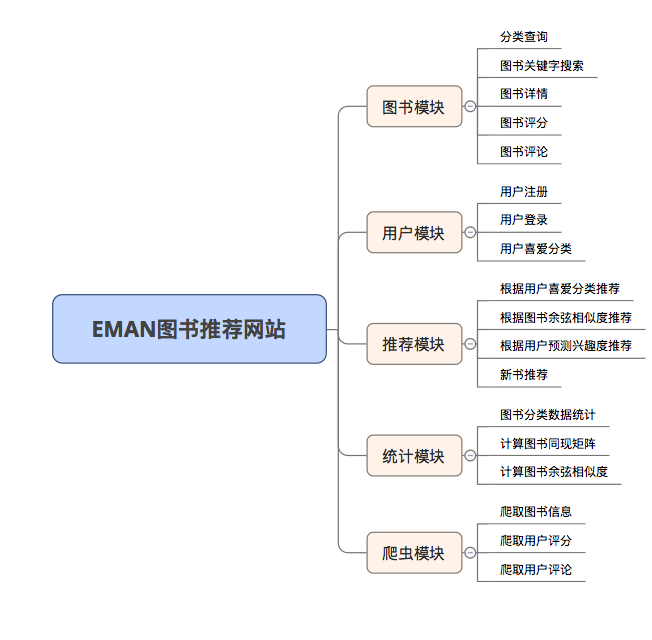
EMAN
1.0.0
Un sistema de recomendación de libro electrónico simple basado en el marco SSM y el algoritmo de filtrado colaborativo de elementos (itemCF)
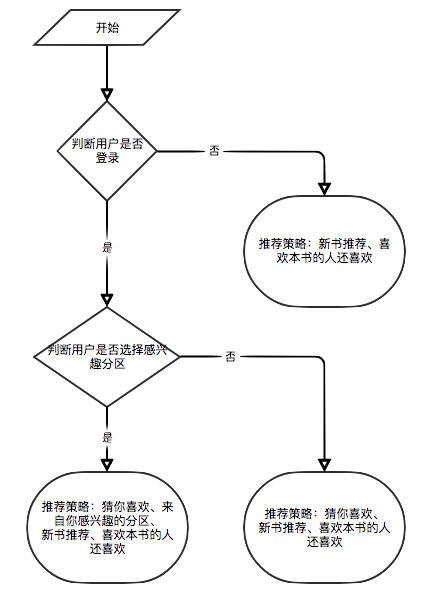
Porque algunos algoritmos de recomendación deben usar los datos favoritos del usuario como parámetros. Si el usuario no ha iniciado sesión, se adoptará la estrategia de recomendación para los turistas. Si el usuario ha iniciado sesión, se adopta la política de recomendación para el usuario iniciado. Si el usuario registrado tiene un registro de interés de interés en la base de datos, se agregará una recomendación de la partición que le interesa. Por lo tanto, la estrategia de recomendación se divide en dos situaciones: si inicia sesión o no.
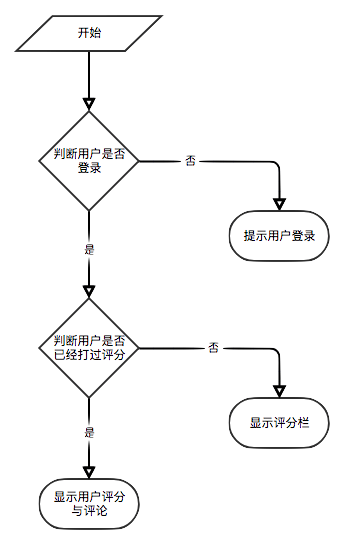
Si el usuario no ha iniciado sesión, se adoptará la estrategia de visualización de calificación del usuario para los turistas. Si se inicia el usuario, se adopta la Política de visualización de calificación del usuario para el usuario iniciado en el usuario. Si el usuario registrado ya ha obtenido el libro electrónico en la página de detalles actual, se mostrará su registro de calificación.
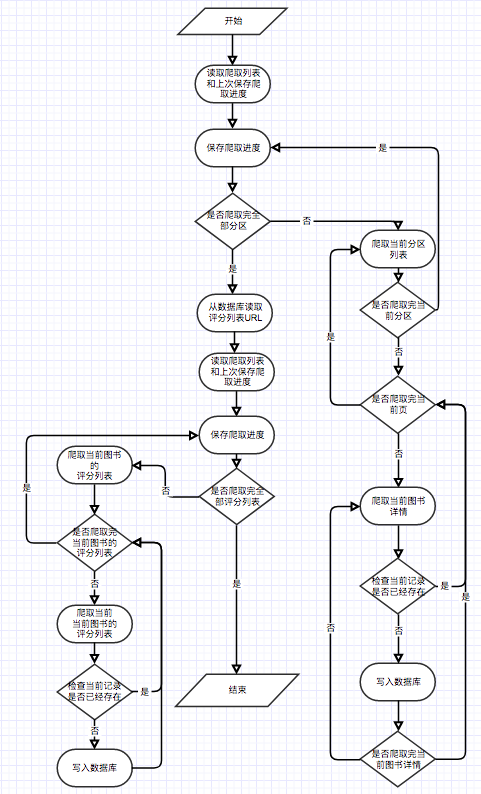
Como se muestra en el diagrama de casos de uso, hay tres usuarios básicos en este sistema. Estos son turistas, usuarios registrados y administradores. Los visitantes pueden visitar la página de inicio de la plataforma de recomendación de libros electrónicos, la página de registro del usuario y ver la página del libro electrónico. La función de registrar a los usuarios es que pueden calificar y comentar sobre libros electrónicos y recomendar libros electrónicos determinados por el interés previsto del usuario. Los administradores pueden usar regularmente el módulo Crawler para actualizar la información del libro electrónico y usar el módulo de estadísticas para actualizar estadísticas clasificadas, matriz de coincidencia de libros electrónicos y matriz de similitud de coseno de libros electrónicos.
! [User Case.png] (/img/user case.png)
Teniendo en cuenta que hay un problema de inicio en frío con este algoritmo. Es decir, para los nuevos usuarios, a menudo carecen de datos de calificación, lo que lleva a la recomendación basada en el nivel de interés predicho del usuario y no se puede llevar a cabo sin problemas. Para resolver este problema, agregué un módulo para usar directamente la matriz de similitud de coseno W para realizar directamente recomendaciones de libros electrónicos similares, de modo que los usuarios no registrados y los nuevos usuarios puedan obtener mejor recomendaciones. En cuanto a los problemas de matriz de datos dispersos en los algoritmos de filtrado colaborativo, algunos libros electrónicos impopulares pueden no tener calificaciones de usuario, baja correlación de libros electrónicos y algunos usuarios tienen pocas calificaciones de libros electrónicos. Para resolver este problema, agregue un nuevo módulo de recomendación de libros a la página de inicio para recomendar mejor los libros electrónicos que no tienen calificación; Agregue un módulo de recomendación de partición para recomendar libros electrónicos basados en el interés del usuario para aumentar el interés de los usuarios específicos para recomendar libros electrónicos. Vale la pena señalar que el libro electrónico recomendado por los usuarios para predecir el interés se calcula utilizando fórmulas en la matriz de similitud de coseno W calculada por este algoritmo. Además, el libro electrónico favorito del usuario también se requiere como parámetros de entrada durante el cálculo. El libro electrónico similar recomendado es usar la matriz de similitud de cadena W para estadísticas directamente. Esto significa que las dos recomendaciones anteriores deben completar el cálculo de la matriz de concurrencia del libro electrónico y la matriz de similitud de coseno del libro electrónico. Debido a que las dos matrices anteriores son computacionalmente grandes y se requieren todos los datos para cada cálculo, el administrador las realizará regularmente.
Símbolo → indica que la clase es una operación manual regular de módulos

Hay dos pasos principales para el algoritmo de filtrado colaborativo basado en elementos:
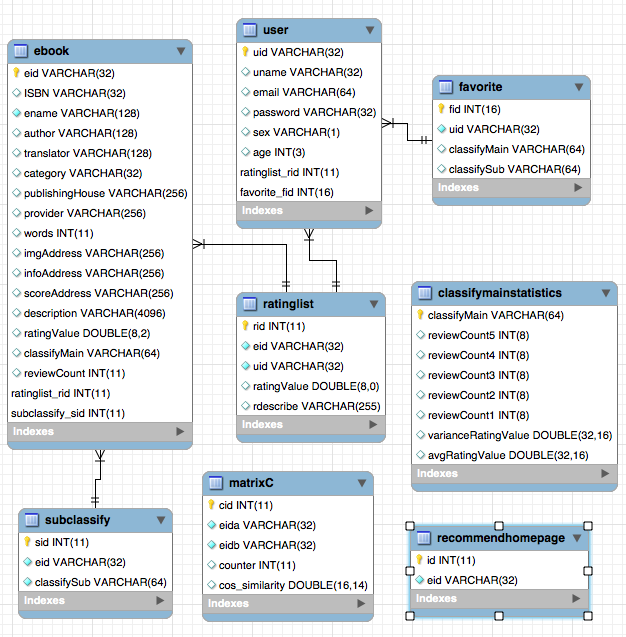
Supongamos que n (i) es la cantidad de usuarios que les gusta el elemento i. N (i) ⋂n (j) representa el número de usuarios que les gusta el elemento I elemento j al mismo tiempo. Entonces la similitud entre el artículo I y el artículo J es:
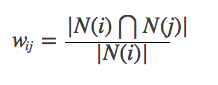
Sin embargo, la fórmula anterior tiene un defecto: cuando el artículo J es un producto muy popular y a todos les gusta, entonces WIJ estará muy cerca de 1, es decir, la fórmula anterior hará que muchos artículos tengan una gran similitud con los productos populares, por lo que puede mejorar la fórmula:
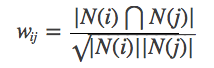
Cree una lista de elementos de usuario invertidos (suponga que las letras mayúsculas representan a los usuarios, las letras minúsculas representan elementos):

Calcule la matriz de concurrencia C (la matriz de concurrencia C representa el número de usuarios que les gustan dos elementos al mismo tiempo, y se calcula en función de la tabla de inversión del elemento del usuario):
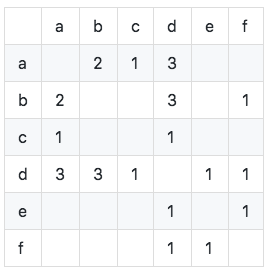
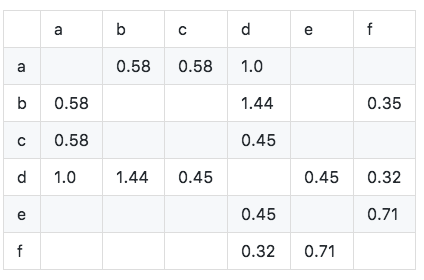
Como se muestra en la figura, podemos ver que los elementos diagonales de la matriz de concurrencia son 0 y son matrices escasas simétricas reales. El algoritmo se implementa de la siguiente manera:
com.statistics.ItemCollaborationFilter
/**
* 计算共现矩阵C
*/
private void computerMatrixC (){
// 建立用户物品倒排表
// 若用户对物品评分大于等于4则认为喜欢(出现)
List < User > allUser = userDao . queryAllUser ();
for ( int i = 0 ; i < allUser . size (); i ++){ // 遍历全部用户
// 获取一个用户的评分列表中>=4的评分记录
List < RatingList > likeList = ratingListDao . selectRatingListByUidAndRatingValue ( allUser . get ( i ). getUid (), 4 );
if ( likeList . size () <= 1 ){ // 若用户只喜欢一本或不喜欢任何图书
continue ;
}
for ( int j = 0 ; j < likeList . size (); j ++){ // 计算likeList中两两出现的图书并写入同现矩阵C
for ( int k = j + 1 ; k < likeList . size (); k ++){
int a = Integer . valueOf ( likeList . get ( j ). getEid ());
int b = Integer . valueOf ( likeList . get ( k ). getEid ());
// 生成key
String key = null ;
if ( a < b ){
key = a + "," + b ;
} else {
key = b + "," + a ;
}
// 检查key是否已经存在
if ( this . matrixC . get ( key ) != null ){
int value = this . matrixC . get ( key );
this . matrixC . put ( key , value + 1 );
} else {
this . matrixC . put ( key , 1 );
}
}
}
System . out . println ( "[" + df . format ( new Date ())+ "]" + "[已完成" + i + ",共" + allUser . size ()+ "]:用户uid=" + allUser . get ( i ). getUid ()+ "的记录以计算完成,共" + likeList . size ()+ "本图书" );
}
}El número de veces que aparece cada elemento es:

Calcule la matriz de similitud de coseno W: la matriz de similitud de coseno se puede obtener utilizando la fórmula mejorada.
El algoritmo se implementa de la siguiente manera:
com.statistics.ItemCollaborationFilter
/**
* 计算余弦相似度矩阵W
* 计算方法:
* 使用矩阵C的每个value作为分子,key中的两个图书的喜欢人数的积开根号作为分母
*/
private Double computerMatrixW ( String eida , String eidb , int value ){
DecimalFormat df = new DecimalFormat ( "#.##" );
// 查询每个图书有多少人喜欢
try {
Statement statemenet = conn . createStatement ();
ResultSet rs = statemenet . executeQuery ( "select count(rid) from ratinglist where eid = '" + eida + "' and ratingValue >= 4;" );
rs . next ();
int likeANum = rs . getInt ( "count(rid)" );
rs = statemenet . executeQuery ( "select count(rid) from ratinglist where eid = '" + eidb + "' and ratingValue >= 4;" );
rs . next ();
int likeBNum = rs . getInt ( "count(rid)" );
if ( likeANum == 0 )
likeANum = 1 ;
if ( likeBNum == 0 )
likeBNum = 1 ;
// 开始计算
Double answer = value * 1.0 / Math . sqrt ( likeANum * likeBNum );
// 精确到小数点后两位
Double result = Double . parseDouble ( df . format ( answer ));
// 返回计算结果
return result ;
} catch ( SQLException e ) {
e . printStackTrace ();
}
return null ;
}El elemento se recomienda en última instancia se determina predecir el interés.
El ítem j predice interés = interés del ítem I que al usuario le gusta × similitud entre el ítem I y el ítem j.
Por ejemplo: a un usuario le gustan los elementos A, B y C. Su interés es 1, 2 y 2 respectivamente. Entonces el interés previsto de los ítems C, D, E y F son:
Por lo tanto, el elemento D debe recomendarse al usuario. El algoritmo se implementa de la siguiente manera:
@ Override
public List < EBook > userRecommendedList ( String uid ) {
// 获取用户喜爱图书列表
List < RatingList > likeList = this . ratingListDao . selectRatingListByUidAndRatingValue ( uid , 4 );
// debug
System . out . println ( "uid=" + uid + "用户喜爱图书列表" );
for ( RatingList r : likeList ){
System . out . println ( r . getEid ()+ "," + r . getRatingValue ());
}
System . out . println ( "likeList.size=" + likeList . size ());
// 定义计算用矩阵
List < Item > matrix = new ArrayList <>();
// 将用户喜爱的图书作为矩阵的列
// 将与用户喜爱的图书同现的图书作为矩阵的行
// 建立工作矩阵
for ( int i = 0 ; i < likeList . size (); i ++){ // 遍历用户喜爱的图书
RatingList temp = likeList . get ( i );
// 获取同现图书
List < MatrixC > itemList = this . matrixCDao . selectMatrixCByEidAOrEidB ( temp . getEid (), temp . getEid ());
for ( int j = 0 ; j < itemList . size (); j ++){
MatrixC c = itemList . get ( j );
// 从matrixC的key中选出同现图书的eid
String sEid = null ;
if ( c . getEida (). equals ( temp . getEid ())){
sEid = c . getEidb ();
} else {
sEid = c . getEida ();
}
// 在行中查询同现图书是否存在
if ( matrix . indexOf ( sEid ) == - 1 ){ // 若列中不存在
double [] col = new double [ likeList . size ()];
// 将同现图书所在行对应喜爱图书的数组值设为对应的余弦相似度*用户喜爱程度(4分为1,5分为2)
col [ likeList . indexOf ( temp )] = c . getCos_similarity ()*( temp . getRatingValue ()- 3 );
matrix . add ( new Item ( sEid , col )); // 增加行
} else { // 若列中存在
// 则将同现图书所在行对应喜爱图书的数组值设为对应的余弦相似度*用户喜爱程度(4分为1,5分为2)
matrix . get ( matrix . indexOf ( sEid )). col [ likeList . indexOf ( temp )] = c . getCos_similarity ()*( temp . getRatingValue ()- 3 );
}
}
}
// 计算预测兴趣度
for ( int i = 0 ; i < matrix . size (); i ++){
Item item = matrix . get ( i );
double interestValue = 0 ;
for ( int j = 0 ; j < item . col . length ; j ++){
interestValue += item . col [ j ];
}
matrix . get ( i ). interestValue = interestValue ;
}
// 根据预测兴趣度进行排序
Collections . sort ( matrix );
// 返回推荐图书列表
List < EBook > resultList = new ArrayList <>();
for ( int i = 0 ; i < matrix . size () && i < 20 ; i ++){ // 返回排前10的书
if ( matrix . get ( i ). interestValue > 0 ){
EBook eBook = this . eBookDao . queryEBookByEid ( matrix . get ( i ). eid );
resultList . add ( eBook );
// debug
System . out . println ( matrix . get ( i ). eid + "," + eBook . getEname ()+ ",interestValue=" + matrix . get ( i ). interestValue );
}
}
return EBookServiceImpl . initEBookImgAddress ( resultList );
}El módulo recomendado utiliza los datos rastreados por el rastreador como entrada para obtener los resultados del cálculo en la tabla MatrixC. Todo el proceso de cálculo se divide en 2 etapas. La primera etapa calcula la matriz de concurrencia C. La segunda etapa calcula la similitud cosena W de los libros electrónicos que aparecen en pares. Para la función recomendada basada en el interés predicho del usuario, debido a que al usuario le gusta el monto del cálculo en tiempo real y total de los datos de libros electrónicos es demasiado grande, el usuario usará cálculos en tiempo real al acceder a la página. Después de múltiples pruebas, el tiempo de espera promedio del usuario está dentro de un rango aceptable.
Debido a que la actualización de la página web de Douban Movie ha agregado medidas antiinterrator, los datos utilizados para ejecutar el algoritmo recomendado se proporcionan aquí.


