EMAN
1.0.0
SSM 프레임 워크 및 항목 협업 필터링 알고리즘 (ItemCF)을 기반으로 한 간단한 전자 책 추천 시스템
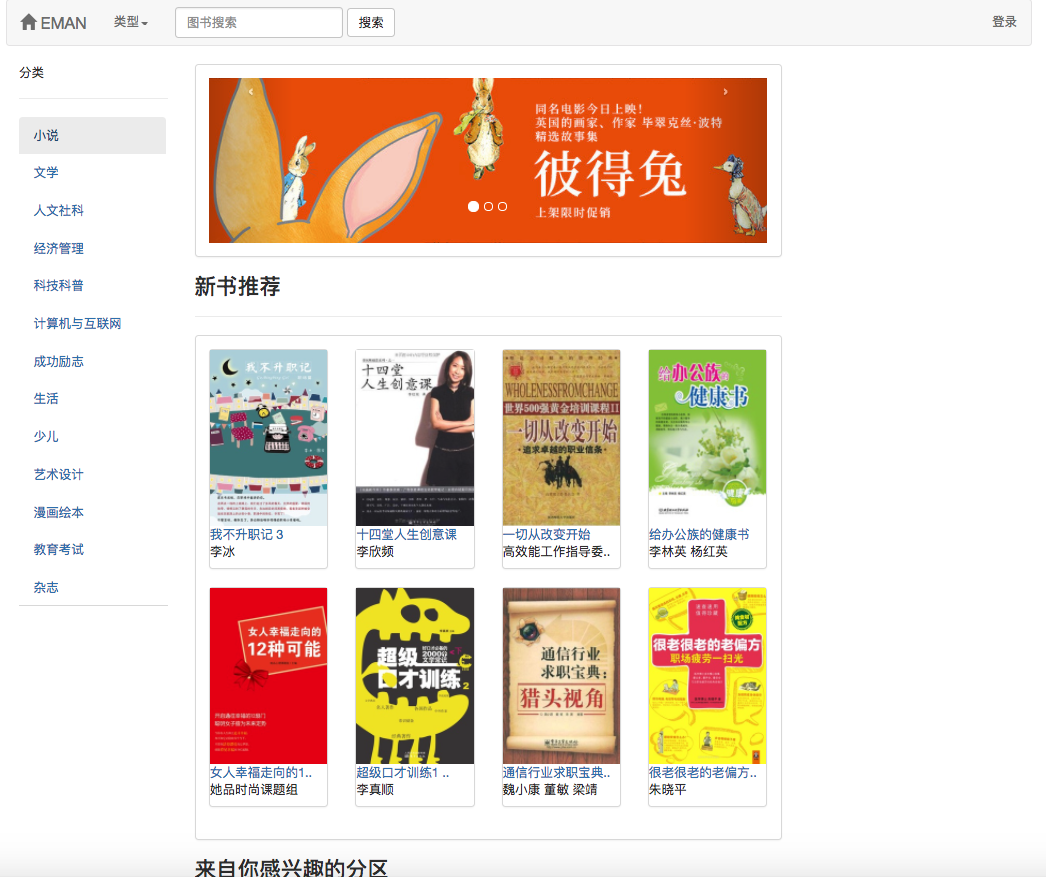
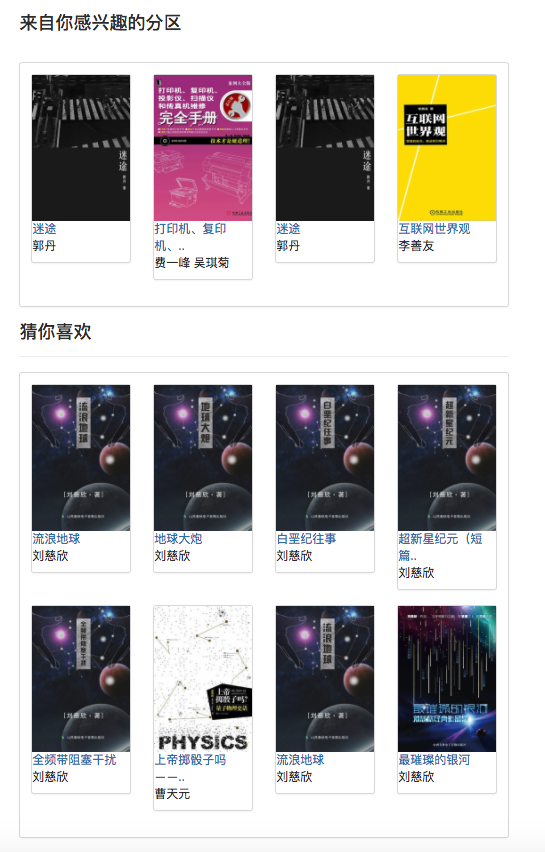
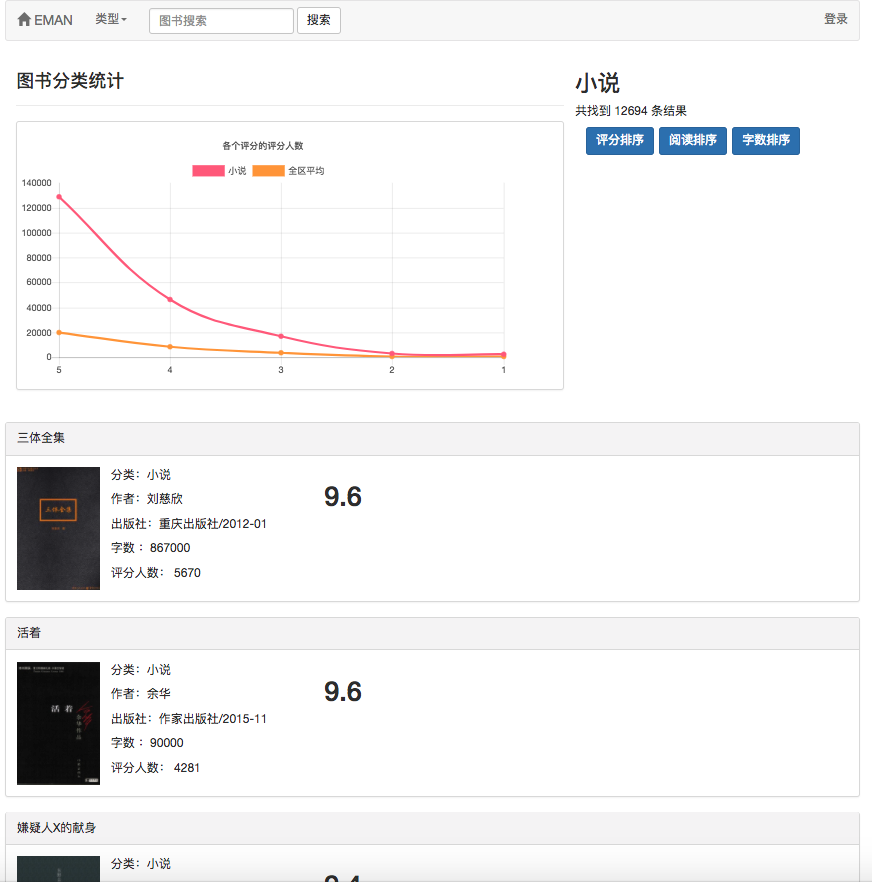
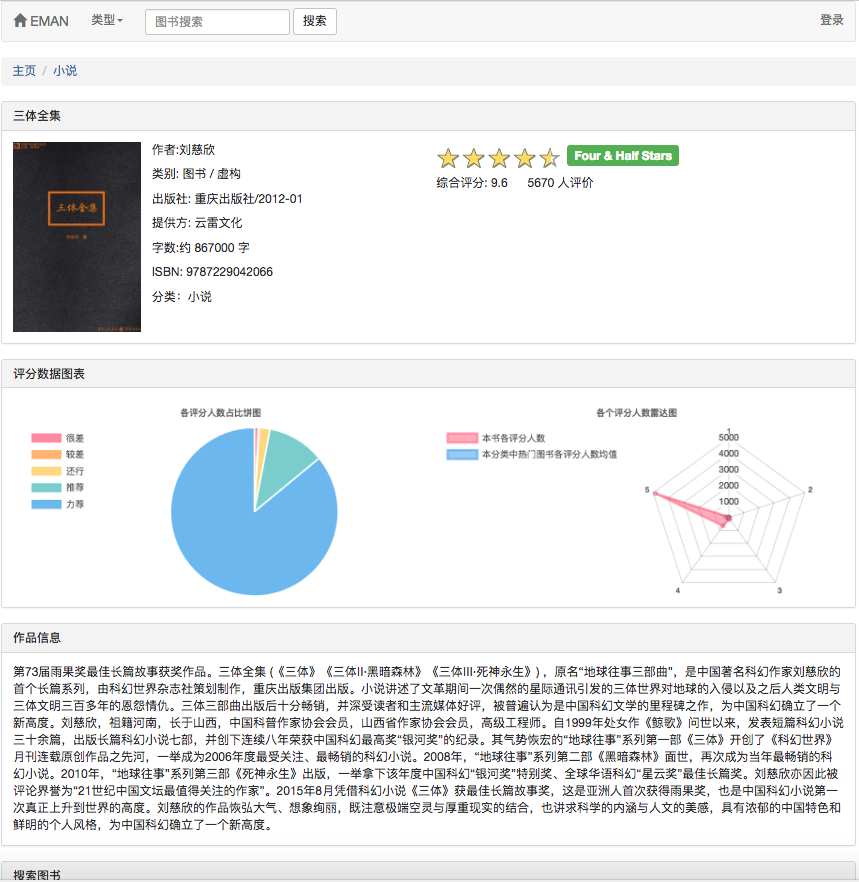
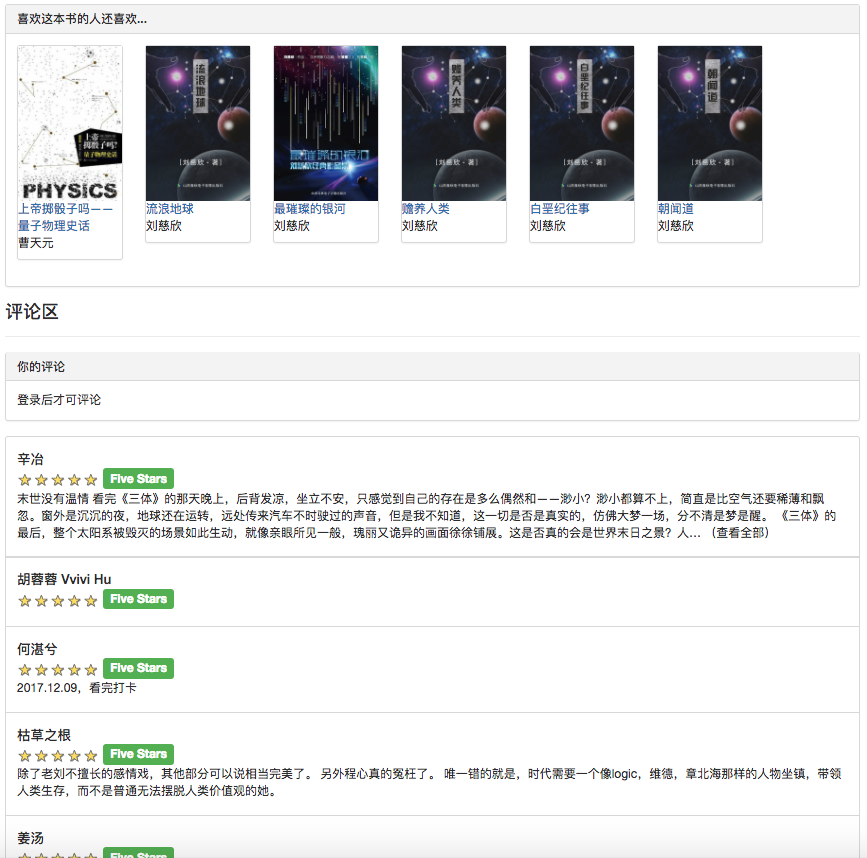
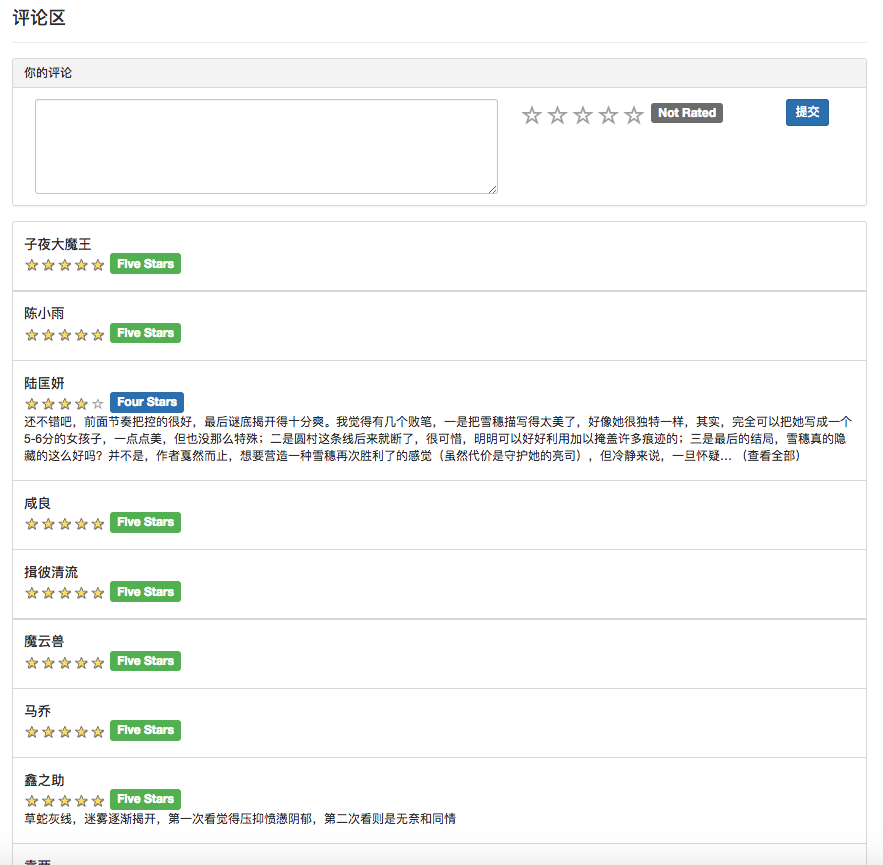
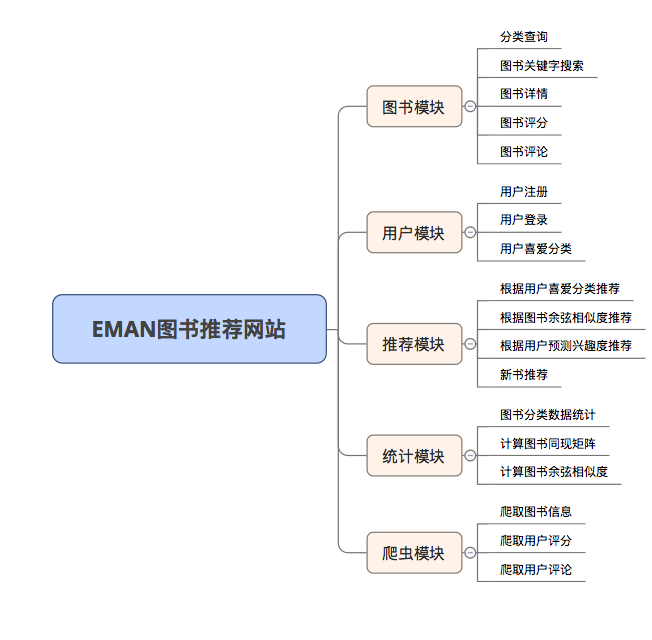
일부 권장 알고리즘은 사용자가 좋아하는 데이터를 매개 변수로 사용해야하기 때문입니다. 사용자가 로그인하지 않으면 관광객을위한 추천 전략이 채택됩니다. 사용자가 로그인하면 로그인 사용자의 권장 정책이 채택됩니다. 로그인 한 사용자가 데이터베이스에 관심있는 파티션 레코드가있는 경우 관심있는 파티션의 권장 사항이 추가됩니다. 따라서 권장 전략은 로그인 여부의 두 가지 상황으로 나뉩니다.
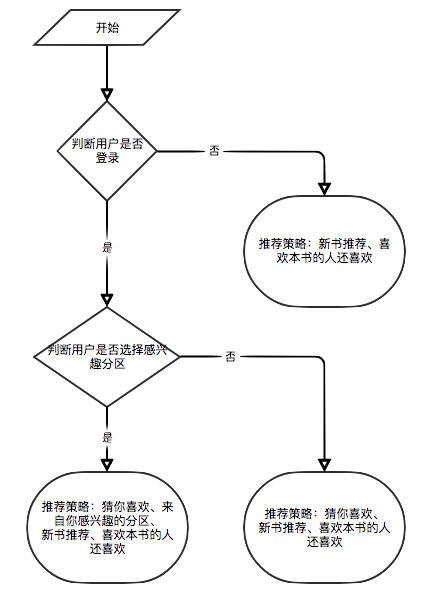
사용자가 로그인하지 않으면 관광객을위한 사용자 등급 표시 전략이 채택됩니다. 사용자가 로그인하면 로그인 한 사용자의 사용자 등급 표시 정책이 채택됩니다. 로그인 한 사용자가 이미 현재 세부 사항 페이지에서 전자 책을 득점 한 경우 등급 레코드가 표시됩니다.
유스 케이스 다이어그램에 표시된 것처럼이 시스템에는 세 가지 기본 사용자가 있습니다. 이들은 관광객, 등록 된 사용자 및 관리자입니다. 방문자는 전자 책 추천 플랫폼, 사용자 등록 페이지의 홈페이지를 방문하여 전자 책 페이지를 볼 수 있습니다. 사용자 등록 기능은 전자 책에 대해 평가하고 의견을 제시하고 사용자의 예측 관심사에 의해 결정된 전자 책을 추천 할 수 있다는 것입니다. 관리자는 Crawler 모듈을 정기적으로 사용하여 전자 책 정보를 업데이트하고 통계 모듈을 사용하여 분류 된 통계, 전자 책 동시 발생 매트릭스 및 전자 책 코사인 유사성 매트릭스를 업데이트 할 수 있습니다.
! [user case.png] (/img/user case.png)
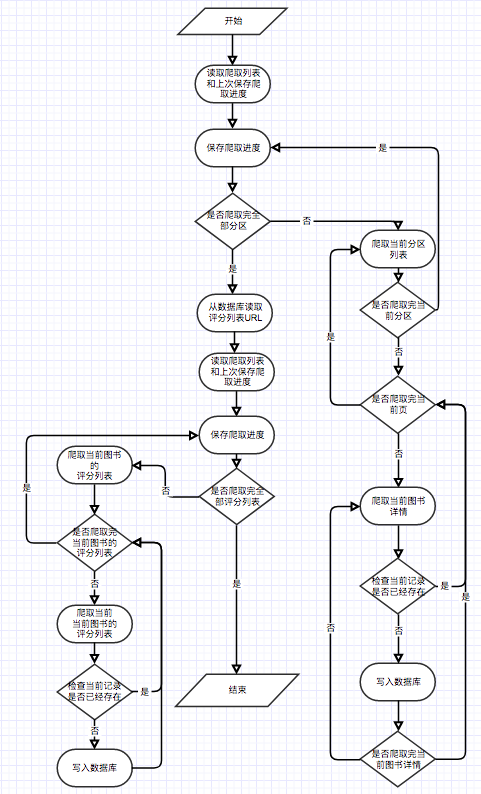
이 알고리즘에는 콜드 스타트 문제가 있음을 고려합니다. 즉, 새로운 사용자의 경우 등급 데이터가 부족하여 사용자의 예측 된이자 수준을 기반으로 권장 사항으로 이어지고 원활하게 수행 할 수 없습니다. 이 문제를 해결하기 위해 코사인 유사성 매트릭스 W를 직접 사용하여 유사한 전자 책 권장 사항을 직접 수행하여 등록되지 않은 사용자와 신규 사용자가 권장 사항을 더 잘 얻을 수 있도록 모듈을 추가했습니다. 공동 필터링 알고리즘의 희소 데이터 매트릭스 문제의 경우, 일부 인기없는 전자 책에는 사용자 등급이없고, 전자 책 상관 관계가 낮을 수 있으며 일부 사용자는 전자 책 등급이 거의 없습니다. 이 문제를 해결하려면 홈페이지에 새 책 권장 모듈을 추가하여 등급이없는 전자 책을 더 잘 추천하십시오. 전자 책을 추천하기 위해 특정 사용자의 관심을 높이기 위해 사용자의 관심사를 기반으로 전자 책을 추천하기 위해 파티션 추천 모듈을 추가하십시오. 이 알고리즘에 의해 계산 된 코사인 유사성 매트릭스 W에 대한 공식을 사용하여 사용자가 권장하는 전자 책은이 알고리즘에 의해 계산된다는 점은 주목할 가치가 있습니다. 또한 계산 중에 입력 매개 변수로서 사용자가 가장 좋아하는 전자 책도 필요합니다. 권장되는 유사한 전자 책은 통계에 직접 문자열 유사성 행렬 w를 사용하는 것입니다. 이는 위의 두 권장 사항이 전자 책의 동시 발생 매트릭스 계산과 전자 책의 코사인 유사성 행렬의 계산을 완료해야 함을 의미합니다. 위의 두 행렬은 계산적으로 크고 각 계산에 모든 데이터가 필요하므로 관리자가 정기적으로 수행하도록 설정됩니다.
기호 → 클래스가 모듈의 정기적 인 수동 작동임을 나타냅니다.

항목을 기반으로 한 협업 필터링 알고리즘에 대한 두 가지 주요 단계가 있습니다.
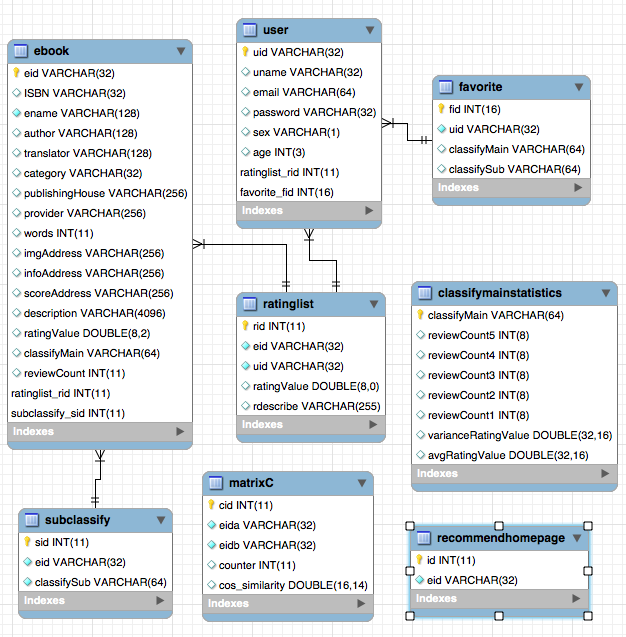
n (i)가 항목 i를 좋아하는 사용자의 수라고 가정합니다. n (i) ⋂n (j)은 항목 i 항목 J를 동시에 좋아하는 사용자의 수를 나타냅니다. 그런 다음 항목 i와 항목 j의 유사성은 다음과 같습니다.
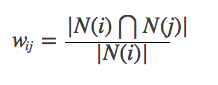
그러나 위의 공식에는 결함이 있습니다. 항목 J가 매우 인기있는 제품이고 모든 사람이 좋아하면 WIJ는 1에 매우 가깝습니다. 즉, 위의 공식은 많은 항목이 인기있는 제품과 유사하게 만들어 지므로 공식을 개선 할 수 있습니다.
거꾸로 된 사용자 항목 목록을 작성합니다 (대문자가 사용자를 나타내고 소문자가 항목을 나타냄).

동시 발생 행렬 C를 계산합니다 (동시 발생 매트릭스 C는 동시에 두 항목을 좋아하는 사용자의 수를 나타내며 사용자 항목 반전 테이블을 기반으로 계산) :
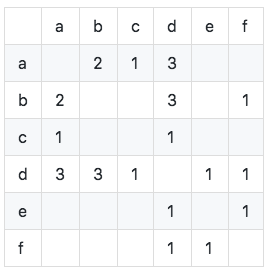
그림에서 볼 수 있듯이, 우리는 동시 발생 매트릭스의 대각선 요소가 모두 0이고 실제 대칭 희소 행렬임을 알 수 있습니다. 알고리즘은 다음과 같이 구현됩니다.
com.statistics.itemcollaborationFilter
/**
* 计算共现矩阵C
*/
private void computerMatrixC (){
// 建立用户物品倒排表
// 若用户对物品评分大于等于4则认为喜欢(出现)
List < User > allUser = userDao . queryAllUser ();
for ( int i = 0 ; i < allUser . size (); i ++){ // 遍历全部用户
// 获取一个用户的评分列表中>=4的评分记录
List < RatingList > likeList = ratingListDao . selectRatingListByUidAndRatingValue ( allUser . get ( i ). getUid (), 4 );
if ( likeList . size () <= 1 ){ // 若用户只喜欢一本或不喜欢任何图书
continue ;
}
for ( int j = 0 ; j < likeList . size (); j ++){ // 计算likeList中两两出现的图书并写入同现矩阵C
for ( int k = j + 1 ; k < likeList . size (); k ++){
int a = Integer . valueOf ( likeList . get ( j ). getEid ());
int b = Integer . valueOf ( likeList . get ( k ). getEid ());
// 生成key
String key = null ;
if ( a < b ){
key = a + "," + b ;
} else {
key = b + "," + a ;
}
// 检查key是否已经存在
if ( this . matrixC . get ( key ) != null ){
int value = this . matrixC . get ( key );
this . matrixC . put ( key , value + 1 );
} else {
this . matrixC . put ( key , 1 );
}
}
}
System . out . println ( "[" + df . format ( new Date ())+ "]" + "[已完成" + i + ",共" + allUser . size ()+ "]:用户uid=" + allUser . get ( i ). getUid ()+ "的记录以计算完成,共" + likeList . size ()+ "本图书" );
}
}각 항목이 나타나는 횟수는 다음과 같습니다.

코사인 유사성 매트릭스 W : 코사인 유사성 매트릭스는 개선 된 공식을 사용하여 얻을 수 있습니다.
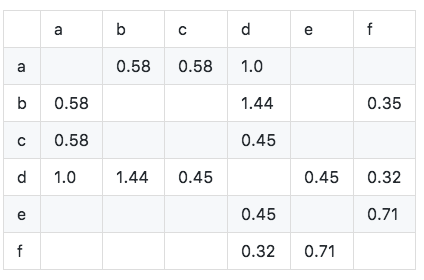
알고리즘은 다음과 같이 구현됩니다.
com.statistics.itemcollaborationFilter
/**
* 计算余弦相似度矩阵W
* 计算方法:
* 使用矩阵C的每个value作为分子,key中的两个图书的喜欢人数的积开根号作为分母
*/
private Double computerMatrixW ( String eida , String eidb , int value ){
DecimalFormat df = new DecimalFormat ( "#.##" );
// 查询每个图书有多少人喜欢
try {
Statement statemenet = conn . createStatement ();
ResultSet rs = statemenet . executeQuery ( "select count(rid) from ratinglist where eid = '" + eida + "' and ratingValue >= 4;" );
rs . next ();
int likeANum = rs . getInt ( "count(rid)" );
rs = statemenet . executeQuery ( "select count(rid) from ratinglist where eid = '" + eidb + "' and ratingValue >= 4;" );
rs . next ();
int likeBNum = rs . getInt ( "count(rid)" );
if ( likeANum == 0 )
likeANum = 1 ;
if ( likeBNum == 0 )
likeBNum = 1 ;
// 开始计算
Double answer = value * 1.0 / Math . sqrt ( likeANum * likeBNum );
// 精确到小数点后两位
Double result = Double . parseDouble ( df . format ( answer ));
// 返回计算结果
return result ;
} catch ( SQLException e ) {
e . printStackTrace ();
}
return null ;
}궁극적으로 권장되는 항목은 관심을 예측하여 결정됩니다.
항목 j는 항목 i와 항목 j 사이의 × 유사성을 좋아하는 항목 i의 관심 = 관심을 예측합니다.
예 : 사용자는 항목 A, B 및 c를 좋아합니다. 그들의 관심은 각각 1, 2 및 2입니다. 그런 다음 항목 C, D, E 및 F의 예측 된 관심은 다음과 같습니다.
따라서 항목 D를 사용자에게 권장해야합니다. 알고리즘은 다음과 같이 구현됩니다.
@ Override
public List < EBook > userRecommendedList ( String uid ) {
// 获取用户喜爱图书列表
List < RatingList > likeList = this . ratingListDao . selectRatingListByUidAndRatingValue ( uid , 4 );
// debug
System . out . println ( "uid=" + uid + "用户喜爱图书列表" );
for ( RatingList r : likeList ){
System . out . println ( r . getEid ()+ "," + r . getRatingValue ());
}
System . out . println ( "likeList.size=" + likeList . size ());
// 定义计算用矩阵
List < Item > matrix = new ArrayList <>();
// 将用户喜爱的图书作为矩阵的列
// 将与用户喜爱的图书同现的图书作为矩阵的行
// 建立工作矩阵
for ( int i = 0 ; i < likeList . size (); i ++){ // 遍历用户喜爱的图书
RatingList temp = likeList . get ( i );
// 获取同现图书
List < MatrixC > itemList = this . matrixCDao . selectMatrixCByEidAOrEidB ( temp . getEid (), temp . getEid ());
for ( int j = 0 ; j < itemList . size (); j ++){
MatrixC c = itemList . get ( j );
// 从matrixC的key中选出同现图书的eid
String sEid = null ;
if ( c . getEida (). equals ( temp . getEid ())){
sEid = c . getEidb ();
} else {
sEid = c . getEida ();
}
// 在行中查询同现图书是否存在
if ( matrix . indexOf ( sEid ) == - 1 ){ // 若列中不存在
double [] col = new double [ likeList . size ()];
// 将同现图书所在行对应喜爱图书的数组值设为对应的余弦相似度*用户喜爱程度(4分为1,5分为2)
col [ likeList . indexOf ( temp )] = c . getCos_similarity ()*( temp . getRatingValue ()- 3 );
matrix . add ( new Item ( sEid , col )); // 增加行
} else { // 若列中存在
// 则将同现图书所在行对应喜爱图书的数组值设为对应的余弦相似度*用户喜爱程度(4分为1,5分为2)
matrix . get ( matrix . indexOf ( sEid )). col [ likeList . indexOf ( temp )] = c . getCos_similarity ()*( temp . getRatingValue ()- 3 );
}
}
}
// 计算预测兴趣度
for ( int i = 0 ; i < matrix . size (); i ++){
Item item = matrix . get ( i );
double interestValue = 0 ;
for ( int j = 0 ; j < item . col . length ; j ++){
interestValue += item . col [ j ];
}
matrix . get ( i ). interestValue = interestValue ;
}
// 根据预测兴趣度进行排序
Collections . sort ( matrix );
// 返回推荐图书列表
List < EBook > resultList = new ArrayList <>();
for ( int i = 0 ; i < matrix . size () && i < 20 ; i ++){ // 返回排前10的书
if ( matrix . get ( i ). interestValue > 0 ){
EBook eBook = this . eBookDao . queryEBookByEid ( matrix . get ( i ). eid );
resultList . add ( eBook );
// debug
System . out . println ( matrix . get ( i ). eid + "," + eBook . getEname ()+ ",interestValue=" + matrix . get ( i ). interestValue );
}
}
return EBookServiceImpl . initEBookImgAddress ( resultList );
}권장 모듈은 Crawler가 크롤링 한 데이터를 입력으로 사용하여 계산 결과를 Matrixc 테이블에 출력합니다. 전체 계산 프로세스는 2 단계로 나뉩니다. 첫 번째 단계는 동시 발생 매트릭스 C를 계산합니다. 두 번째 단계는 쌍으로 나타나는 전자 책의 코사인 유사성을 계산합니다. 사용자 예측 관심사를 기반으로 권장되는 기능의 경우, 사용자가 실시간 및 총 계산 금액을 좋아하기 때문에 전자 책 데이터의 전체 계산량이 너무 크기 때문에 사용자는 페이지에 액세스 할 때 실시간 계산을 사용합니다. 여러 테스트 후 사용자의 평균 대기 시간은 허용 범위 내에 있습니다.
Douban Movie Web Page 업그레이드는 크롤링 조치 방지 측정을 추가했기 때문에 권장 알고리즘을 실행하는 데 사용되는 데이터가 여기에 제공됩니다.


