EMAN
1.0.0
Un simple système de recommandation de livres électroniques basé sur le cadre SSM et l'algorithme de filtrage collaboratif des articles (ITEMCF)
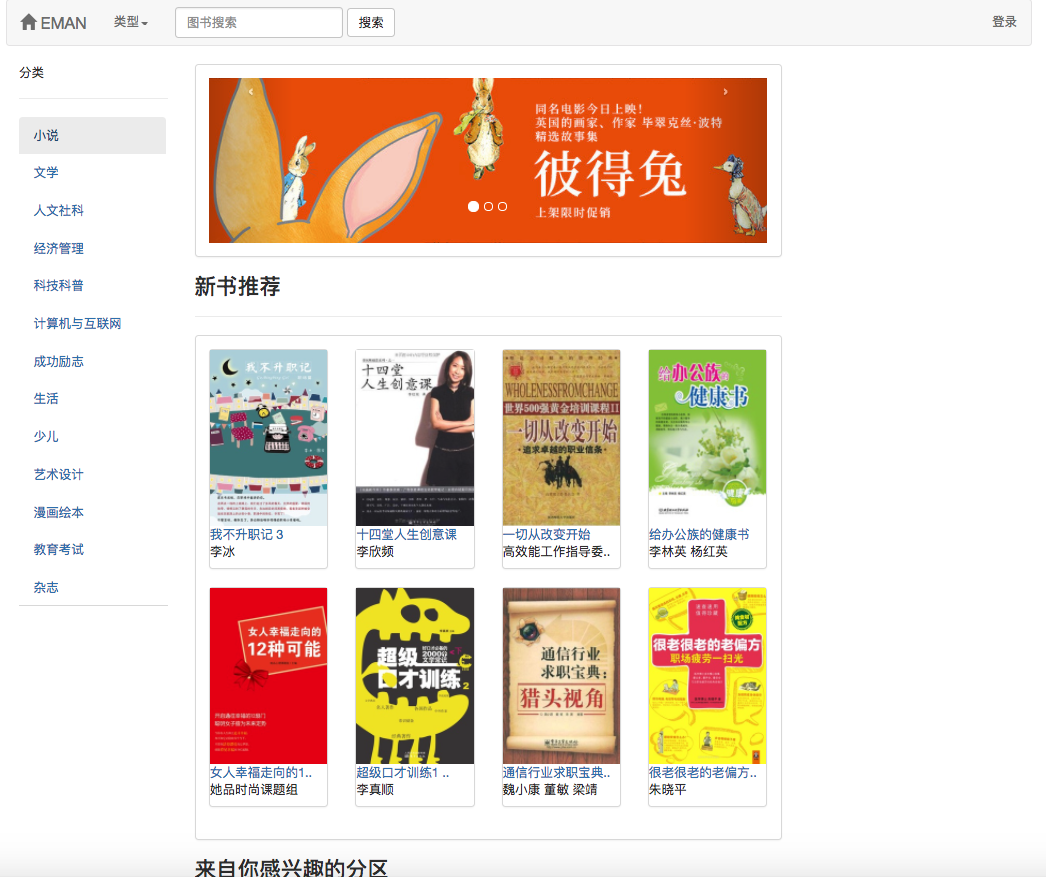
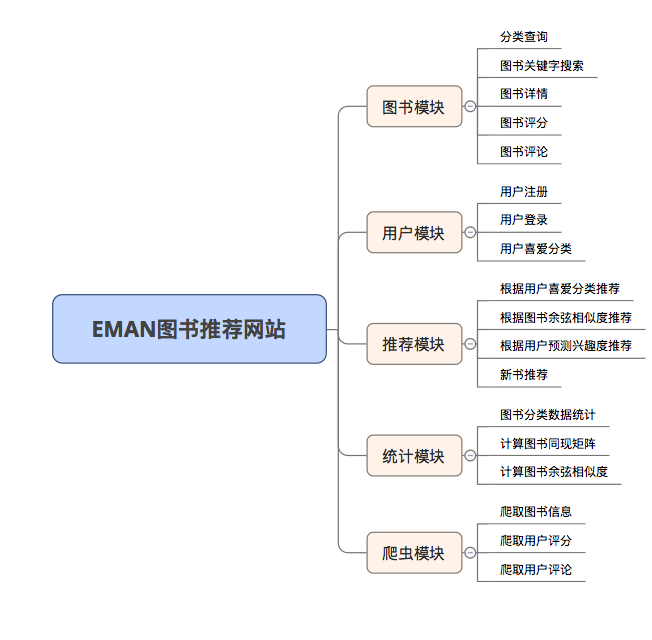
Parce que certains algorithmes de recommandation doivent utiliser les données préférées de l'utilisateur comme paramètres. Si l'utilisateur n'est pas connecté, la stratégie de recommandation pour les touristes sera adoptée. Si l'utilisateur est connecté, la stratégie de recommandation pour l'utilisateur connecté est adoptée. Si l'utilisateur enregistré a un enregistrement d'intérêt de partition dans la base de données, une recommandation de la partition qui vous intéresse sera ajoutée. Par conséquent, la stratégie de recommandation est divisée en deux situations: que ce soit à se connecter ou non.
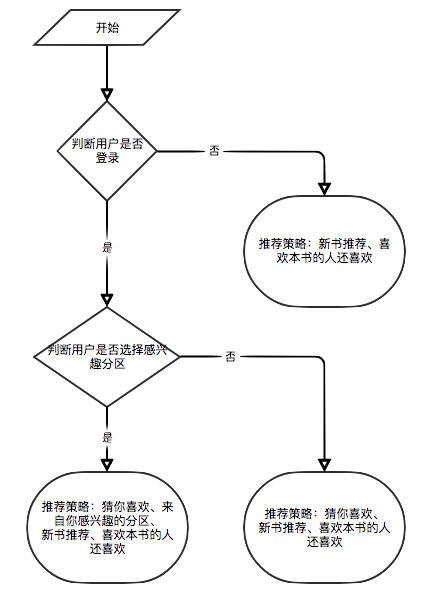
Si l'utilisateur n'est pas connecté, la stratégie d'affichage de l'évaluation de l'utilisateur pour les touristes sera adoptée. Si l'utilisateur est connecté, la stratégie d'affichage de l'évaluation de l'utilisateur pour l'utilisateur connecté est adoptée. Si l'utilisateur connecté a déjà noté le livre électronique sur la page de détails actuelle, son enregistrement de notation sera affiché.
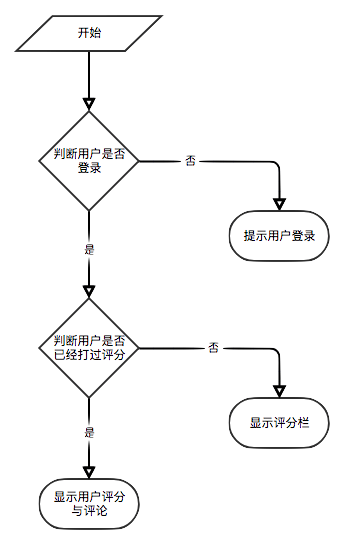
Comme le montre le diagramme de cas d'utilisation, il y a trois utilisateurs de base dans ce système. Ce sont des touristes, des utilisateurs enregistrés et des administrateurs. Les visiteurs peuvent visiter la page d'accueil de la plate-forme de recommandation de livres électroniques, la page d'enregistrement des utilisateurs et afficher la page E-Book. La fonction de l'enregistrement des utilisateurs est qu'ils peuvent évaluer et commenter les livres électroniques et recommander des livres électroniques déterminés par l'intérêt prévu de l'utilisateur. Les administrateurs peuvent régulièrement utiliser le module Crawler pour mettre à jour les informations sur les livres électroniques et utiliser le module statistique pour mettre à jour les statistiques classifiées, la matrice de co-occurrence du livre électronique et la matrice de similitude en cosinus électronique.
! [User case.png] (/ img / user case.png)
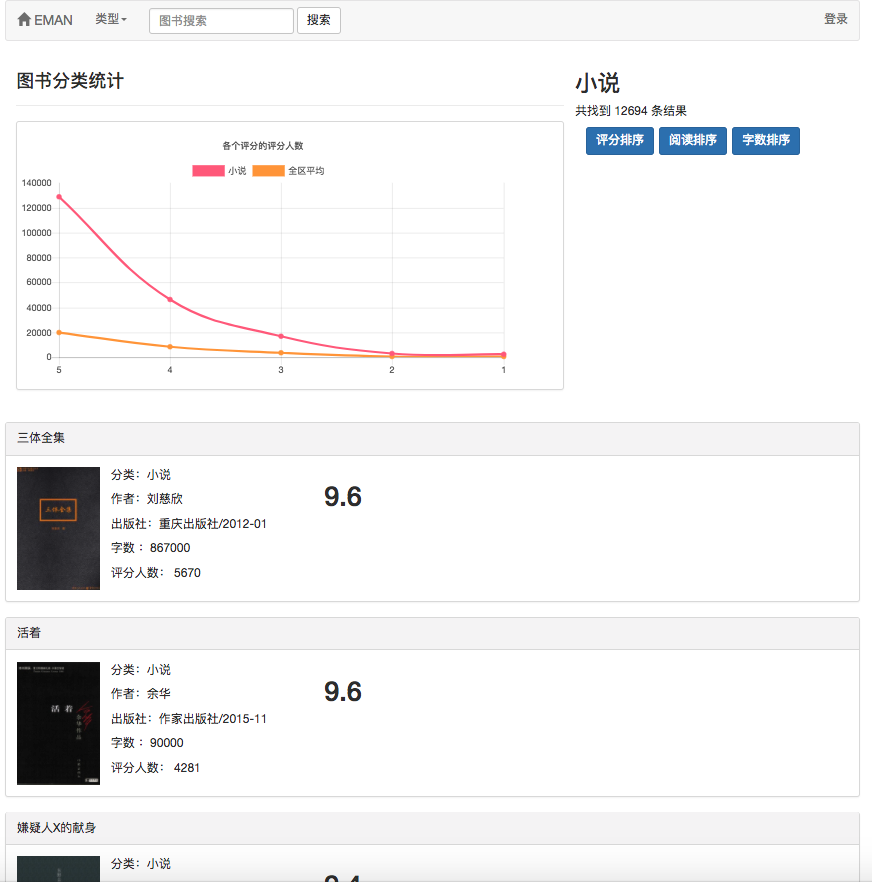
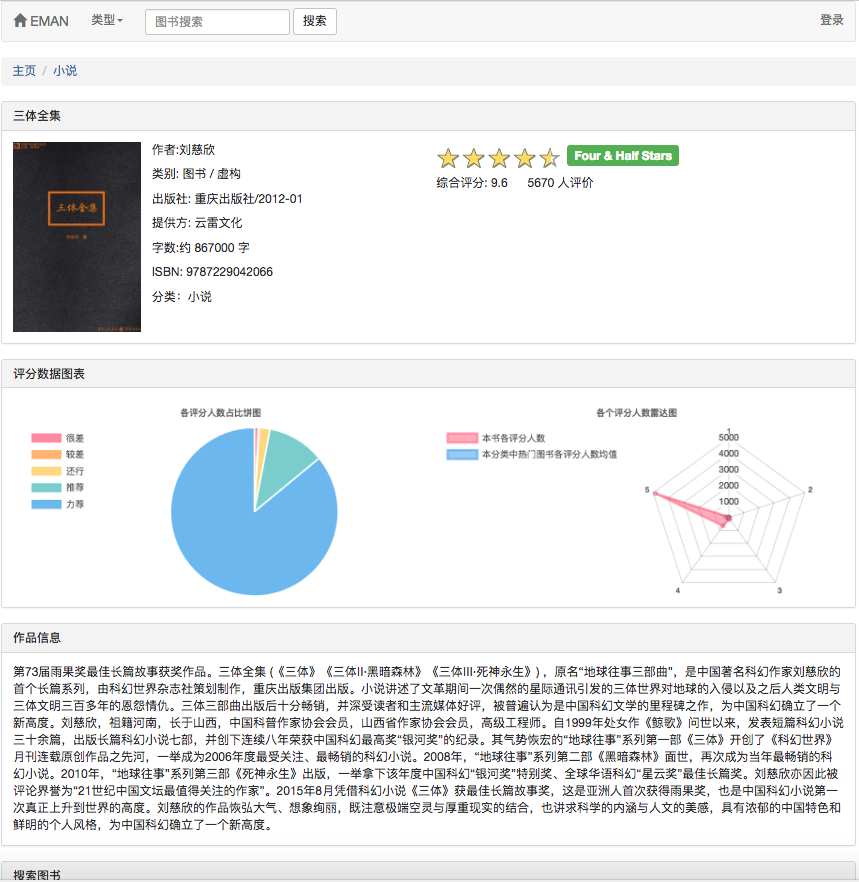
Considérant qu'il y a un problème de début à froid avec cet algorithme. Autrement dit, pour les nouveaux utilisateurs, ils manquent souvent de données de notation, ce qui conduit à la recommandation en fonction du niveau d'intérêt prévu de l'utilisateur et ne peut pas être effectuée en douceur. Pour résoudre ce problème, j'ai ajouté un module pour utiliser directement la matrice de similitude Cosine W pour effectuer directement des recommandations de livres électroniques similaires, afin que les utilisateurs non enregistrés et les nouveaux utilisateurs puissent mieux obtenir des recommandations. En ce qui concerne les problèmes de matrice de données clairsemés dans les algorithmes de filtrage collaboratif, certains livres électroniques impopulaires peuvent ne pas avoir de notes d'utilisateur, une faible corrélation de livres électroniques et certains utilisateurs ont peu de notes de livres électroniques. Pour résoudre ce problème, ajoutez un nouveau module de recommandation de livre à la page d'accueil pour mieux recommander des livres électroniques qui n'ont pas de note; Ajoutez un module de recommandation de partition pour recommander des livres électroniques en fonction de l'intérêt de l'utilisateur afin d'augmenter l'intérêt des utilisateurs spécifiques pour recommander des livres électroniques. Il convient de noter que le livre électronique recommandé par les utilisateurs de prédire l'intérêt est calculé à l'aide de formules sur la matrice de similitude en cosinus w calculée par cet algorithme. De plus, le livre électronique préféré de l'utilisateur est également requis en tant que paramètres d'entrée pendant le calcul. Le livre électronique similaire recommandé est d'utiliser directement la matrice de similitude de chaîne W pour les statistiques directement. Cela signifie que les deux recommandations ci-dessus doivent compléter le calcul de la matrice de cooccurrence du livre électronique et la matrice de similitude cosinus du livre électronique. Étant donné que les deux matrices ci-dessus sont importantes sur le calcul et toutes les données sont nécessaires pour chaque calcul, il est défini régulièrement par l'administrateur.
Symbole → indique que la classe est une opération manuelle régulière des modules

Il existe deux étapes principales pour l'algorithme de filtrage collaboratif basé sur les éléments:
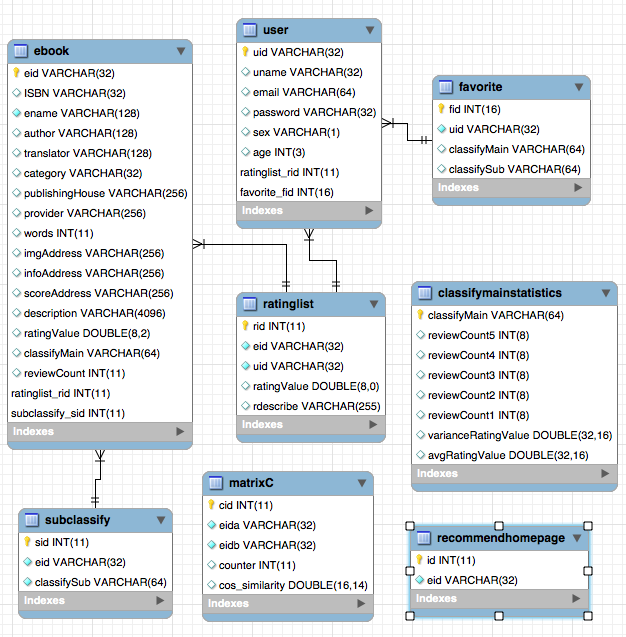
Supposons que n (i) soit le nombre d'utilisateurs qui aiment l'article i. N (i) ⋂n (j) représente le nombre d'utilisateurs qui aiment le point I Article J en même temps. Ensuite, la similitude entre les articles I et J est:
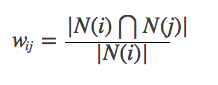
Cependant, la formule ci-dessus a un défaut: lorsque l'article J est un produit très populaire et que tout le monde l'aime, alors Wij sera très proche de 1, c'est-à-dire que la formule ci-dessus fera que de nombreux articles ont une grande similitude avec les produits populaires, afin que vous puissiez améliorer la formule:
Créer une liste d'éléments utilisateur inversés (Supposons que les lettres majuscules représentent les utilisateurs, les lettres minuscules représentent les éléments):

Calculez la matrice de cooccurrence C (la matrice de cooccurrence C représente le nombre d'utilisateurs qui aiment deux éléments en même temps, et est calculé sur la base du tableau d'inversion de l'élément utilisateur):
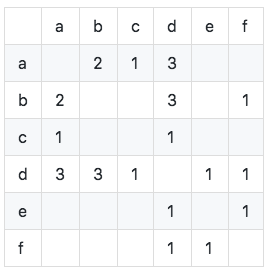
Comme le montre la figure, nous pouvons voir que les éléments diagonaux de la matrice de co-occurrence sont tous 0 et sont de véritables matrices clairsemées symétriques. L'algorithme est implémenté comme suit:
com.statistics.itemCollaborationFilter
/**
* 计算共现矩阵C
*/
private void computerMatrixC (){
// 建立用户物品倒排表
// 若用户对物品评分大于等于4则认为喜欢(出现)
List < User > allUser = userDao . queryAllUser ();
for ( int i = 0 ; i < allUser . size (); i ++){ // 遍历全部用户
// 获取一个用户的评分列表中>=4的评分记录
List < RatingList > likeList = ratingListDao . selectRatingListByUidAndRatingValue ( allUser . get ( i ). getUid (), 4 );
if ( likeList . size () <= 1 ){ // 若用户只喜欢一本或不喜欢任何图书
continue ;
}
for ( int j = 0 ; j < likeList . size (); j ++){ // 计算likeList中两两出现的图书并写入同现矩阵C
for ( int k = j + 1 ; k < likeList . size (); k ++){
int a = Integer . valueOf ( likeList . get ( j ). getEid ());
int b = Integer . valueOf ( likeList . get ( k ). getEid ());
// 生成key
String key = null ;
if ( a < b ){
key = a + "," + b ;
} else {
key = b + "," + a ;
}
// 检查key是否已经存在
if ( this . matrixC . get ( key ) != null ){
int value = this . matrixC . get ( key );
this . matrixC . put ( key , value + 1 );
} else {
this . matrixC . put ( key , 1 );
}
}
}
System . out . println ( "[" + df . format ( new Date ())+ "]" + "[已完成" + i + ",共" + allUser . size ()+ "]:用户uid=" + allUser . get ( i ). getUid ()+ "的记录以计算完成,共" + likeList . size ()+ "本图书" );
}
}Le nombre de fois que chaque élément apparaît est:

Calculez la matrice de similitude en cosinus W: La matrice de similitude en cosinus peut être obtenue en utilisant la formule améliorée.
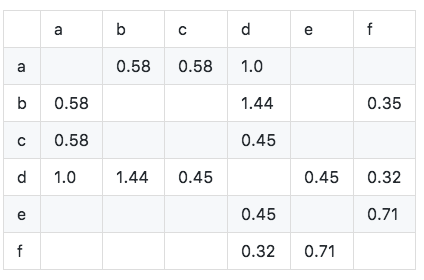
L'algorithme est implémenté comme suit:
com.statistics.itemCollaborationFilter
/**
* 计算余弦相似度矩阵W
* 计算方法:
* 使用矩阵C的每个value作为分子,key中的两个图书的喜欢人数的积开根号作为分母
*/
private Double computerMatrixW ( String eida , String eidb , int value ){
DecimalFormat df = new DecimalFormat ( "#.##" );
// 查询每个图书有多少人喜欢
try {
Statement statemenet = conn . createStatement ();
ResultSet rs = statemenet . executeQuery ( "select count(rid) from ratinglist where eid = '" + eida + "' and ratingValue >= 4;" );
rs . next ();
int likeANum = rs . getInt ( "count(rid)" );
rs = statemenet . executeQuery ( "select count(rid) from ratinglist where eid = '" + eidb + "' and ratingValue >= 4;" );
rs . next ();
int likeBNum = rs . getInt ( "count(rid)" );
if ( likeANum == 0 )
likeANum = 1 ;
if ( likeBNum == 0 )
likeBNum = 1 ;
// 开始计算
Double answer = value * 1.0 / Math . sqrt ( likeANum * likeBNum );
// 精确到小数点后两位
Double result = Double . parseDouble ( df . format ( answer ));
// 返回计算结果
return result ;
} catch ( SQLException e ) {
e . printStackTrace ();
}
return null ;
}L'article est finalement recommandé est déterminé en prédisant l'intérêt.
L'article J prédit l'intérêt = intérêt de l'article I que l'utilisateur aime × similitude entre l'élément I et l'article j.
Par exemple: un utilisateur aime les éléments A, B et C. Leur intérêt est respectivement de 1, 2 et 2. Ensuite, l'intérêt prévu des articles C, D, E et F sont:
Par conséquent, l'article D doit être recommandé à l'utilisateur. L'algorithme est implémenté comme suit:
@ Override
public List < EBook > userRecommendedList ( String uid ) {
// 获取用户喜爱图书列表
List < RatingList > likeList = this . ratingListDao . selectRatingListByUidAndRatingValue ( uid , 4 );
// debug
System . out . println ( "uid=" + uid + "用户喜爱图书列表" );
for ( RatingList r : likeList ){
System . out . println ( r . getEid ()+ "," + r . getRatingValue ());
}
System . out . println ( "likeList.size=" + likeList . size ());
// 定义计算用矩阵
List < Item > matrix = new ArrayList <>();
// 将用户喜爱的图书作为矩阵的列
// 将与用户喜爱的图书同现的图书作为矩阵的行
// 建立工作矩阵
for ( int i = 0 ; i < likeList . size (); i ++){ // 遍历用户喜爱的图书
RatingList temp = likeList . get ( i );
// 获取同现图书
List < MatrixC > itemList = this . matrixCDao . selectMatrixCByEidAOrEidB ( temp . getEid (), temp . getEid ());
for ( int j = 0 ; j < itemList . size (); j ++){
MatrixC c = itemList . get ( j );
// 从matrixC的key中选出同现图书的eid
String sEid = null ;
if ( c . getEida (). equals ( temp . getEid ())){
sEid = c . getEidb ();
} else {
sEid = c . getEida ();
}
// 在行中查询同现图书是否存在
if ( matrix . indexOf ( sEid ) == - 1 ){ // 若列中不存在
double [] col = new double [ likeList . size ()];
// 将同现图书所在行对应喜爱图书的数组值设为对应的余弦相似度*用户喜爱程度(4分为1,5分为2)
col [ likeList . indexOf ( temp )] = c . getCos_similarity ()*( temp . getRatingValue ()- 3 );
matrix . add ( new Item ( sEid , col )); // 增加行
} else { // 若列中存在
// 则将同现图书所在行对应喜爱图书的数组值设为对应的余弦相似度*用户喜爱程度(4分为1,5分为2)
matrix . get ( matrix . indexOf ( sEid )). col [ likeList . indexOf ( temp )] = c . getCos_similarity ()*( temp . getRatingValue ()- 3 );
}
}
}
// 计算预测兴趣度
for ( int i = 0 ; i < matrix . size (); i ++){
Item item = matrix . get ( i );
double interestValue = 0 ;
for ( int j = 0 ; j < item . col . length ; j ++){
interestValue += item . col [ j ];
}
matrix . get ( i ). interestValue = interestValue ;
}
// 根据预测兴趣度进行排序
Collections . sort ( matrix );
// 返回推荐图书列表
List < EBook > resultList = new ArrayList <>();
for ( int i = 0 ; i < matrix . size () && i < 20 ; i ++){ // 返回排前10的书
if ( matrix . get ( i ). interestValue > 0 ){
EBook eBook = this . eBookDao . queryEBookByEid ( matrix . get ( i ). eid );
resultList . add ( eBook );
// debug
System . out . println ( matrix . get ( i ). eid + "," + eBook . getEname ()+ ",interestValue=" + matrix . get ( i ). interestValue );
}
}
return EBookServiceImpl . initEBookImgAddress ( resultList );
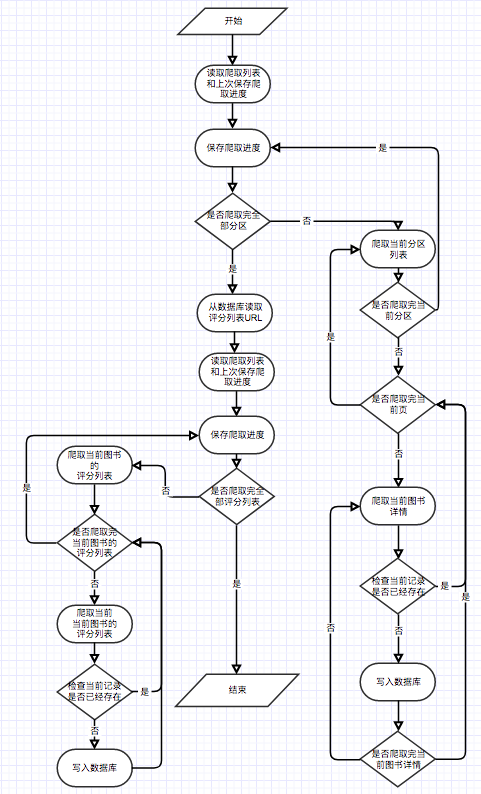
}Le module recommandé utilise les données rampées par le robot comme entrée pour sortir les résultats du calcul dans la table matrixc. L'ensemble du processus de calcul est divisé en 2 étapes. La première étape calcule la matrice de cooccurrence C. La deuxième étape calcule la similitude du cosinus w des livres électroniques qui apparaissent par paires. Pour la fonction recommandée basée sur l'intérêt prédit par l'utilisateur, car l'utilisateur aime la quantité de calcul en temps réel et total de données de livres électroniques est trop grande, l'utilisateur utilisera des calculs en temps réel lors de l'accès à la page. Après plusieurs tests, le temps d'attente moyen de l'utilisateur se situe dans une plage acceptable.
Étant donné que la mise à niveau de la page Web de Douban Movie a ajouté des mesures anti-rampe, les données utilisées pour exécuter l'algorithme recommandé sont fournies ici.


