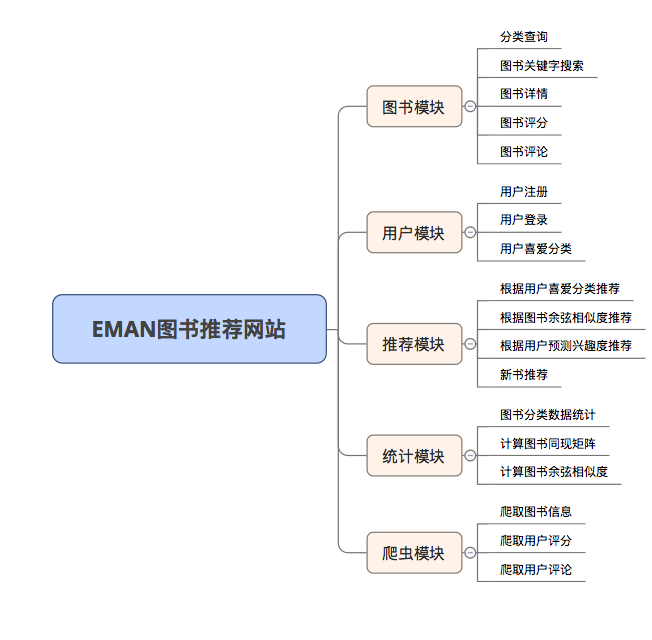
EMAN
1.0.0
SSMフレームワークとアイテムコラボレーションフィルタリングアルゴリズム(itemcf)に基づく簡単な電子書籍推奨システム
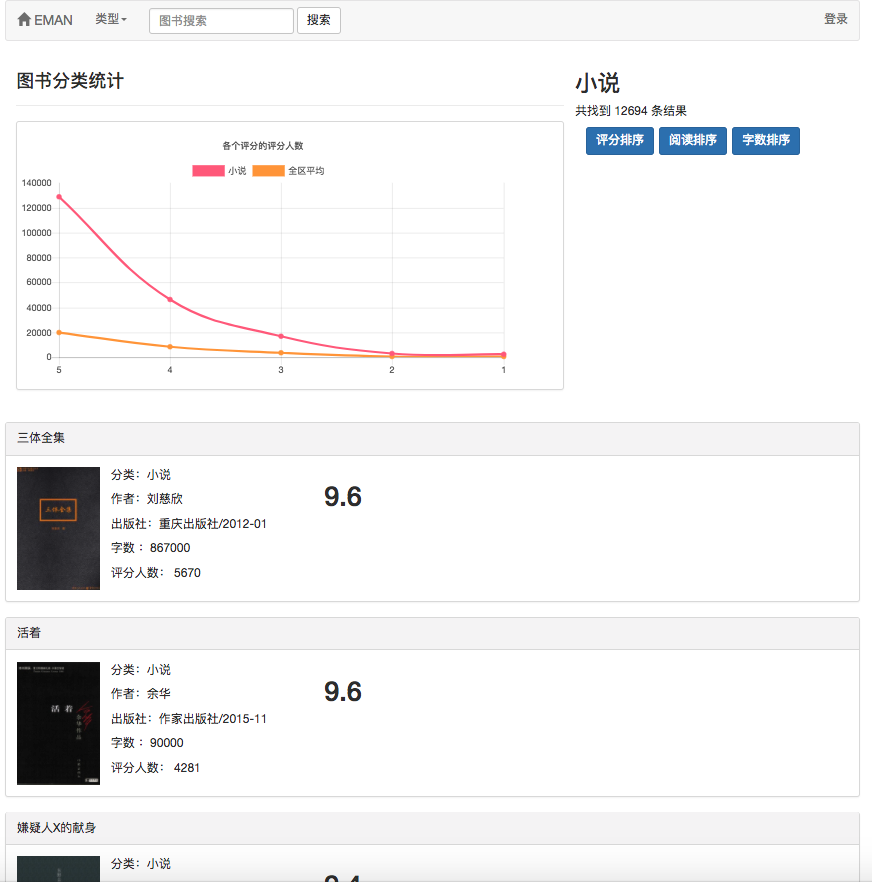
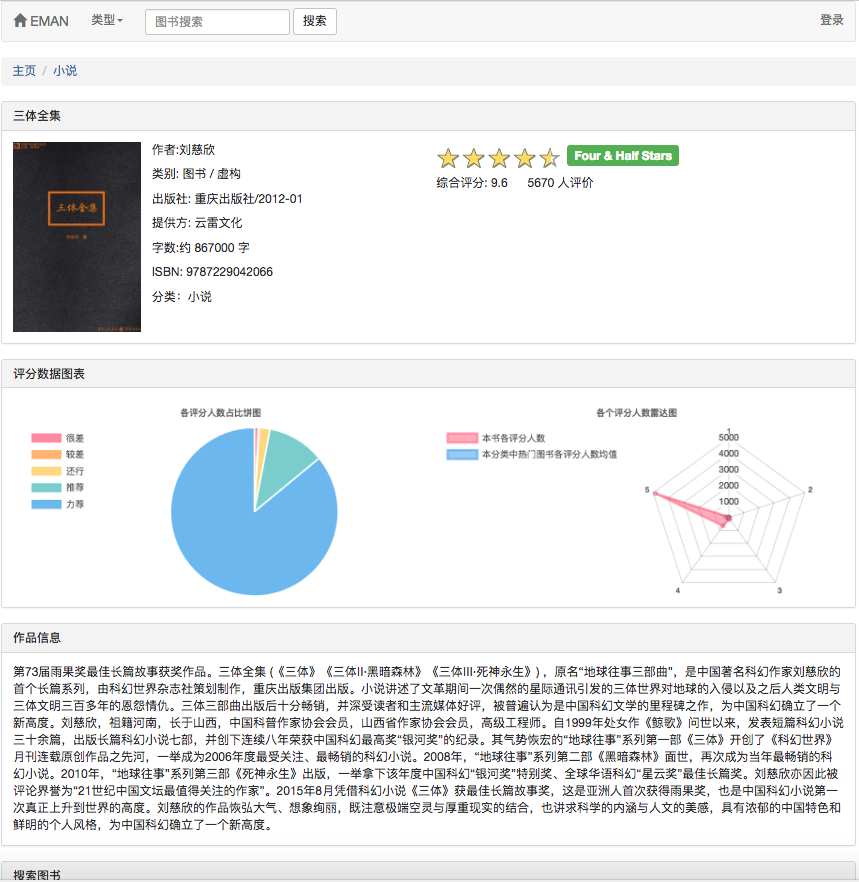
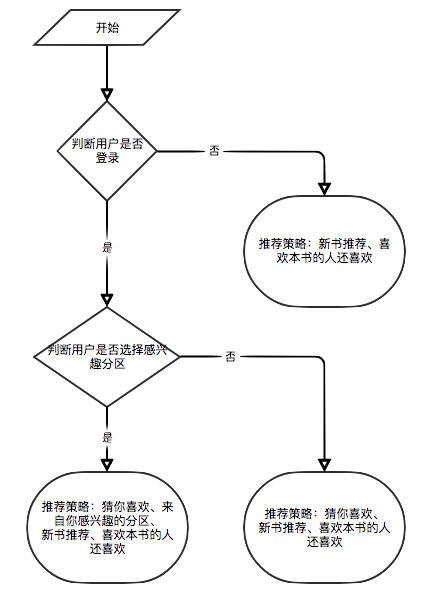
一部の推奨アルゴリズムは、ユーザーのお気に入りのデータをパラメーターとして使用する必要があるためです。ユーザーがログインしていない場合、観光客向けの推奨戦略が採用されます。ユーザーがログインしている場合、ログインしたユーザーの推奨ポリシーが採用されます。ログインユーザーにデータベースに関心のあるパーティションレコードがある場合、興味のあるパーティションからの推奨事項が追加されます。したがって、推奨戦略は、ログインするかどうかにかかわらず、2つの状況に分けられます。
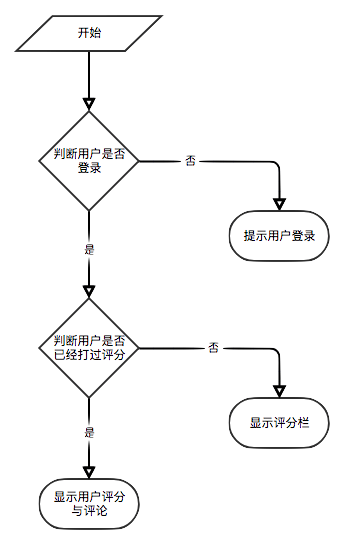
ユーザーがログインしていない場合、観光客向けのユーザー評価ディスプレイ戦略が採用されます。ユーザーがログインしている場合、ログインしたユーザーのユーザー評価ディスプレイポリシーが採用されます。ログインユーザーが現在の詳細ページでe-bookを既に獲得している場合、その評価レコードが表示されます。
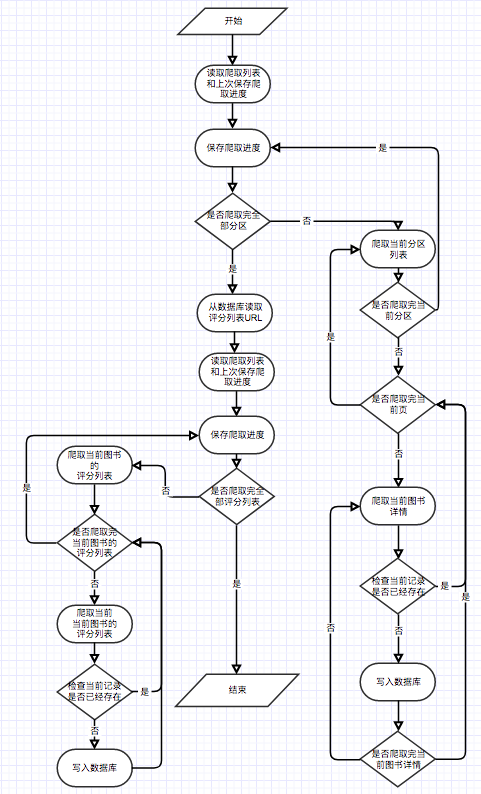
ユースケース図に示されているように、このシステムには3人の基本ユーザーがいます。これらは、観光客、登録ユーザー、および管理者です。訪問者は、電子書籍の推奨プラットフォーム、ユーザー登録ページのホームページにアクセスして、電子書籍ページを表示できます。ユーザーを登録する機能は、ユーザーが電子書籍を評価してコメントし、ユーザーの予測された関心によって決定される電子書籍を推奨できることです。管理者は、Crawlerモジュールを定期的に使用して電子書籍情報を更新し、統計モジュールを使用して、分類された統計、電子書籍の共起マトリックス、電子書籍のCosine類似性マトリックスを更新できます。

このアルゴリズムにコールドスタートの問題があることを考慮してください。つまり、新規ユーザーにとっては、多くの場合、評価データが不足しているため、ユーザーの予測された関心レベルに基づいて推奨につながり、スムーズに実行できません。この問題を解決するために、コサイン類似性マトリックスWを直接使用して、同様の電子書籍の推奨事項を直接実行するモジュールを追加しました。共同のフィルタリングアルゴリズムのまばらなデータマトリックスの問題については、一部の不人気な電子書籍にはユーザーの評価がなく、電子書籍の相関が低く、電子書籍の評価がほとんどありません。この問題を解決するには、新しい本の推奨モジュールをホームページに追加して、評価されていない電子書籍をより適切に推奨します。特定のユーザーの関心を電子書籍を推奨するために、ユーザーの関心に基づいて電子書籍を推奨するパーティション推奨モジュールを追加します。関心を予測するためにユーザーが推奨する電子書籍は、このアルゴリズムによって計算されたCOSINE類似性マトリックスWの式を使用して計算されることは注目に値します。さらに、ユーザーのお気に入りの電子書籍も、計算中に入力パラメーターとして必要です。推奨される同様の電子書籍は、統計に直接文字列類似性マトリックスWを使用することです。これは、上記の2つの推奨事項が、電子書籍の共起マトリックスと電子書籍のCosine類似性マトリックスの計算を完了する必要があることを意味します。上記の2つのマトリックスは計算が大きく、すべてのデータが各計算に必要であるため、管理者が定期的に実行するように設定されています。
シンボル→クラスがモジュールの定期的な手動操作であることを示します

アイテムに基づいて、共同フィルタリングアルゴリズムには2つの主要な手順があります。
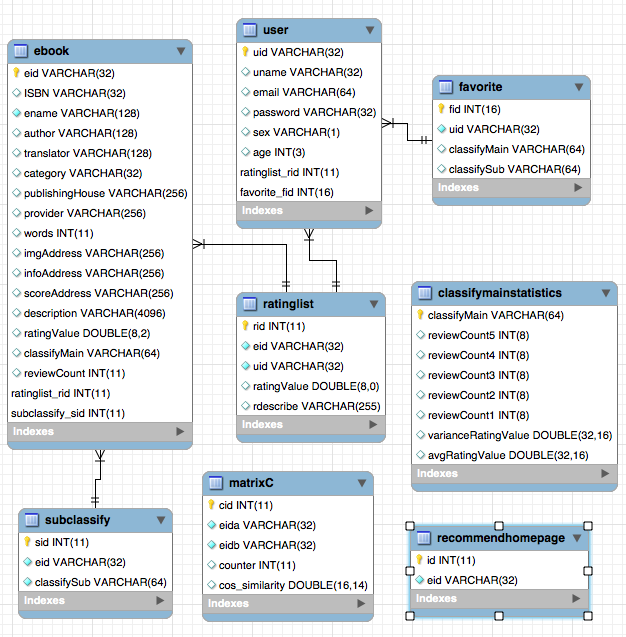
n(i)がアイテムiが好きなユーザーの数であると仮定します。 n(i)⋂n(j)は、アイテムiアイテムJが同時に好きなユーザーの数を表します。次に、アイテムIとアイテムJの類似性は次のとおりです。
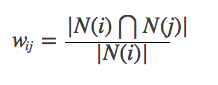
ただし、上記の式には欠陥があります。アイテムJが非常に人気のある製品であり、誰もがそれを好む場合、Wijは1に非常に近くなります。つまり、上記のフォーミュラは多くのアイテムが人気のある製品と大きな類似性を持つため、式を改善できます。
反転したユーザーアイテムのリストを作成します(大文字がユーザーを表し、小文字を表すアイテムを表すと仮定します):

共起マトリックスCを計算します(共起マトリックスCは、同時に2つのアイテムが好きなユーザーの数を表し、ユーザーアイテムの反転表に基づいて計算されます):
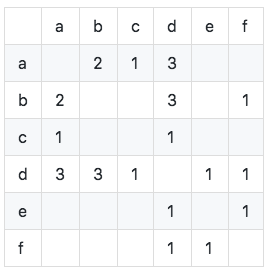
図に示すように、共起マトリックスの対角線要素はすべて0であり、実際の対称スパースマトリックスであることがわかります。アルゴリズムは次のように実装されます。
com.statistics.itemcollaborationfilter
/**
* 计算共现矩阵C
*/
private void computerMatrixC (){
// 建立用户物品倒排表
// 若用户对物品评分大于等于4则认为喜欢(出现)
List < User > allUser = userDao . queryAllUser ();
for ( int i = 0 ; i < allUser . size (); i ++){ // 遍历全部用户
// 获取一个用户的评分列表中>=4的评分记录
List < RatingList > likeList = ratingListDao . selectRatingListByUidAndRatingValue ( allUser . get ( i ). getUid (), 4 );
if ( likeList . size () <= 1 ){ // 若用户只喜欢一本或不喜欢任何图书
continue ;
}
for ( int j = 0 ; j < likeList . size (); j ++){ // 计算likeList中两两出现的图书并写入同现矩阵C
for ( int k = j + 1 ; k < likeList . size (); k ++){
int a = Integer . valueOf ( likeList . get ( j ). getEid ());
int b = Integer . valueOf ( likeList . get ( k ). getEid ());
// 生成key
String key = null ;
if ( a < b ){
key = a + "," + b ;
} else {
key = b + "," + a ;
}
// 检查key是否已经存在
if ( this . matrixC . get ( key ) != null ){
int value = this . matrixC . get ( key );
this . matrixC . put ( key , value + 1 );
} else {
this . matrixC . put ( key , 1 );
}
}
}
System . out . println ( "[" + df . format ( new Date ())+ "]" + "[已完成" + i + ",共" + allUser . size ()+ "]:用户uid=" + allUser . get ( i ). getUid ()+ "的记录以计算完成,共" + likeList . size ()+ "本图书" );
}
}各アイテムが表示される回数は次のとおりです。

Cosine類似性マトリックスWを計算します。Cosine類似性マトリックスは、改善された式を使用して取得できます。
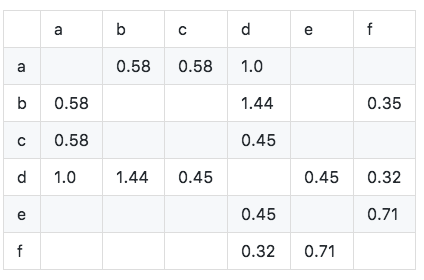
アルゴリズムは次のように実装されます。
com.statistics.itemcollaborationfilter
/**
* 计算余弦相似度矩阵W
* 计算方法:
* 使用矩阵C的每个value作为分子,key中的两个图书的喜欢人数的积开根号作为分母
*/
private Double computerMatrixW ( String eida , String eidb , int value ){
DecimalFormat df = new DecimalFormat ( "#.##" );
// 查询每个图书有多少人喜欢
try {
Statement statemenet = conn . createStatement ();
ResultSet rs = statemenet . executeQuery ( "select count(rid) from ratinglist where eid = '" + eida + "' and ratingValue >= 4;" );
rs . next ();
int likeANum = rs . getInt ( "count(rid)" );
rs = statemenet . executeQuery ( "select count(rid) from ratinglist where eid = '" + eidb + "' and ratingValue >= 4;" );
rs . next ();
int likeBNum = rs . getInt ( "count(rid)" );
if ( likeANum == 0 )
likeANum = 1 ;
if ( likeBNum == 0 )
likeBNum = 1 ;
// 开始计算
Double answer = value * 1.0 / Math . sqrt ( likeANum * likeBNum );
// 精确到小数点后两位
Double result = Double . parseDouble ( df . format ( answer ));
// 返回计算结果
return result ;
} catch ( SQLException e ) {
e . printStackTrace ();
}
return null ;
}最終的に推奨されるアイテムは、関心を予測することによって決定されます。
項目Jは、ユーザーが気に入るアイテムIの関心=アイテムIとアイテムJの類似性を予測します。
例:ユーザーはアイテムA、B、およびcが好きです。彼らの関心はそれぞれ1、2、2です。次に、アイテムC、D、E、およびFの予測される関心は次のとおりです。
したがって、アイテムDをユーザーに推奨する必要があります。アルゴリズムは次のように実装されます。
@ Override
public List < EBook > userRecommendedList ( String uid ) {
// 获取用户喜爱图书列表
List < RatingList > likeList = this . ratingListDao . selectRatingListByUidAndRatingValue ( uid , 4 );
// debug
System . out . println ( "uid=" + uid + "用户喜爱图书列表" );
for ( RatingList r : likeList ){
System . out . println ( r . getEid ()+ "," + r . getRatingValue ());
}
System . out . println ( "likeList.size=" + likeList . size ());
// 定义计算用矩阵
List < Item > matrix = new ArrayList <>();
// 将用户喜爱的图书作为矩阵的列
// 将与用户喜爱的图书同现的图书作为矩阵的行
// 建立工作矩阵
for ( int i = 0 ; i < likeList . size (); i ++){ // 遍历用户喜爱的图书
RatingList temp = likeList . get ( i );
// 获取同现图书
List < MatrixC > itemList = this . matrixCDao . selectMatrixCByEidAOrEidB ( temp . getEid (), temp . getEid ());
for ( int j = 0 ; j < itemList . size (); j ++){
MatrixC c = itemList . get ( j );
// 从matrixC的key中选出同现图书的eid
String sEid = null ;
if ( c . getEida (). equals ( temp . getEid ())){
sEid = c . getEidb ();
} else {
sEid = c . getEida ();
}
// 在行中查询同现图书是否存在
if ( matrix . indexOf ( sEid ) == - 1 ){ // 若列中不存在
double [] col = new double [ likeList . size ()];
// 将同现图书所在行对应喜爱图书的数组值设为对应的余弦相似度*用户喜爱程度(4分为1,5分为2)
col [ likeList . indexOf ( temp )] = c . getCos_similarity ()*( temp . getRatingValue ()- 3 );
matrix . add ( new Item ( sEid , col )); // 增加行
} else { // 若列中存在
// 则将同现图书所在行对应喜爱图书的数组值设为对应的余弦相似度*用户喜爱程度(4分为1,5分为2)
matrix . get ( matrix . indexOf ( sEid )). col [ likeList . indexOf ( temp )] = c . getCos_similarity ()*( temp . getRatingValue ()- 3 );
}
}
}
// 计算预测兴趣度
for ( int i = 0 ; i < matrix . size (); i ++){
Item item = matrix . get ( i );
double interestValue = 0 ;
for ( int j = 0 ; j < item . col . length ; j ++){
interestValue += item . col [ j ];
}
matrix . get ( i ). interestValue = interestValue ;
}
// 根据预测兴趣度进行排序
Collections . sort ( matrix );
// 返回推荐图书列表
List < EBook > resultList = new ArrayList <>();
for ( int i = 0 ; i < matrix . size () && i < 20 ; i ++){ // 返回排前10的书
if ( matrix . get ( i ). interestValue > 0 ){
EBook eBook = this . eBookDao . queryEBookByEid ( matrix . get ( i ). eid );
resultList . add ( eBook );
// debug
System . out . println ( matrix . get ( i ). eid + "," + eBook . getEname ()+ ",interestValue=" + matrix . get ( i ). interestValue );
}
}
return EBookServiceImpl . initEBookImgAddress ( resultList );
}推奨されるモジュールは、計算結果をMatrixCテーブルに出力するために入力としてクローラーによってクロールされたデータを使用します。計算プロセス全体が2つの段階に分割されます。第1段階では、共起行列Cを計算します。2番目の段階は、ペアで表示される電子書籍のコサイン類似性Wを計算します。ユーザーが予測された関心に基づいて推奨される機能の場合、ユーザーは電子書籍データのリアルタイムと合計計算額が大きすぎることを好むため、ユーザーはページにアクセスするときにリアルタイムの計算を使用します。複数のテストの後、ユーザーの平均待機時間は許容範囲内にあります。
Douban MovieのWebページのアップグレードには反論測定が追加されているため、推奨アルゴリズムの実行に使用されるデータがここで提供されます。


