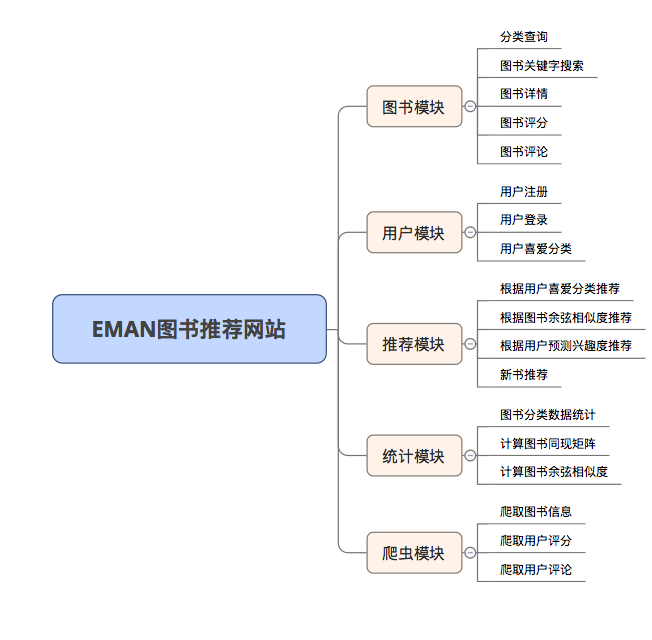
EMAN
1.0.0
Um sistema de recomendação de livros eletrônicos simples baseado no algoritmo de filtragem colaborativa do SSM e itens (itemcf)
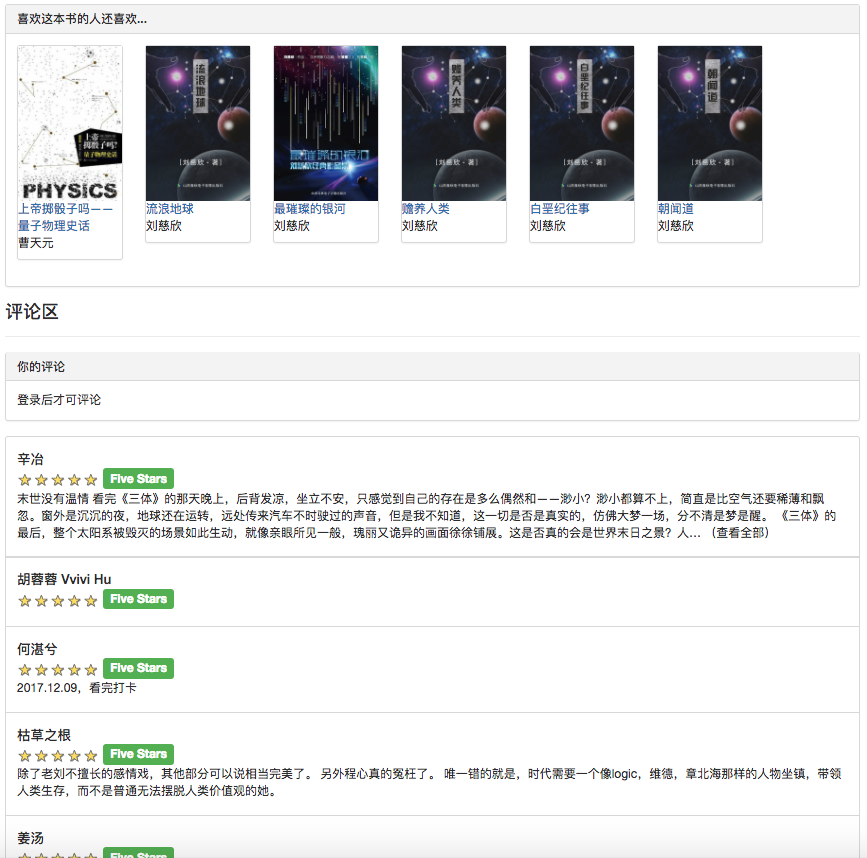
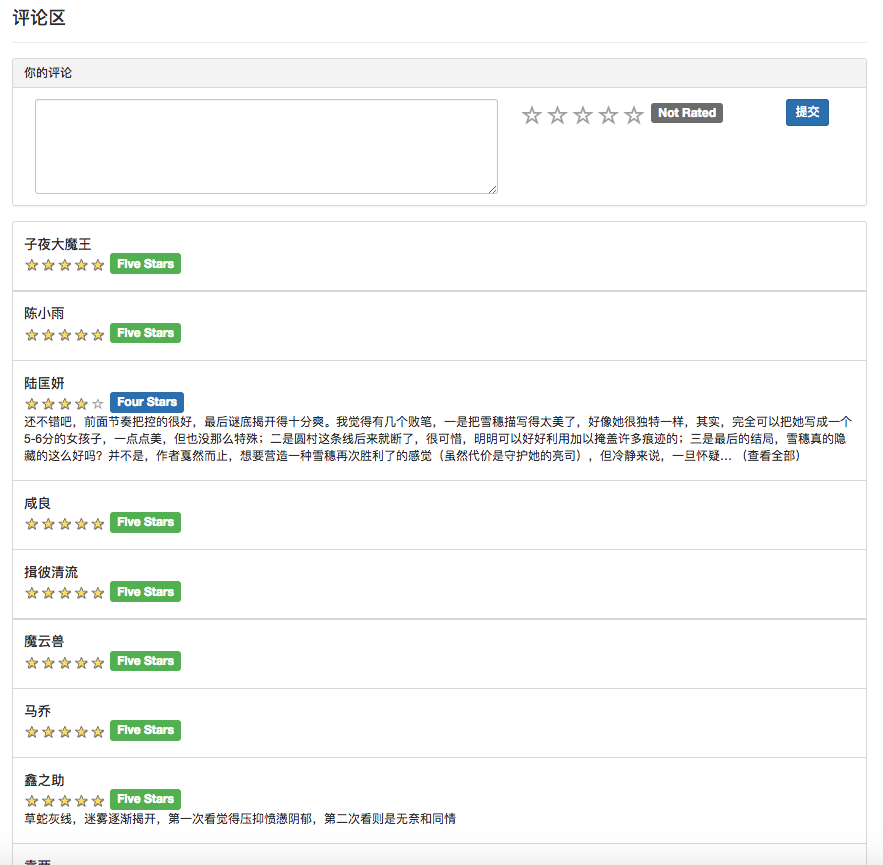
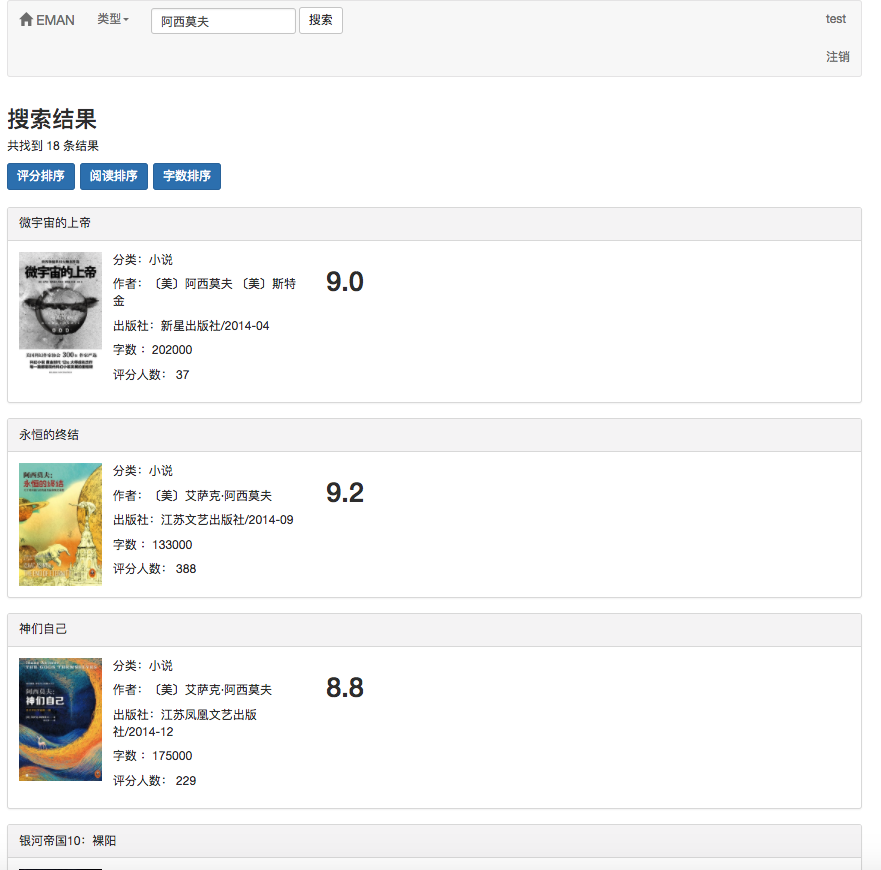
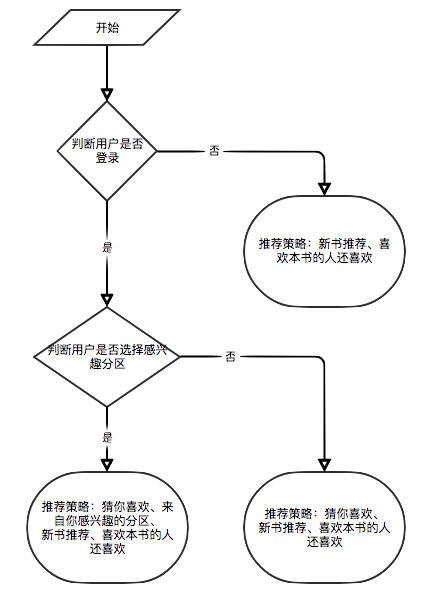
Porque alguns algoritmos de recomendação precisam usar os dados favoritos do usuário como parâmetros. Se o usuário não estiver conectado, a estratégia de recomendação para turistas será adotada. Se o usuário estiver conectado, a Política de Recomendação para o Usuário logada será adotada. Se o usuário logado tiver um registro de partição de interesse no banco de dados, será adicionada uma recomendação da partição. Portanto, a estratégia de recomendação é dividida em duas situações: se deve fazer login ou não.
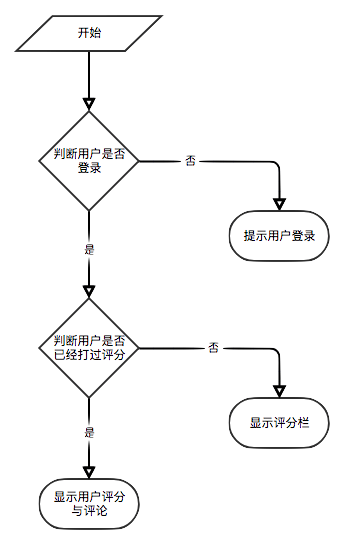
Se o usuário não estiver conectado, a estratégia de exibição de classificação do usuário para turistas será adotada. Se o usuário estiver conectado, a política de exibição de classificação do usuário para o usuário registrada será adotada. Se o usuário logado já tiver obtido o e-book na página de detalhes atuais, seu registro de classificação será exibido.
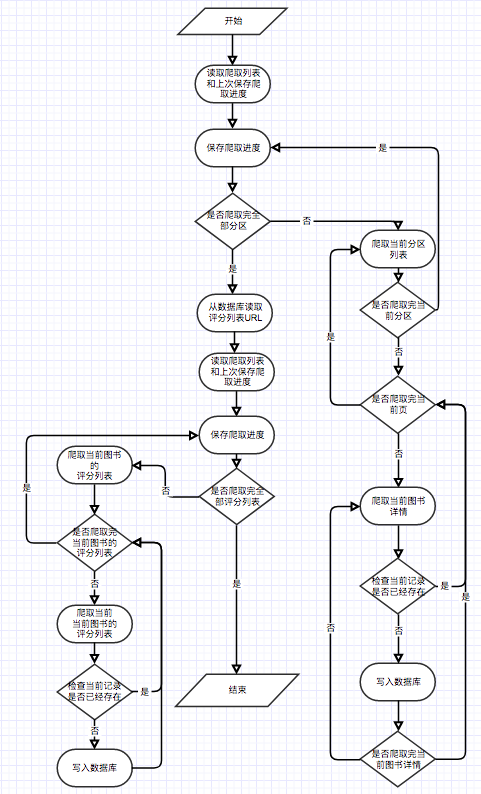
Conforme mostrado no diagrama de casos de uso, existem três usuários básicos neste sistema. São turistas, usuários registrados e administradores. Os visitantes podem visitar a página inicial da plataforma de recomendação de livros eletrônicos, página de registro do usuário e visualizar a página de livros eletrônicos. A função de registrar os usuários é que eles podem avaliar e comentar os e-books e recomendar e-books determinados pelo interesse previsto do usuário. Os administradores podem usar regularmente o módulo Crawler para atualizar as informações do e-book e usar o módulo de estatística para atualizar as estatísticas classificadas, a matriz de co-ocorrência de livros eletrônicos e a matriz de similaridade de cosseno.
! [Case.png do usuário] (/img/user case.png)
Considerando que há um problema de início frio com esse algoritmo. Ou seja, para novos usuários, eles geralmente não têm dados de classificação, o que leva à recomendação com base no nível de interesse previsto do usuário e não pode ser realizado sem problemas. Para resolver esse problema, adicionei um módulo para usar diretamente a matriz de similaridade Cosine W para executar diretamente recomendações semelhantes de livros eletrônicos, para que usuários não registrados e novos usuários possam obter melhor recomendações. Quanto aos problemas escassos da matriz de dados em algoritmos de filtragem colaborativa, alguns e-books impopulares podem não ter classificações de usuário, baixa correlação de livros eletrônicos e alguns usuários têm poucas classificações de e-book. Para resolver esse problema, adicione um novo módulo de recomendação do livro à página inicial para recomendar melhor os e-books que não têm classificação; Adicione um módulo de recomendação de partição para recomendar e-books com base no interesse do usuário, a fim de aumentar o interesse de usuários específicos para recomendar e-books. Vale ressaltar que o e-book recomendado pelos usuários para prever juros é calculado usando fórmulas na matriz de similaridade de cosseno W calculada por esse algoritmo. Além disso, o e-book favorito do usuário também é necessário como parâmetros de entrada durante o cálculo. O e-book semelhante recomendado é usar a matriz de similaridade de strings diretamente para estatísticas. Isso significa que as duas recomendações acima precisam concluir o cálculo da matriz de co-ocorrência do e-book e a matriz de similaridade de cosseno do e-book. Como as duas matrizes acima são computacionalmente grandes e todos os dados são necessários para cada cálculo, eles serão realizados regularmente pelo administrador.
Símbolo → Indica que a classe é uma operação manual regular de módulos

Existem duas etapas principais para o algoritmo de filtragem colaborativa com base em itens:
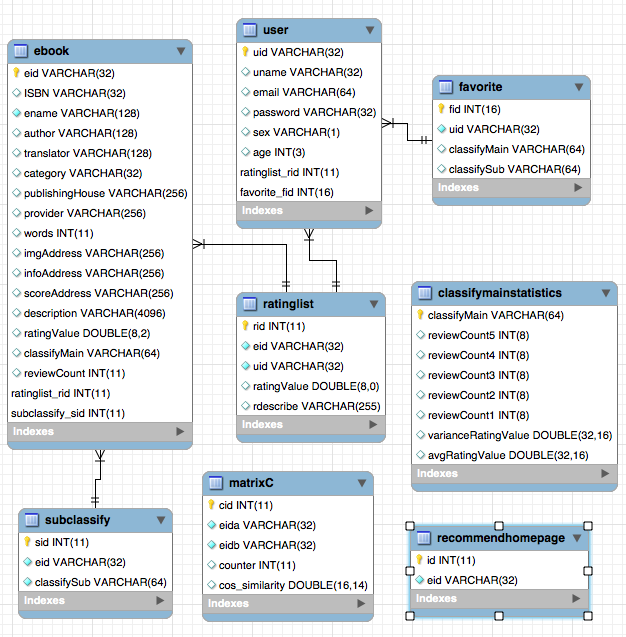
Suponha que n (i) seja o número de usuários que gostam do item i. N (i) ⋂n (j) representa o número de usuários que gostam de item I Item j ao mesmo tempo. Então a semelhança entre o item I e o item J é:
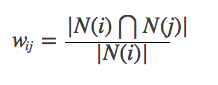
No entanto, a fórmula acima tem um defeito: quando o item J é um produto muito popular e todo mundo gosta, o Wij estará muito próximo de 1, ou seja, a fórmula acima fará com que muitos itens tenham uma grande semelhança com os produtos populares, para que você possa melhorar a fórmula:
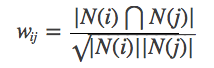
Crie uma lista de itens do usuário invertidos (suponha que letras maiúsculas representem usuários, letras minúsculas representam itens):

Calcule a matriz de co-ocorrência C (a matriz de co-ocorrência C representa o número de usuários que gostam de dois itens ao mesmo tempo e são calculados com base na tabela de inversão do item do usuário):
Como mostrado na figura, podemos ver que os elementos diagonais da matriz de co-ocorrência são todos 0 e são matrizes esparsas simétricas reais. O algoritmo é implementado da seguinte maneira:
com.statistics.itemCollaborationFilter
/**
* 计算共现矩阵C
*/
private void computerMatrixC (){
// 建立用户物品倒排表
// 若用户对物品评分大于等于4则认为喜欢(出现)
List < User > allUser = userDao . queryAllUser ();
for ( int i = 0 ; i < allUser . size (); i ++){ // 遍历全部用户
// 获取一个用户的评分列表中>=4的评分记录
List < RatingList > likeList = ratingListDao . selectRatingListByUidAndRatingValue ( allUser . get ( i ). getUid (), 4 );
if ( likeList . size () <= 1 ){ // 若用户只喜欢一本或不喜欢任何图书
continue ;
}
for ( int j = 0 ; j < likeList . size (); j ++){ // 计算likeList中两两出现的图书并写入同现矩阵C
for ( int k = j + 1 ; k < likeList . size (); k ++){
int a = Integer . valueOf ( likeList . get ( j ). getEid ());
int b = Integer . valueOf ( likeList . get ( k ). getEid ());
// 生成key
String key = null ;
if ( a < b ){
key = a + "," + b ;
} else {
key = b + "," + a ;
}
// 检查key是否已经存在
if ( this . matrixC . get ( key ) != null ){
int value = this . matrixC . get ( key );
this . matrixC . put ( key , value + 1 );
} else {
this . matrixC . put ( key , 1 );
}
}
}
System . out . println ( "[" + df . format ( new Date ())+ "]" + "[已完成" + i + ",共" + allUser . size ()+ "]:用户uid=" + allUser . get ( i ). getUid ()+ "的记录以计算完成,共" + likeList . size ()+ "本图书" );
}
}O número de vezes que cada item aparece é:

Calcule a matriz de similaridade de cosseno W: A matriz de similaridade de cosseno pode ser obtida usando a fórmula aprimorada.
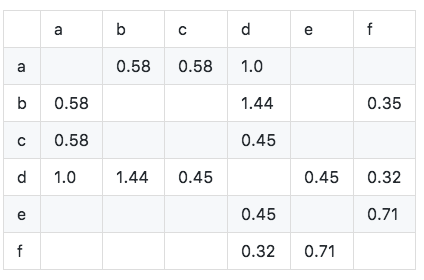
O algoritmo é implementado da seguinte maneira:
com.statistics.itemCollaborationFilter
/**
* 计算余弦相似度矩阵W
* 计算方法:
* 使用矩阵C的每个value作为分子,key中的两个图书的喜欢人数的积开根号作为分母
*/
private Double computerMatrixW ( String eida , String eidb , int value ){
DecimalFormat df = new DecimalFormat ( "#.##" );
// 查询每个图书有多少人喜欢
try {
Statement statemenet = conn . createStatement ();
ResultSet rs = statemenet . executeQuery ( "select count(rid) from ratinglist where eid = '" + eida + "' and ratingValue >= 4;" );
rs . next ();
int likeANum = rs . getInt ( "count(rid)" );
rs = statemenet . executeQuery ( "select count(rid) from ratinglist where eid = '" + eidb + "' and ratingValue >= 4;" );
rs . next ();
int likeBNum = rs . getInt ( "count(rid)" );
if ( likeANum == 0 )
likeANum = 1 ;
if ( likeBNum == 0 )
likeBNum = 1 ;
// 开始计算
Double answer = value * 1.0 / Math . sqrt ( likeANum * likeBNum );
// 精确到小数点后两位
Double result = Double . parseDouble ( df . format ( answer ));
// 返回计算结果
return result ;
} catch ( SQLException e ) {
e . printStackTrace ();
}
return null ;
}Qual item é finalmente recomendado é determinado pela previsão de interesse.
O item j prevê juros = interesse do item I de que o usuário gosta de × similaridade entre o item I e o item j.
Por exemplo: um usuário gosta de itens A, B e C. O interesse deles é 1, 2 e 2, respectivamente. Então o interesse previsto dos itens C, D, E e F são:
Portanto, o item D deve ser recomendado ao usuário. O algoritmo é implementado da seguinte maneira:
@ Override
public List < EBook > userRecommendedList ( String uid ) {
// 获取用户喜爱图书列表
List < RatingList > likeList = this . ratingListDao . selectRatingListByUidAndRatingValue ( uid , 4 );
// debug
System . out . println ( "uid=" + uid + "用户喜爱图书列表" );
for ( RatingList r : likeList ){
System . out . println ( r . getEid ()+ "," + r . getRatingValue ());
}
System . out . println ( "likeList.size=" + likeList . size ());
// 定义计算用矩阵
List < Item > matrix = new ArrayList <>();
// 将用户喜爱的图书作为矩阵的列
// 将与用户喜爱的图书同现的图书作为矩阵的行
// 建立工作矩阵
for ( int i = 0 ; i < likeList . size (); i ++){ // 遍历用户喜爱的图书
RatingList temp = likeList . get ( i );
// 获取同现图书
List < MatrixC > itemList = this . matrixCDao . selectMatrixCByEidAOrEidB ( temp . getEid (), temp . getEid ());
for ( int j = 0 ; j < itemList . size (); j ++){
MatrixC c = itemList . get ( j );
// 从matrixC的key中选出同现图书的eid
String sEid = null ;
if ( c . getEida (). equals ( temp . getEid ())){
sEid = c . getEidb ();
} else {
sEid = c . getEida ();
}
// 在行中查询同现图书是否存在
if ( matrix . indexOf ( sEid ) == - 1 ){ // 若列中不存在
double [] col = new double [ likeList . size ()];
// 将同现图书所在行对应喜爱图书的数组值设为对应的余弦相似度*用户喜爱程度(4分为1,5分为2)
col [ likeList . indexOf ( temp )] = c . getCos_similarity ()*( temp . getRatingValue ()- 3 );
matrix . add ( new Item ( sEid , col )); // 增加行
} else { // 若列中存在
// 则将同现图书所在行对应喜爱图书的数组值设为对应的余弦相似度*用户喜爱程度(4分为1,5分为2)
matrix . get ( matrix . indexOf ( sEid )). col [ likeList . indexOf ( temp )] = c . getCos_similarity ()*( temp . getRatingValue ()- 3 );
}
}
}
// 计算预测兴趣度
for ( int i = 0 ; i < matrix . size (); i ++){
Item item = matrix . get ( i );
double interestValue = 0 ;
for ( int j = 0 ; j < item . col . length ; j ++){
interestValue += item . col [ j ];
}
matrix . get ( i ). interestValue = interestValue ;
}
// 根据预测兴趣度进行排序
Collections . sort ( matrix );
// 返回推荐图书列表
List < EBook > resultList = new ArrayList <>();
for ( int i = 0 ; i < matrix . size () && i < 20 ; i ++){ // 返回排前10的书
if ( matrix . get ( i ). interestValue > 0 ){
EBook eBook = this . eBookDao . queryEBookByEid ( matrix . get ( i ). eid );
resultList . add ( eBook );
// debug
System . out . println ( matrix . get ( i ). eid + "," + eBook . getEname ()+ ",interestValue=" + matrix . get ( i ). interestValue );
}
}
return EBookServiceImpl . initEBookImgAddress ( resultList );
}O módulo recomendado usa os dados rastejados pelo rastreador como entrada para produzir os resultados do cálculo para a tabela Matrixc. Todo o processo de cálculo é dividido em 2 estágios. O primeiro estágio calcula a matriz de co-ocorrência C. O segundo estágio calcula a similaridade de cosseno w dos e-books que aparecem em pares. Para a função recomendada com base no interesse previsto do usuário, porque o usuário gosta da quantidade de cálculo total e de cálculo total dos dados do e-book é muito grande, o usuário usará cálculos em tempo real ao acessar a página. Após vários testes, o tempo médio de espera do usuário está dentro de um intervalo aceitável.
Como a atualização da página da Web de Douban Movie adicionou medidas anti-rastejamento, os dados usados para executar o algoritmo recomendado são fornecidos aqui.


