnerisch groß sind und alle Daten für jede Berechnung erforderlich sind, wird sie vom Administrator regelmäßig durchgeführt.
Symbol → Zeigt an, dass die Klasse ein regelmäßiger manueller Betrieb von Modulen ist

Es gibt zwei Hauptschritte für den kollaborativen Filteralgorithmus basierend auf Elementen:
Angenommen, N (i) ist die Anzahl der Benutzer, die Item I mögen. N (i) ⋂n (j) repräsentiert die Anzahl der Benutzer, die gleichzeitig Element I Element J mögen. Dann ist die Ähnlichkeit zwischen Artikel I und Gegenstand J:
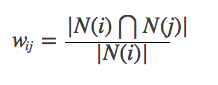
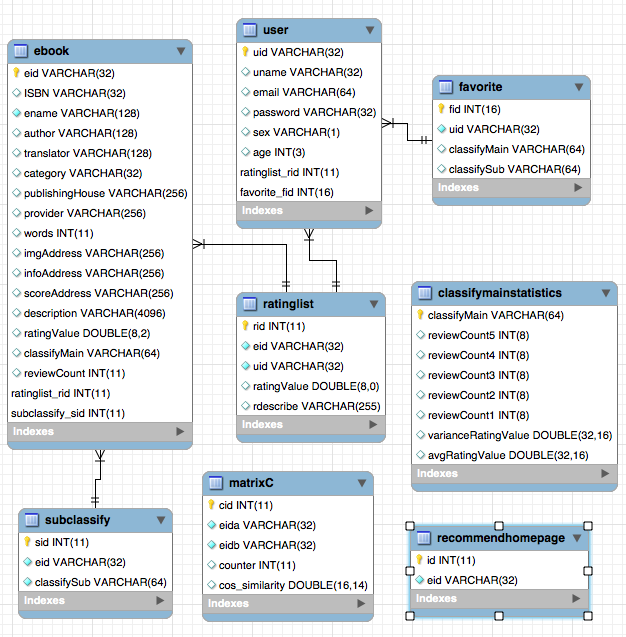
Die obige Formel hat jedoch einen Defekt: Wenn Gegenstand J ein sehr beliebtes Produkt ist und jeder es mag, wird Wij sehr nahe bei 1 sein. Die obige Formel wird viele Gegenstände zu einer großen Ähnlichkeit mit beliebten Produkten haben, sodass Sie die Formel verbessern können:
Erstellen Sie eine Liste der invertierten Benutzerelemente (Angenommen, Großbuchstaben vertreten Benutzer, Kleinbuchstaben dar, die Elemente darstellen):

Berechnen Sie die Co-Auftreten-Matrix C (die Co-Auftreten-Matrix C repräsentiert die Anzahl der Benutzer, die zwei Elemente gleichzeitig mögen, und wird basierend auf der Inversionstabelle der Benutzerelemente berechnet):
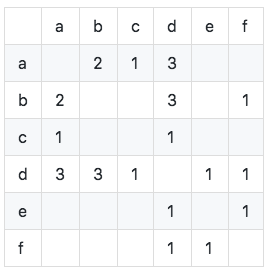
Wie in der Abbildung gezeigt, können wir sehen, dass die diagonalen Elemente der Co-Auftreten-Matrix alle 0 sind und echte symmetrische spärliche Matrizen sind. Der Algorithmus wird wie folgt implementiert:
com.statistics.itemcollaborationFilter
/**
* 计算共现矩阵C
*/
private void computerMatrixC (){
// 建立用户物品倒排表
// 若用户对物品评分大于等于4则认为喜欢(出现)
List < User > allUser = userDao . queryAllUser ();
for ( int i = 0 ; i < allUser . size (); i ++){ // 遍历全部用户
// 获取一个用户的评分列表中>=4的评分记录
List < RatingList > likeList = ratingListDao . selectRatingListByUidAndRatingValue ( allUser . get ( i ). getUid (), 4 );
if ( likeList . size () <= 1 ){ // 若用户只喜欢一本或不喜欢任何图书
continue ;
}
for ( int j = 0 ; j < likeList . size (); j ++){ // 计算likeList中两两出现的图书并写入同现矩阵C
for ( int k = j + 1 ; k < likeList . size (); k ++){
int a = Integer . valueOf ( likeList . get ( j ). getEid ());
int b = Integer . valueOf ( likeList . get ( k ). getEid ());
// 生成key
String key = null ;
if ( a < b ){
key = a + "," + b ;
} else {
key = b + "," + a ;
}
// 检查key是否已经存在
if ( this . matrixC . get ( key ) != null ){
int value = this . matrixC . get ( key );
this . matrixC . put ( key , value + 1 );
} else {
this . matrixC . put ( key , 1 );
}
}
}
System . out . println ( "[" + df . format ( new Date ())+ "]" + "[已完成" + i + ",共" + allUser . size ()+ "]:用户uid=" + allUser . get ( i ). getUid ()+ "的记录以计算完成,共" + likeList . size ()+ "本图书" );
}
}Die Häufigkeit, mit der jedes Element angezeigt wird, ist:

Berechnen Sie die Kosinus -Ähnlichkeitsmatrix W: Die Kosinus -Ähnlichkeitsmatrix kann unter Verwendung der verbesserten Formel erhalten werden.
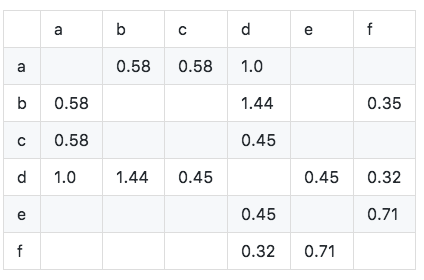
Der Algorithmus wird wie folgt implementiert:
com.statistics.itemcollaborationFilter
/**
* 计算余弦相似度矩阵W
* 计算方法:
* 使用矩阵C的每个value作为分子,key中的两个图书的喜欢人数的积开根号作为分母
*/
private Double computerMatrixW ( String eida , String eidb , int value ){
DecimalFormat df = new DecimalFormat ( "#.##" );
// 查询每个图书有多少人喜欢
try {
Statement statemenet = conn . createStatement ();
ResultSet rs = statemenet . executeQuery ( "select count(rid) from ratinglist where eid = '" + eida + "' and ratingValue >= 4;" );
rs . next ();
int likeANum = rs . getInt ( "count(rid)" );
rs = statemenet . executeQuery ( "select count(rid) from ratinglist where eid = '" + eidb + "' and ratingValue >= 4;" );
rs . next ();
int likeBNum = rs . getInt ( "count(rid)" );
if ( likeANum == 0 )
likeANum = 1 ;
if ( likeBNum == 0 )
likeBNum = 1 ;
// 开始计算
Double answer = value * 1.0 / Math . sqrt ( likeANum * likeBNum );
// 精确到小数点后两位
Double result = Double . parseDouble ( df . format ( answer ));
// 返回计算结果
return result ;
} catch ( SQLException e ) {
e . printStackTrace ();
}
return null ;
}Welcher Artikel letztendlich empfohlen wird, wird durch Vorhersage von Interesse bestimmt.
Punkt J sagt Interesse voraus = Interesse von Punkt I, dass der Benutzer × Ähnlichkeit zwischen Punkt I und Punkt J mag.
Zum Beispiel: Ein Benutzer mag die Elemente A, B und c. Ihr Interesse beträgt 1, 2 bzw. 2. Dann sind das vorhergesagte Interesse der Punkte C, D, E und F:
Daher sollte Element D dem Benutzer empfohlen werden. Der Algorithmus wird wie folgt implementiert:
@ Override
public List < EBook > userRecommendedList ( String uid ) {
// 获取用户喜爱图书列表
List < RatingList > likeList = this . ratingListDao . selectRatingListByUidAndRatingValue ( uid , 4 );
// debug
System . out . println ( "uid=" + uid + "用户喜爱图书列表" );
for ( RatingList r : likeList ){
System . out . println ( r . getEid ()+ "," + r . getRatingValue ());
}
System . out . println ( "likeList.size=" + likeList . size ());
// 定义计算用矩阵
List < Item > matrix = new ArrayList <>();
// 将用户喜爱的图书作为矩阵的列
// 将与用户喜爱的图书同现的图书作为矩阵的行
// 建立工作矩阵
for ( int i = 0 ; i < likeList . size (); i ++){ // 遍历用户喜爱的图书
RatingList temp = likeList . get ( i );
// 获取同现图书
List < MatrixC > itemList = this . matrixCDao . selectMatrixCByEidAOrEidB ( temp . getEid (), temp . getEid ());
for ( int j = 0 ; j < itemList . size (); j ++){
MatrixC c = itemList . get ( j );
// 从matrixC的key中选出同现图书的eid
String sEid = null ;
if ( c . getEida (). equals ( temp . getEid ())){
sEid = c . getEidb ();
} else {
sEid = c . getEida ();
}
// 在行中查询同现图书是否存在
if ( matrix . indexOf ( sEid ) == - 1 ){ // 若列中不存在
double [] col = new double [ likeList . size ()];
// 将同现图书所在行对应喜爱图书的数组值设为对应的余弦相似度*用户喜爱程度(4分为1,5分为2)
col [ likeList . indexOf ( temp )] = c . getCos_similarity ()*( temp . getRatingValue ()- 3 );
matrix . add ( new Item ( sEid , col )); // 增加行
} else { // 若列中存在
// 则将同现图书所在行对应喜爱图书的数组值设为对应的余弦相似度*用户喜爱程度(4分为1,5分为2)
matrix . get ( matrix . indexOf ( sEid )). col [ likeList . indexOf ( temp )] = c . getCos_similarity ()*( temp . getRatingValue ()- 3 );
}
}
}
// 计算预测兴趣度
for ( int i = 0 ; i < matrix . size (); i ++){
Item item = matrix . get ( i );
double interestValue = 0 ;
for ( int j = 0 ; j < item . col . length ; j ++){
interestValue += item . col [ j ];
}
matrix . get ( i ). interestValue = interestValue ;
}
// 根据预测兴趣度进行排序
Collections . sort ( matrix );
// 返回推荐图书列表
List < EBook > resultList = new ArrayList <>();
for ( int i = 0 ; i < matrix . size () && i < 20 ; i ++){ // 返回排前10的书
if ( matrix . get ( i ). interestValue > 0 ){
EBook eBook = this . eBookDao . queryEBookByEid ( matrix . get ( i ). eid );
resultList . add ( eBook );
// debug
System . out . println ( matrix . get ( i ). eid + "," + eBook . getEname ()+ ",interestValue=" + matrix . get ( i ). interestValue );
}
}
return EBookServiceImpl . initEBookImgAddress ( resultList );
}Das empfohlene Modul verwendet die vom Crawler krabbelten Daten als Eingabe, um die Berechnungsergebnisse in die Matrixc -Tabelle auszugeben. Der gesamte Berechnungsprozess ist in 2 Stufen unterteilt. Die erste Stufe berechnet die Co-Auftreten-Matrix C. Die zweite Stufe berechnet die Kosinus-Ähnlichkeit w der E-Books, die paarweise erscheinen. Für die empfohlene Funktion basierend auf dem benutzer vorhergesagten Interessen, da der Benutzer die Echtzeit- und Gesamtberechnung der E-Book-Daten zu groß ist, verwendet der Benutzer bei der Zugriff auf die Seite Echtzeitberechnungen. Nach mehreren Tests liegt die durchschnittliche Wartezeit des Benutzers in einem akzeptablen Bereich.
Da das Doppel-Upgrade von Douban Movie Web Page zu Anti-Crawling-Maßnahmen hinzugefügt wurde, werden hier Daten zur Ausführung des empfohlenen Algorithmus bereitgestellt.


