repsys
1.0.0
Repsys เป็นกรอบสำหรับการพัฒนาและวิเคราะห์ระบบแนะนำและช่วยให้คุณ:
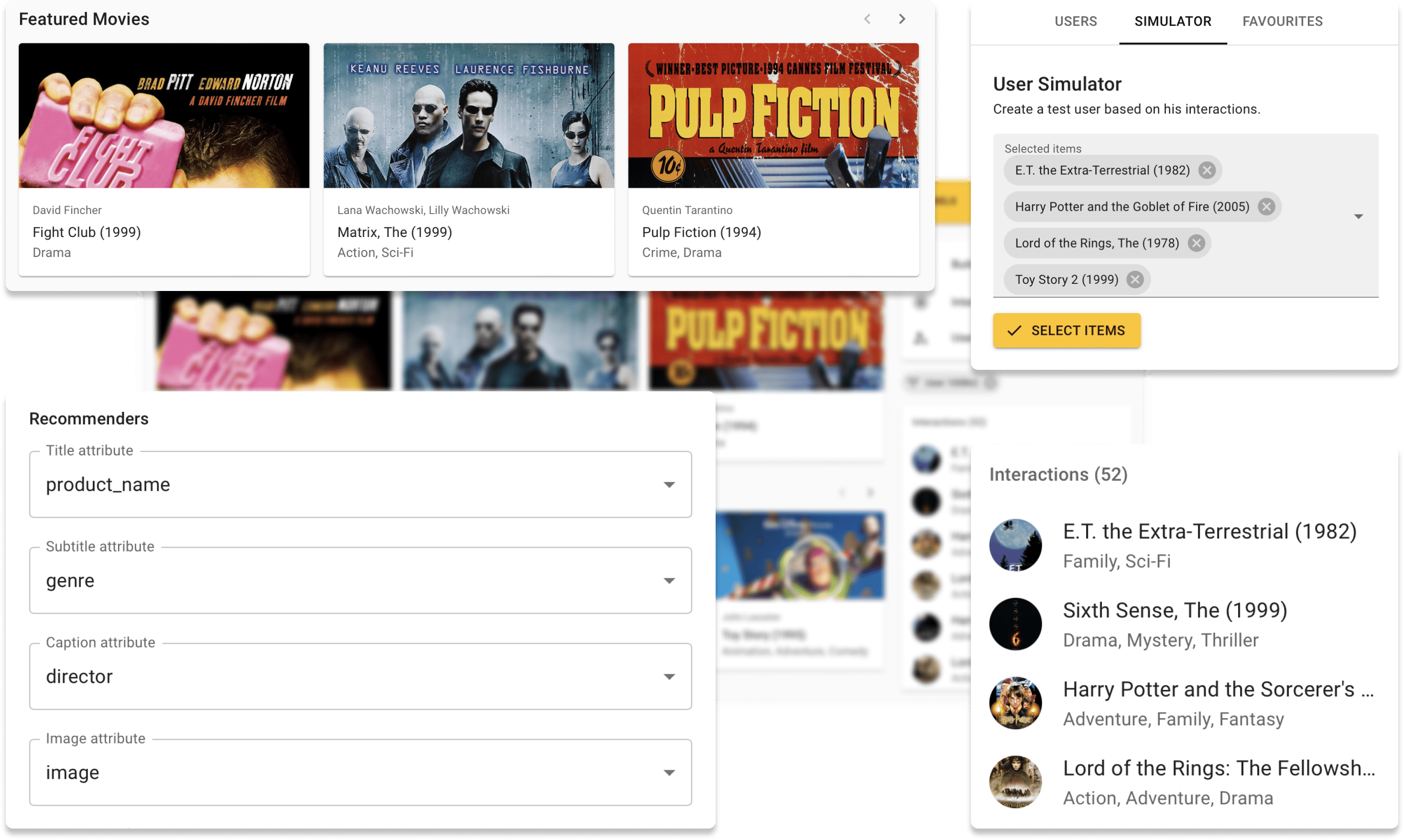
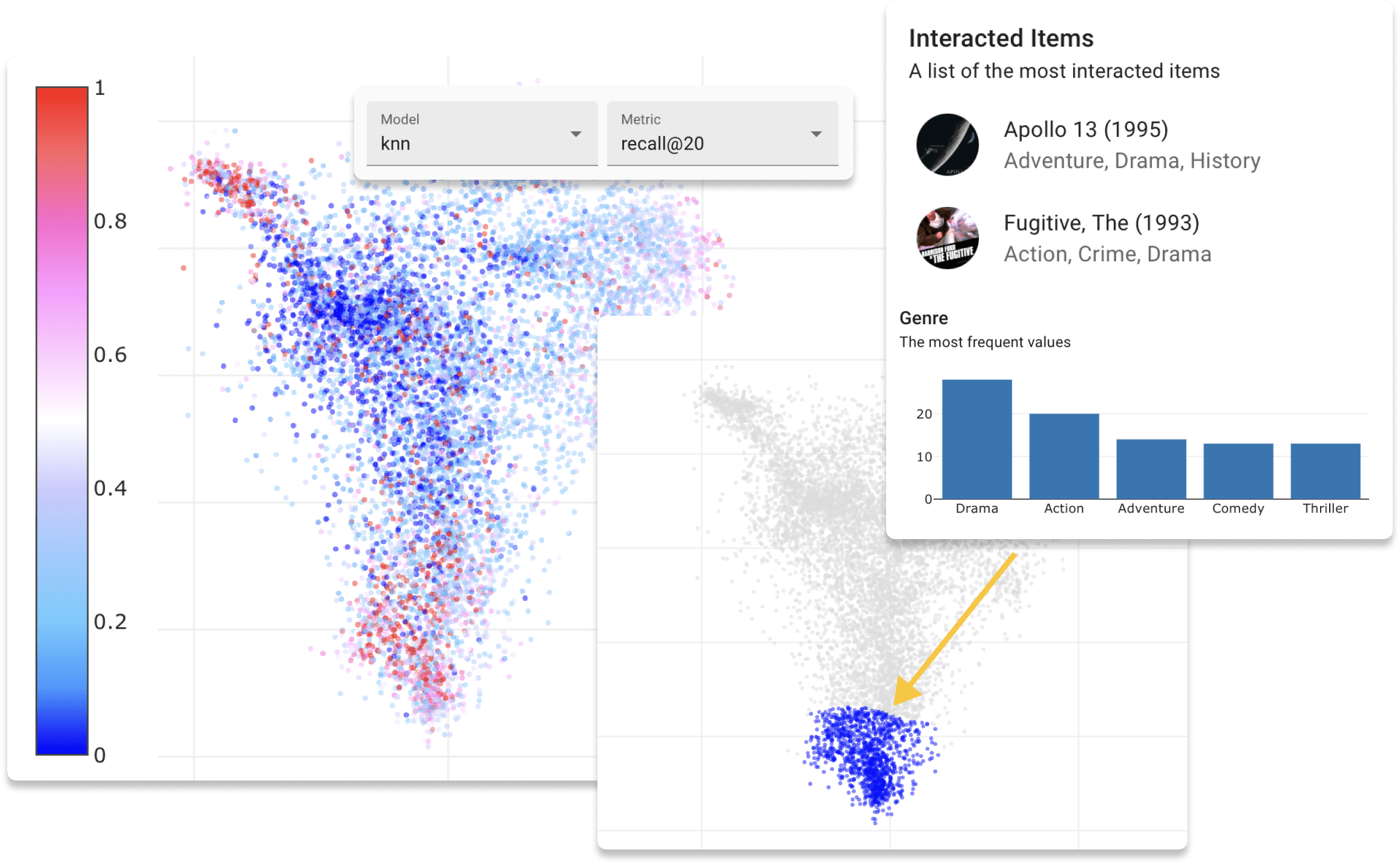

ตอนนี้คุณสามารถลอง repsys ออนไลน์บนเว็บไซต์สาธิตของเราด้วยชุดข้อมูล Movielens นอกจากนี้ตรวจสอบโพสต์บล็อกแบบโต้ตอบที่เราทำโดยใช้ส่วนประกอบวิดเจ็ต Repsys
กระดาษของเรา "repsys: กรอบสำหรับการประเมินแบบโต้ตอบของระบบผู้แนะนำ" ได้รับการยอมรับในการประชุม Recsys'22
ติดตั้งแพ็คเกจโดยใช้ PIP:
$ pip install repsys-framework
หากคุณจะใช้ PYMDE สำหรับการสร้างภาพข้อมูลคุณต้องติดตั้ง repsys ด้วยความพิเศษต่อไปนี้:
$ pip install repsys-framework[pymde]
หากคุณต้องการข้ามบทช่วยสอนนี้และลองใช้เฟรมเวิร์กคุณสามารถดึงเนื้อหาของโฟลเดอร์สาธิตที่อยู่ที่พื้นที่เก็บข้อมูล ดังที่ได้กล่าวไว้ในขั้นตอนต่อไปคุณยังต้องดาวน์โหลดชุดข้อมูลก่อนที่จะเริ่ม
มิฉะนั้นโปรดสร้างโฟลเดอร์โครงการว่างเปล่าที่จะมีชุดข้อมูลและการใช้งานโมเดล
├── __init__.py
├── dataset.py
├── models.py
├── repsys.ini
└── .gitignore
ประการแรกเราต้องนำเข้าชุดข้อมูลของเรา เราจะใช้ชุดข้อมูล Movielens 20m โดยมีการจัดอันดับ 20 ล้านรายจากผู้ใช้ 138,000 คนเป็น 27,000 เรื่องเพื่อการสอน โปรดดาวน์โหลดไฟล์ ml-20m.zip และคลายซิปข้อมูลลงในโฟลเดอร์ปัจจุบัน จากนั้นเพิ่มเนื้อหาต่อไปนี้ลงในไฟล์ dataset.py :
import pandas as pd
from repsys import Dataset
import repsys . dtypes as dtypes
class MovieLens ( Dataset ):
def name ( self ):
return "ml20m"
def item_cols ( self ):
return {
"movieId" : dtypes . ItemID (),
"title" : dtypes . Title (),
"genres" : dtypes . Tag ( sep = "|" ),
"year" : dtypes . Number ( data_type = int ),
}
def interaction_cols ( self ):
return {
"movieId" : dtypes . ItemID (),
"userId" : dtypes . UserID (),
"rating" : dtypes . Interaction (),
}
def load_items ( self ):
df = pd . read_csv ( "./ml-20m/movies.csv" )
df [ "year" ] = df [ "title" ]. str . extract ( r"((d+))" )
return df
def load_interactions ( self ):
df = pd . read_csv ( "./ml-20m/ratings.csv" )
return dfรหัสนี้จะกำหนดชุดข้อมูลใหม่ที่เรียกว่า ML20M และจะนำเข้าข้อมูลการให้คะแนนและรายการ คุณต้องระบุโครงสร้างข้อมูลของคุณเสมอโดยใช้ชนิดข้อมูลที่กำหนดไว้ล่วงหน้า ก่อนที่คุณจะส่งคืนข้อมูลคุณสามารถประมวลผลล่วงหน้าได้เช่นการแยกปีของภาพยนตร์จากคอลัมน์ชื่อเรื่อง
ตอนนี้เรากำหนดรูปแบบคำแนะนำแรกซึ่งจะเป็นการใช้งานอย่างง่ายของ KNN ที่ใช้ผู้ใช้
import numpy as np
import scipy . sparse as sp
from sklearn . neighbors import NearestNeighbors
from repsys import Model
class KNN ( Model ):
def __init__ ( self ):
self . model = NearestNeighbors ( n_neighbors = 20 , metric = "cosine" )
def name ( self ):
return "knn"
def fit ( self , training = False ):
X = self . dataset . get_train_data ()
self . model . fit ( X )
def predict ( self , X , ** kwargs ):
if X . count_nonzero () == 0 :
return np . random . uniform ( size = X . shape )
distances , indices = self . model . kneighbors ( X )
distances = distances [:, 1 :]
indices = indices [:, 1 :]
distances = 1 - distances
sums = distances . sum ( axis = 1 )
distances = distances / sums [:, np . newaxis ]
def f ( dist , idx ):
A = self . dataset . get_train_data ()[ idx ]
D = sp . diags ( dist )
return D . dot ( A ). sum ( axis = 0 )
vf = np . vectorize ( f , signature = "(n),(n)->(m)" )
predictions = vf ( distances , indices )
predictions [ X . nonzero ()] = 0
return predictionsคุณต้องกำหนดวิธี FIT ในการฝึกอบรมแบบจำลองของคุณโดยใช้ข้อมูลการฝึกอบรมหรือโหลดโมเดลที่ผ่านการฝึกอบรมมาก่อนจากไฟล์ ทุกรุ่นได้รับการติดตั้งเมื่อเว็บแอปพลิเคชันเริ่มต้นหรือกระบวนการประเมินเริ่มต้นขึ้น หากนี่ไม่ใช่ขั้นตอนการฝึกอบรมให้โหลดโมเดลของคุณจากจุดตรวจสอบเพื่อเร่งกระบวนการ เพื่อจุดประสงค์ในการสอนสิ่งนี้ถูกละเว้น
คุณต้องกำหนดวิธีการทำนายที่ได้รับเมทริกซ์กระจัดกระจายของการโต้ตอบของผู้ใช้ในอินพุต สำหรับผู้ใช้แต่ละคน (แถวของเมทริกซ์) และไอเท็ม (คอลัมน์ของเมทริกซ์) วิธีการควรส่งคืนคะแนนที่คาดการณ์ไว้ซึ่งจะแสดงว่าผู้ใช้จะเพลิดเพลินไปกับรายการ
นอกจากนี้คุณสามารถระบุพารามิเตอร์เว็บแอปพลิเคชันบางอย่างที่คุณสามารถตั้งค่าระหว่างการสร้างผู้แนะนำ ค่าจะสามารถเข้าถึงได้ในอาร์กิวเมนต์ **kwargs ของวิธีการทำนาย ในตัวอย่างเราสร้างอินพุตเลือกด้วยประเภทที่ไม่ซ้ำกันทั้งหมดและกรองเฉพาะภาพยนตร์ที่ไม่มีประเภทที่เลือก
ไฟล์สุดท้ายที่เราควรสร้างคือการกำหนดค่าที่ช่วยให้คุณสามารถควบคุมกระบวนการแยกข้อมูลการตั้งค่าเซิร์ฟเวอร์พฤติกรรมเฟรมเวิร์ก ฯลฯ
[general]
seed =1234
[dataset]
train_split_prop =0.85
test_holdout_prop =0.2
min_user_interacts =5
min_item_interacts =0
[evaluation]
precision_recall_k =20,50
ndcg_k =100
coverage_k =20
diversity_k =20
novelty_k =20
percentage_lt_k =20
coverage_lt_k =20
[visualization]
embed_method =pymde
pymde_neighbors =15
umap_neighbors =15
umap_min_dist =0.1
tsne_perplexity =30
[server]
port =3001ก่อนที่เราจะฝึกอบรมแบบจำลองของเราเราต้องแยกข้อมูลออกเป็นรถไฟการตรวจสอบและชุดทดสอบ เรียกใช้คำสั่งต่อไปนี้จากไดเรกทอรีปัจจุบัน
$ repsys dataset split
สิ่งนี้จะถือว่า 85% ของผู้ใช้เป็นข้อมูลการฝึกอบรมและส่วนที่เหลือ 15% จะใช้เป็นข้อมูลการตรวจสอบ/ทดสอบโดยมีผู้ใช้ 7.5% สำหรับทั้งชุดการตรวจสอบและทดสอบ 20% ของการโต้ตอบจะถูกจัดขึ้นเพื่อวัตถุประสงค์ในการประเมิน ชุดข้อมูลแยกจะถูกเก็บไว้ในโฟลเดอร์จุดตรวจสอบเริ่มต้น
ตอนนี้เราสามารถย้ายไปยังกระบวนการฝึกอบรม หากต้องการทำสิ่งนี้โปรดโทรหาคำสั่งต่อไปนี้
$ repsys model train
คำสั่งนี้จะเรียกวิธีการพอดีของแต่ละรุ่นด้วยการตั้งค่าสถานะการฝึกอบรมเป็น TRUE คุณสามารถ จำกัด โมเดลที่ใช้ -m Flag ด้วยชื่อของโมเดลเป็นพารามิเตอร์
เมื่อข้อมูลถูกเตรียมและแบบจำลองที่ผ่านการฝึกอบรมเราสามารถประเมินประสิทธิภาพของโมเดลในการโต้ตอบของผู้ใช้ที่มองไม่เห็น เรียกใช้คำสั่งต่อไปนี้เพื่อทำเช่นนั้น
$ repsys model eval
อีกครั้งคุณสามารถ จำกัด รุ่นโดยใช้ธง -m ผลลัพธ์จะถูกเก็บไว้ในโฟลเดอร์จุดตรวจสอบเมื่อทำการประเมินเสร็จ
ก่อนที่จะเริ่มเว็บแอปพลิเคชันขั้นตอนสุดท้ายคือการประเมินข้อมูลของชุดข้อมูล ขั้นตอนนี้จะสร้างผู้ใช้และรายการฝังข้อมูลการฝึกอบรมและการตรวจสอบข้อมูลเพื่อให้คุณสำรวจพื้นที่แฝง เรียกใช้คำสั่งต่อไปนี้จากไดเรกทอรีโครงการ
$ repsys dataset eval
คุณสามารถเลือกอัลกอริทึม Embeddings สามประเภท:
--method umap (นี่คือตัวเลือกเริ่มต้น)--method pymde--method tsne--method custom และเพิ่มวิธีการต่อไปนี้ในคลาสของโมเดลที่คุณเลือก ในกรณีนี้คุณต้องระบุชื่อของโมเดลโดยใช้พารามิเตอร์ -m from sklearn . decomposition import NMF
def compute_embeddings ( self , X ):
nmf = NMF ( n_components = 2 )
W = nmf . fit_transform ( X )
H = nmf . components_
return W , H . Tในตัวอย่างการใช้การผสมเมทริกซ์เชิงลบจะใช้ คุณต้องส่งคืนคู่ผู้ใช้และรายการ Embeddings ในลำดับนี้ นอกจากนี้ยังเป็นสิ่งสำคัญที่จะต้องส่งคืนเมทริกซ์ในรูปของ (n_users/n_items, n_dim) หากมิติที่ลดลงสูงกว่า 2 จะใช้วิธี TSNE
ในที่สุดก็ถึงเวลาที่จะเริ่มต้นแอปพลิเคชันเว็บเพื่อดูผลลัพธ์ของการประเมินและแสดงตัวอย่างคำแนะนำสดของโมเดลของคุณ
$ repsys server
แอปพลิเคชันควรเข้าถึงได้บนที่อยู่เริ่มต้น http: // localhost: 3001 เมื่อคุณเปิดลิงค์คุณจะเห็นหน้าจอหลักที่คำแนะนำของคุณปรากฏขึ้นเมื่อคุณตั้งค่าเสร็จสิ้น ขั้นตอนแรกคือการกำหนดวิธีที่คอลัมน์ข้อมูลของรายการควรแมปกับส่วนประกอบมุมมองรายการ
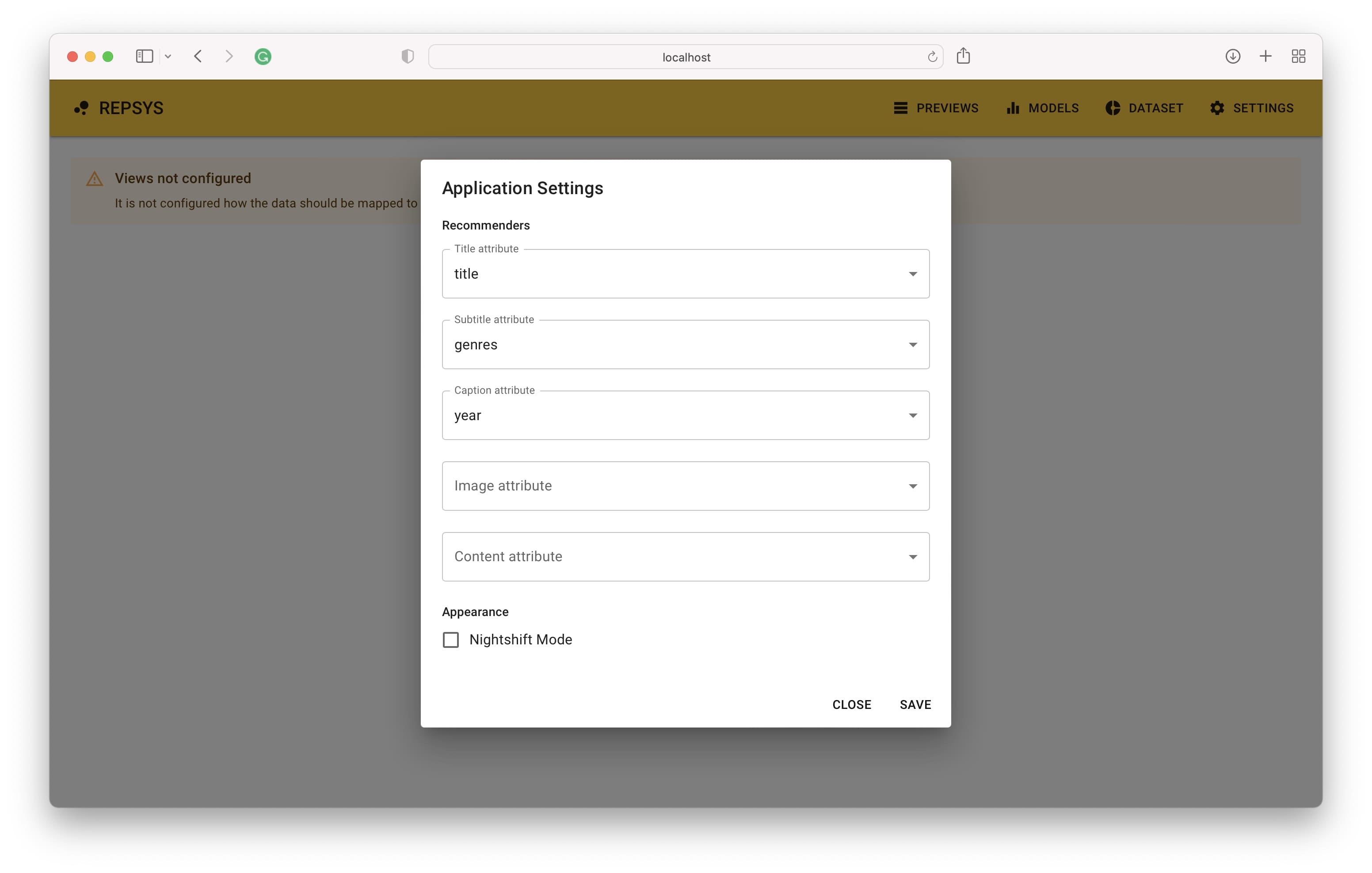
จากนั้นเราต้องเปลี่ยนไปใช้โหมดบิลด์และเพิ่มผู้แนะนำสองคน - หนึ่งที่ไม่มีตัวกรองและภาพยนตร์เรื่องที่สองที่มีภาพยนตร์ตลกเท่านั้น
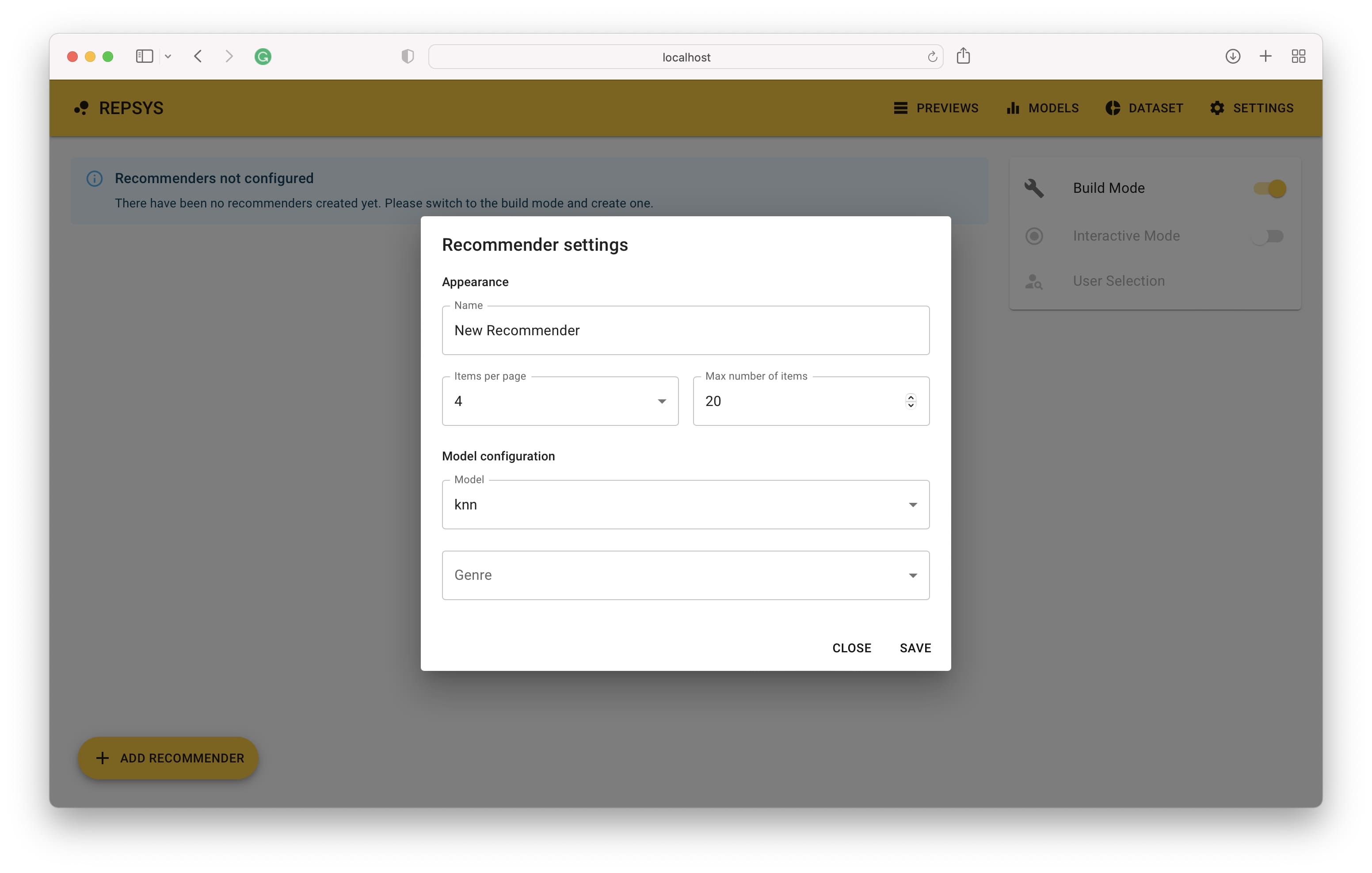
ตอนนี้เราเปลี่ยนกลับจากโหมดการสร้างและเลือกผู้ใช้จากชุดการตรวจสอบ (ไม่เคยเห็นมาก่อน)
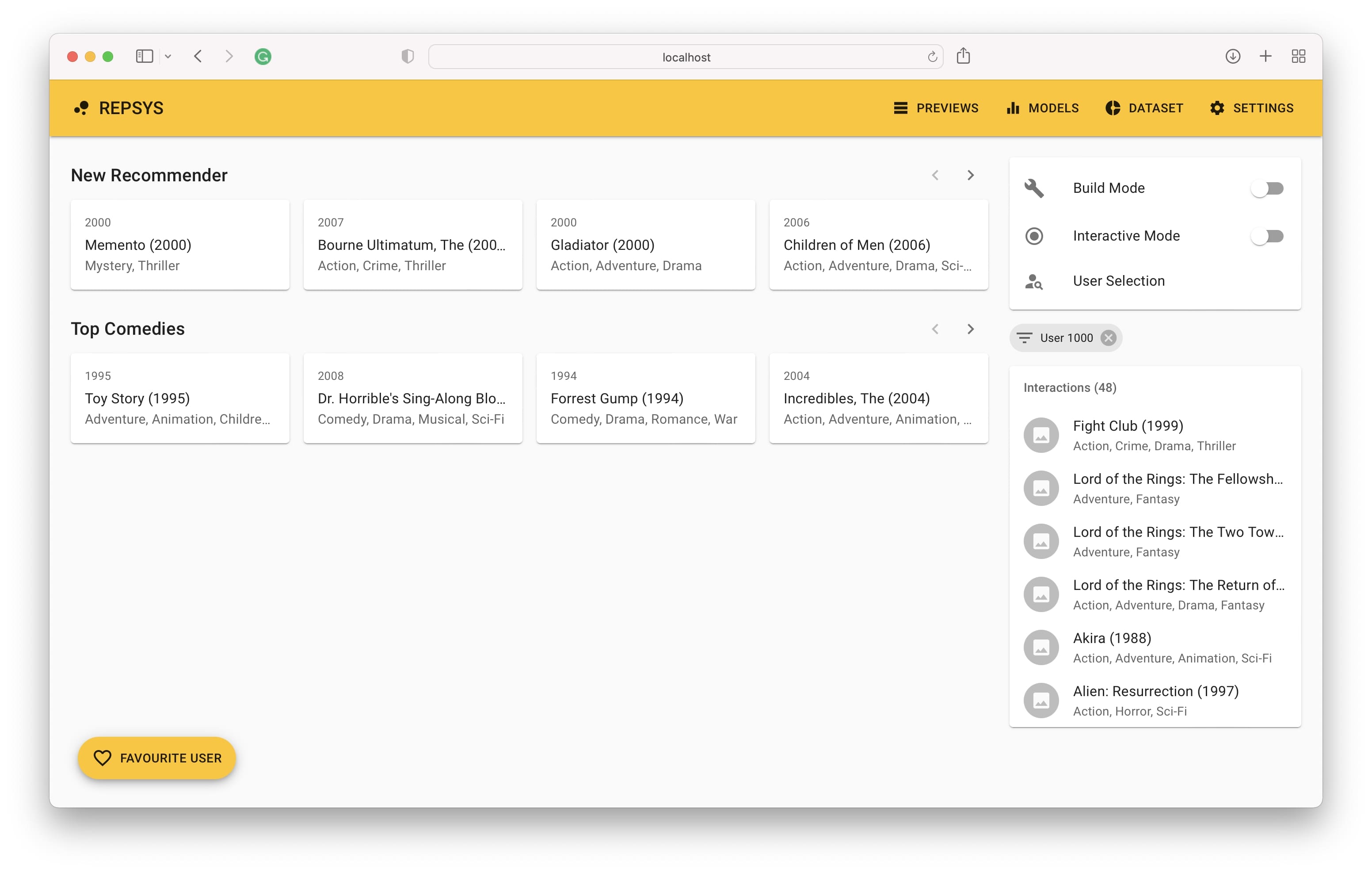
ในที่สุดเราจะเห็นประวัติการโต้ตอบของผู้ใช้ทางด้านขวาและคำแนะนำที่ทำโดยโมเดลทางด้านซ้าย
ในการสร้างแพ็คเกจจากแหล่งที่มาคุณต้องติดตั้งไลบรารี Node.js และ NPM ก่อนที่จะบันทึกไว้ที่นี่ จากนั้นคุณสามารถเรียกใช้สคริปต์ต่อไปนี้จากไดเรกทอรีรูทเพื่อสร้างเว็บแอปพลิเคชันและติดตั้งแพ็คเกจในเครื่อง
$ ./scripts/install-locally.sh
หากคุณจ้าง repsys ในงานวิจัยของคุณโปรดอย่าลืมอ้างถึงเอกสารที่เกี่ยวข้อง:
@inproceedings{10.1145/3523227.3551469,
author = {v{S}afav{r}'{i}k, Jan and Vanv{c}ura, Vojtv{e}ch and Kord'{i}k, Pavel},
title = {RepSys: Framework for Interactive Evaluation of Recommender Systems},
year = {2022},
isbn = {9781450392785},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3523227.3551469},
doi = {10.1145/3523227.3551469},
booktitle = {Proceedings of the 16th ACM Conference on Recommender Systems},
pages = {636–639},
numpages = {4},
keywords = {User simulation, Distribution analysis, Recommender systems},
location = {Seattle, WA, USA},
series = {RecSys '22}
}
การพัฒนาเฟรมเวิร์กนี้ได้รับการสนับสนุนจาก บริษัท Recombee



