repsys
1.0.0
Le Repsys est un cadre pour développer et analyser les systèmes de recommandation, et il vous permet de:
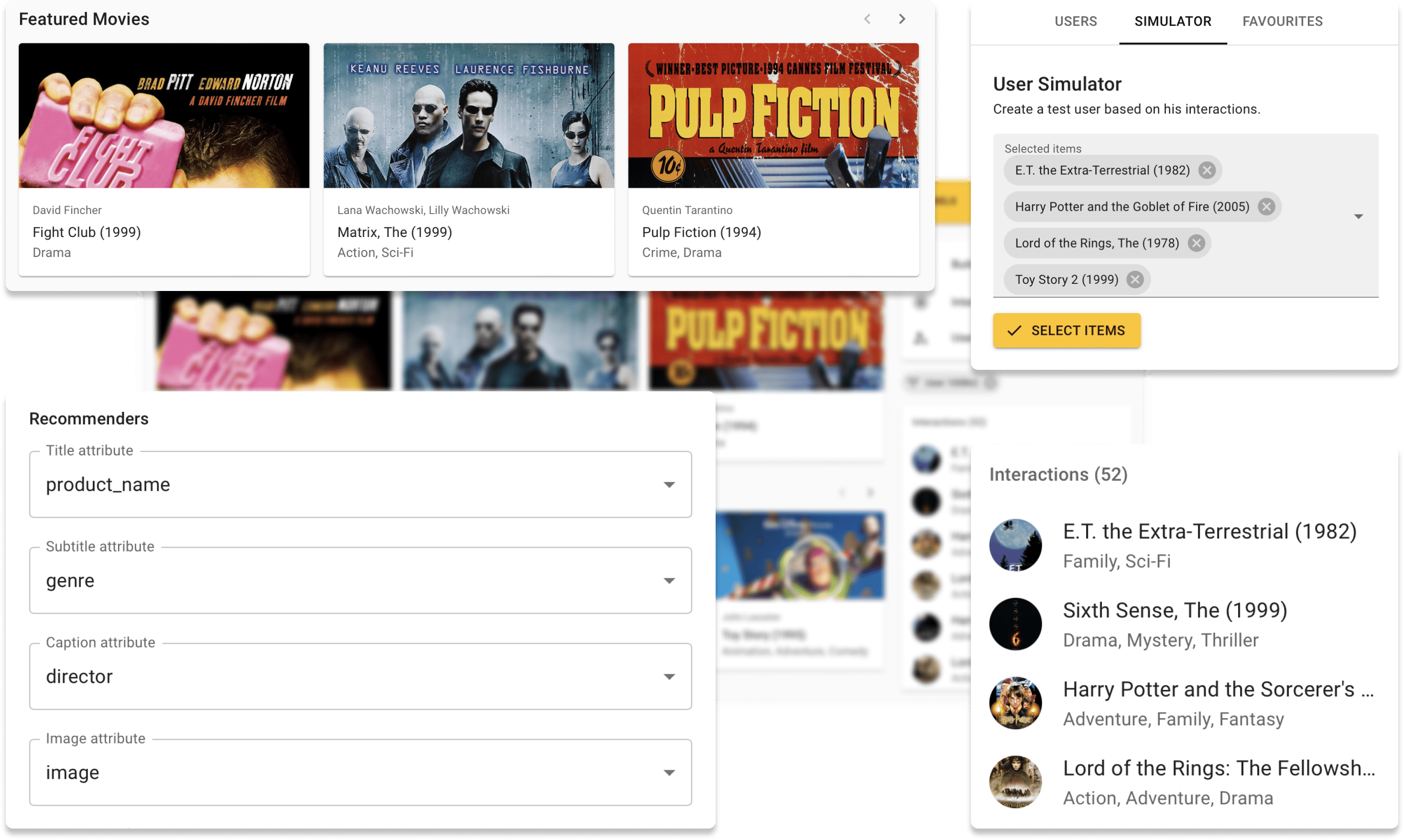
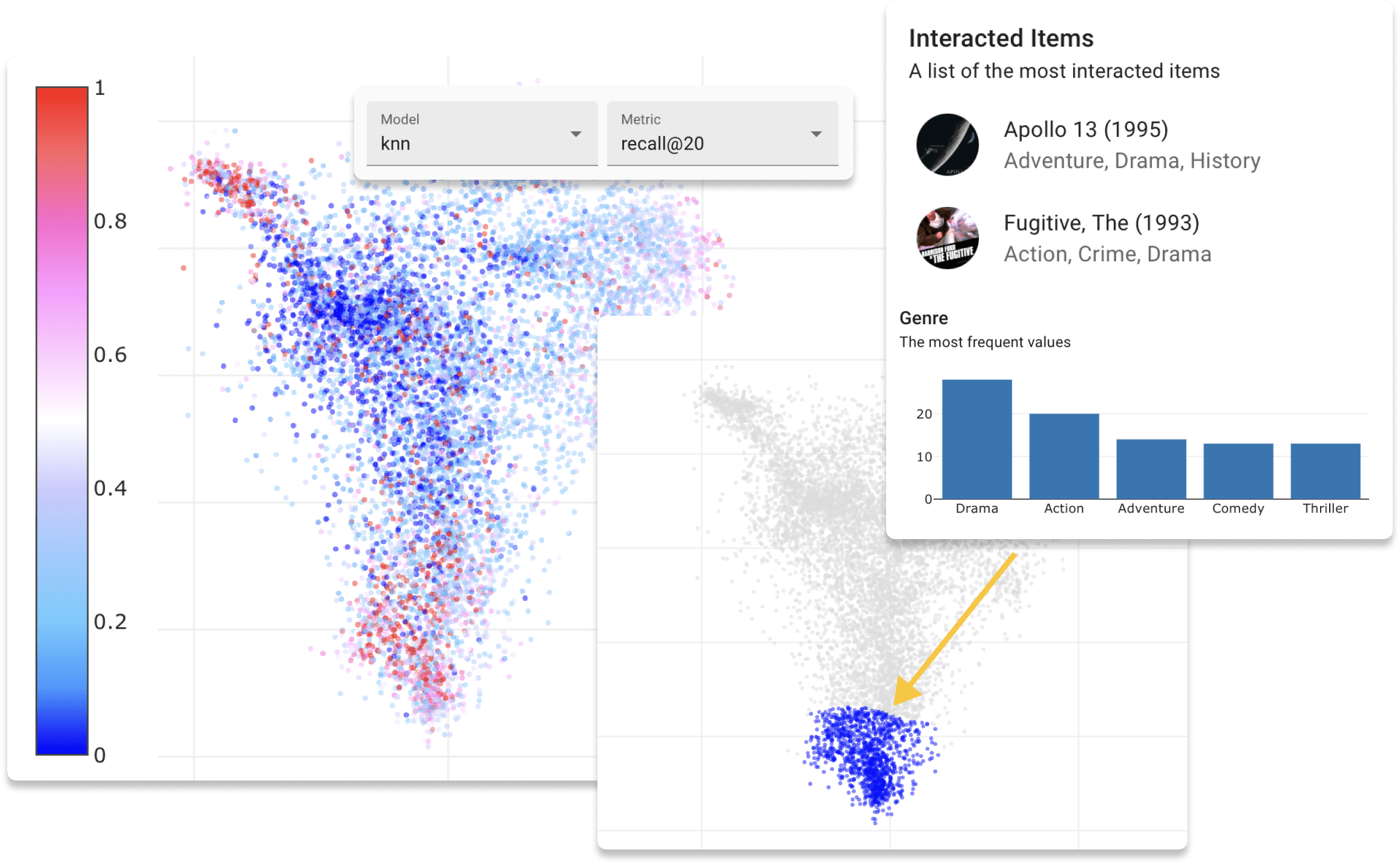

Vous pouvez maintenant essayer Repsys en ligne sur notre site de démonstration avec l'ensemble de données Moviens. Consultez également un article de blog interactif que nous avons réalisé en utilisant le composant Repsys Widgets.
Notre article "Repsys: Cadre pour l'évaluation interactive des systèmes de recommandation" a été accepté pour la conférence Recsys'22.
Installez le package à l'aide de PIP:
$ pip install repsys-framework
Si vous utilisez PYMDE pour la visualisation des données, vous devez installer Repsys avec les extras suivants:
$ pip install repsys-framework[pymde]
Si vous souhaitez ignorer ce tutoriel et essayer le cadre, vous pouvez retirer le contenu du dossier de démonstration situé au référentiel. Comme mentionné à l'étape suivante, vous devez toujours télécharger l'ensemble de données avant de commencer.
Sinon, veuillez créer un dossier de projet vide qui contiendra la mise en œuvre de l'ensemble de données et des modèles.
├── __init__.py
├── dataset.py
├── models.py
├── repsys.ini
└── .gitignore
Tout d'abord, nous devons importer notre ensemble de données. Nous utiliserons l'ensemble de données Moviens 20m avec 20 millions de notes faites par 138 000 utilisateurs à 27 000 films à des fins de tutoriel. Veuillez télécharger le fichier ml-20m.zip et décompresser les données dans le dossier actuel. Ajoutez ensuite le contenu suivant dans le fichier dataset.py :
import pandas as pd
from repsys import Dataset
import repsys . dtypes as dtypes
class MovieLens ( Dataset ):
def name ( self ):
return "ml20m"
def item_cols ( self ):
return {
"movieId" : dtypes . ItemID (),
"title" : dtypes . Title (),
"genres" : dtypes . Tag ( sep = "|" ),
"year" : dtypes . Number ( data_type = int ),
}
def interaction_cols ( self ):
return {
"movieId" : dtypes . ItemID (),
"userId" : dtypes . UserID (),
"rating" : dtypes . Interaction (),
}
def load_items ( self ):
df = pd . read_csv ( "./ml-20m/movies.csv" )
df [ "year" ] = df [ "title" ]. str . extract ( r"((d+))" )
return df
def load_interactions ( self ):
df = pd . read_csv ( "./ml-20m/ratings.csv" )
return dfCe code définira un nouvel ensemble de données appelé ML20M, et il importera à la fois les données des notes et des éléments. Vous devez toujours spécifier votre structure de données à l'aide de types de données prédéfinis. Avant de retourner les données, vous pouvez également le prétraiter comme extraire l'année du film de la colonne de titre.
Nous définissons maintenant le premier modèle de recommandation, qui sera une simple implémentation du KNN basé sur l'utilisateur.
import numpy as np
import scipy . sparse as sp
from sklearn . neighbors import NearestNeighbors
from repsys import Model
class KNN ( Model ):
def __init__ ( self ):
self . model = NearestNeighbors ( n_neighbors = 20 , metric = "cosine" )
def name ( self ):
return "knn"
def fit ( self , training = False ):
X = self . dataset . get_train_data ()
self . model . fit ( X )
def predict ( self , X , ** kwargs ):
if X . count_nonzero () == 0 :
return np . random . uniform ( size = X . shape )
distances , indices = self . model . kneighbors ( X )
distances = distances [:, 1 :]
indices = indices [:, 1 :]
distances = 1 - distances
sums = distances . sum ( axis = 1 )
distances = distances / sums [:, np . newaxis ]
def f ( dist , idx ):
A = self . dataset . get_train_data ()[ idx ]
D = sp . diags ( dist )
return D . dot ( A ). sum ( axis = 0 )
vf = np . vectorize ( f , signature = "(n),(n)->(m)" )
predictions = vf ( distances , indices )
predictions [ X . nonzero ()] = 0
return predictionsVous devez définir la méthode d'ajustement pour former votre modèle à l'aide des données d'entraînement ou charger le modèle précédemment formé à partir d'un fichier. Tous les modèles sont ajustés au démarrage de l'application Web ou que le processus d'évaluation commence. S'il ne s'agit pas d'une phase de formation, chargez toujours votre modèle à partir d'un point de contrôle pour accélérer le processus. À des fins de tutoriel, cela est omis.
Vous devez également définir la méthode de prédiction qui reçoit une matrice clairsemée des interactions des utilisateurs sur l'entrée. Pour chaque utilisateur (ligne de la matrice) et élément (colonne de la matrice), la méthode doit renvoyer un score prévu indiquant combien l'utilisateur profitera de l'élément.
De plus, vous pouvez spécifier certains paramètres d'application Web que vous pouvez définir pendant la création de recommandation. La valeur est ensuite accessible dans l'argument **kwargs de la méthode de prédiction. Dans l'exemple, nous créons une entrée sélectionnée avec tous les genres uniques et filtrons uniquement les films qui ne contiennent pas le genre sélectionné.
Le dernier fichier que nous devons créer est une configuration qui vous permet de contrôler un processus de division de données, des paramètres du serveur, un comportement de framework, etc.
[general]
seed =1234
[dataset]
train_split_prop =0.85
test_holdout_prop =0.2
min_user_interacts =5
min_item_interacts =0
[evaluation]
precision_recall_k =20,50
ndcg_k =100
coverage_k =20
diversity_k =20
novelty_k =20
percentage_lt_k =20
coverage_lt_k =20
[visualization]
embed_method =pymde
pymde_neighbors =15
umap_neighbors =15
umap_min_dist =0.1
tsne_perplexity =30
[server]
port =3001Avant de former nos modèles, nous devons diviser les données en train, validation et ensembles de test. Exécutez la commande suivante à partir du répertoire actuel.
$ repsys dataset split
Cela tiendra 85% des utilisateurs en tant que données de formation, et les 15% seront utilisés comme données de validation / test avec 7,5% des utilisateurs chacun. Pour la validation et l'ensemble de tests, 20% des interactions seront également tenues à des fins d'évaluation. L'ensemble de données Split sera stocké dans le dossier par défaut des points de contrôle.
Nous pouvons maintenant passer au processus de formation. Pour ce faire, veuillez appeler la commande suivante.
$ repsys model train
Cette commande appellera la méthode d'ajustement de chaque modèle avec l'indicateur de formation défini sur true. Vous pouvez toujours limiter les modèles en utilisant le drapeau -m avec le nom du modèle en tant que paramètre.
Lorsque les données sont préparées et les modèles formés, nous pouvons évaluer les performances des modèles sur les interactions des utilisateurs invisibles. Exécutez la commande suivante pour le faire.
$ repsys model eval
Encore une fois, vous pouvez limiter les modèles à l'aide de l'indicateur -m . Les résultats seront stockés dans le dossier des points de contrôle lorsque l'évaluation sera effectuée.
Avant de démarrer l'application Web, la dernière étape consiste à évaluer les données de l'ensemble de données. Cette procédure créera des utilisateurs et des éléments intégrés des données de formation et de validation pour vous permettre d'explorer l'espace latent. Exécutez la commande suivante à partir du répertoire du projet.
$ repsys dataset eval
Vous pouvez choisir parmi trois types d'algorithmes d'incorporation:
--method umap (c'est l'option par défaut).--method pymde .--method tsne .--method custom et ajoutez la méthode suivante à la classe du modèle de votre choix. Dans ce cas, vous devez également spécifier le nom du modèle à l'aide du paramètre -m . from sklearn . decomposition import NMF
def compute_embeddings ( self , X ):
nmf = NMF ( n_components = 2 )
W = nmf . fit_transform ( X )
H = nmf . components_
return W , H . TDans l'exemple, la factorisation de la matrice négative est utilisée. Vous devez renvoyer une paire intégrée d'utilisateur et d'élément dans cet ordre. En outre, il est essentiel de retourner les matrices sous la forme de (n_users / n_items, n_dim). Si la dimension réduite est supérieure à 2, la méthode TSNE est appliquée.
Enfin, il est temps de démarrer l'application Web pour voir les résultats des évaluations et prévisualiser les recommandations en direct de vos modèles.
$ repsys server
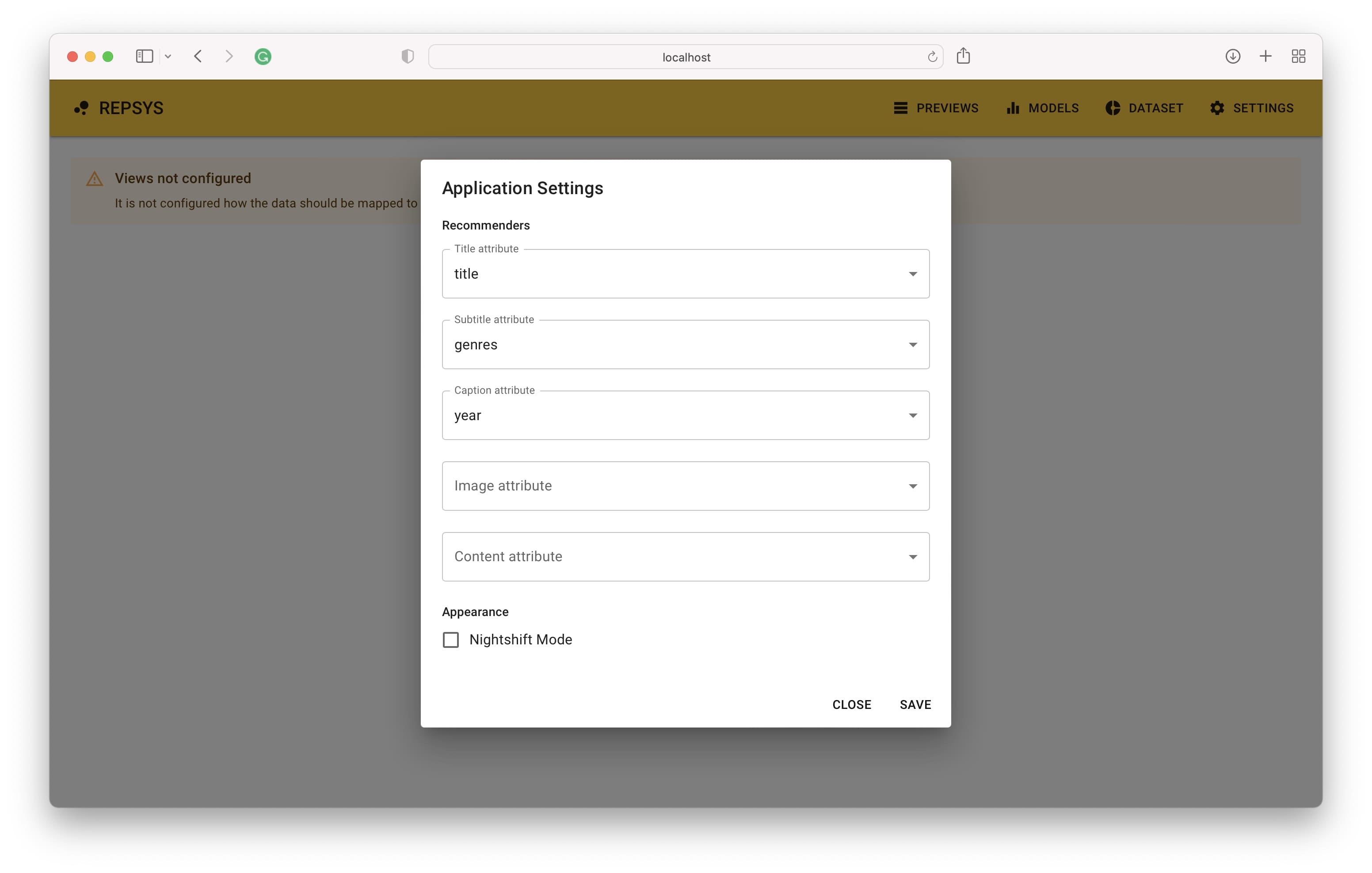
L'application doit être accessible sur l'adresse par défaut http: // localhost: 3001. Lorsque vous ouvrez le lien, vous verrez l'écran principal où vos recommandations apparaissent une fois que vous avez terminé la configuration. La première étape consiste à déterminer comment les colonnes de données des éléments doivent être mappées sur les composants de la vue de l'élément.
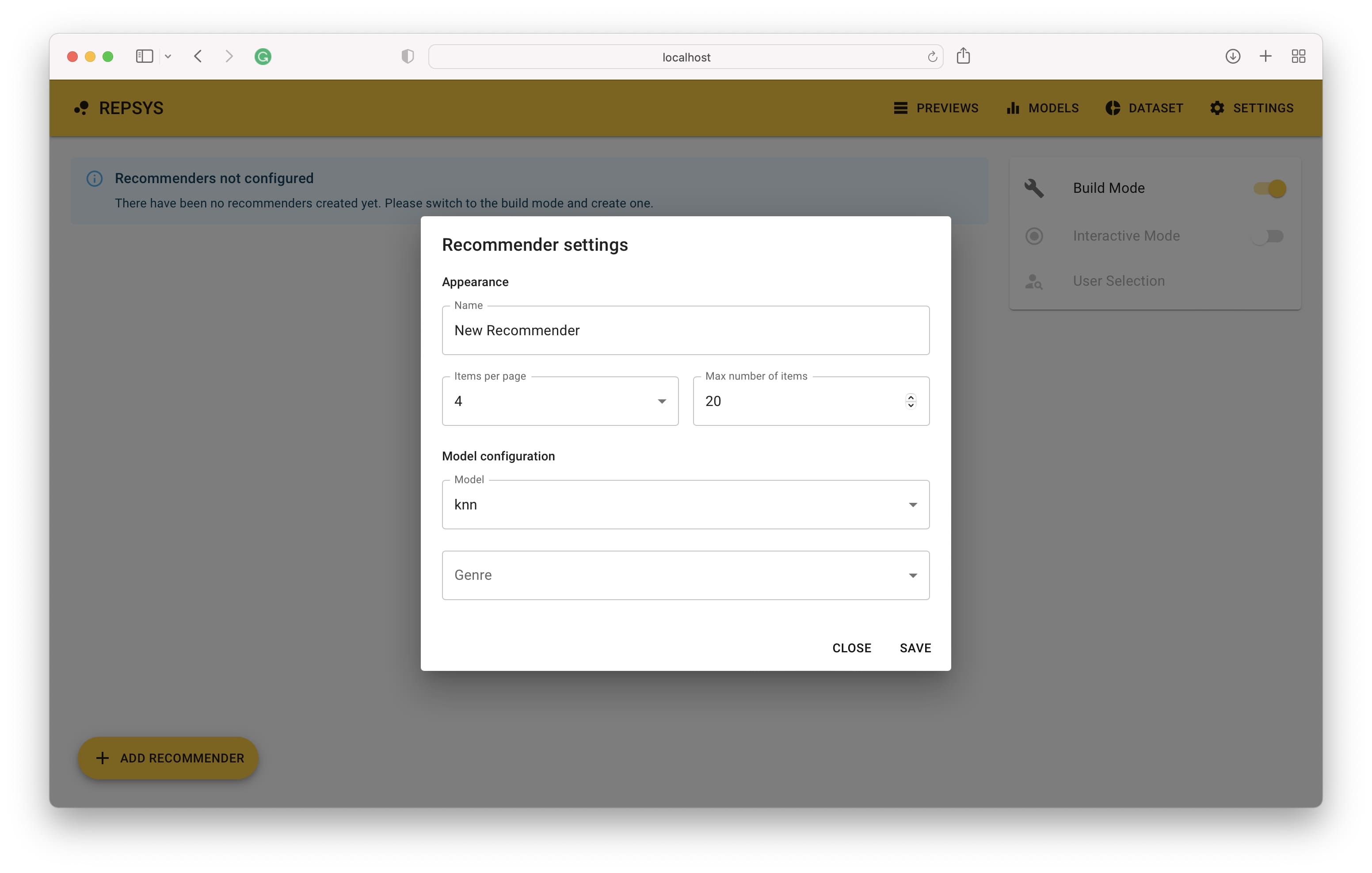
Ensuite, nous devons passer au mode de construction et ajouter deux recommandateurs - un sans filtre et le second avec uniquement des films de comédie inclus.
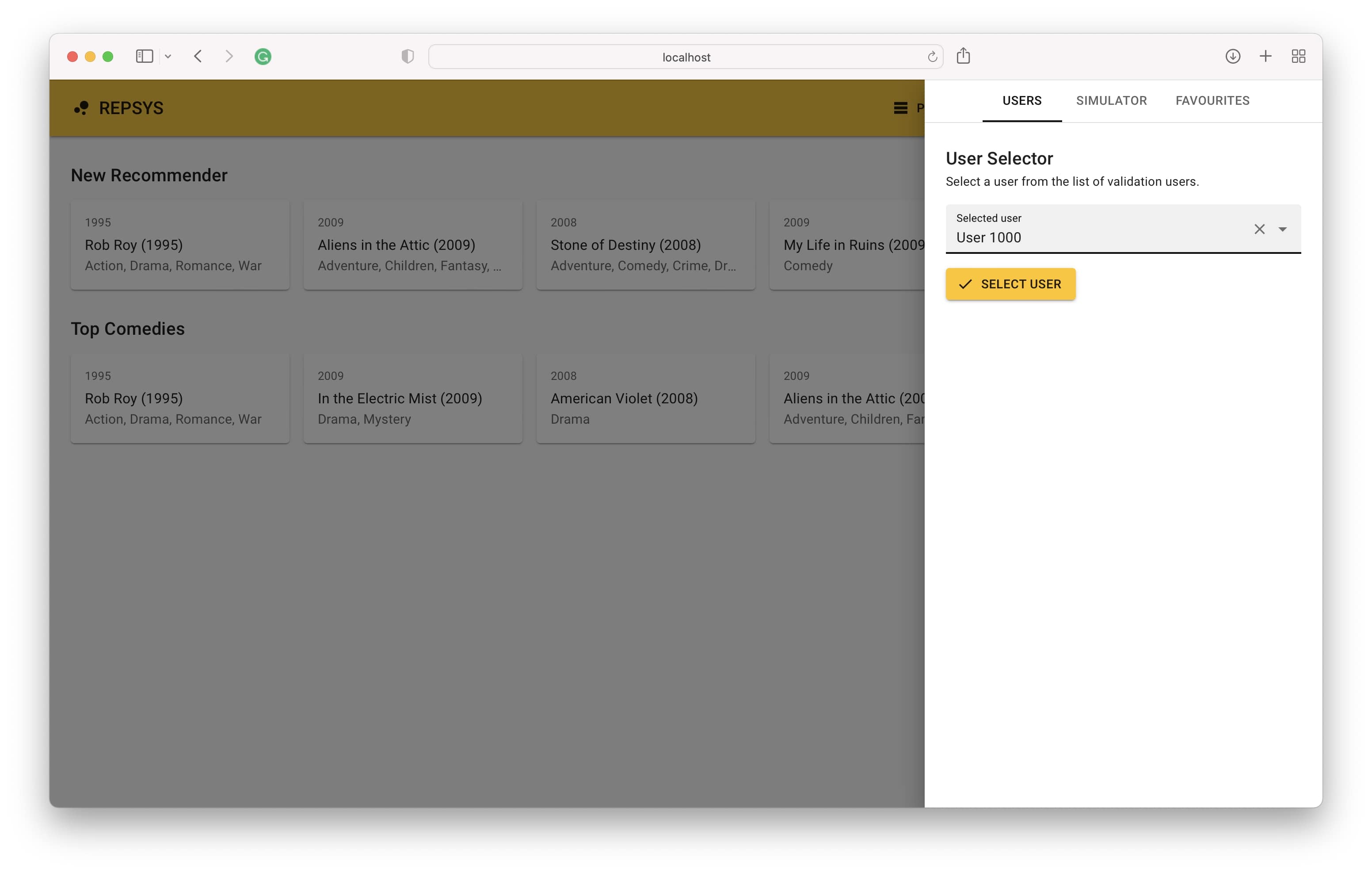
Maintenant, nous revenons du mode de construction et sélectionnons un utilisateur dans l'ensemble de validation (jamais vu par un modèle auparavant).
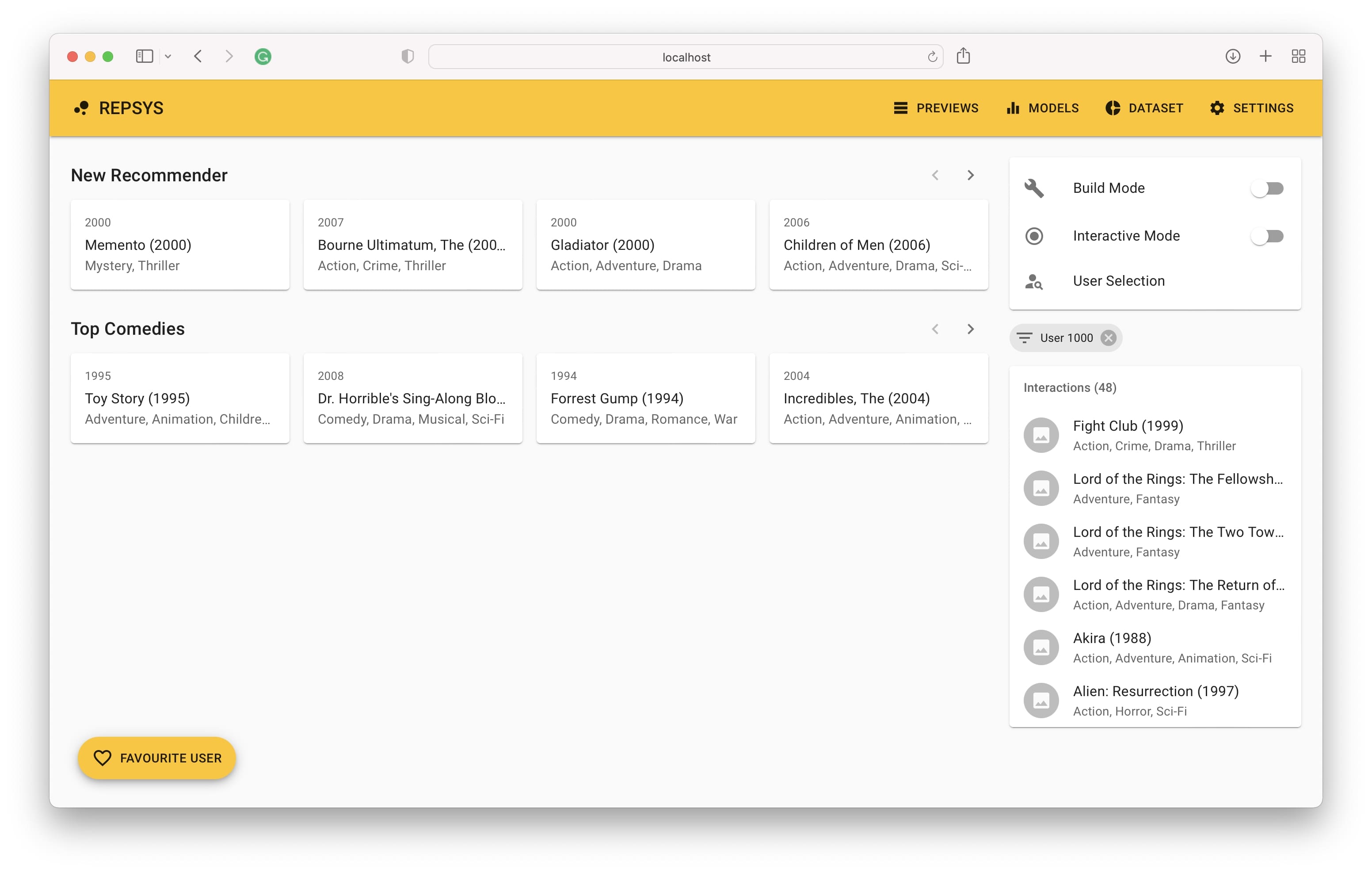
Enfin, nous voyons l'historique d'interaction de l'utilisateur sur le côté droit et les recommandations faites par le modèle sur le côté gauche.
Pour construire le package à partir de la source, vous devez d'abord installer la bibliothèque Node.js et NPM comme documenté ici. Ensuite, vous pouvez exécuter le script suivant à partir du répertoire racine pour créer l'application Web et installer le package localement.
$ ./scripts/install-locally.sh
Si vous utilisez Repsys dans votre travail de recherche, n'oubliez pas de citer l'article connexe:
@inproceedings{10.1145/3523227.3551469,
author = {v{S}afav{r}'{i}k, Jan and Vanv{c}ura, Vojtv{e}ch and Kord'{i}k, Pavel},
title = {RepSys: Framework for Interactive Evaluation of Recommender Systems},
year = {2022},
isbn = {9781450392785},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3523227.3551469},
doi = {10.1145/3523227.3551469},
booktitle = {Proceedings of the 16th ACM Conference on Recommender Systems},
pages = {636–639},
numpages = {4},
keywords = {User simulation, Distribution analysis, Recommender systems},
location = {Seattle, WA, USA},
series = {RecSys '22}
}
Le développement de ce cadre est parrainé par la société Recombee.



