repsys
1.0.0
Repsys - это основа для разработки и анализа систем рекомендаций, и он позволяет вам:
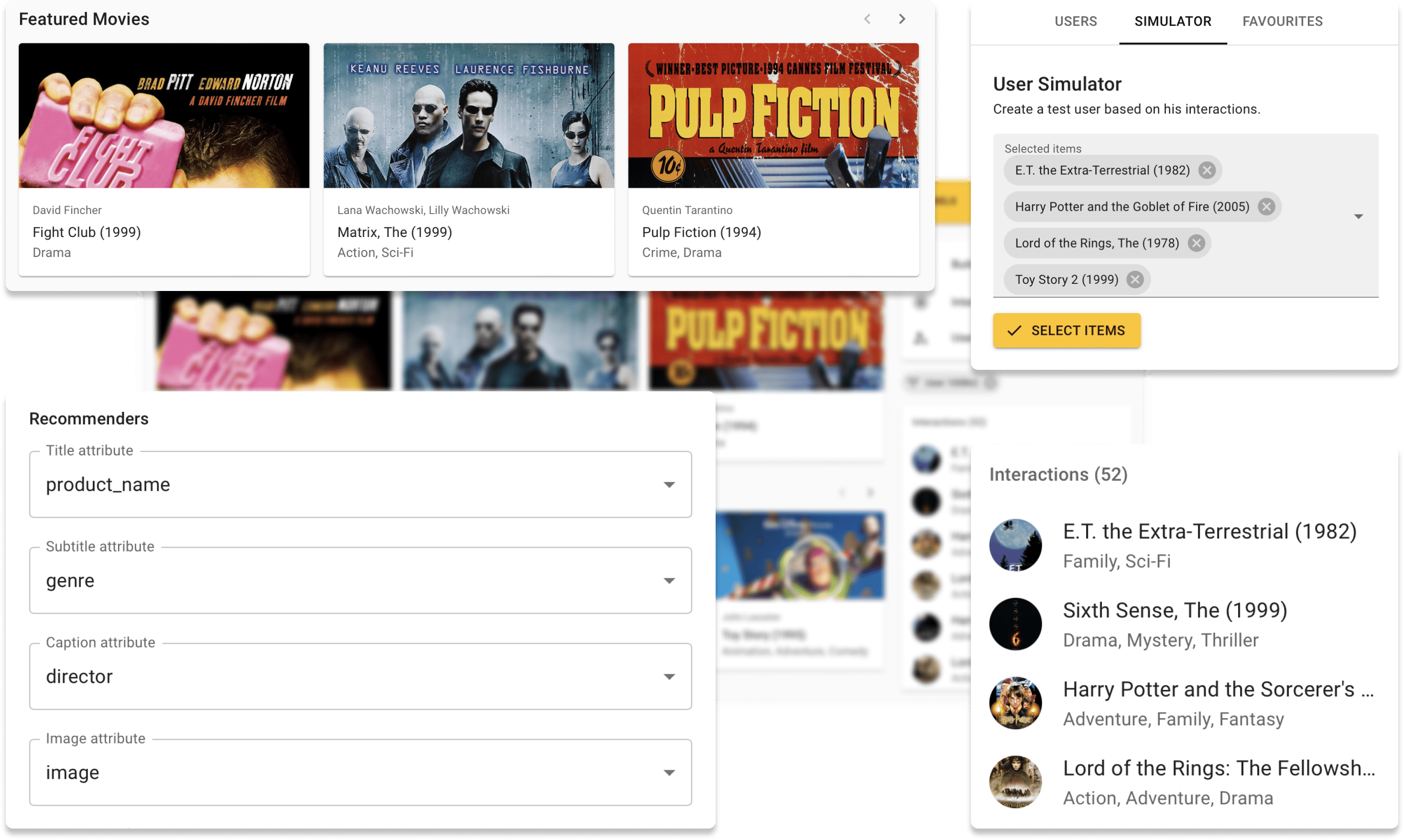

Теперь вы можете попробовать Repsys Online на нашем демонстрационном сайте с набором данных Movielens. Кроме того, ознакомьтесь с интерактивным сообщением в блоге, которое мы сделали, используя компонент Vidgets Repsys.
Наша статья «Repsys: структура для интерактивной оценки рекомендательных систем» была принята на конференцию Recsys'22.
Установите пакет с помощью PIP:
$ pip install repsys-framework
Если вы будете использовать Pymde для визуализации данных, вам необходимо установить Repsys со следующими дополнениями:
$ pip install repsys-framework[pymde]
Если вы хотите пропустить этот урок и попробовать фреймворк, вы можете потянуть содержание демонстрационной папки, расположенной в репозитории. Как упоминалось на следующем шаге, вам все равно нужно загрузить набор данных, прежде чем начать.
В противном случае, пожалуйста, создайте пустую папку проекта, которая будет содержать реализацию набора данных и моделей.
├── __init__.py
├── dataset.py
├── models.py
├── repsys.ini
└── .gitignore
Во -первых, нам нужно импортировать наш набор данных. Мы будем использовать набор данных Movielens 20 млн. С 20 миллионами рейтингов, полученных 138 000 пользователей до 27 000 фильмов для учебного пособия. Пожалуйста, загрузите файл ml-20m.zip и разкаплите данные в текущую папку. Затем добавьте следующий контент в файл dataset.py :
import pandas as pd
from repsys import Dataset
import repsys . dtypes as dtypes
class MovieLens ( Dataset ):
def name ( self ):
return "ml20m"
def item_cols ( self ):
return {
"movieId" : dtypes . ItemID (),
"title" : dtypes . Title (),
"genres" : dtypes . Tag ( sep = "|" ),
"year" : dtypes . Number ( data_type = int ),
}
def interaction_cols ( self ):
return {
"movieId" : dtypes . ItemID (),
"userId" : dtypes . UserID (),
"rating" : dtypes . Interaction (),
}
def load_items ( self ):
df = pd . read_csv ( "./ml-20m/movies.csv" )
df [ "year" ] = df [ "title" ]. str . extract ( r"((d+))" )
return df
def load_interactions ( self ):
df = pd . read_csv ( "./ml-20m/ratings.csv" )
return dfЭтот код будет определять новый набор данных под названием ML20M, и он будет импортировать как оценки, так и данные элементов. Вы всегда должны указывать свою структуру данных, используя предопределенные типы данных. Прежде чем вернуть данные, вы также можете предварительно обработать их, например, извлечь год фильма из заголовка.
Теперь мы определяем первую модель рекомендаций, которая будет простой реализацией пользовательского KNN.
import numpy as np
import scipy . sparse as sp
from sklearn . neighbors import NearestNeighbors
from repsys import Model
class KNN ( Model ):
def __init__ ( self ):
self . model = NearestNeighbors ( n_neighbors = 20 , metric = "cosine" )
def name ( self ):
return "knn"
def fit ( self , training = False ):
X = self . dataset . get_train_data ()
self . model . fit ( X )
def predict ( self , X , ** kwargs ):
if X . count_nonzero () == 0 :
return np . random . uniform ( size = X . shape )
distances , indices = self . model . kneighbors ( X )
distances = distances [:, 1 :]
indices = indices [:, 1 :]
distances = 1 - distances
sums = distances . sum ( axis = 1 )
distances = distances / sums [:, np . newaxis ]
def f ( dist , idx ):
A = self . dataset . get_train_data ()[ idx ]
D = sp . diags ( dist )
return D . dot ( A ). sum ( axis = 0 )
vf = np . vectorize ( f , signature = "(n),(n)->(m)" )
predictions = vf ( distances , indices )
predictions [ X . nonzero ()] = 0
return predictionsВы должны определить метод соответствия для обучения своей модели, используя учебные данные или загрузить ранее обученную модель из файла. Все модели устанавливаются, когда начинается веб -приложение, или начинается процесс оценки. Если это не фаза обучения, всегда загружайте свою модель с контрольной точки, чтобы ускорить процесс. Для учебных целей это опущено.
Вы также должны определить метод прогнозирования, который получает разреженную матрицу взаимодействий пользователей на входе. Для каждого пользователя (строка матрицы) и элемента (столбец матрицы) метод должен вернуть прогнозируемый балл, указывающий, насколько пользователь будет наслаждаться элементом.
Кроме того, вы можете указать некоторые параметры веб -приложения, которые вы можете установить во время создания рекомендаций. Затем значение доступно в аргументе **kwargs о методе прогнозирования». В примере мы создаем ввод Select со всеми уникальными жанрами и отфильтровали только те фильмы, которые не содержат выбранного жанра.
Последний файл, который мы должны создать, - это конфигурация, которая позволяет управлять процессом разделения данных, настройки сервера, фреймворчатого поведения и т. Д.
[general]
seed =1234
[dataset]
train_split_prop =0.85
test_holdout_prop =0.2
min_user_interacts =5
min_item_interacts =0
[evaluation]
precision_recall_k =20,50
ndcg_k =100
coverage_k =20
diversity_k =20
novelty_k =20
percentage_lt_k =20
coverage_lt_k =20
[visualization]
embed_method =pymde
pymde_neighbors =15
umap_neighbors =15
umap_min_dist =0.1
tsne_perplexity =30
[server]
port =3001Прежде чем тренировать наши модели, нам нужно разделить данные на поезда, валидацию и тестовые наборы. Запустите следующую команду из текущего каталога.
$ repsys dataset split
Это будет удерживать 85% пользователей в качестве учебных данных, а остальные 15% будут использоваться в качестве проверки/тестовых данных с 7,5% пользователей в каждом. Как для проверки, так и для набора тестов 20% взаимодействий также будут проводиться в целях оценки. Распределенный набор данных будет храниться в папке контрольных точек по умолчанию.
Теперь мы можем перейти к тренировочному процессу. Для этого, пожалуйста, позвоните следующей команде.
$ repsys model train
Эта команда будет называть метод FIT каждой модели с помощью обучающего флага, установленного TRUE. Вы всегда можете ограничить модели, используя флаг -m с помощью имени модели в качестве параметра.
Когда данные будут подготовлены и обучены модели, мы можем оценить производительность моделей на невидимых взаимодействиях пользователей. Запустите следующую команду, чтобы сделать это.
$ repsys model eval
Опять же, вы можете ограничить модели, используя флаг -m . Результаты будут храниться в папке контрольных точек, когда будет выполнена оценка.
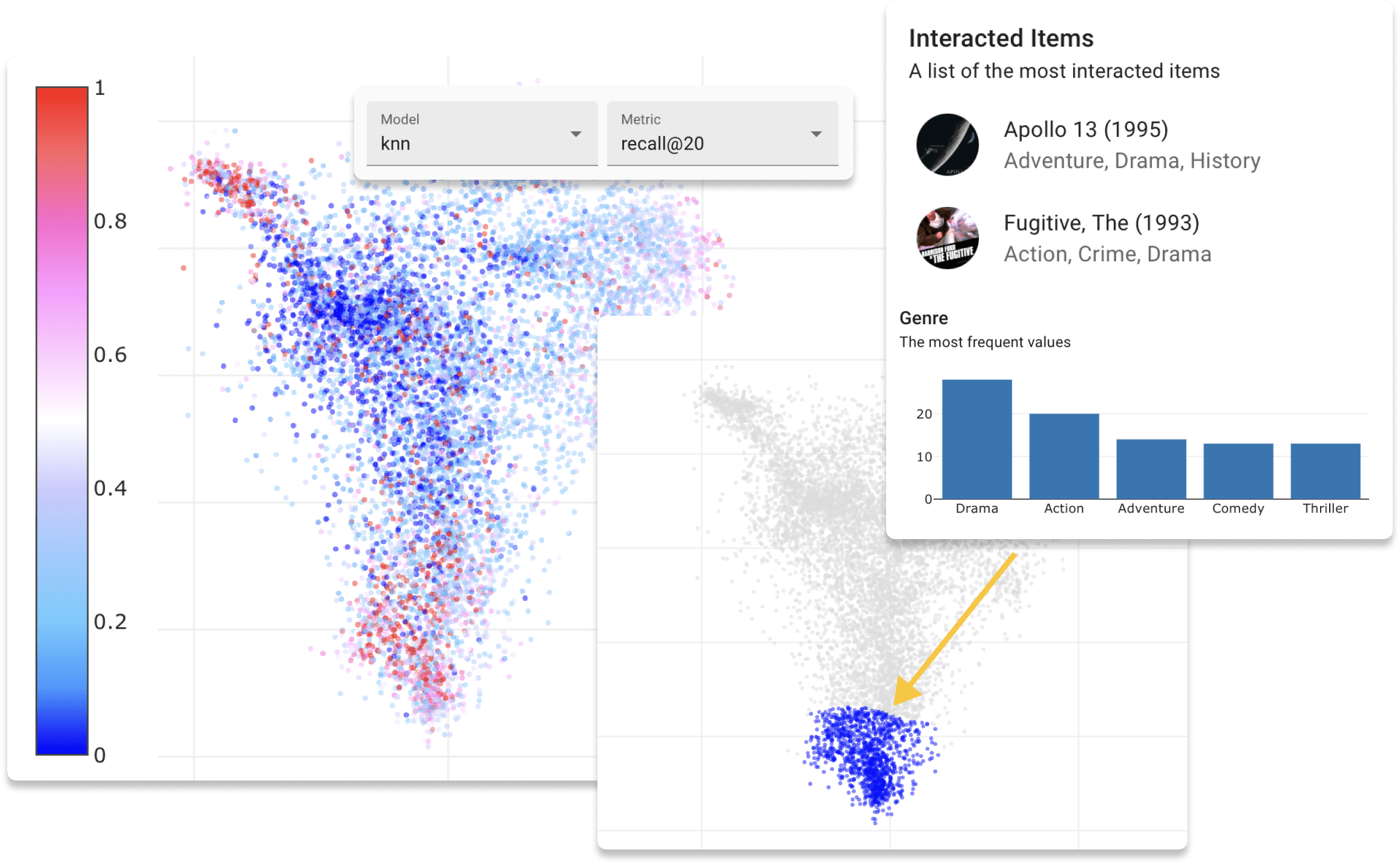
Перед началом веб -приложения окончательным шагом является оценка данных набора данных. Эта процедура создаст пользователей и элементы, внедряющие данные обучения и проверки, чтобы позволить вам исследовать скрытое пространство. Запустите следующую команду из каталога проекта.
$ repsys dataset eval
Вы можете выбрать из трех типов алгоритма встраивания:
--method umap (это опция по умолчанию).--method pymde .--method tsne .--method custom и добавьте следующий метод в класс модели по вашему выбору. В этом случае вы также должны указать имя модели, используя параметр -m . from sklearn . decomposition import NMF
def compute_embeddings ( self , X ):
nmf = NMF ( n_components = 2 )
W = nmf . fit_transform ( X )
H = nmf . components_
return W , H . TВ примере используется отрицательная матричная факторизация. В этом порядке вы должны вернуть пару пользовательских и элементов. Кроме того, важно вернуть матрицы в форме (n_users/n_items, n_dim). Если уменьшенный размер выше 2, применяется метод TSNE.
Наконец, пришло время начать веб -приложение, чтобы увидеть результаты оценки и предварительно просмотреть живые рекомендации ваших моделей.
$ repsys server
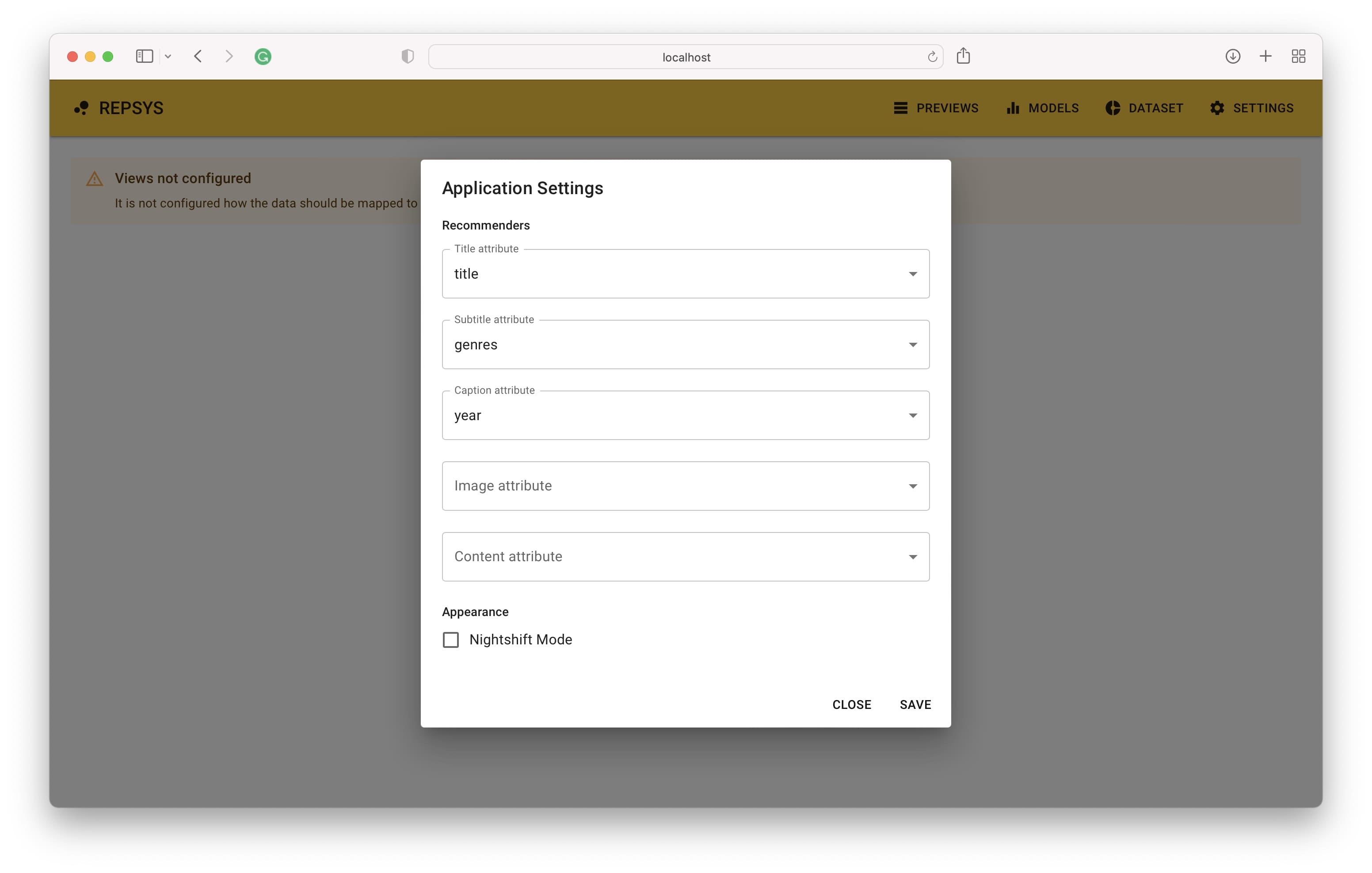
Приложение должно быть доступно по адресу по умолчанию http: // localhost: 3001. Когда вы откроете ссылку, вы увидите основной экран, где ваши рекомендации появятся после завершения настройки. Первым шагом является определение того, как столбцы данных элементов должны быть сопоставлены с компонентами представления элемента.
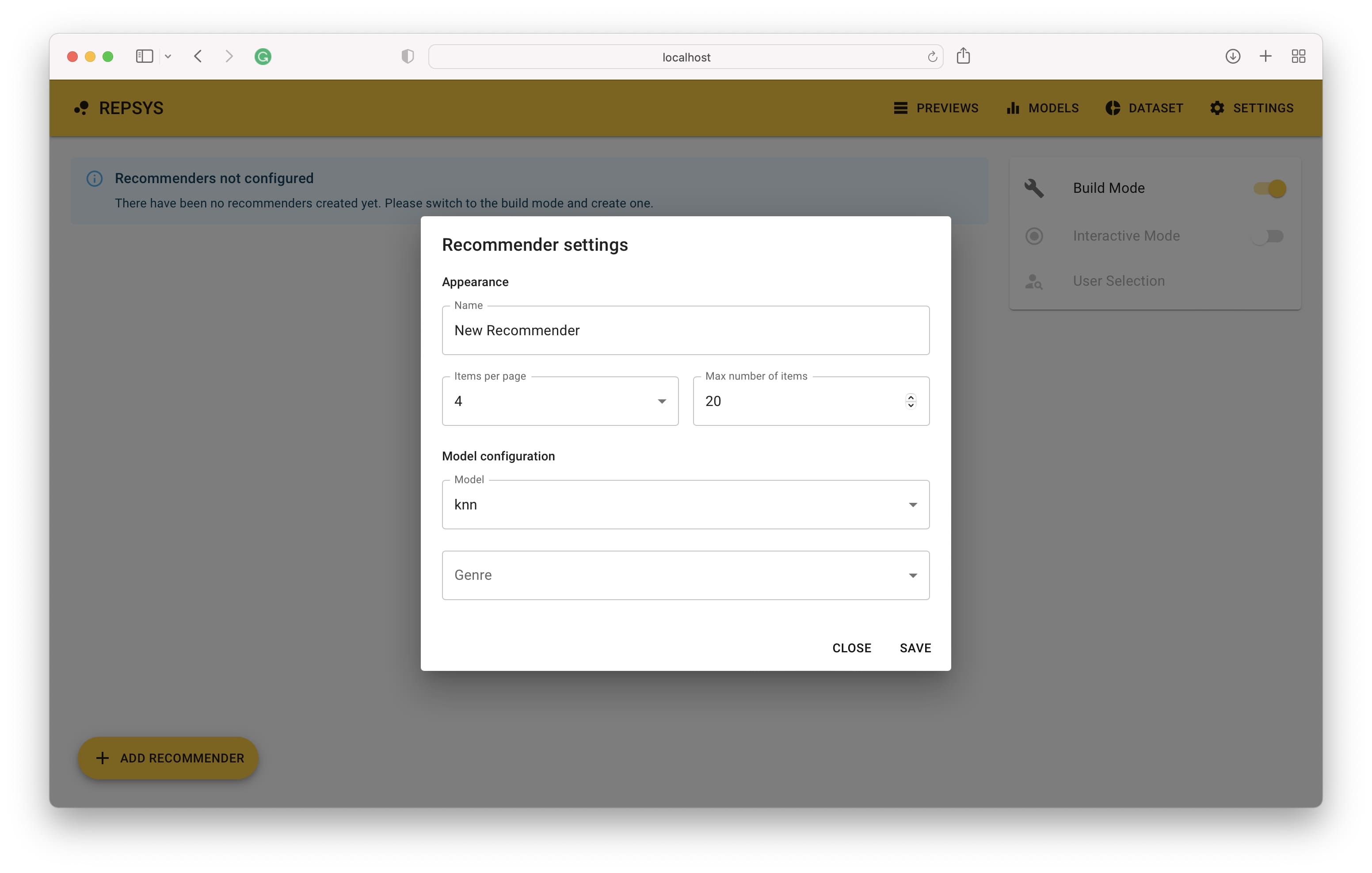
Затем нам нужно переключиться на режим сборки и добавить два рекомендатора - один без фильтра, а второй с включенными только комедийными фильмами.
Теперь мы переходим обратно из режима сборки и выбираем пользователя из набора валидации (никогда раньше не видели модель).
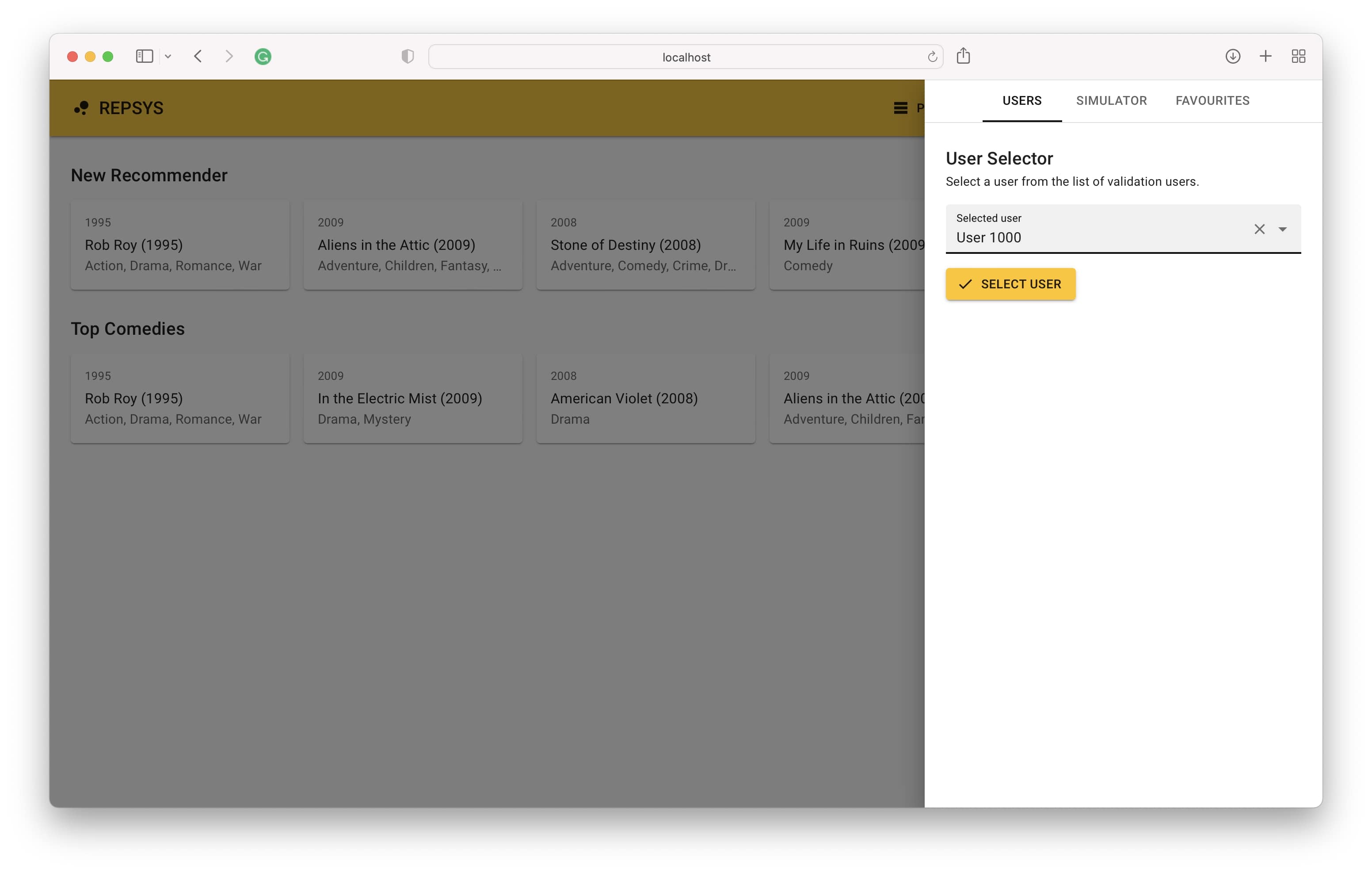
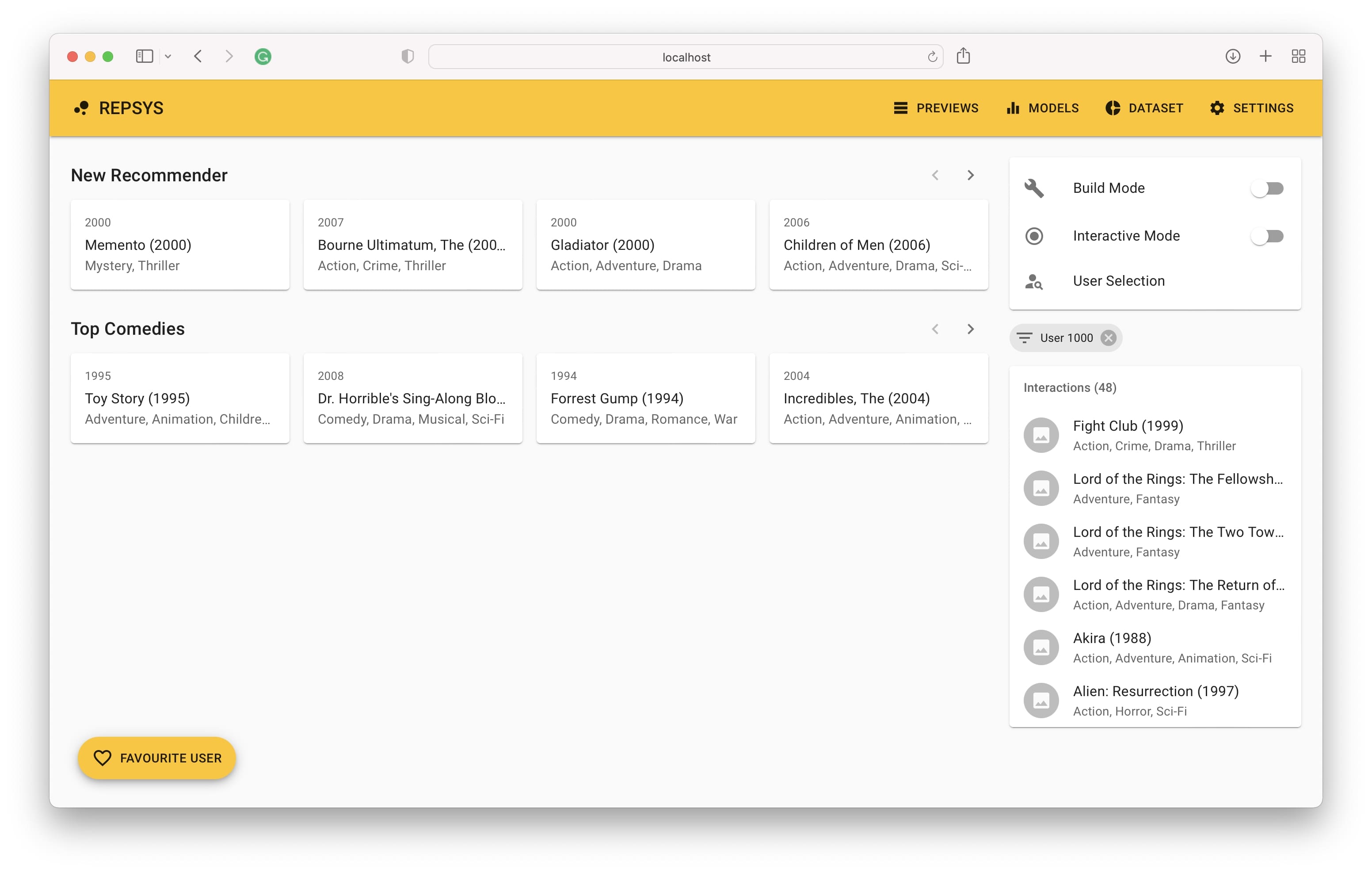
Наконец, мы видим историю взаимодействия пользователя на правой стороне и рекомендации, сделанные моделью с левой стороны.
Чтобы построить пакет из источника, вам сначала нужно установить Node.js и библиотеку NPM, как задокументировано здесь. Затем вы можете запустить следующий сценарий из корневого каталога, чтобы создать веб -приложение и установить пакет локально.
$ ./scripts/install-locally.sh
Если вы нанимаете Repsys в своей исследовательской работе, пожалуйста, не забудьте цитировать связанную статью:
@inproceedings{10.1145/3523227.3551469,
author = {v{S}afav{r}'{i}k, Jan and Vanv{c}ura, Vojtv{e}ch and Kord'{i}k, Pavel},
title = {RepSys: Framework for Interactive Evaluation of Recommender Systems},
year = {2022},
isbn = {9781450392785},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3523227.3551469},
doi = {10.1145/3523227.3551469},
booktitle = {Proceedings of the 16th ACM Conference on Recommender Systems},
pages = {636–639},
numpages = {4},
keywords = {User simulation, Distribution analysis, Recommender systems},
location = {Seattle, WA, USA},
series = {RecSys '22}
}
Разработка этой структуры спонсируется рекомбиничной компанией.



