repsys
1.0.0
O Repsys é uma estrutura para desenvolver e analisar sistemas de recomendação e permite:

Agora você pode experimentar o Repsys Online em nosso site de demonstração com o conjunto de dados do MovieLENS. Além disso, confira uma postagem interativa do blog que fizemos usando o componente Widgets Repsys.
Nosso artigo "Repsys: estrutura para avaliação interativa de sistemas de recomendação" foi aceita na conferência Recsys'22.
Instale o pacote usando PIP:
$ pip install repsys-framework
Se você usará o Pymde para visualização de dados, precisará instalar o Repsys com os seguintes extras:
$ pip install repsys-framework[pymde]
Se você deseja pular este tutorial e experimentar a estrutura, poderá puxar o conteúdo da pasta de demonstração localizada no repositório. Como mencionado na próxima etapa, você ainda precisa baixar o conjunto de dados antes de começar.
Caso contrário, crie uma pasta de projeto vazia que conterá o conjunto de dados e a implementação de modelos.
├── __init__.py
├── dataset.py
├── models.py
├── repsys.ini
└── .gitignore
Em primeiro lugar, precisamos importar nosso conjunto de dados. Usaremos o conjunto de dados do MovieLens 20M com 20 milhões de classificações feitas por 138.000 usuários para 27.000 filmes para o objetivo do tutorial. Faça o download do arquivo ml-20m.zip e descubra os dados na pasta atual. Em seguida, adicione o seguinte conteúdo ao arquivo dataset.py :
import pandas as pd
from repsys import Dataset
import repsys . dtypes as dtypes
class MovieLens ( Dataset ):
def name ( self ):
return "ml20m"
def item_cols ( self ):
return {
"movieId" : dtypes . ItemID (),
"title" : dtypes . Title (),
"genres" : dtypes . Tag ( sep = "|" ),
"year" : dtypes . Number ( data_type = int ),
}
def interaction_cols ( self ):
return {
"movieId" : dtypes . ItemID (),
"userId" : dtypes . UserID (),
"rating" : dtypes . Interaction (),
}
def load_items ( self ):
df = pd . read_csv ( "./ml-20m/movies.csv" )
df [ "year" ] = df [ "title" ]. str . extract ( r"((d+))" )
return df
def load_interactions ( self ):
df = pd . read_csv ( "./ml-20m/ratings.csv" )
return dfEste código definirá um novo conjunto de dados chamado ML20M e importará os dados de classificações e itens. Você sempre deve especificar sua estrutura de dados usando tipos de dados predefinidos. Antes de retornar os dados, você também pode pré -processá -los como extrair o ano do filme da coluna do título.
Agora definimos o primeiro modelo de recomendação, que será uma implementação simples do KNN baseado no usuário.
import numpy as np
import scipy . sparse as sp
from sklearn . neighbors import NearestNeighbors
from repsys import Model
class KNN ( Model ):
def __init__ ( self ):
self . model = NearestNeighbors ( n_neighbors = 20 , metric = "cosine" )
def name ( self ):
return "knn"
def fit ( self , training = False ):
X = self . dataset . get_train_data ()
self . model . fit ( X )
def predict ( self , X , ** kwargs ):
if X . count_nonzero () == 0 :
return np . random . uniform ( size = X . shape )
distances , indices = self . model . kneighbors ( X )
distances = distances [:, 1 :]
indices = indices [:, 1 :]
distances = 1 - distances
sums = distances . sum ( axis = 1 )
distances = distances / sums [:, np . newaxis ]
def f ( dist , idx ):
A = self . dataset . get_train_data ()[ idx ]
D = sp . diags ( dist )
return D . dot ( A ). sum ( axis = 0 )
vf = np . vectorize ( f , signature = "(n),(n)->(m)" )
predictions = vf ( distances , indices )
predictions [ X . nonzero ()] = 0
return predictionsVocê deve definir o método de ajuste para treinar seu modelo usando os dados de treinamento ou carregar o modelo anteriormente treinado em um arquivo. Todos os modelos são ajustados quando o aplicativo da Web é iniciado ou o processo de avaliação começa. Se essa não for uma fase de treinamento, sempre carregue seu modelo do ponto de verificação para acelerar o processo. Para fins tutoriais, isso é omitido.
Você também deve definir o método de previsão que recebe uma matriz esparsa das interações dos usuários na entrada. Para cada usuário (linha da matriz) e item (coluna da matriz), o método deve retornar uma pontuação prevista, indicando quanto o usuário apreciará o item.
Além disso, você pode especificar alguns parâmetros de aplicativos da Web que você pode definir durante a criação de recomendação. O valor é então acessível no argumento **kwargs do método de previsão. No exemplo, criamos uma entrada selecionada com todos os gêneros exclusivos e filtramos apenas os filmes que não contêm o gênero selecionado.
O último arquivo que devemos criar é uma configuração que permite controlar um processo de divisão de dados, configurações do servidor, comportamento da estrutura etc.
[general]
seed =1234
[dataset]
train_split_prop =0.85
test_holdout_prop =0.2
min_user_interacts =5
min_item_interacts =0
[evaluation]
precision_recall_k =20,50
ndcg_k =100
coverage_k =20
diversity_k =20
novelty_k =20
percentage_lt_k =20
coverage_lt_k =20
[visualization]
embed_method =pymde
pymde_neighbors =15
umap_neighbors =15
umap_min_dist =0.1
tsne_perplexity =30
[server]
port =3001Antes de treinarmos nossos modelos, precisamos dividir os dados em conjuntos de trens, validação e testes. Execute o seguinte comando no diretório atual.
$ repsys dataset split
Isso manterá 85% dos usuários como dados de treinamento, e o restante 15% será usado como dados de validação/teste, com 7,5% dos usuários cada. Para validação e conjunto de testes, 20% das interações também serão mantidas para fins de avaliação. O conjunto de dados dividido será armazenado na pasta Pontos de verificação padrão.
Agora podemos mudar para o processo de treinamento. Para fazer isso, ligue para o seguinte comando.
$ repsys model train
Este comando chamará o método de ajuste de cada modelo com o sinalizador de treinamento definido como true. Você sempre pode limitar os modelos usando sinalizador -m com o nome do modelo como um parâmetro.
Quando os dados são preparados e os modelos treinados, podemos avaliar o desempenho dos modelos nas interações dos usuários invisíveis. Execute o seguinte comando para fazê -lo.
$ repsys model eval
Novamente, você pode limitar os modelos usando o sinalizador -m . Os resultados serão armazenados na pasta dos pontos de verificação quando a avaliação for feita.
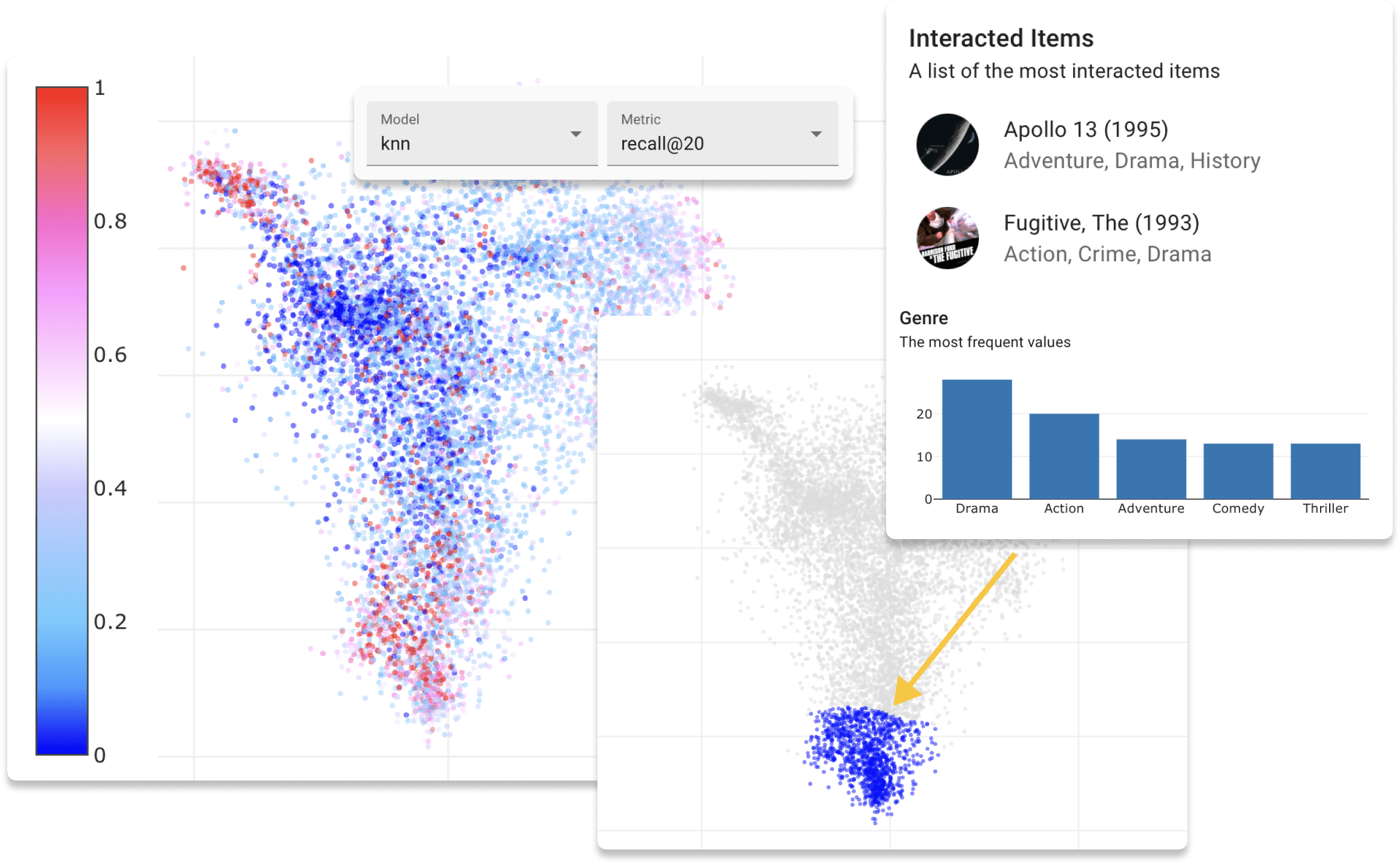
Antes de iniciar o aplicativo da Web, a etapa final é avaliar os dados do conjunto de dados. Este procedimento criará usuários e itens incorporados dos dados de treinamento e validação para permitir que você explore o espaço latente. Execute o seguinte comando no diretório do projeto.
$ repsys dataset eval
Você pode escolher entre três tipos de algoritmo de incorporação:
--method umap (esta é a opção padrão).--method pymde .--method tsne .--method custom e adicione o seguinte método à classe do modelo de sua escolha. Nesse caso, você também deve especificar o nome do modelo usando o parâmetro -m . from sklearn . decomposition import NMF
def compute_embeddings ( self , X ):
nmf = NMF ( n_components = 2 )
W = nmf . fit_transform ( X )
H = nmf . components_
return W , H . TNo exemplo, a fatorização da matriz negativa é usada. Você precisa devolver um par de incorporação de usuário e item nesse pedido. Além disso, é essencial retornar as matrizes na forma de (n_users/n_items, n_dim). Se a dimensão reduzida for superior a 2, o método TSNE será aplicado.
Por fim, é hora de iniciar o aplicativo da Web para ver os resultados das avaliações e visualizar as recomendações ao vivo de seus modelos.
$ repsys server
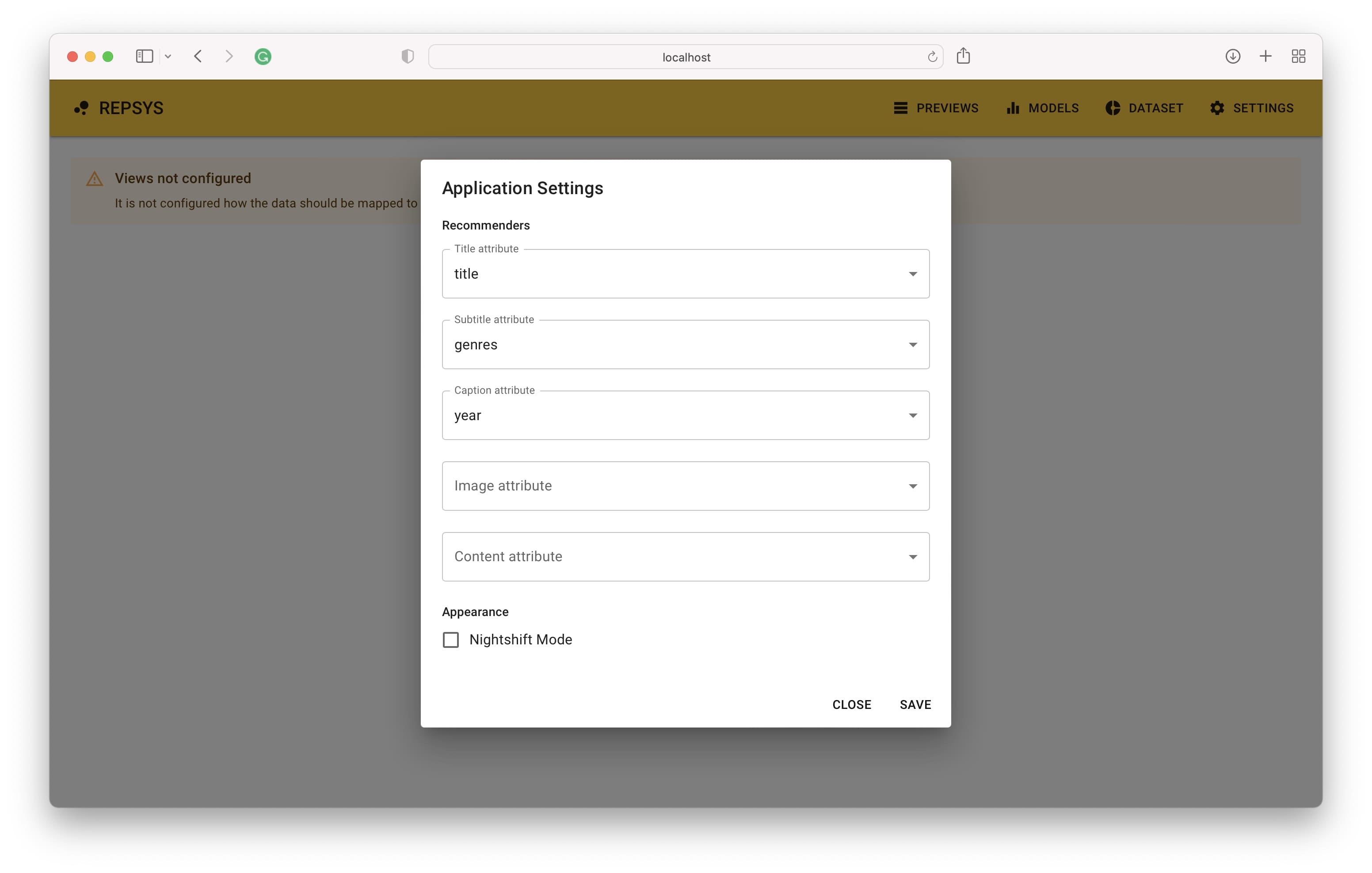
O aplicativo deve estar acessível no endereço padrão http: // localhost: 3001. Ao abrir o link, você verá a tela principal onde suas recomendações aparecem quando terminar a configuração. A primeira etapa é definir como as colunas de dados dos itens devem ser mapeadas para os componentes de exibição do item.
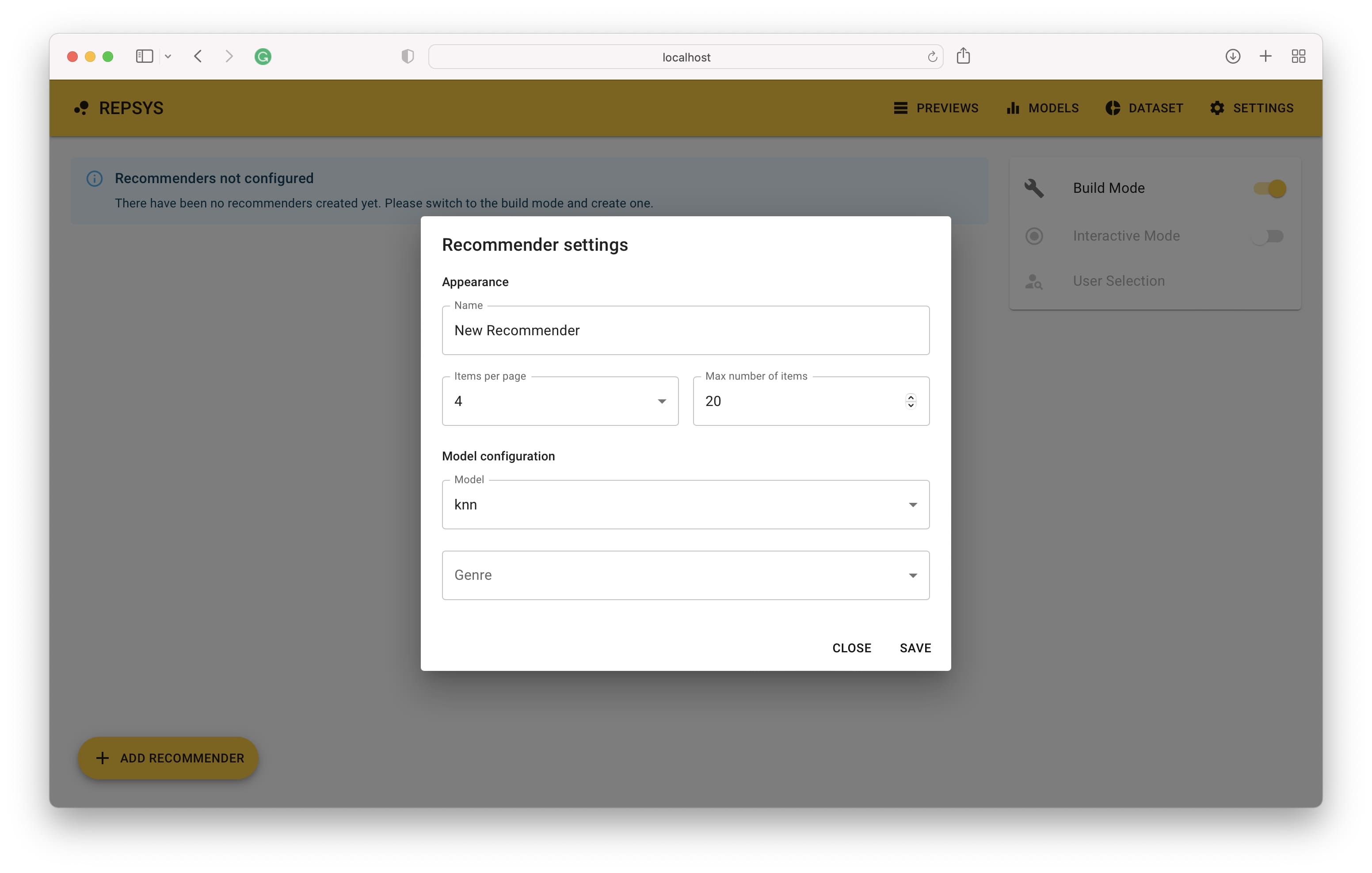
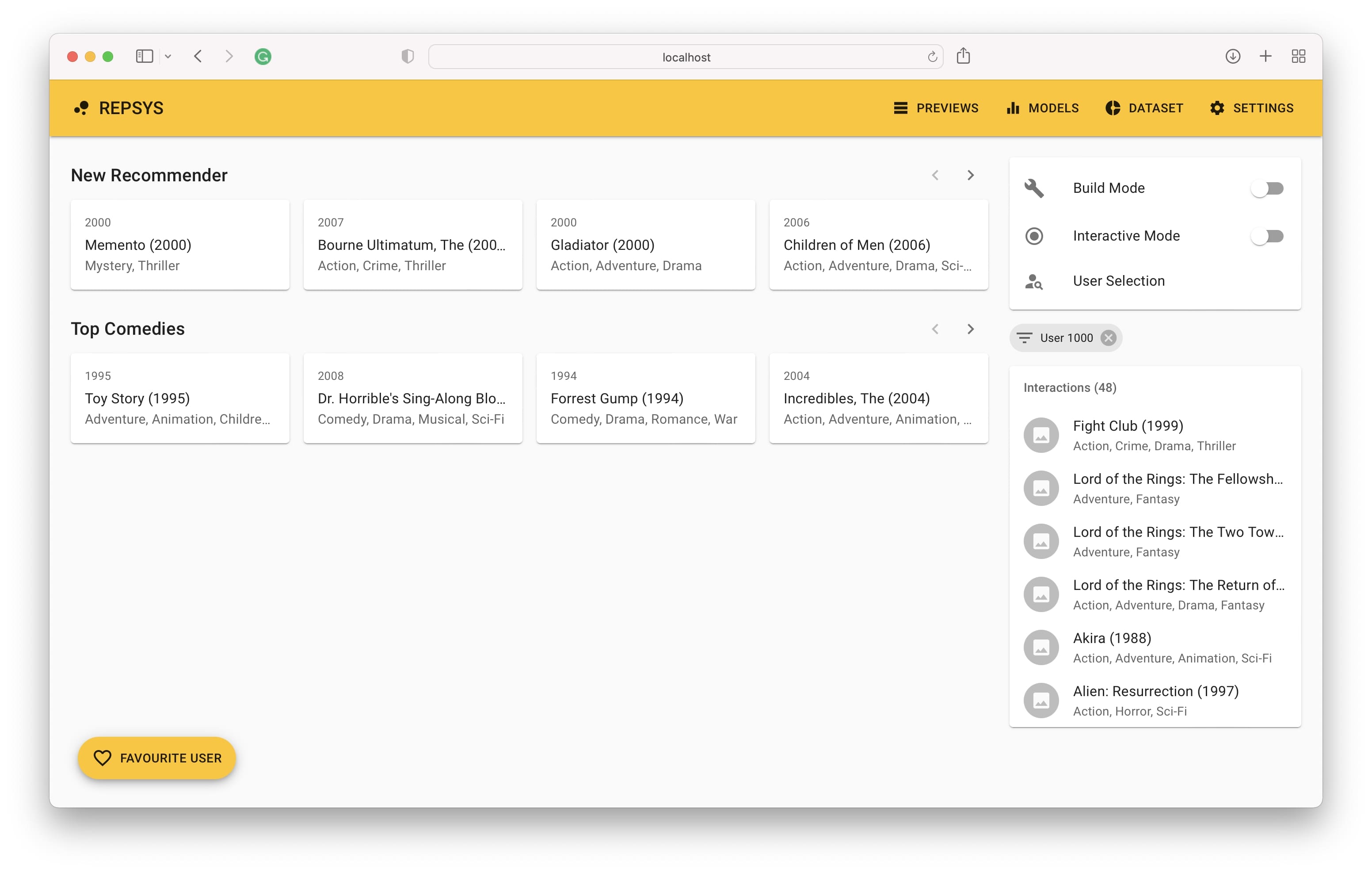
Em seguida, precisamos mudar para o modo de construção e adicionar dois recomendadores - um sem filtro e o segundo com apenas filmes de comédia incluídos.
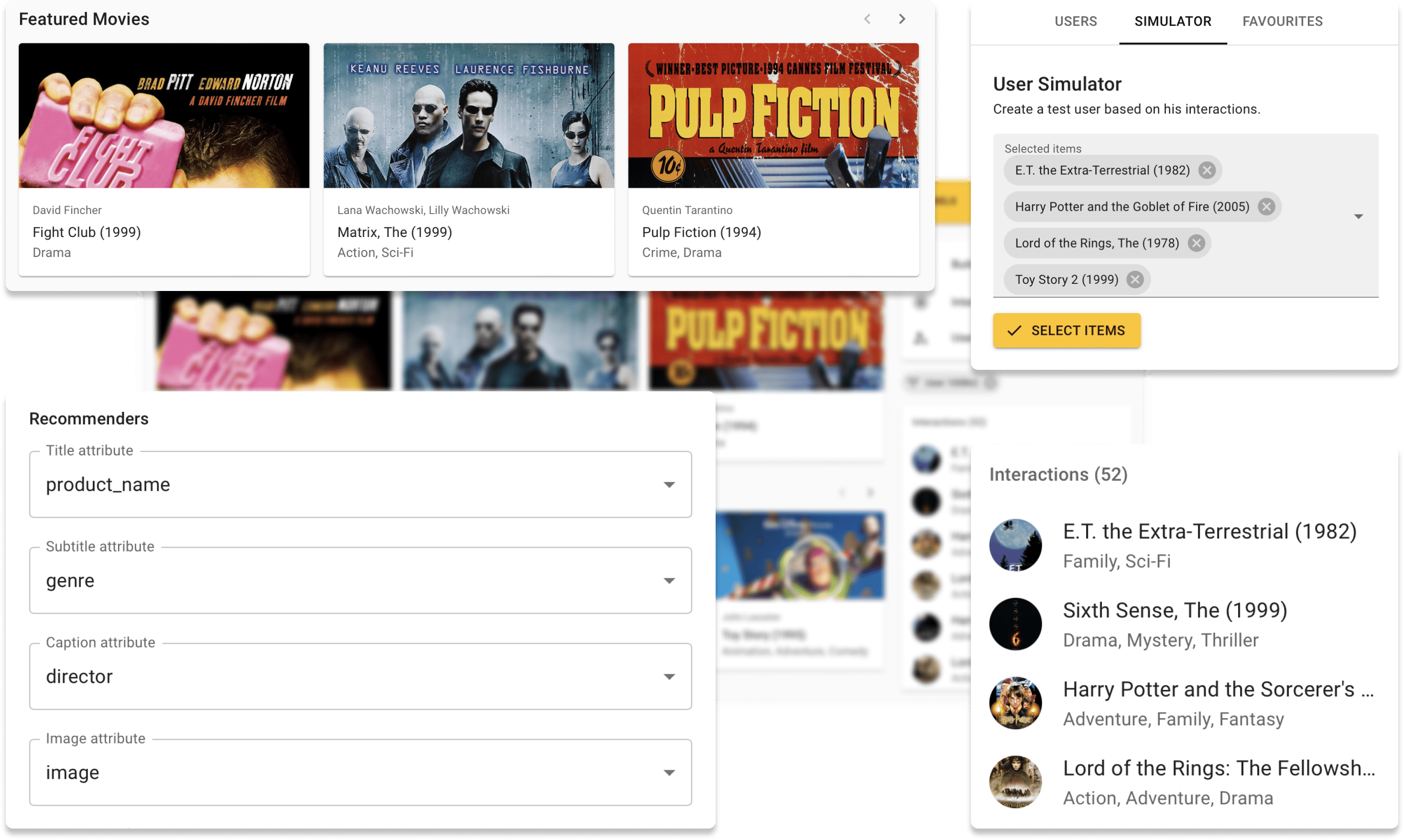
Agora, voltamos do modo de construção e selecionamos um usuário no conjunto de validação (nunca visto por um modelo antes).
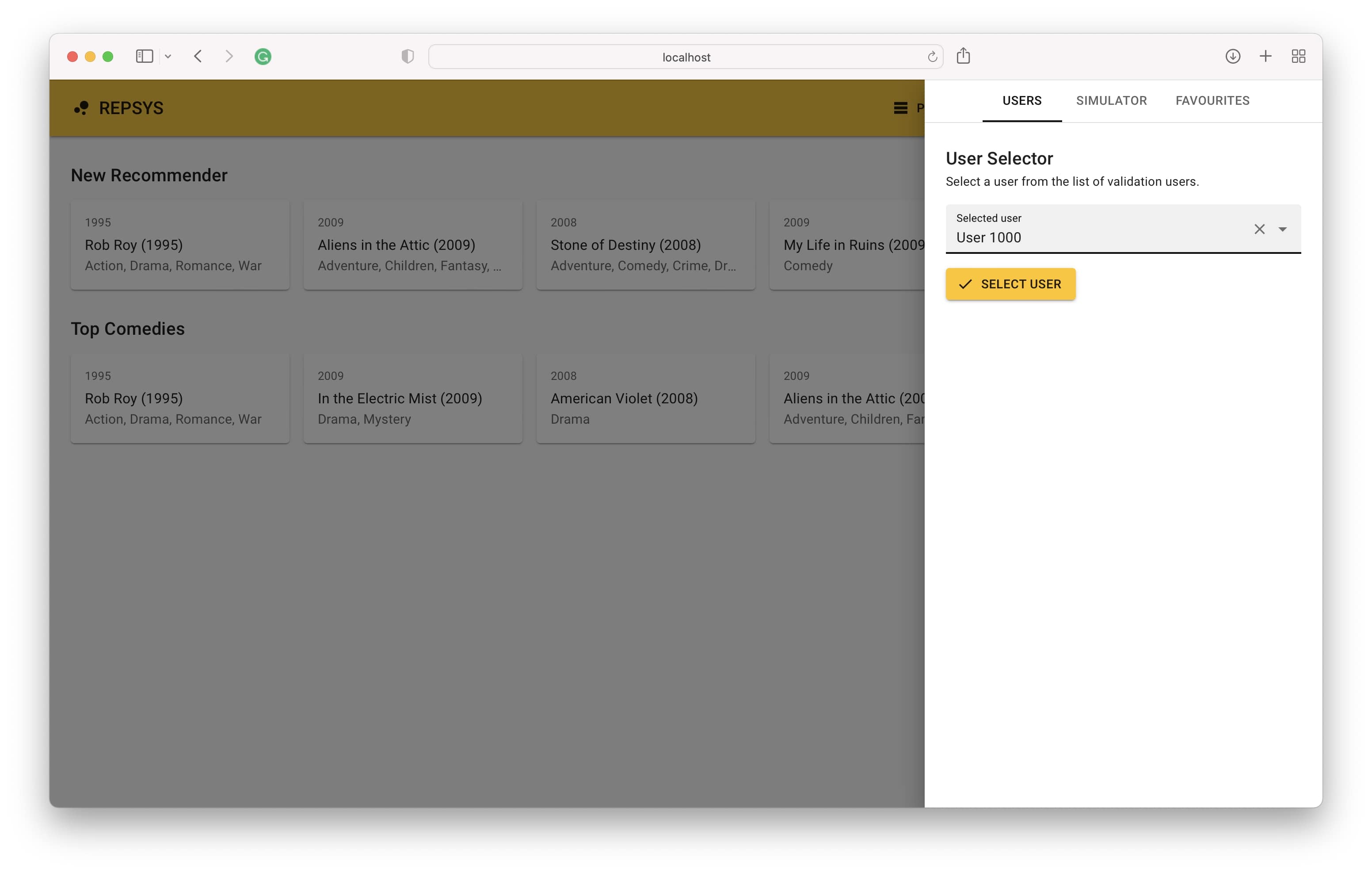
Por fim, vemos o histórico de interação do usuário no lado direito e as recomendações feitas pelo modelo no lado esquerdo.
Para construir o pacote a partir da fonte, você primeiro precisa instalar a biblioteca Node.js e NPM, conforme documentado aqui. Em seguida, você pode executar o seguinte script no diretório raiz para criar o aplicativo da web e instalar o pacote localmente.
$ ./scripts/install-locally.sh
Se você emprega Repsys em seu trabalho de pesquisa, não se esqueça de citar o artigo relacionado:
@inproceedings{10.1145/3523227.3551469,
author = {v{S}afav{r}'{i}k, Jan and Vanv{c}ura, Vojtv{e}ch and Kord'{i}k, Pavel},
title = {RepSys: Framework for Interactive Evaluation of Recommender Systems},
year = {2022},
isbn = {9781450392785},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3523227.3551469},
doi = {10.1145/3523227.3551469},
booktitle = {Proceedings of the 16th ACM Conference on Recommender Systems},
pages = {636–639},
numpages = {4},
keywords = {User simulation, Distribution analysis, Recommender systems},
location = {Seattle, WA, USA},
series = {RecSys '22}
}
O desenvolvimento dessa estrutura é patrocinado pela The Recombee Company.



