repsys
1.0.0
代表是開發和分析推薦系統的框架,它使您可以:
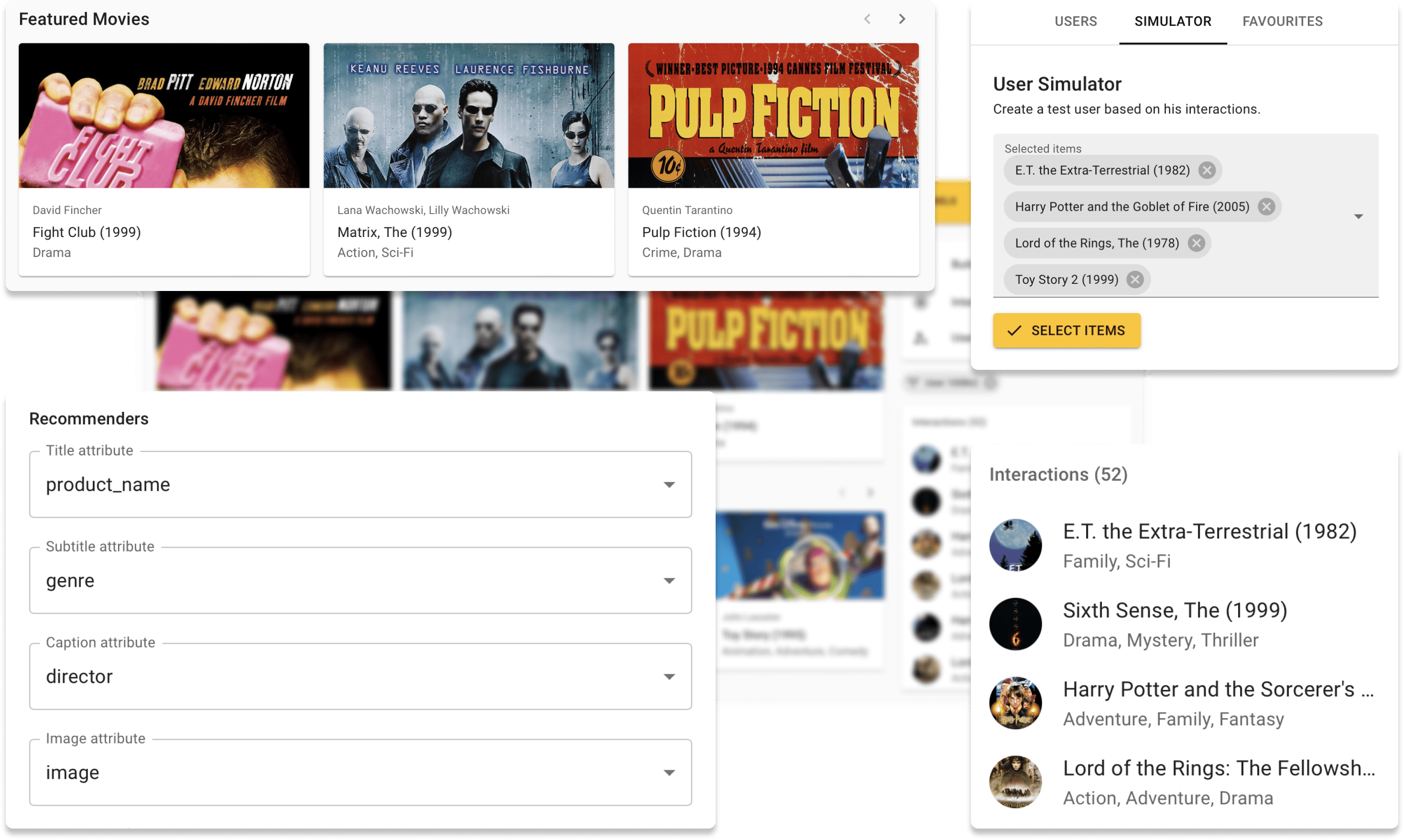
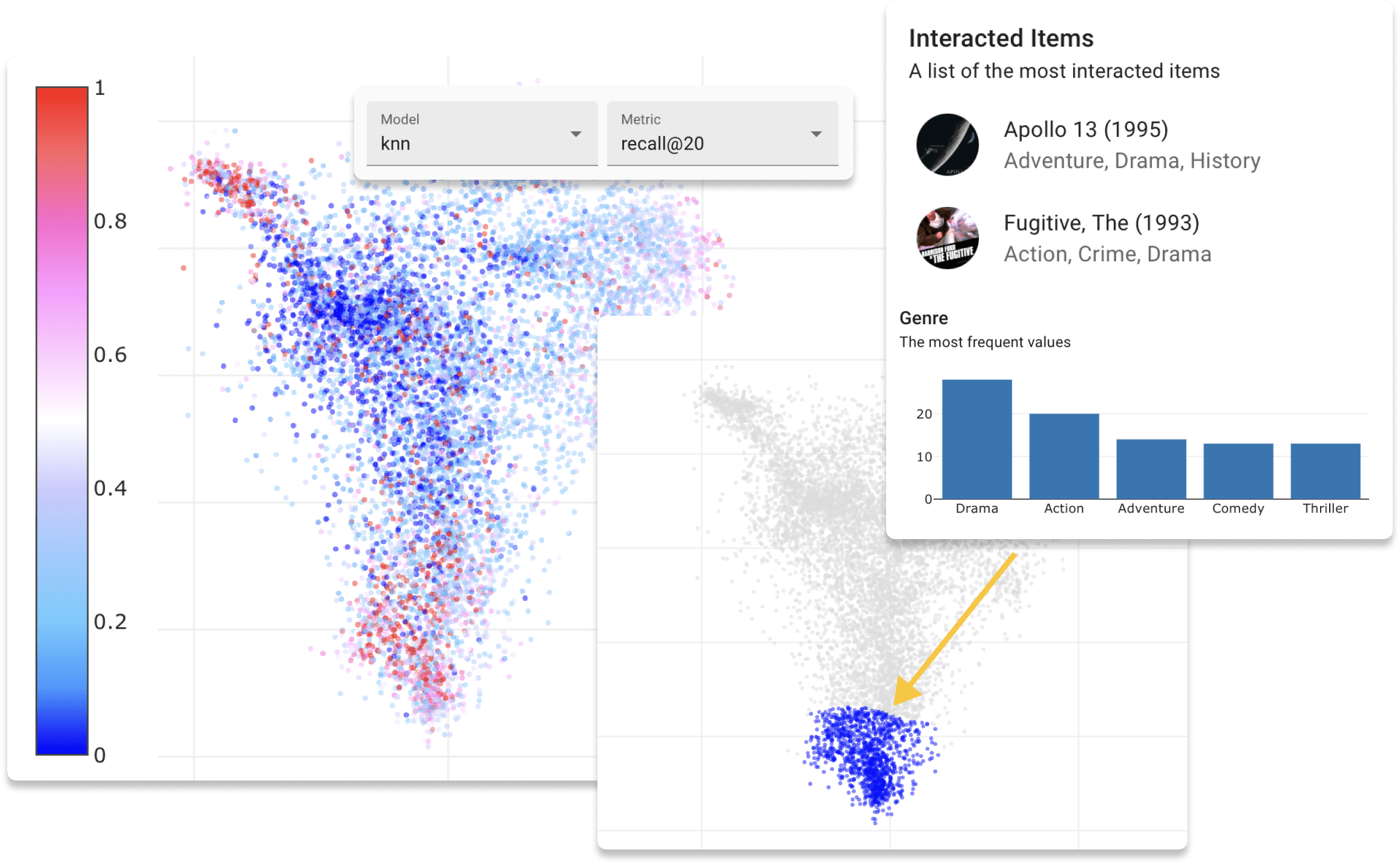

現在,您可以使用Movielens數據集在我們的演示網站上在線嘗試Repsys。另外,請查看我們使用repsys小部件組件製作的交互式博客文章。
我們的論文“ Repsys:推薦系統的交互式評估框架”被Recsys'22會議接受。
使用PIP安裝軟件包:
$ pip install repsys-framework
如果您將使用PYMDE進行數據可視化,則需要使用以下附加功能安裝repsys:
$ pip install repsys-framework[pymde]
如果您想跳過本教程並嘗試框架,則可以提取位於存儲庫的演示文件夾的內容。如下一步所述,在開始之前,您仍然必須下載數據集。
否則,請創建一個將包含數據集和模型實現的空項目文件夾。
├── __init__.py
├── dataset.py
├── models.py
├── repsys.ini
└── .gitignore
首先,我們需要導入我們的數據集。為了教程目的,我們將使用Movielens 2000萬數據集和138,000個用戶對27,000部電影進行的2000萬個評級。請下載ml-20m.zip文件,然後將數據解壓縮到當前文件夾中。然後將以下內容添加到dataset.py文件:
import pandas as pd
from repsys import Dataset
import repsys . dtypes as dtypes
class MovieLens ( Dataset ):
def name ( self ):
return "ml20m"
def item_cols ( self ):
return {
"movieId" : dtypes . ItemID (),
"title" : dtypes . Title (),
"genres" : dtypes . Tag ( sep = "|" ),
"year" : dtypes . Number ( data_type = int ),
}
def interaction_cols ( self ):
return {
"movieId" : dtypes . ItemID (),
"userId" : dtypes . UserID (),
"rating" : dtypes . Interaction (),
}
def load_items ( self ):
df = pd . read_csv ( "./ml-20m/movies.csv" )
df [ "year" ] = df [ "title" ]. str . extract ( r"((d+))" )
return df
def load_interactions ( self ):
df = pd . read_csv ( "./ml-20m/ratings.csv" )
return df該代碼將定義一個名為ML20M的新數據集,它將導入評級和項目數據。您必須始終使用預定義的數據類型指定數據結構。在返回數據之前,您還可以像從標題列中提取電影年一樣進行預處理。
現在,我們定義了第一個推薦模型,這將是基於用戶的KNN的簡單實現。
import numpy as np
import scipy . sparse as sp
from sklearn . neighbors import NearestNeighbors
from repsys import Model
class KNN ( Model ):
def __init__ ( self ):
self . model = NearestNeighbors ( n_neighbors = 20 , metric = "cosine" )
def name ( self ):
return "knn"
def fit ( self , training = False ):
X = self . dataset . get_train_data ()
self . model . fit ( X )
def predict ( self , X , ** kwargs ):
if X . count_nonzero () == 0 :
return np . random . uniform ( size = X . shape )
distances , indices = self . model . kneighbors ( X )
distances = distances [:, 1 :]
indices = indices [:, 1 :]
distances = 1 - distances
sums = distances . sum ( axis = 1 )
distances = distances / sums [:, np . newaxis ]
def f ( dist , idx ):
A = self . dataset . get_train_data ()[ idx ]
D = sp . diags ( dist )
return D . dot ( A ). sum ( axis = 0 )
vf = np . vectorize ( f , signature = "(n),(n)->(m)" )
predictions = vf ( distances , indices )
predictions [ X . nonzero ()] = 0
return predictions您必須定義使用培訓數據訓練模型的合適方法,或從文件中加載先前訓練的模型。 Web應用程序啟動或評估過程開始時,所有模型均擬合。如果這不是訓練階段,請始終將模型從檢查站加載以加快過程。出於教程的目的,省略了這一點。
您還必須定義預測方法,該方法接收到輸入上用戶交互的稀疏矩陣。對於每個用戶(矩陣的行)和項目(矩陣的列),該方法應返回預測的分數,以指示用戶將享受該項目的數量。
此外,您可以指定在推薦創建期間可以設置的一些Web應用程序參數。然後,在預測方法的**kwargs參數中可以訪問該值。在示例中,我們創建了一個具有所有唯一類型的選擇輸入,並僅濾除那些不包含所選類型的電影。
我們應該創建的最後一個文件是一種配置,該配置允許您控制數據拆分過程,服務器設置,框架行為等。
[general]
seed =1234
[dataset]
train_split_prop =0.85
test_holdout_prop =0.2
min_user_interacts =5
min_item_interacts =0
[evaluation]
precision_recall_k =20,50
ndcg_k =100
coverage_k =20
diversity_k =20
novelty_k =20
percentage_lt_k =20
coverage_lt_k =20
[visualization]
embed_method =pymde
pymde_neighbors =15
umap_neighbors =15
umap_min_dist =0.1
tsne_perplexity =30
[server]
port =3001在訓練模型之前,我們需要將數據分為火車,驗證和測試集。從當前目錄運行以下命令。
$ repsys dataset split
這將使85%的用戶作為培訓數據,其餘的15%將用作驗證/測試數據,每個用戶的用戶中有7.5%。對於驗證和測試集,還將為評估目的而進行20%的交互。拆分數據集將存儲在默認檢查點文件夾中。
現在,我們可以進入培訓過程。為此,請致電以下命令。
$ repsys model train
此命令將將每個模型的擬合方法稱為true。您始終可以使用-m名稱作為參數限制模型。
準備數據並訓練模型時,我們可以評估模型在看不見的用戶交互中的性能。運行以下命令來這樣做。
$ repsys model eval
同樣,您可以使用-m標誌限制模型。進行評估後,結果將存儲在檢查點文件夾中。
在啟動Web應用程序之前,最後一步是評估數據集的數據。此過程將創建培訓和驗證數據的用戶和項目嵌入,以允許您探索潛在空間。從項目目錄運行以下命令。
$ repsys dataset eval
您可以從三種類型的嵌入算法中進行選擇:
--method umap (這是默認選項)。--method pymde 。--method tsne 。--method custom ,並將以下方法添加到您選擇的模型類中。在這種情況下,您還必須使用-m參數指定模型的名稱。 from sklearn . decomposition import NMF
def compute_embeddings ( self , X ):
nmf = NMF ( n_components = 2 )
W = nmf . fit_transform ( X )
H = nmf . components_
return W , H . T在示例中,使用負基質分解。您必須按照此順序返回用戶和項目嵌入對。同樣,必須以(n_users/n_items,n_dim)形狀返回矩陣。如果還原尺寸高於2,則應用TSNE方法。
最後,現在是時候啟動Web應用程序來查看您的模型的評估和預覽實時建議的結果了。
$ repsys server
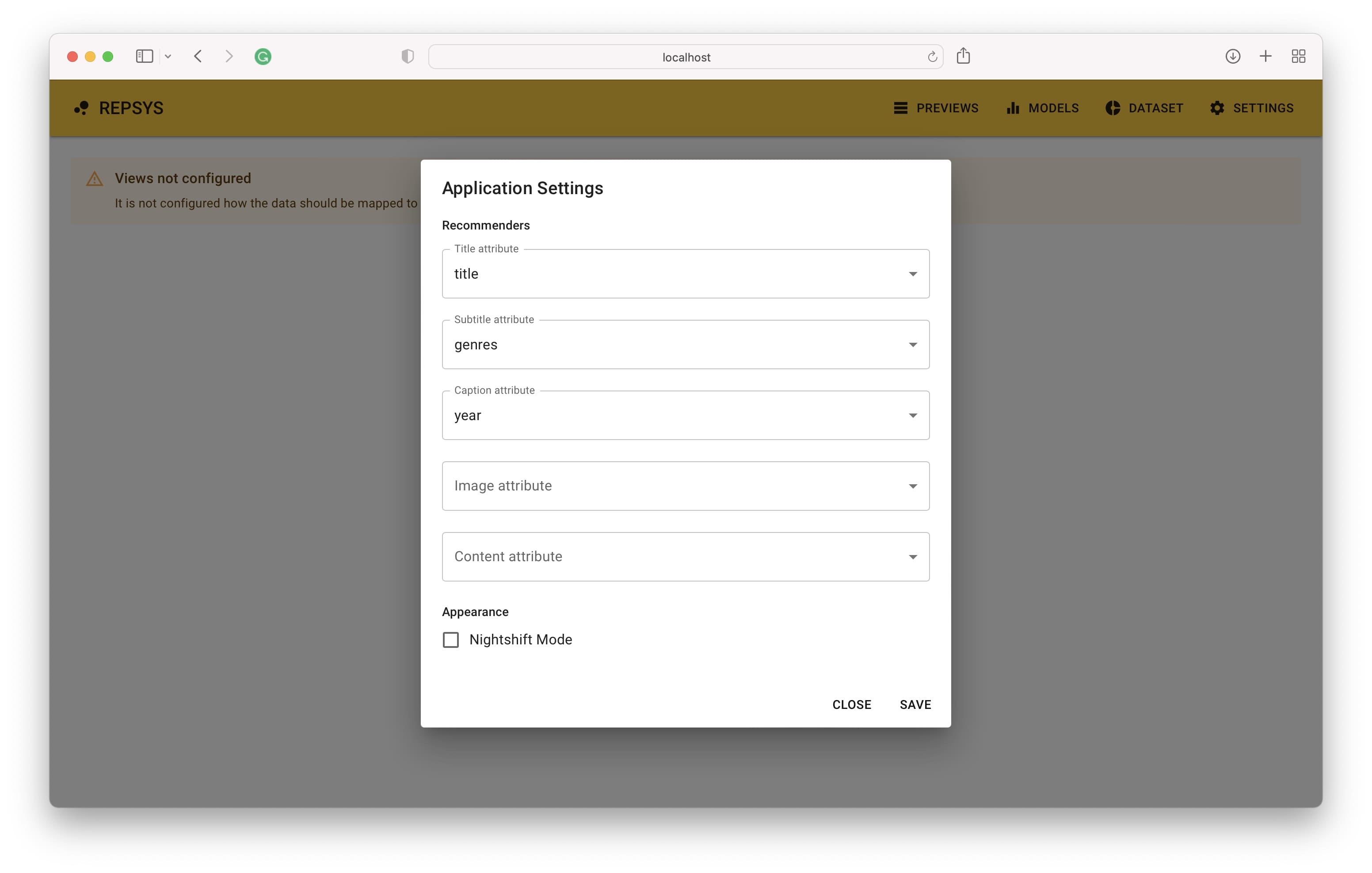
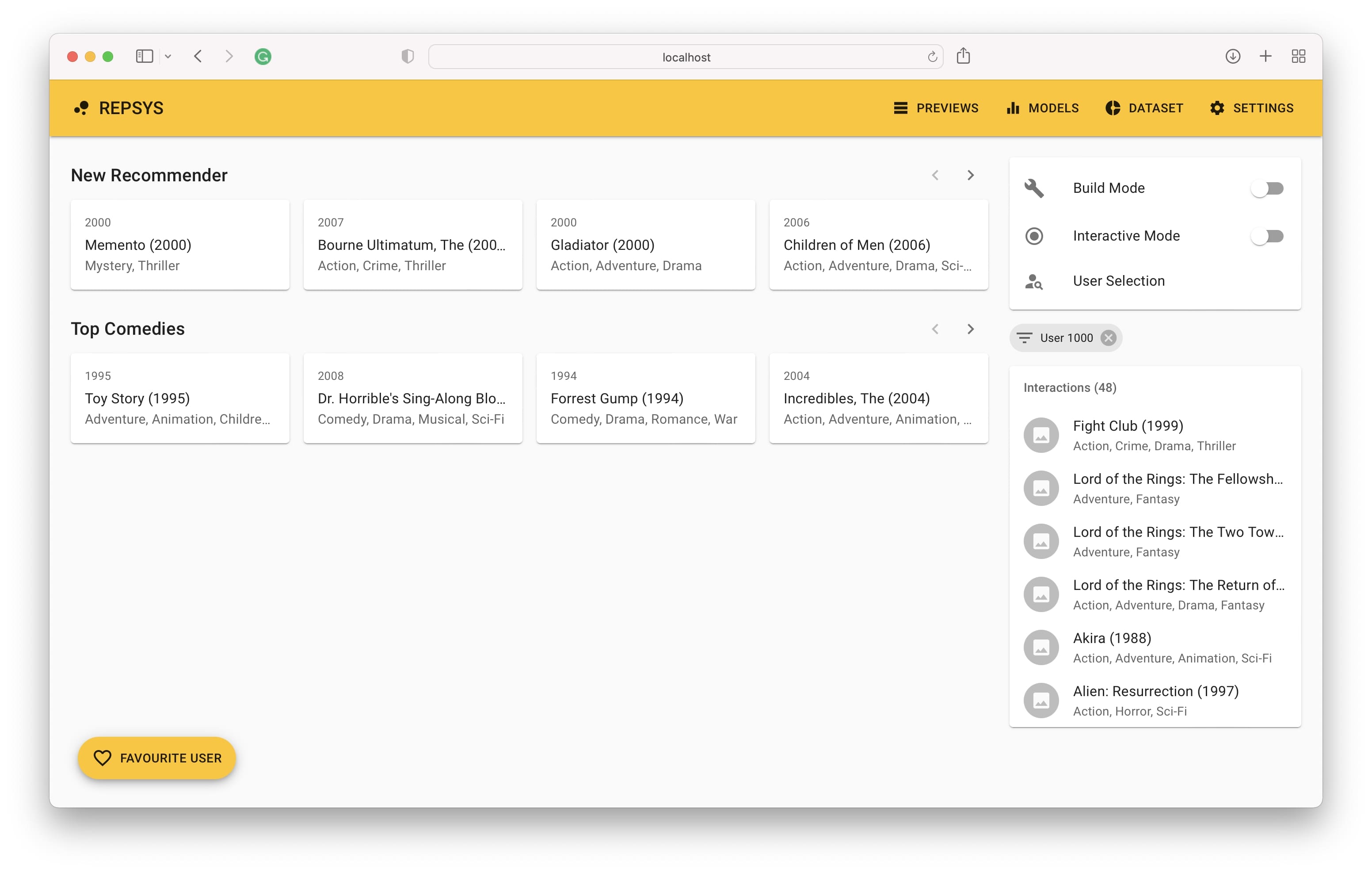
該應用程序應在默認地址http:// localhost:3001上訪問。打開鏈接時,您將看到主屏幕,一旦完成設置,建議就會出現。第一步是定義如何將項目的數據列映射到項目視圖組件。
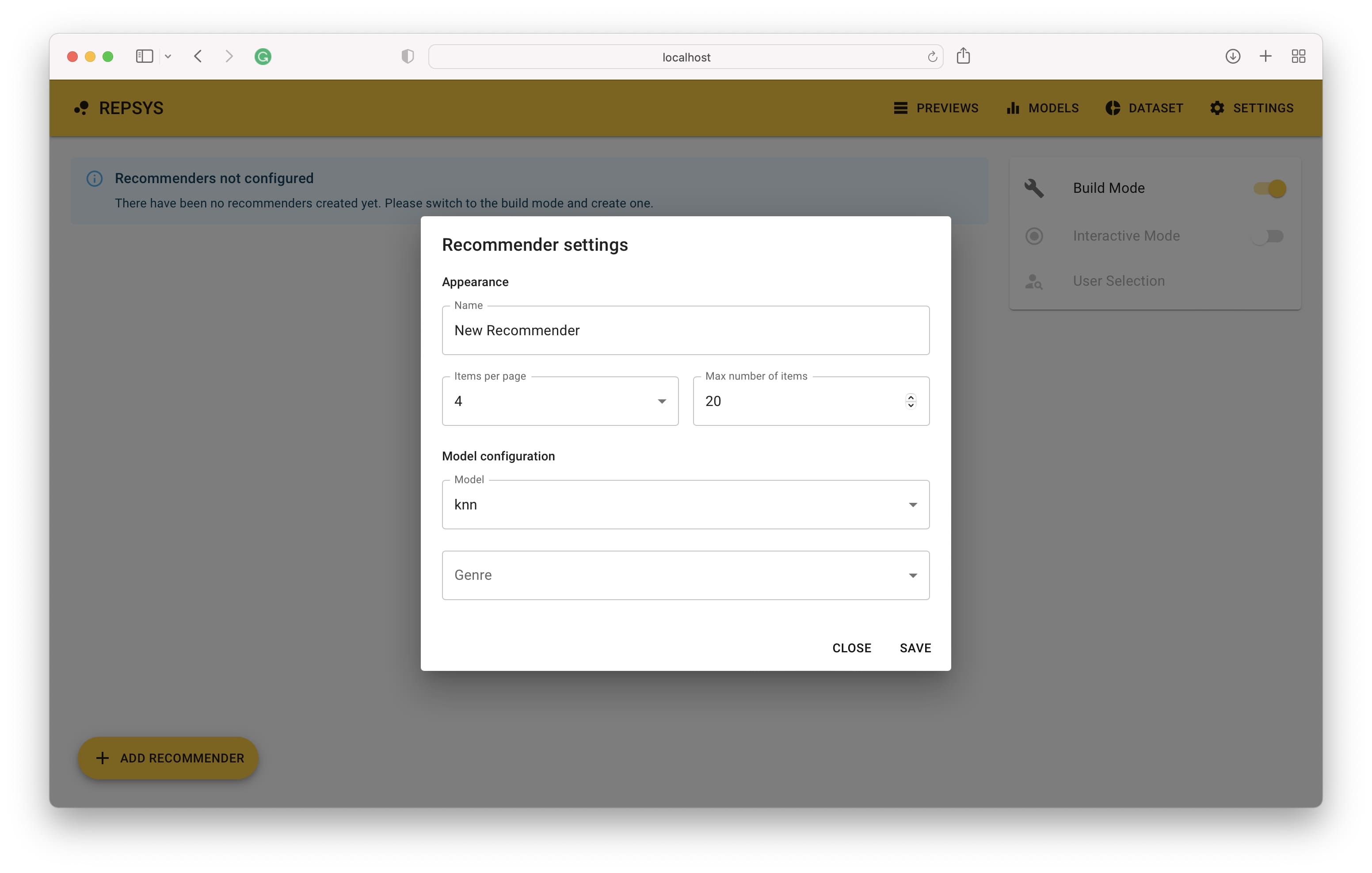
然後,我們需要切換到構建模式,並添加兩個推薦器 - 一個沒有過濾器,第二部只包含喜劇電影。
現在,我們從構建模式切換回,然後從驗證集中選擇用戶(以前從未見過)。
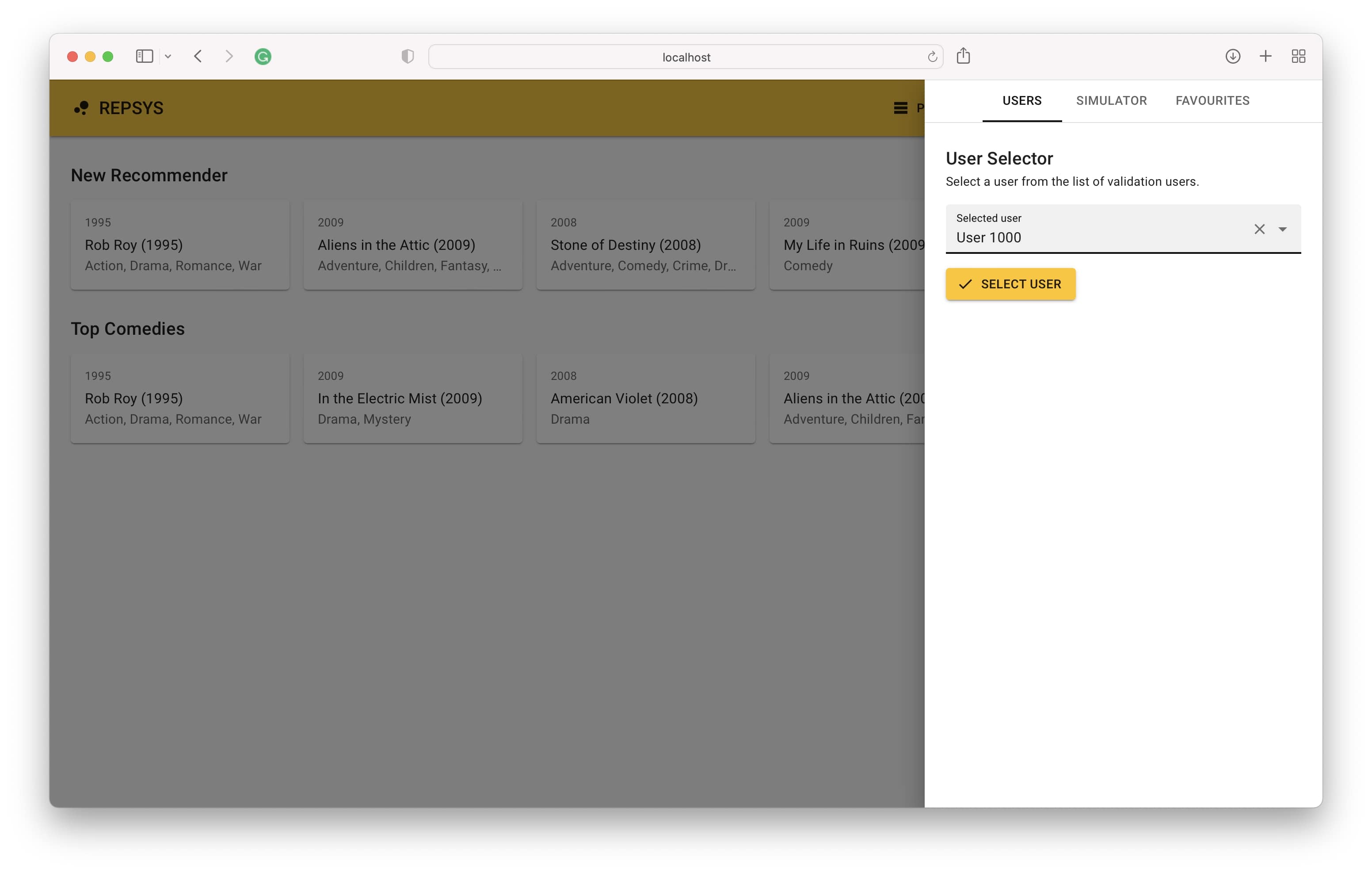
最後,我們在右側看到用戶的交互歷史記錄以及左側模型的建議。
要從源構建軟件包,您首先需要按照此處記錄的內容安裝node.js和npm庫。然後,您可以從根目錄運行以下腳本以構建Web應用程序並在本地安裝軟件包。
$ ./scripts/install-locally.sh
如果您在研究工作中採用代表,請不要忘記引用相關論文:
@inproceedings{10.1145/3523227.3551469,
author = {v{S}afav{r}'{i}k, Jan and Vanv{c}ura, Vojtv{e}ch and Kord'{i}k, Pavel},
title = {RepSys: Framework for Interactive Evaluation of Recommender Systems},
year = {2022},
isbn = {9781450392785},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3523227.3551469},
doi = {10.1145/3523227.3551469},
booktitle = {Proceedings of the 16th ACM Conference on Recommender Systems},
pages = {636–639},
numpages = {4},
keywords = {User simulation, Distribution analysis, Recommender systems},
location = {Seattle, WA, USA},
series = {RecSys '22}
}
該框架的開發是由Recombee Company贊助的。



