repsys
1.0.0
Repsys adalah kerangka kerja untuk mengembangkan dan menganalisis sistem rekomendasi, dan memungkinkan Anda untuk:
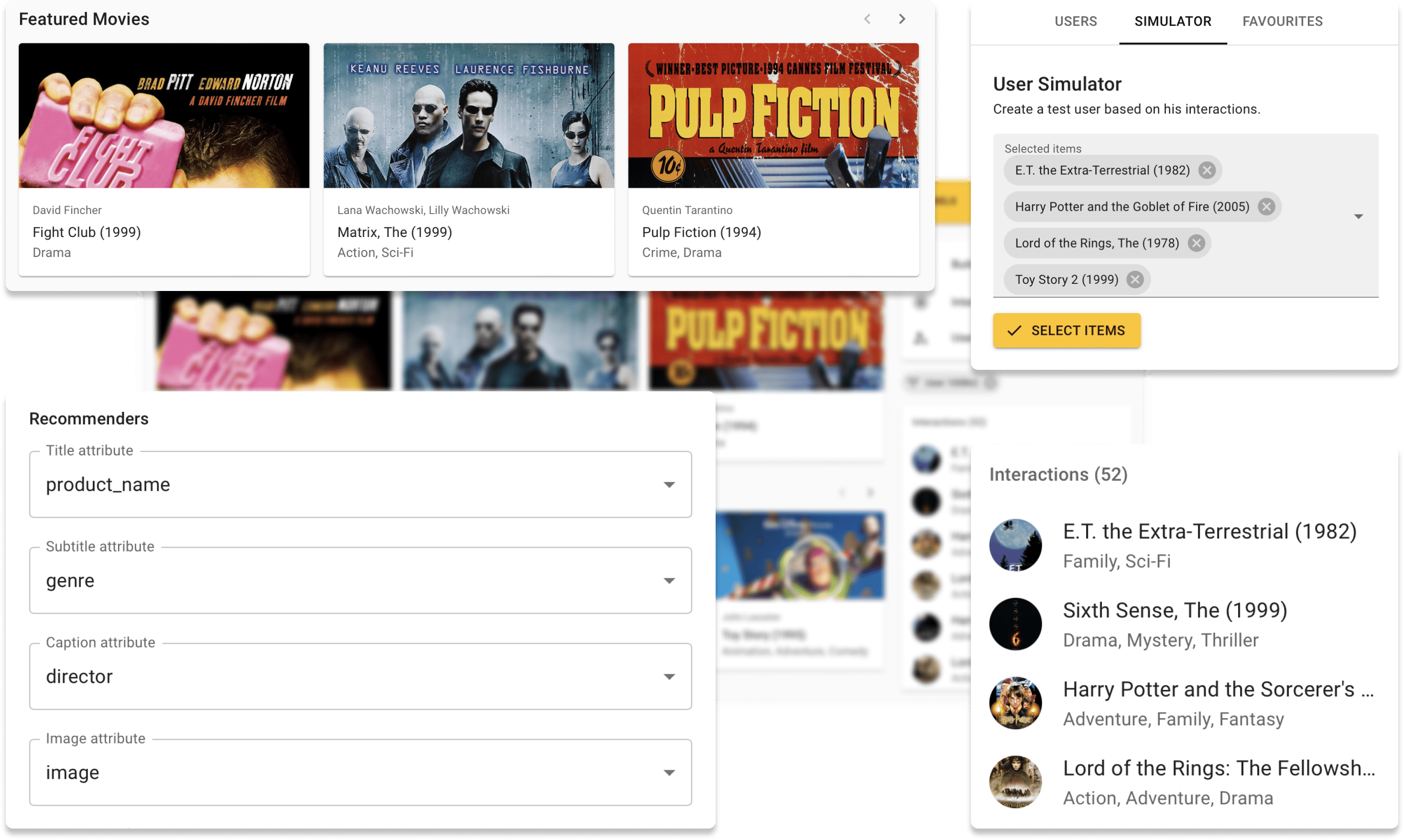
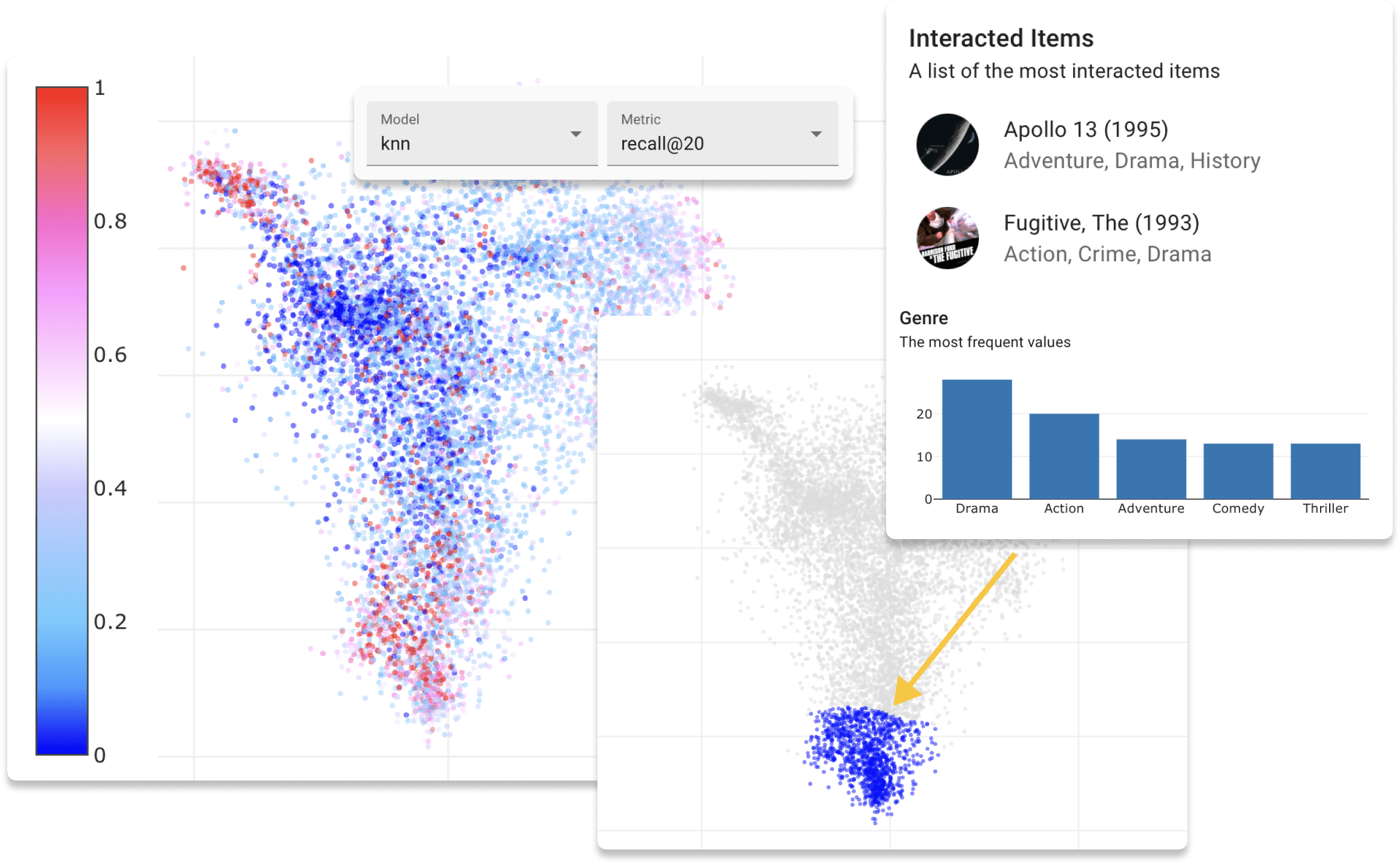

Anda sekarang dapat mencoba repsys online di situs demo kami dengan dataset Movielens. Juga, lihat posting blog interaktif yang kami buat menggunakan komponen widget repsys.
Makalah kami "Repsys: Framework untuk Evaluasi Interaktif Sistem Rekomendasi" diterima untuk konferensi Recsys'22.
Instal paket menggunakan PIP:
$ pip install repsys-framework
Jika Anda akan menggunakan PYMDE untuk visualisasi data, Anda perlu menginstal repsys dengan ekstra berikut:
$ pip install repsys-framework[pymde]
Jika Anda ingin melewatkan tutorial ini dan mencoba kerangka kerja, Anda dapat menarik konten folder demo yang terletak di repositori. Seperti yang disebutkan pada langkah berikutnya, Anda masih harus mengunduh dataset sebelum Anda mulai.
Jika tidak, silakan buat folder proyek kosong yang akan berisi implementasi dataset dan model.
├── __init__.py
├── dataset.py
├── models.py
├── repsys.ini
└── .gitignore
Pertama, kita perlu mengimpor dataset kita. Kami akan menggunakan Dataset 20m Movielens dengan 20 juta peringkat yang dibuat oleh 138.000 pengguna untuk 27.000 film untuk tujuan tutorial. Silakan unduh file ml-20m.zip dan unzip data ke folder saat ini. Kemudian tambahkan konten berikut ke file dataset.py :
import pandas as pd
from repsys import Dataset
import repsys . dtypes as dtypes
class MovieLens ( Dataset ):
def name ( self ):
return "ml20m"
def item_cols ( self ):
return {
"movieId" : dtypes . ItemID (),
"title" : dtypes . Title (),
"genres" : dtypes . Tag ( sep = "|" ),
"year" : dtypes . Number ( data_type = int ),
}
def interaction_cols ( self ):
return {
"movieId" : dtypes . ItemID (),
"userId" : dtypes . UserID (),
"rating" : dtypes . Interaction (),
}
def load_items ( self ):
df = pd . read_csv ( "./ml-20m/movies.csv" )
df [ "year" ] = df [ "title" ]. str . extract ( r"((d+))" )
return df
def load_interactions ( self ):
df = pd . read_csv ( "./ml-20m/ratings.csv" )
return dfKode ini akan menentukan dataset baru yang disebut ML20M, dan akan mengimpor data peringkat dan item. Anda harus selalu menentukan struktur data Anda menggunakan tipe data yang telah ditentukan. Sebelum Anda mengembalikan data, Anda juga dapat melakukan preprocess seperti mengekstraksi tahun film dari kolom judul.
Sekarang kami mendefinisikan model rekomendasi pertama, yang akan menjadi implementasi sederhana dari KNN berbasis pengguna.
import numpy as np
import scipy . sparse as sp
from sklearn . neighbors import NearestNeighbors
from repsys import Model
class KNN ( Model ):
def __init__ ( self ):
self . model = NearestNeighbors ( n_neighbors = 20 , metric = "cosine" )
def name ( self ):
return "knn"
def fit ( self , training = False ):
X = self . dataset . get_train_data ()
self . model . fit ( X )
def predict ( self , X , ** kwargs ):
if X . count_nonzero () == 0 :
return np . random . uniform ( size = X . shape )
distances , indices = self . model . kneighbors ( X )
distances = distances [:, 1 :]
indices = indices [:, 1 :]
distances = 1 - distances
sums = distances . sum ( axis = 1 )
distances = distances / sums [:, np . newaxis ]
def f ( dist , idx ):
A = self . dataset . get_train_data ()[ idx ]
D = sp . diags ( dist )
return D . dot ( A ). sum ( axis = 0 )
vf = np . vectorize ( f , signature = "(n),(n)->(m)" )
predictions = vf ( distances , indices )
predictions [ X . nonzero ()] = 0
return predictionsAnda harus mendefinisikan metode FIT untuk melatih model Anda menggunakan data pelatihan atau memuat model yang dilatih sebelumnya dari suatu file. Semua model dipasang saat aplikasi web dimulai, atau proses evaluasi dimulai. Jika ini bukan fase pelatihan, selalu muat model Anda dari pos pemeriksaan untuk mempercepat proses. Untuk tujuan tutorial, ini dihilangkan.
Anda juga harus mendefinisikan metode prediksi yang menerima matriks jarang dari interaksi pengguna pada input. Untuk setiap pengguna (baris matriks) dan item (kolom matriks), metode ini harus mengembalikan skor yang diprediksi yang menunjukkan seberapa banyak pengguna akan menikmati item tersebut.
Selain itu, Anda dapat menentukan beberapa parameter aplikasi web yang dapat Anda tetapkan selama pembuatan rekomendasi. Nilainya kemudian dapat diakses dalam argumen **kwargs dari metode prediksi. Dalam contoh, kami membuat input terpilih dengan semua genre unik dan menyaring hanya film -film yang tidak mengandung genre yang dipilih.
File terakhir yang harus kami buat adalah konfigurasi yang memungkinkan Anda untuk mengontrol proses pemisahan data, pengaturan server, perilaku kerangka kerja, dll.
[general]
seed =1234
[dataset]
train_split_prop =0.85
test_holdout_prop =0.2
min_user_interacts =5
min_item_interacts =0
[evaluation]
precision_recall_k =20,50
ndcg_k =100
coverage_k =20
diversity_k =20
novelty_k =20
percentage_lt_k =20
coverage_lt_k =20
[visualization]
embed_method =pymde
pymde_neighbors =15
umap_neighbors =15
umap_min_dist =0.1
tsne_perplexity =30
[server]
port =3001Sebelum kami melatih model kami, kami perlu membagi data menjadi set kereta, validasi, dan tes. Jalankan perintah berikut dari direktori saat ini.
$ repsys dataset split
Ini akan menampung 85% pengguna sebagai data pelatihan, dan sisanya 15% akan digunakan sebagai data validasi/uji dengan masing -masing 7,5% pengguna. Untuk validasi dan set tes, 20% dari interaksi juga akan bertahan untuk tujuan evaluasi. Dataset split akan disimpan di folder pos pemeriksaan default.
Sekarang kita bisa pindah ke proses pelatihan. Untuk melakukan ini, hubungi perintah berikut.
$ repsys model train
Perintah ini akan memanggil metode Fit dari setiap model dengan bendera pelatihan yang diatur ke True. Anda selalu dapat membatasi model menggunakan bendera -m dengan nama model sebagai parameter.
Ketika data disiapkan dan model yang dilatih, kami dapat mengevaluasi kinerja model pada interaksi pengguna yang tidak terlihat. Jalankan perintah berikut untuk melakukannya.
$ repsys model eval
Sekali lagi, Anda dapat membatasi model menggunakan bendera -m . Hasilnya akan disimpan di folder pos pemeriksaan saat evaluasi selesai.
Sebelum memulai aplikasi web, langkah terakhir adalah mengevaluasi data dataset. Prosedur ini akan membuat pengguna dan item embedding dari data pelatihan dan validasi untuk memungkinkan Anda menjelajahi ruang laten. Jalankan perintah berikut dari direktori proyek.
$ repsys dataset eval
Anda dapat memilih dari tiga jenis algoritma embeddings:
--method umap (ini adalah opsi default).--method pymde .--method tsne .--method custom dan tambahkan metode berikut ke kelas model pilihan Anda. Dalam hal ini, Anda juga harus menentukan nama model menggunakan parameter -m . from sklearn . decomposition import NMF
def compute_embeddings ( self , X ):
nmf = NMF ( n_components = 2 )
W = nmf . fit_transform ( X )
H = nmf . components_
return W , H . TDalam contoh, faktorisasi matriks negatif digunakan. Anda harus mengembalikan pasangan embeddings pengguna dan item dalam urutan ini. Juga, penting untuk mengembalikan matriks dalam bentuk (n_users/n_items, n_dim). Jika dimensi yang dikurangi lebih tinggi dari 2, metode TSNE diterapkan.
Akhirnya, sekarang saatnya untuk memulai aplikasi web untuk melihat hasil evaluasi dan pratinjau rekomendasi langsung dari model Anda.
$ repsys server
Aplikasi harus dapat diakses pada alamat default http: // localhost: 3001. Saat Anda membuka tautan, Anda akan melihat layar utama di mana rekomendasi Anda muncul setelah Anda menyelesaikan pengaturan. Langkah pertama adalah mendefinisikan bagaimana kolom data item harus dipetakan ke komponen tampilan item.
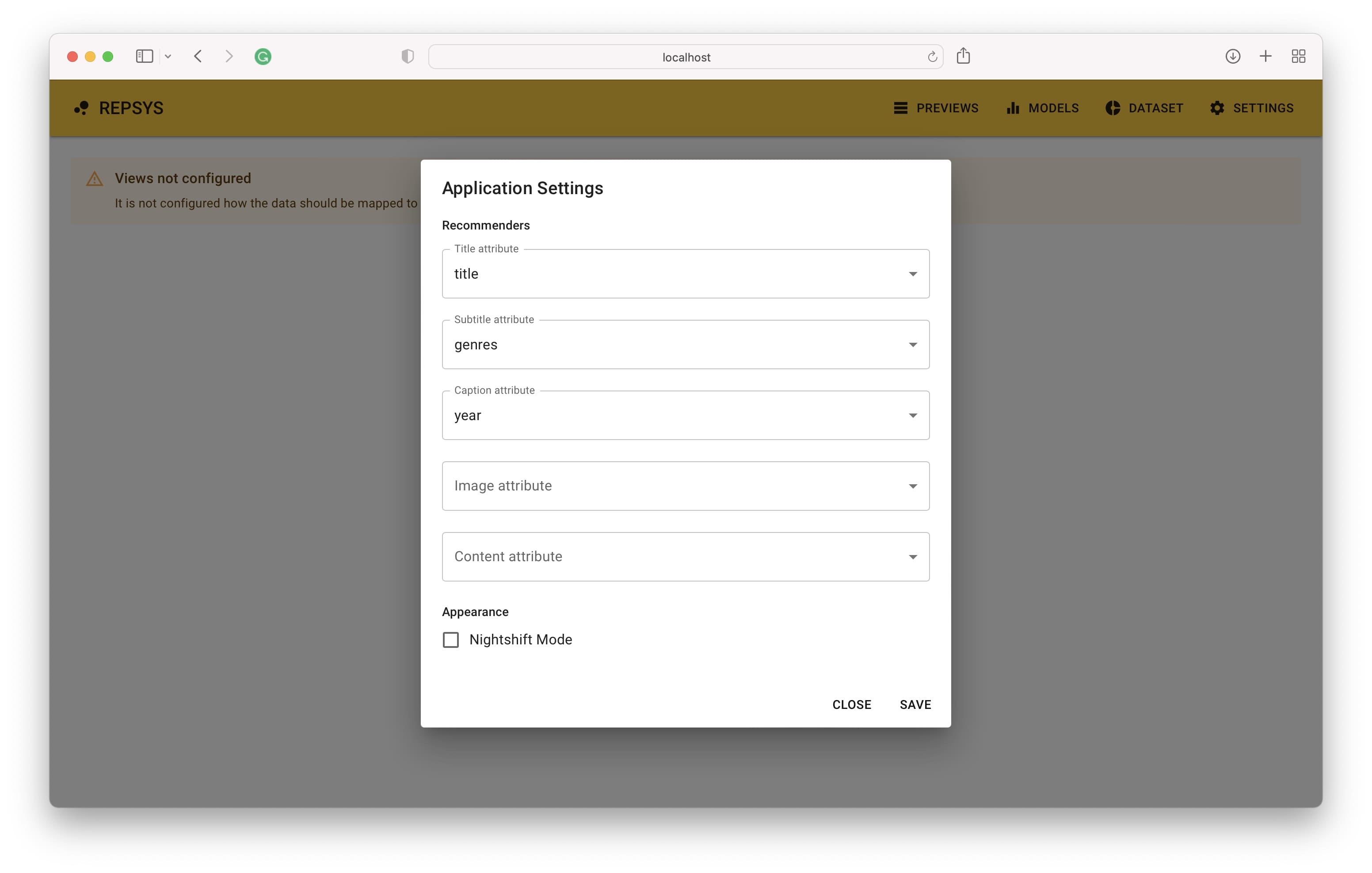
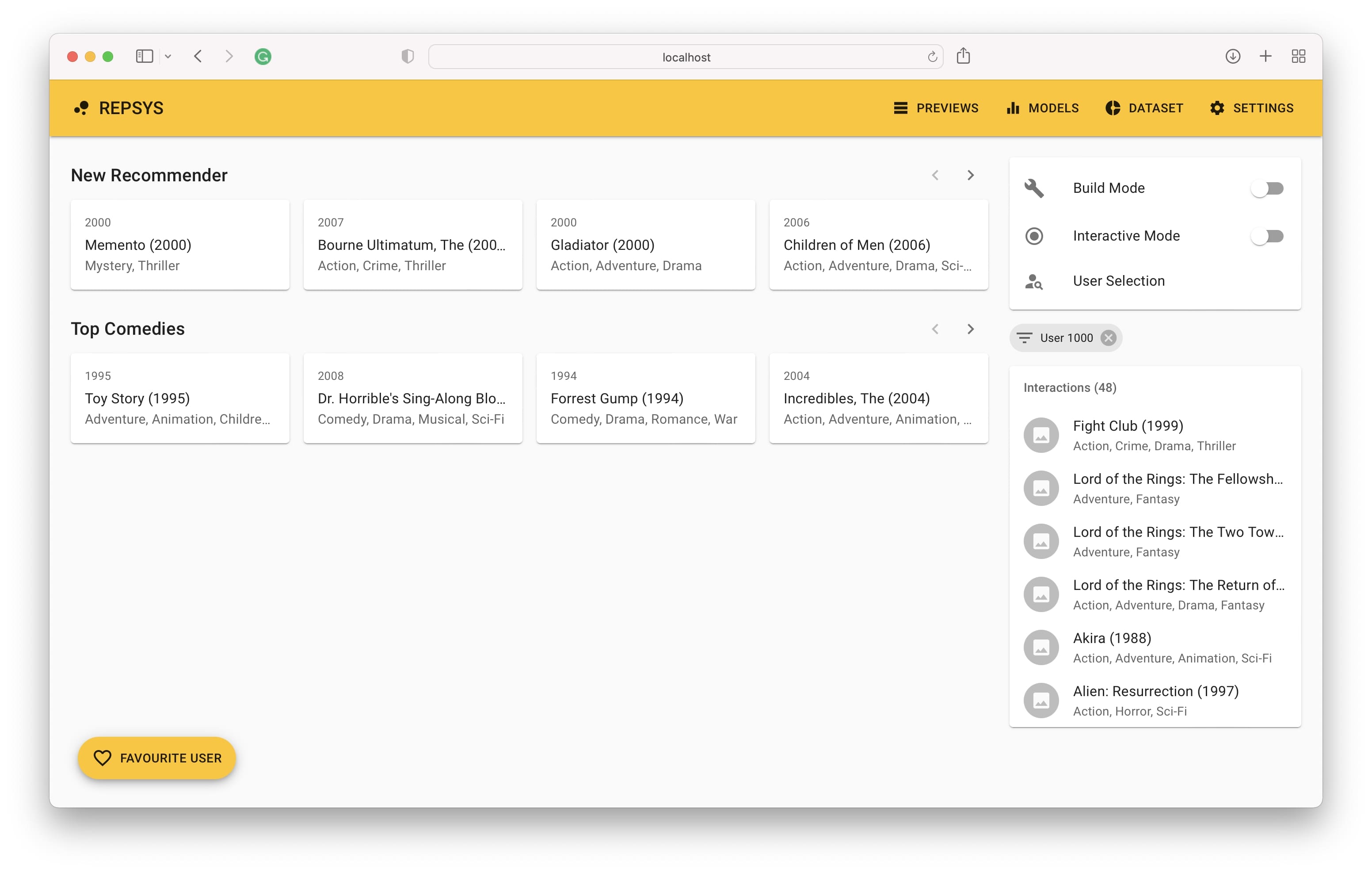
Kemudian kita perlu beralih ke mode build dan menambahkan dua rekomendasi - satu tanpa filter dan yang kedua dengan hanya film komedi yang disertakan.
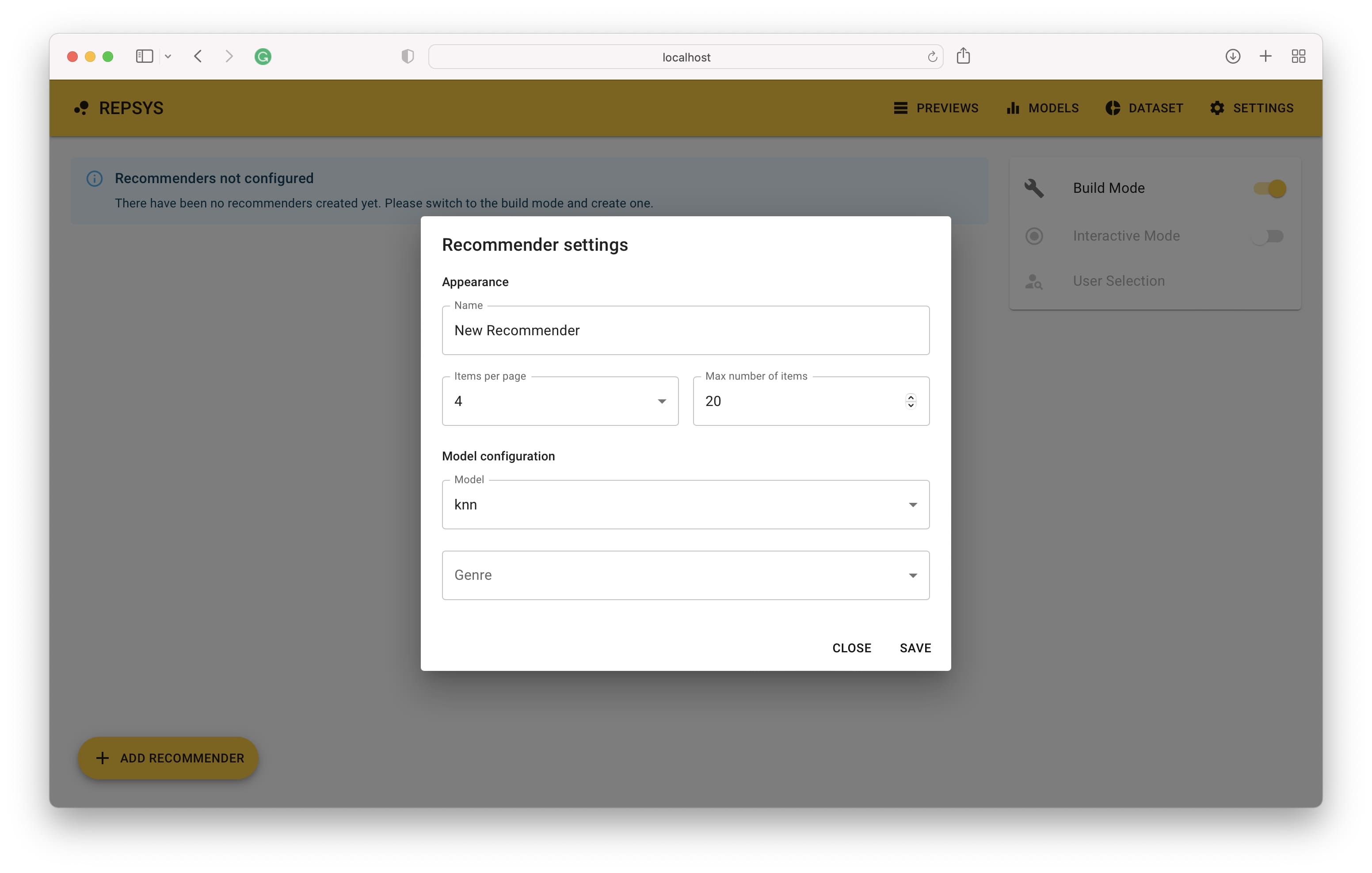
Sekarang kami beralih kembali dari mode build dan memilih pengguna dari set validasi (belum pernah dilihat oleh model sebelumnya).
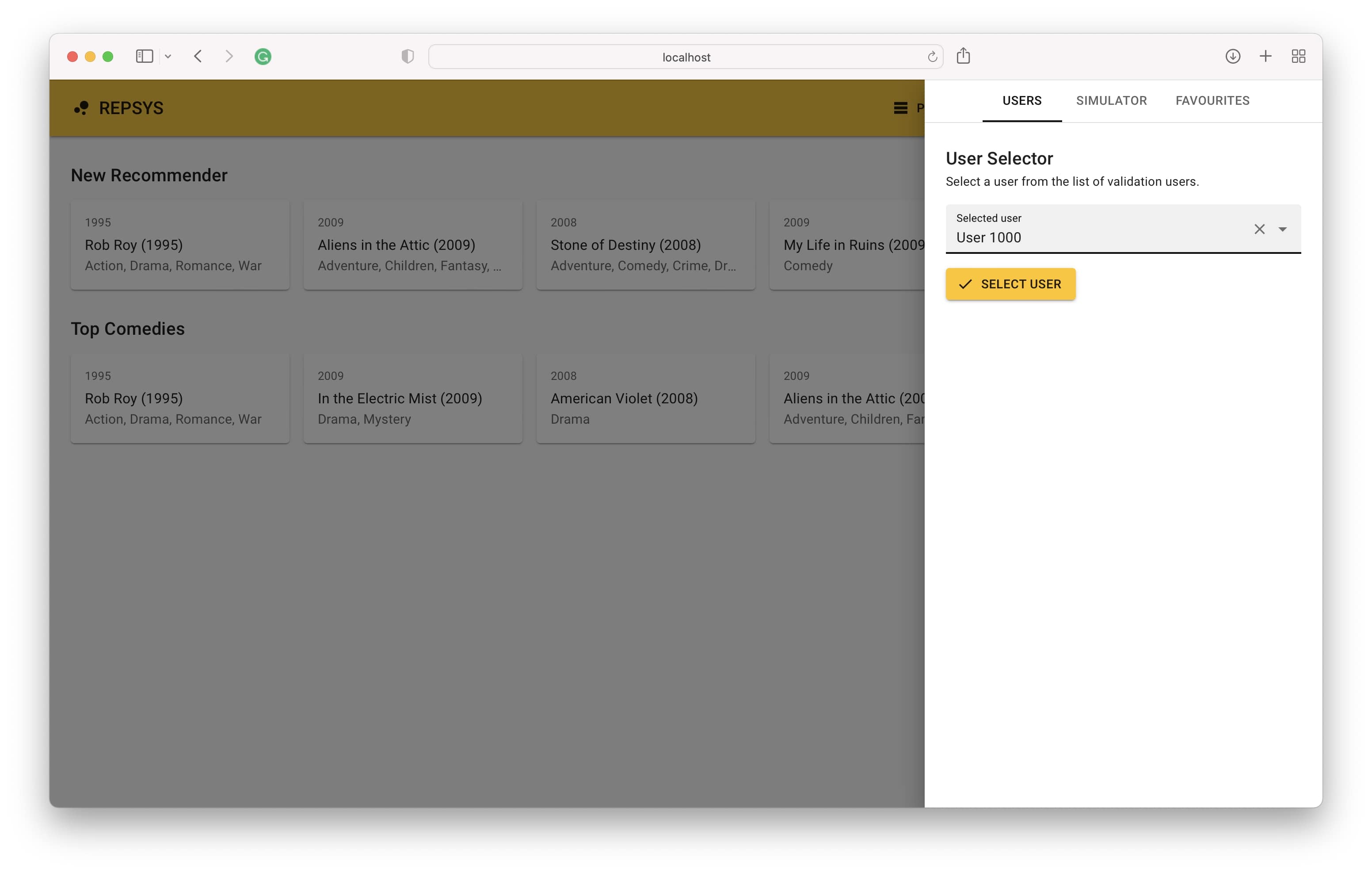
Akhirnya, kami melihat riwayat interaksi pengguna di sisi kanan dan rekomendasi yang dibuat oleh model di sisi kiri.
Untuk membangun paket dari sumbernya, pertama -tama Anda harus menginstal pustaka Node.js dan NPM seperti yang didokumentasikan di sini. Kemudian Anda dapat menjalankan skrip berikut dari direktori root untuk membangun aplikasi web dan menginstal paket secara lokal.
$ ./scripts/install-locally.sh
Jika Anda menggunakan repsys dalam pekerjaan penelitian Anda, jangan lupa untuk mengutip makalah terkait:
@inproceedings{10.1145/3523227.3551469,
author = {v{S}afav{r}'{i}k, Jan and Vanv{c}ura, Vojtv{e}ch and Kord'{i}k, Pavel},
title = {RepSys: Framework for Interactive Evaluation of Recommender Systems},
year = {2022},
isbn = {9781450392785},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3523227.3551469},
doi = {10.1145/3523227.3551469},
booktitle = {Proceedings of the 16th ACM Conference on Recommender Systems},
pages = {636–639},
numpages = {4},
keywords = {User simulation, Distribution analysis, Recommender systems},
location = {Seattle, WA, USA},
series = {RecSys '22}
}
Pengembangan kerangka kerja ini disponsori oleh perusahaan rekombee.



