repsys
1.0.0
Repsysは、推奨システムを開発および分析するためのフレームワークであり、次のことができます。
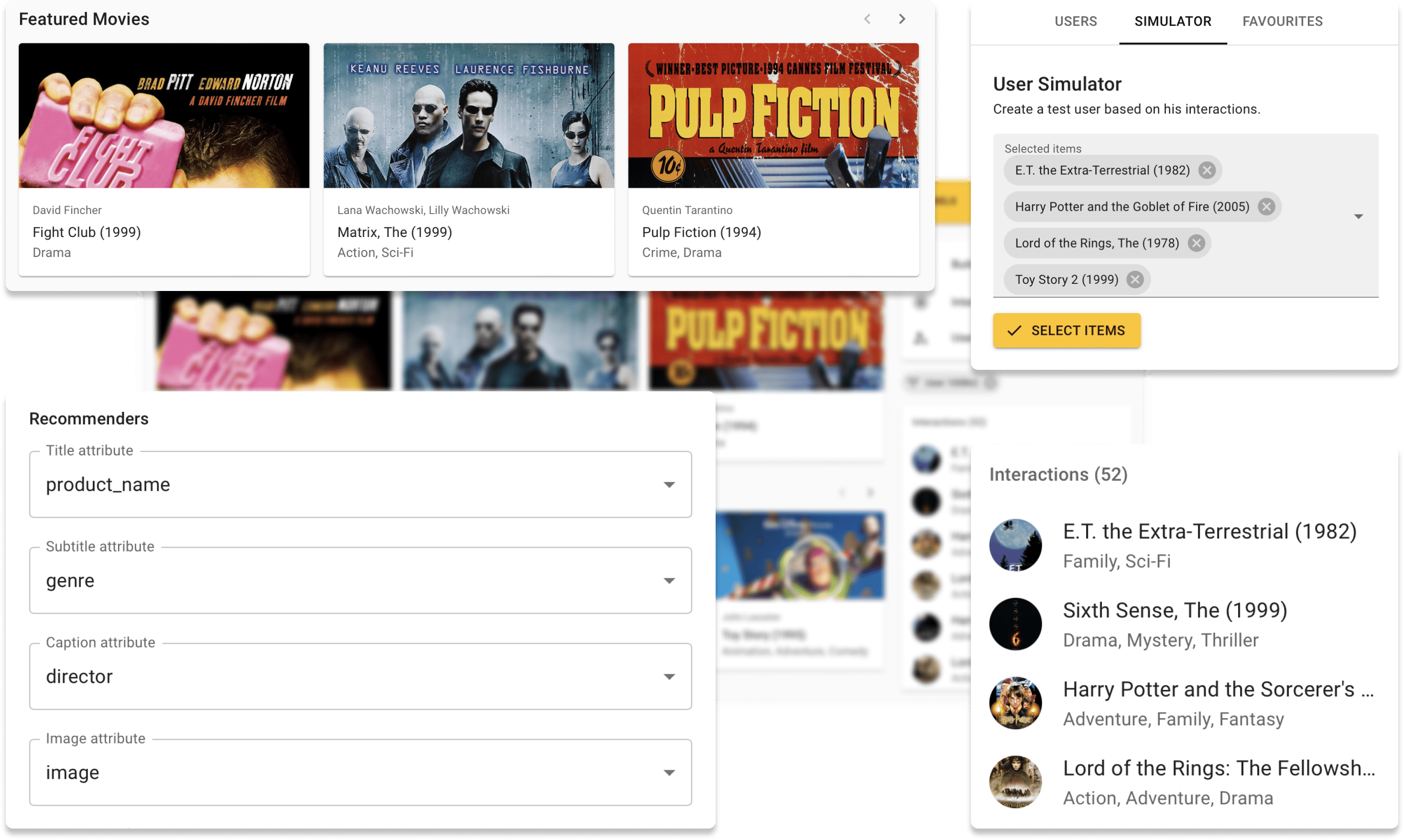

Movielensデータセットを使用して、デモサイトでRepsysをオンラインで試すことができます。また、Repsysウィジェットコンポーネントを使用して作成したインタラクティブなブログ投稿をご覧ください。
私たちの論文「担当者:推奨システムのインタラクティブ評価のためのフレームワーク」は、Recsys'22会議に受け入れられました。
PIPを使用してパッケージをインストールします。
$ pip install repsys-framework
データの視覚化にPymdeを使用する場合は、次のエキストラを使用してRepsysをインストールする必要があります。
$ pip install repsys-framework[pymde]
このチュートリアルをスキップしてフレームワークを試す場合は、リポジトリにあるデモフォルダーのコンテンツをプルできます。次のステップで述べたように、開始する前にデータセットをダウンロードする必要があります。
それ以外の場合は、データセットとモデルの実装を含む空のプロジェクトフォルダーを作成してください。
├── __init__.py
├── dataset.py
├── models.py
├── repsys.ini
└── .gitignore
まず、データセットをインポートする必要があります。チュートリアルの目的で、138,000人のユーザーが27,000枚の映画から2,000万人の評価を得て、Movielens 20mデータセットを使用します。 ml-20m.zipファイルをダウンロードして、データを現在のフォルダーに解凍してください。次に、次のコンテンツをdataset.pyファイルに追加します。
import pandas as pd
from repsys import Dataset
import repsys . dtypes as dtypes
class MovieLens ( Dataset ):
def name ( self ):
return "ml20m"
def item_cols ( self ):
return {
"movieId" : dtypes . ItemID (),
"title" : dtypes . Title (),
"genres" : dtypes . Tag ( sep = "|" ),
"year" : dtypes . Number ( data_type = int ),
}
def interaction_cols ( self ):
return {
"movieId" : dtypes . ItemID (),
"userId" : dtypes . UserID (),
"rating" : dtypes . Interaction (),
}
def load_items ( self ):
df = pd . read_csv ( "./ml-20m/movies.csv" )
df [ "year" ] = df [ "title" ]. str . extract ( r"((d+))" )
return df
def load_interactions ( self ):
df = pd . read_csv ( "./ml-20m/ratings.csv" )
return dfこのコードは、ML20Mと呼ばれる新しいデータセットを定義し、評価とアイテムの両方のデータをインポートします。事前定義されたデータ型を使用して、常にデータ構造を指定する必要があります。データを返す前に、タイトルコラムから映画の年を抽出するように前処理することもできます。
次に、最初の推奨モデルを定義します。これは、ユーザーベースのKNNの簡単な実装となります。
import numpy as np
import scipy . sparse as sp
from sklearn . neighbors import NearestNeighbors
from repsys import Model
class KNN ( Model ):
def __init__ ( self ):
self . model = NearestNeighbors ( n_neighbors = 20 , metric = "cosine" )
def name ( self ):
return "knn"
def fit ( self , training = False ):
X = self . dataset . get_train_data ()
self . model . fit ( X )
def predict ( self , X , ** kwargs ):
if X . count_nonzero () == 0 :
return np . random . uniform ( size = X . shape )
distances , indices = self . model . kneighbors ( X )
distances = distances [:, 1 :]
indices = indices [:, 1 :]
distances = 1 - distances
sums = distances . sum ( axis = 1 )
distances = distances / sums [:, np . newaxis ]
def f ( dist , idx ):
A = self . dataset . get_train_data ()[ idx ]
D = sp . diags ( dist )
return D . dot ( A ). sum ( axis = 0 )
vf = np . vectorize ( f , signature = "(n),(n)->(m)" )
predictions = vf ( distances , indices )
predictions [ X . nonzero ()] = 0
return predictionsトレーニングデータを使用してモデルをトレーニングするFITメソッドを定義するか、ファイルから以前にトレーニングしたモデルをロードする必要があります。すべてのモデルは、Webアプリケーションが開始されるとき、または評価プロセスが開始されるときに取り付けられます。これがトレーニングフェーズではない場合は、常にチェックポイントからモデルをロードしてプロセスを高速化してください。チュートリアルのために、これは省略されています。
また、入力上のユーザーの相互作用のまばらなマトリックスを受信する予測方法を定義する必要があります。各ユーザー(マトリックスの行)とアイテム(マトリックスの列)について、メソッドは、ユーザーがアイテムをどれだけ享受するかを示す予測スコアを返す必要があります。
さらに、推奨作成中に設定できるWebアプリケーションパラメーターを指定できます。値は、予測法の**kwargs引数でアクセスできます。この例では、すべてのユニークなジャンルを使用して選択された入力を作成し、選択したジャンルを含まない映画のみを除外します。
最後に作成する必要があるファイルは、データ分割プロセス、サーバー設定、フレームワークの動作などを制御できる構成です。
[general]
seed =1234
[dataset]
train_split_prop =0.85
test_holdout_prop =0.2
min_user_interacts =5
min_item_interacts =0
[evaluation]
precision_recall_k =20,50
ndcg_k =100
coverage_k =20
diversity_k =20
novelty_k =20
percentage_lt_k =20
coverage_lt_k =20
[visualization]
embed_method =pymde
pymde_neighbors =15
umap_neighbors =15
umap_min_dist =0.1
tsne_perplexity =30
[server]
port =3001モデルをトレーニングする前に、データをトレーニング、検証、およびテストセットに分割する必要があります。現在のディレクトリから次のコマンドを実行します。
$ repsys dataset split
これにより、ユーザーの85%がトレーニングデータとして保持され、残りの15%はそれぞれ7.5%の検証/テストデータとして使用されます。検証とテストセットの両方で、相互作用の20%も評価のために保留されます。分割データセットは、デフォルトのチェックポイントフォルダーに保存されます。
これで、トレーニングプロセスに移行できます。これを行うには、次のコマンドに電話してください。
$ repsys model train
このコマンドは、トレーニングフラグをtrueに設定して、各モデルの適合方法を呼び出します。パラメーターとしてモデルの名前を持つ-mフラグを使用して、常にモデルを制限できます。
データが準備され、モデルがトレーニングされたら、目に見えないユーザーのインタラクションのモデルのパフォーマンスを評価できます。次のコマンドを実行してください。
$ repsys model eval
繰り返しますが、 -mフラグを使用してモデルを制限できます。結果は、評価が完了すると、チェックポイントフォルダーに保存されます。
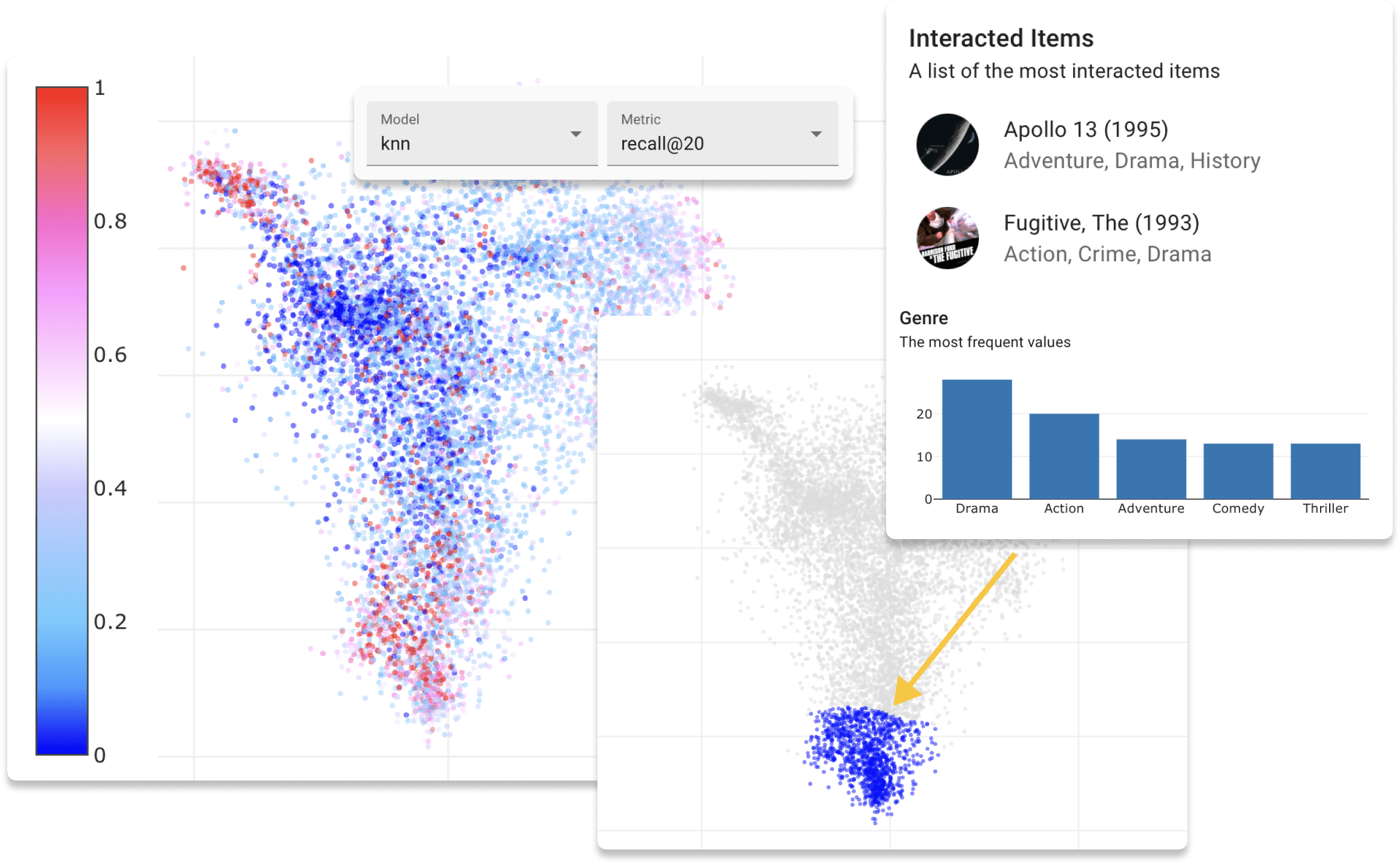
Webアプリケーションを開始する前に、最後のステップはデータセットのデータを評価することです。この手順により、トレーニングデータと検証データのユーザーとアイテムの組み込みが作成され、潜在スペースを探索できます。プロジェクトディレクトリから次のコマンドを実行します。
$ repsys dataset eval
3種類の埋め込みアルゴリズムから選択できます。
--method umap (これはデフォルトオプションです)。--method pymde使用します。--method tsne 。--method customを使用して、次の方法をモデルの選択したクラスに追加します。この場合、 -mパラメーターを使用してモデルの名前を指定する必要があります。 from sklearn . decomposition import NMF
def compute_embeddings ( self , X ):
nmf = NMF ( n_components = 2 )
W = nmf . fit_transform ( X )
H = nmf . components_
return W , H . Tこの例では、負のマトリックス因子化が使用されます。この順序でユーザーとアイテムの埋め込みペアを返す必要があります。また、(n_users/n_items、n_dim)の形で行列を返すことが不可欠です。縮小寸法が2より高い場合、TSNEメソッドが適用されます。
最後に、Webアプリケーションを開始して、評価の結果を確認し、モデルのライブ推奨事項をプレビューする時が来ました。
$ repsys server
アプリケーションは、デフォルトのアドレスhttp:// localhost:3001でアクセスできるようにする必要があります。リンクを開くと、セットアップが終了したら推奨事項が表示されるメイン画面が表示されます。最初のステップは、アイテムのデータ列をアイテムビューコンポーネントにマッピングする方法を定義することです。
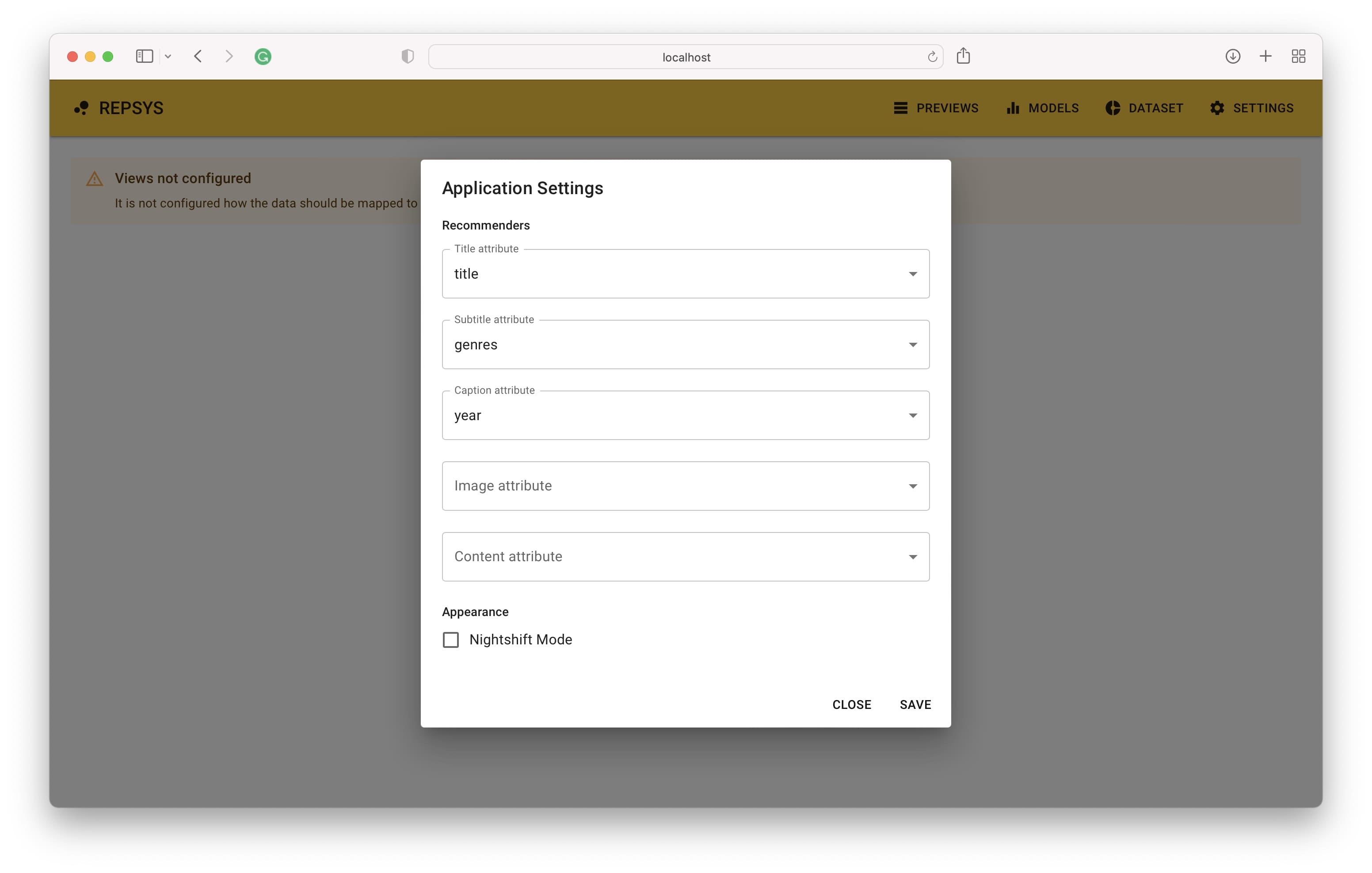
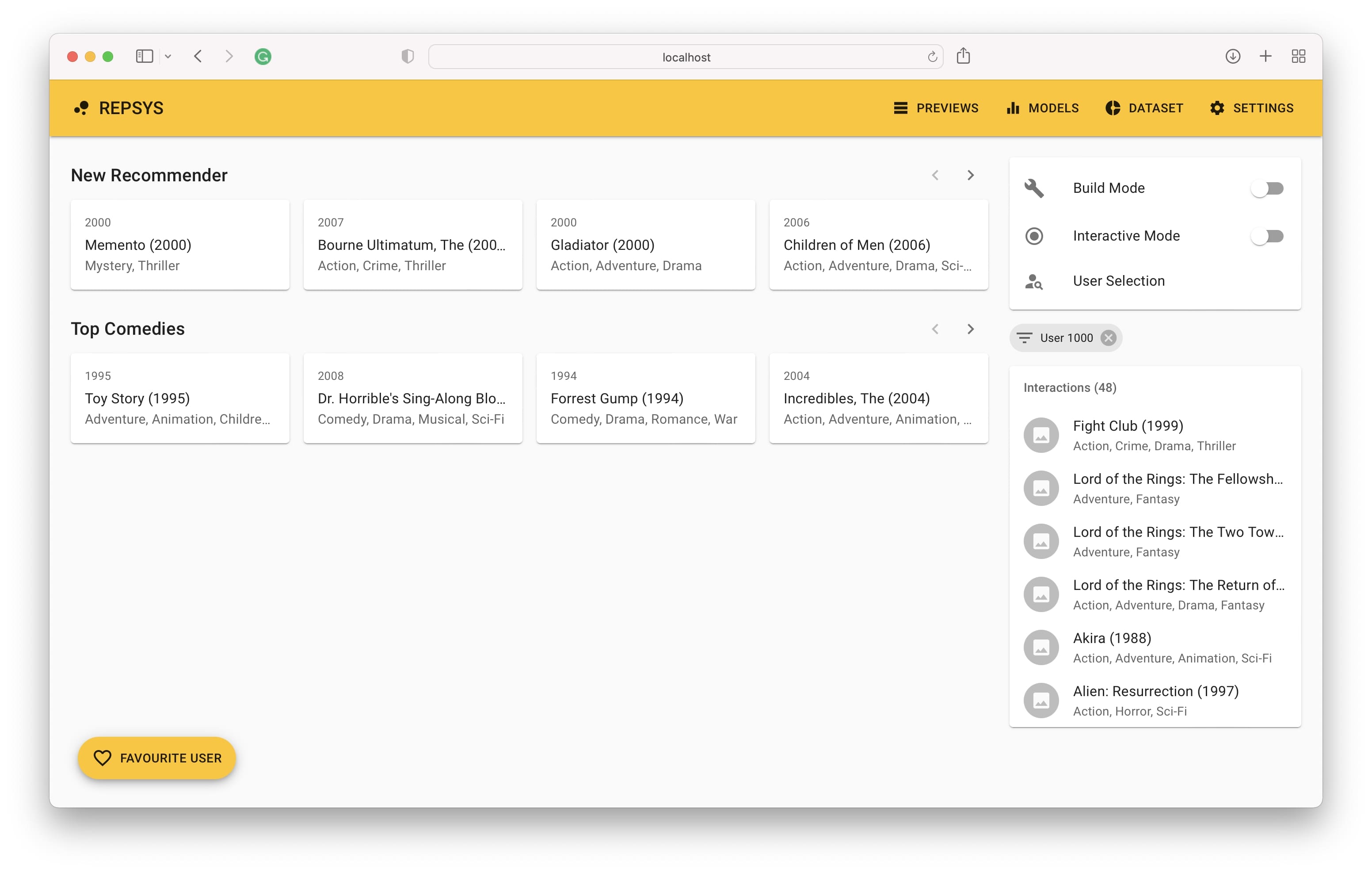
次に、ビルドモードに切り替えて、1つはフィルターなしで、コメディ映画のみが含まれている2つの推奨事項を追加する必要があります。
![[推奨]を追加します](https://images.downcodes.com/uploads/20250708/img_686c66c5d52ea34.png)
次に、ビルドモードから戻り、検証セットからユーザーを選択します(以前にモデルで見たことはありません)。
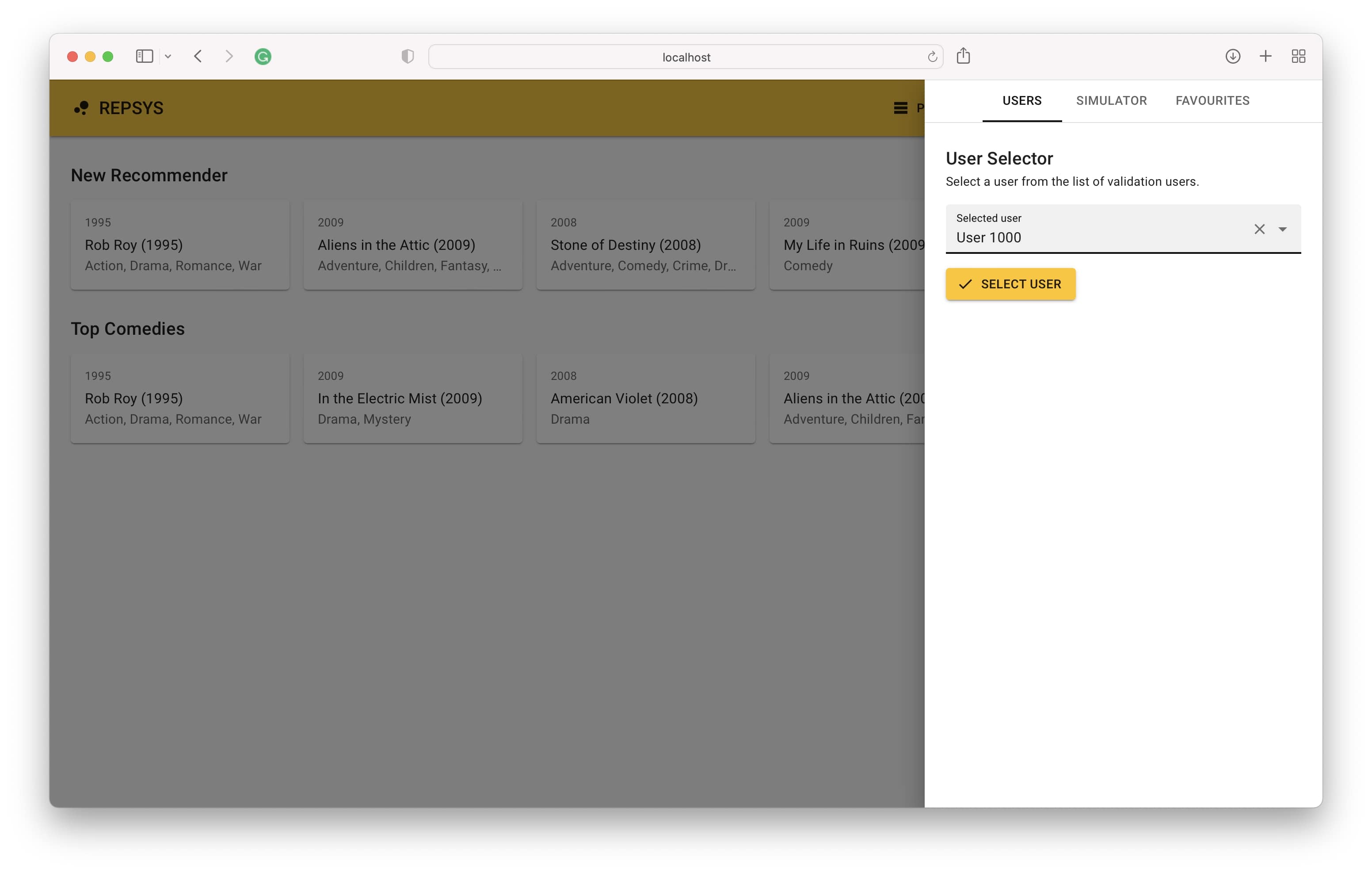
最後に、右側にユーザーの相互作用履歴と、左側のモデルによって行われた推奨事項が表示されます。
ソースからパッケージを構築するには、まずここに文書化されているようにnode.jsとnpmライブラリをインストールする必要があります。次に、ルートディレクトリから次のスクリプトを実行して、Webアプリケーションを構築し、パッケージをローカルにインストールできます。
$ ./scripts/install-locally.sh
研究作業で担当者を採用している場合は、関連する論文を引用することを忘れないでください。
@inproceedings{10.1145/3523227.3551469,
author = {v{S}afav{r}'{i}k, Jan and Vanv{c}ura, Vojtv{e}ch and Kord'{i}k, Pavel},
title = {RepSys: Framework for Interactive Evaluation of Recommender Systems},
year = {2022},
isbn = {9781450392785},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3523227.3551469},
doi = {10.1145/3523227.3551469},
booktitle = {Proceedings of the 16th ACM Conference on Recommender Systems},
pages = {636–639},
numpages = {4},
keywords = {User simulation, Distribution analysis, Recommender systems},
location = {Seattle, WA, USA},
series = {RecSys '22}
}
このフレームワークの開発は、Recombee Companyが後援しています。



