repsys
1.0.0
The Repsys هو إطار لتطوير وتحليل أنظمة التوصيات ، ويسمح لك بـ:
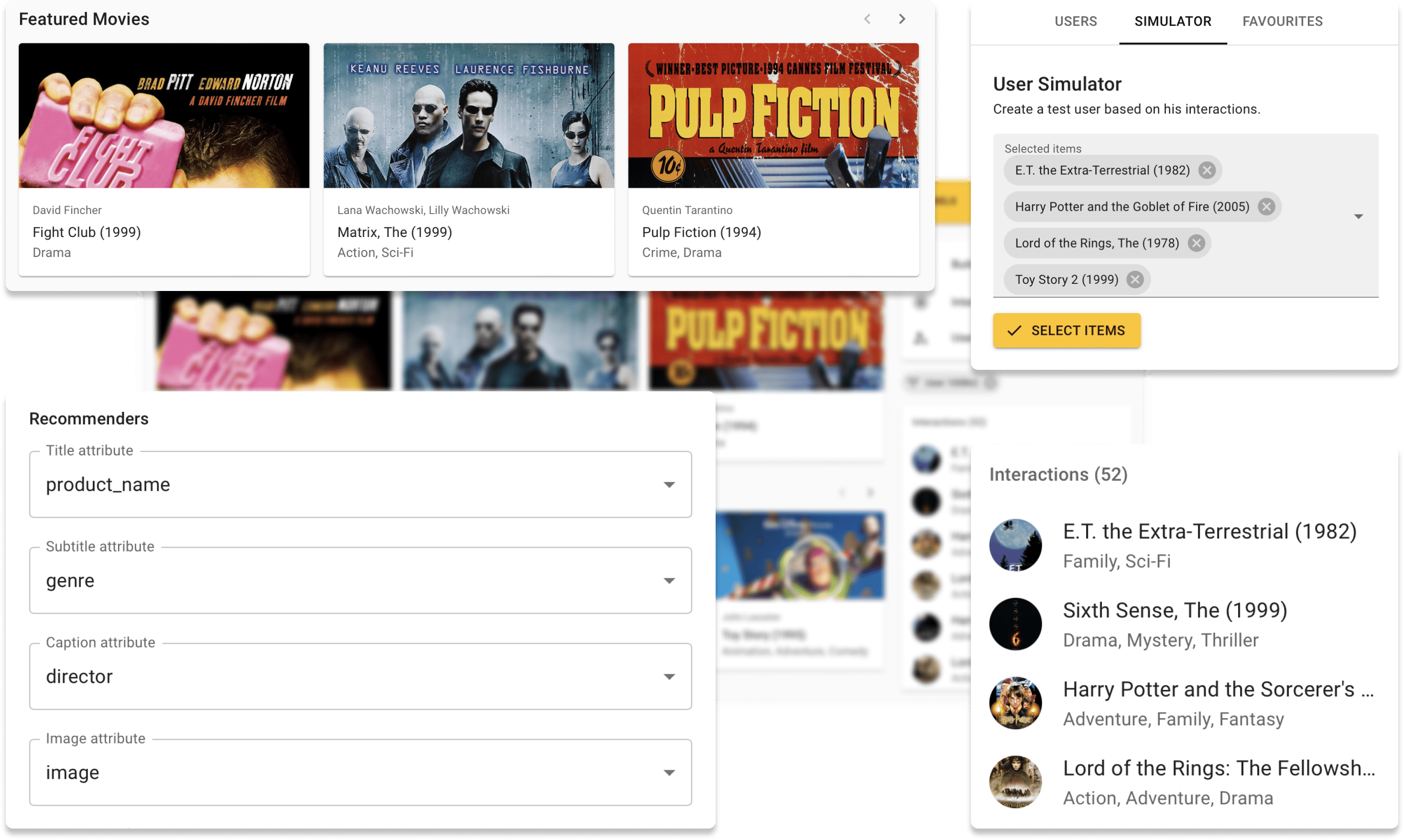
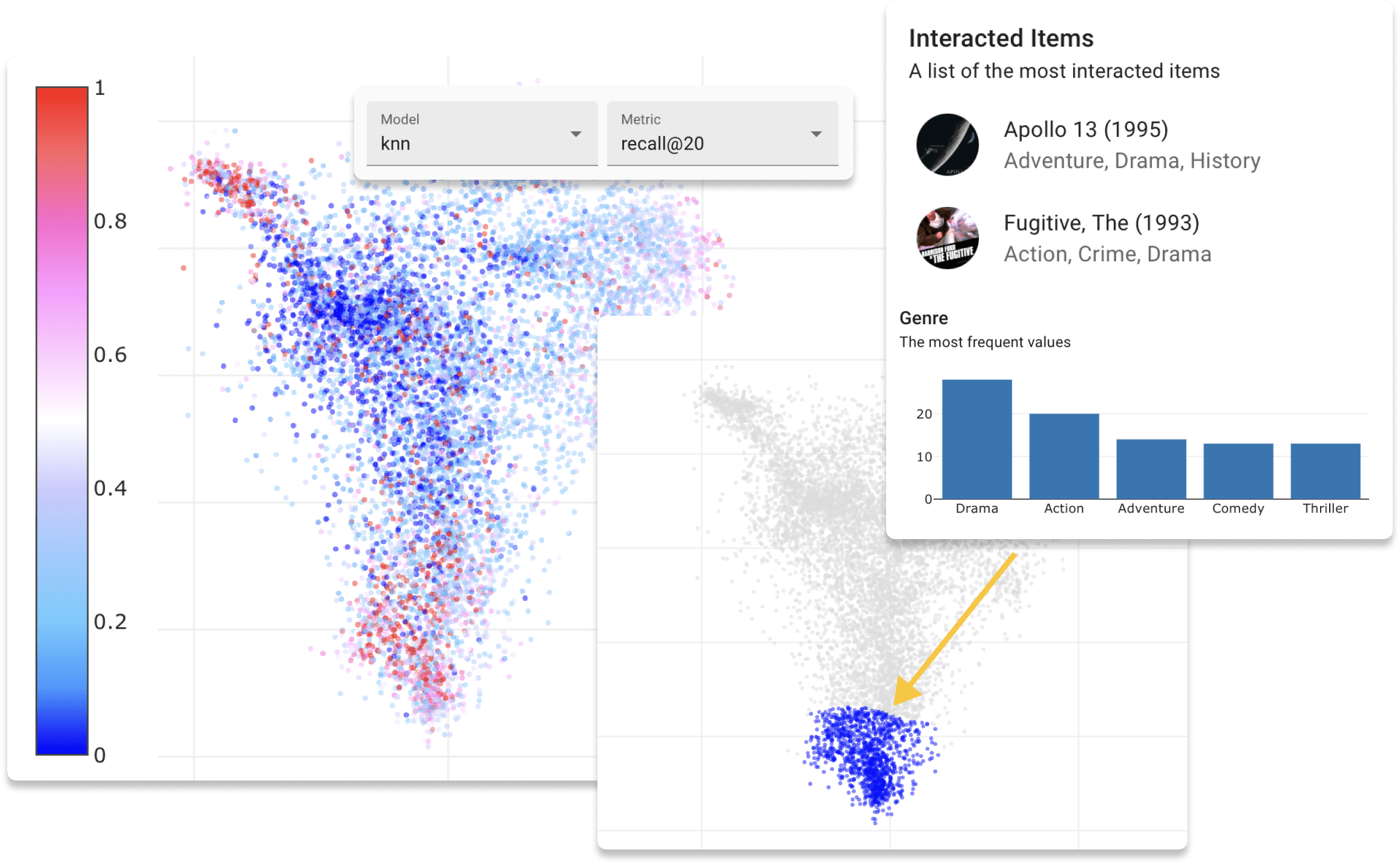

يمكنك الآن تجربة Repsys عبر الإنترنت على موقعنا التجريبي مع مجموعة بيانات Movielens. أيضًا ، تحقق من منشور مدونة تفاعلي قمنا به باستخدام مكون مصغرة Repsys.
تم قبول ورقة "Repsys: Framework للتقييم التفاعلي لأنظمة التوصية" في مؤتمر Recsys'22.
قم بتثبيت الحزمة باستخدام PIP:
$ pip install repsys-framework
إذا كنت ستستخدم pymde لتصور البيانات ، فأنت بحاجة إلى تثبيت repsys مع الإضافات التالية:
$ pip install repsys-framework[pymde]
إذا كنت ترغب في تخطي هذا البرنامج التعليمي وتجربة الإطار ، فيمكنك سحب محتوى المجلد التجريبي الموجود في المستودع. كما هو مذكور في الخطوة التالية ، لا يزال يتعين عليك تنزيل مجموعة البيانات قبل البدء.
خلاف ذلك ، يرجى إنشاء مجلد مشروع فارغ يحتوي على تطبيق مجموعة البيانات والموديلات.
├── __init__.py
├── dataset.py
├── models.py
├── repsys.ini
└── .gitignore
أولاً ، نحتاج إلى استيراد مجموعة البيانات الخاصة بنا. سوف نستخدم مجموعة بيانات Movielens 20m مع 20 مليون تصنيف من قبل 138000 مستخدم إلى 27000 فيلم لغرض البرنامج التعليمي. يرجى تنزيل ملف ml-20m.zip وفك ضغط البيانات في المجلد الحالي. ثم أضف المحتوى التالي إلى ملف dataset.py :
import pandas as pd
from repsys import Dataset
import repsys . dtypes as dtypes
class MovieLens ( Dataset ):
def name ( self ):
return "ml20m"
def item_cols ( self ):
return {
"movieId" : dtypes . ItemID (),
"title" : dtypes . Title (),
"genres" : dtypes . Tag ( sep = "|" ),
"year" : dtypes . Number ( data_type = int ),
}
def interaction_cols ( self ):
return {
"movieId" : dtypes . ItemID (),
"userId" : dtypes . UserID (),
"rating" : dtypes . Interaction (),
}
def load_items ( self ):
df = pd . read_csv ( "./ml-20m/movies.csv" )
df [ "year" ] = df [ "title" ]. str . extract ( r"((d+))" )
return df
def load_interactions ( self ):
df = pd . read_csv ( "./ml-20m/ratings.csv" )
return dfسيحدد هذا الرمز مجموعة بيانات جديدة تسمى ML20M ، وسيقوم باستيراد كل من بيانات التصنيفات والمواد. يجب عليك دائمًا تحديد بنية البيانات الخاصة بك باستخدام أنواع البيانات المحددة مسبقًا. قبل إرجاع البيانات ، يمكنك أيضًا معالجتها مسبقًا مثل استخراج عام الفيلم من عمود العنوان.
الآن نقوم بتحديد نموذج التوصية الأول ، والذي سيكون تطبيقًا بسيطًا لـ KNN المستند إلى المستخدم.
import numpy as np
import scipy . sparse as sp
from sklearn . neighbors import NearestNeighbors
from repsys import Model
class KNN ( Model ):
def __init__ ( self ):
self . model = NearestNeighbors ( n_neighbors = 20 , metric = "cosine" )
def name ( self ):
return "knn"
def fit ( self , training = False ):
X = self . dataset . get_train_data ()
self . model . fit ( X )
def predict ( self , X , ** kwargs ):
if X . count_nonzero () == 0 :
return np . random . uniform ( size = X . shape )
distances , indices = self . model . kneighbors ( X )
distances = distances [:, 1 :]
indices = indices [:, 1 :]
distances = 1 - distances
sums = distances . sum ( axis = 1 )
distances = distances / sums [:, np . newaxis ]
def f ( dist , idx ):
A = self . dataset . get_train_data ()[ idx ]
D = sp . diags ( dist )
return D . dot ( A ). sum ( axis = 0 )
vf = np . vectorize ( f , signature = "(n),(n)->(m)" )
predictions = vf ( distances , indices )
predictions [ X . nonzero ()] = 0
return predictionsيجب عليك تحديد طريقة الملاءمة لتدريب النموذج الخاص بك باستخدام بيانات التدريب أو تحميل النموذج المدربين مسبقًا من ملف. يتم تركيب جميع النماذج عند بدء تطبيق الويب ، أو تبدأ عملية التقييم. إذا لم تكن هذه مرحلة تدريب ، فاحمل دائمًا النموذج الخاص بك من نقطة تفتيش لتسريع العملية. لأغراض البرنامج التعليمي ، تم حذف هذا.
يجب عليك أيضًا تحديد طريقة التنبؤ التي تتلقى مصفوفة متناثرة من تفاعلات المستخدمين على الإدخال. لكل مستخدم (صف من المصفوفة) والعنصر (عمود المصفوفة) ، يجب أن تُرجع الطريقة إلى درجة متوقعة تشير إلى مقدار ما سيستمتع به المستخدم للعنصر.
بالإضافة إلى ذلك ، يمكنك تحديد بعض معلمات تطبيق الويب التي يمكنك تعيينها أثناء إنشاء التوصية. ثم يمكن الوصول إلى القيمة في وسيطة **kwargs لطريقة التنبؤ. في المثال ، نقوم بإنشاء إدخال محدد مع جميع الأنواع الفريدة وتصفية فقط تلك الأفلام التي لا تحتوي على النوع المحدد.
آخر ملف يجب أن ننشئه هو تكوين يسمح لك بالتحكم في عملية تقسيم البيانات ، وإعدادات الخادم ، وسلوك الإطار ، إلخ.
[general]
seed =1234
[dataset]
train_split_prop =0.85
test_holdout_prop =0.2
min_user_interacts =5
min_item_interacts =0
[evaluation]
precision_recall_k =20,50
ndcg_k =100
coverage_k =20
diversity_k =20
novelty_k =20
percentage_lt_k =20
coverage_lt_k =20
[visualization]
embed_method =pymde
pymde_neighbors =15
umap_neighbors =15
umap_min_dist =0.1
tsne_perplexity =30
[server]
port =3001قبل أن ندرب نماذجنا ، نحتاج إلى تقسيم البيانات إلى مجموعات القطار والتحقق من الصحة والاختبار. تشغيل الأمر التالي من الدليل الحالي.
$ repsys dataset split
سيحتفظ ذلك بنسبة 85 ٪ من المستخدمين كبيانات تدريب ، وسيتم استخدام الباقي بنسبة 15 ٪ كبيانات التحقق/الاختبار مع 7.5 ٪ من المستخدمين لكل منهم. بالنسبة لكل من التحقق من الصحة ومجموعة الاختبار ، سيتم أيضًا عقد 20 ٪ من التفاعلات لأغراض التقييم. سيتم تخزين مجموعة البيانات المقسمة في مجلد نقاط التفتيش الافتراضية.
الآن يمكننا الانتقال إلى عملية التدريب. للقيام بذلك ، يرجى الاتصال بالأمر التالي.
$ repsys model train
سيتصل هذا الأمر بالطريقة الملائمة لكل نموذج مع تعيين علامة التدريب إلى TRUE. يمكنك دائمًا الحد من النماذج باستخدام علامة -m باسم النموذج كمعلمة.
عند إعداد البيانات وتدريب النماذج ، يمكننا تقييم أداء النماذج على تفاعلات المستخدمين غير المرئيين. تشغيل الأمر التالي للقيام بذلك.
$ repsys model eval
مرة أخرى ، يمكنك الحد من النماذج باستخدام علامة -m . سيتم تخزين النتائج في مجلد نقاط التفتيش عند إجراء التقييم.
قبل بدء تطبيق الويب ، تتمثل الخطوة النهائية في تقييم بيانات مجموعة البيانات. سيقوم هذا الإجراء بإنشاء مستخدمين وعناصر تضمينات لبيانات التدريب والتحقق للسماح لك باستكشاف المساحة الكامنة. قم بتشغيل الأمر التالي من دليل المشروع.
$ repsys dataset eval
يمكنك الاختيار من بين ثلاثة أنواع من خوارزمية التضمينات:
--method umap (هذا هو الخيار الافتراضي).--method pymde .--method tsne .--method custom وأضف الطريقة التالية إلى فئة النموذج التي تختارها. في هذه الحالة ، يجب عليك أيضًا تحديد اسم النموذج باستخدام المعلمة -m . from sklearn . decomposition import NMF
def compute_embeddings ( self , X ):
nmf = NMF ( n_components = 2 )
W = nmf . fit_transform ( X )
H = nmf . components_
return W , H . Tفي المثال ، يتم استخدام عامل المصفوفة السلبي. يجب عليك إرجاع زوج تضمينات المستخدم والعنصر في هذا الترتيب. أيضًا ، من الضروري إعادة المصفوفات في شكل (N_Users/n_items ، N_DIM). إذا كان البعد المخفض أعلى من 2 ، يتم تطبيق طريقة TSNE.
أخيرًا ، حان الوقت لبدء تطبيق الويب لمعرفة نتائج التقييمات ومعاينة التوصيات الحية لنماذجك.
$ repsys server
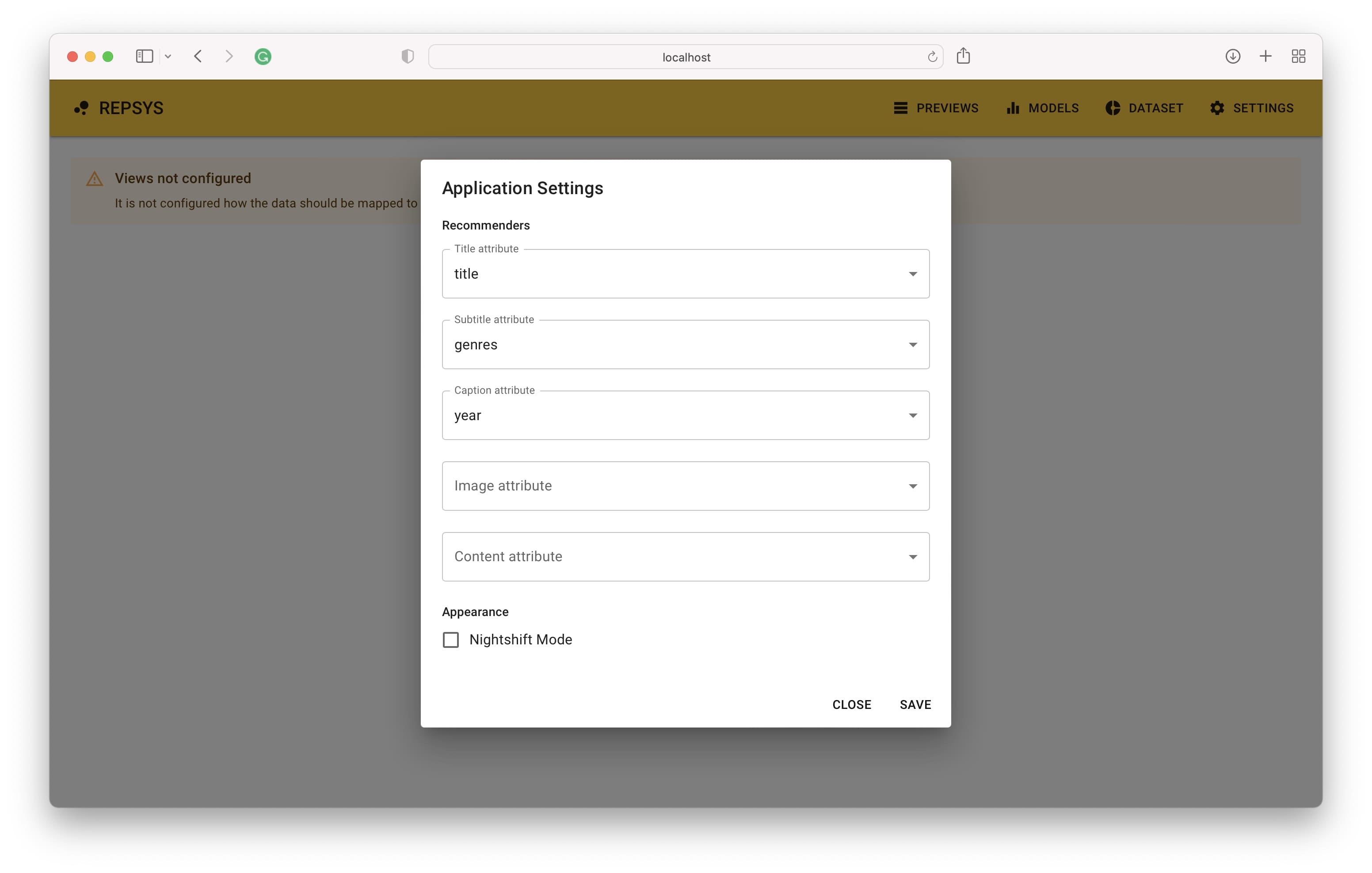
يجب الوصول إلى التطبيق على العنوان الافتراضي http: // localhost: 3001. عند فتح الرابط ، سترى الشاشة الرئيسية حيث تظهر توصياتك بمجرد الانتهاء من الإعداد. تتمثل الخطوة الأولى في تحديد كيفية تعيين أعمدة بيانات العناصر لمكونات عرض العنصر.
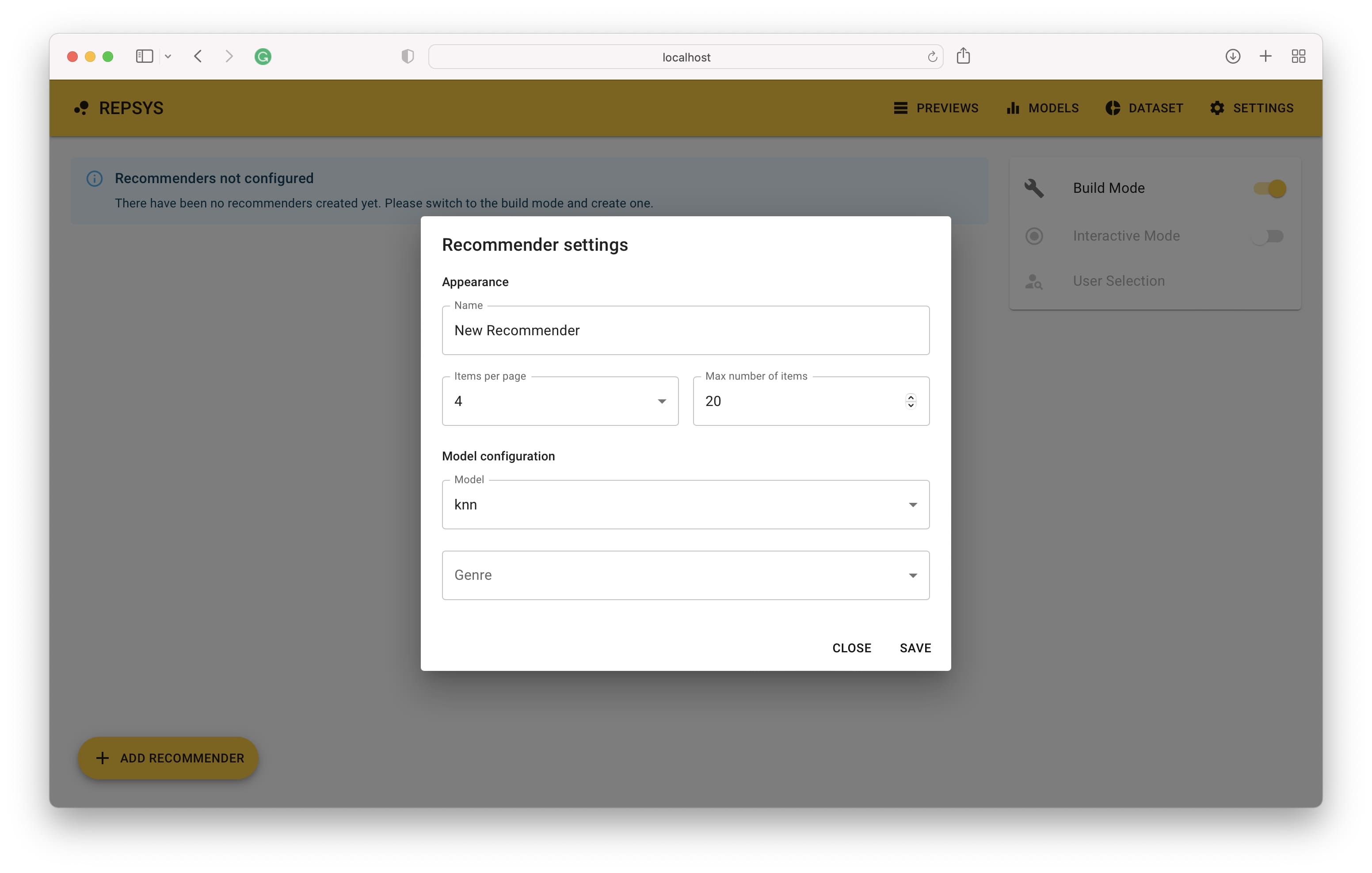
ثم نحتاج إلى التبديل إلى وضع الإنشاء وإضافة موظفين - واحد بدون مرشح والثاني مع الأفلام الكوميدية فقط.
الآن نقوم بالرجوع من وضع الإنشاء وحدد مستخدمًا من مجموعة التحقق من الصحة (لم يسبق له مثيل من قبل نموذج من قبل).
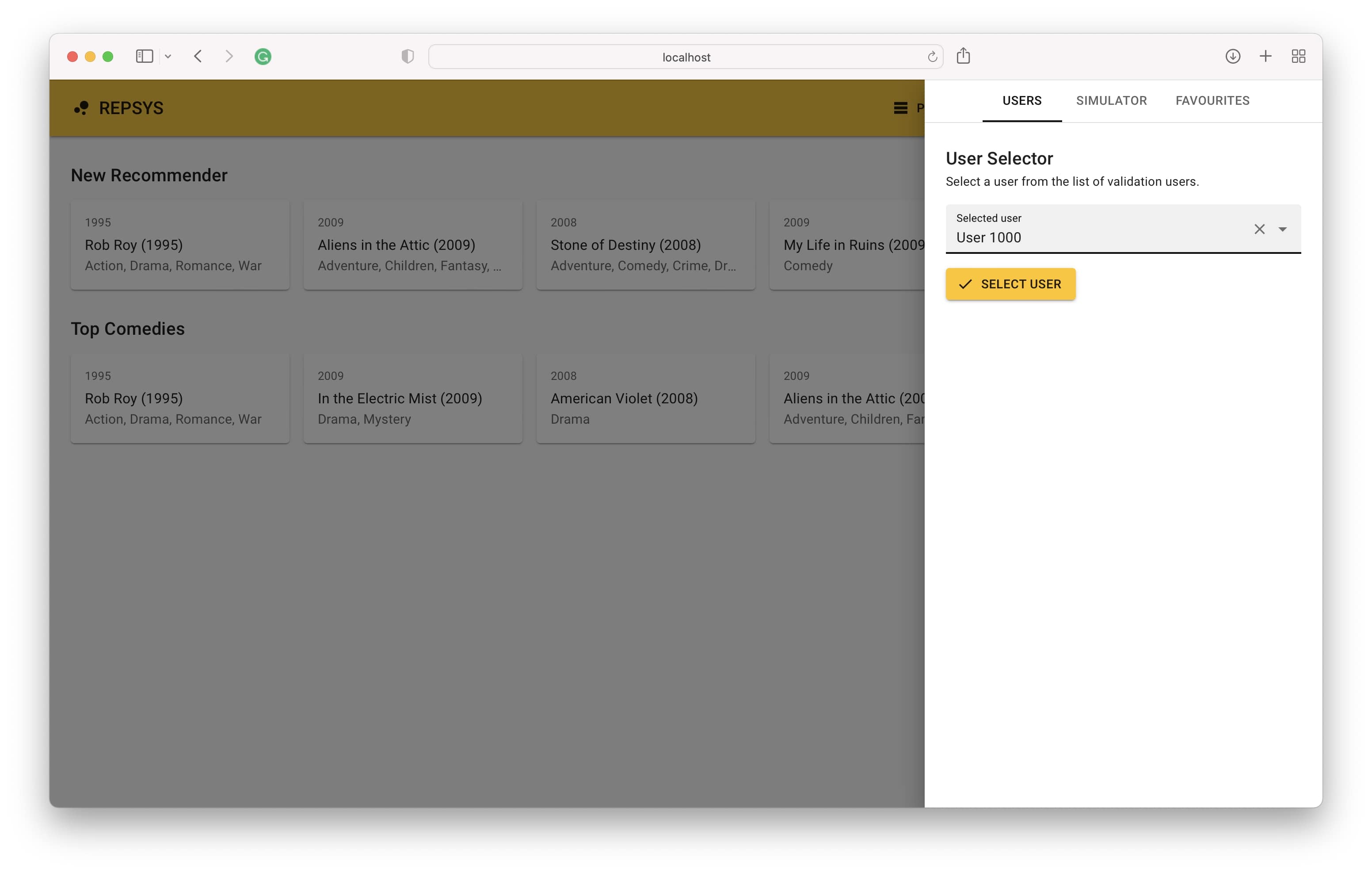
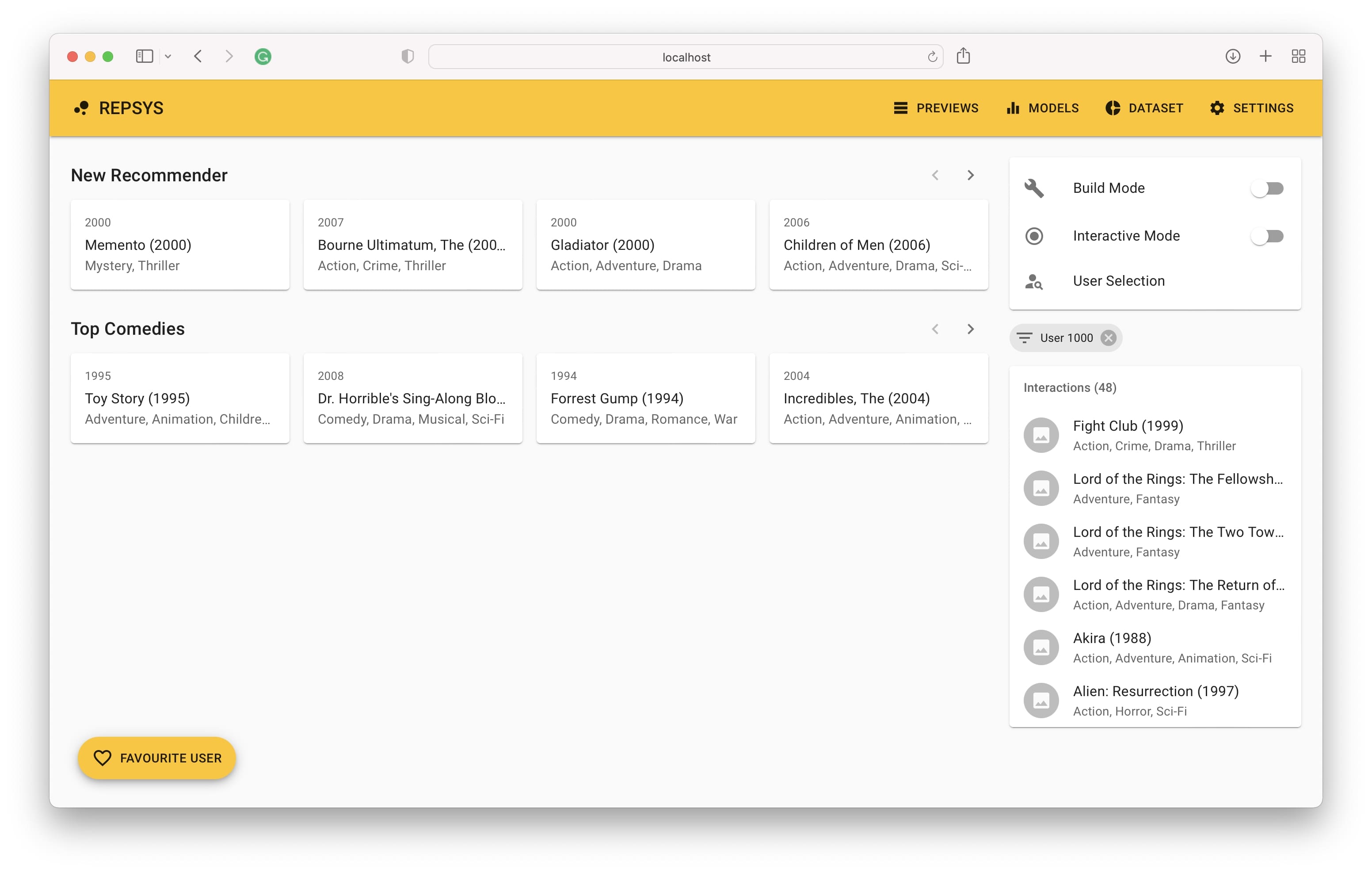
أخيرًا ، نرى تاريخ تفاعل المستخدم على الجانب الأيمن والتوصيات التي يقدمها النموذج على الجانب الأيسر.
لإنشاء الحزمة من المصدر ، تحتاج أولاً إلى تثبيت مكتبة Node.js و NPM كما هو موثق هنا. بعد ذلك ، يمكنك تشغيل البرنامج النصي التالي من دليل الجذر لإنشاء تطبيق الويب وتثبيت الحزمة محليًا.
$ ./scripts/install-locally.sh
إذا كنت توظف ممثلين في عملك البحثي ، فيرجى عدم نسيان الاستشهاد بالورقة ذات الصلة:
@inproceedings{10.1145/3523227.3551469,
author = {v{S}afav{r}'{i}k, Jan and Vanv{c}ura, Vojtv{e}ch and Kord'{i}k, Pavel},
title = {RepSys: Framework for Interactive Evaluation of Recommender Systems},
year = {2022},
isbn = {9781450392785},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3523227.3551469},
doi = {10.1145/3523227.3551469},
booktitle = {Proceedings of the 16th ACM Conference on Recommender Systems},
pages = {636–639},
numpages = {4},
keywords = {User simulation, Distribution analysis, Recommender systems},
location = {Seattle, WA, USA},
series = {RecSys '22}
}
تتم رعاية تطوير هذا الإطار من قبل شركة إعادة التركيب.



