repsys
1.0.0
Die Repsys ist ein Rahmen für die Entwicklung und Analyse von Empfehlungssystemen und ermöglicht es Ihnen:
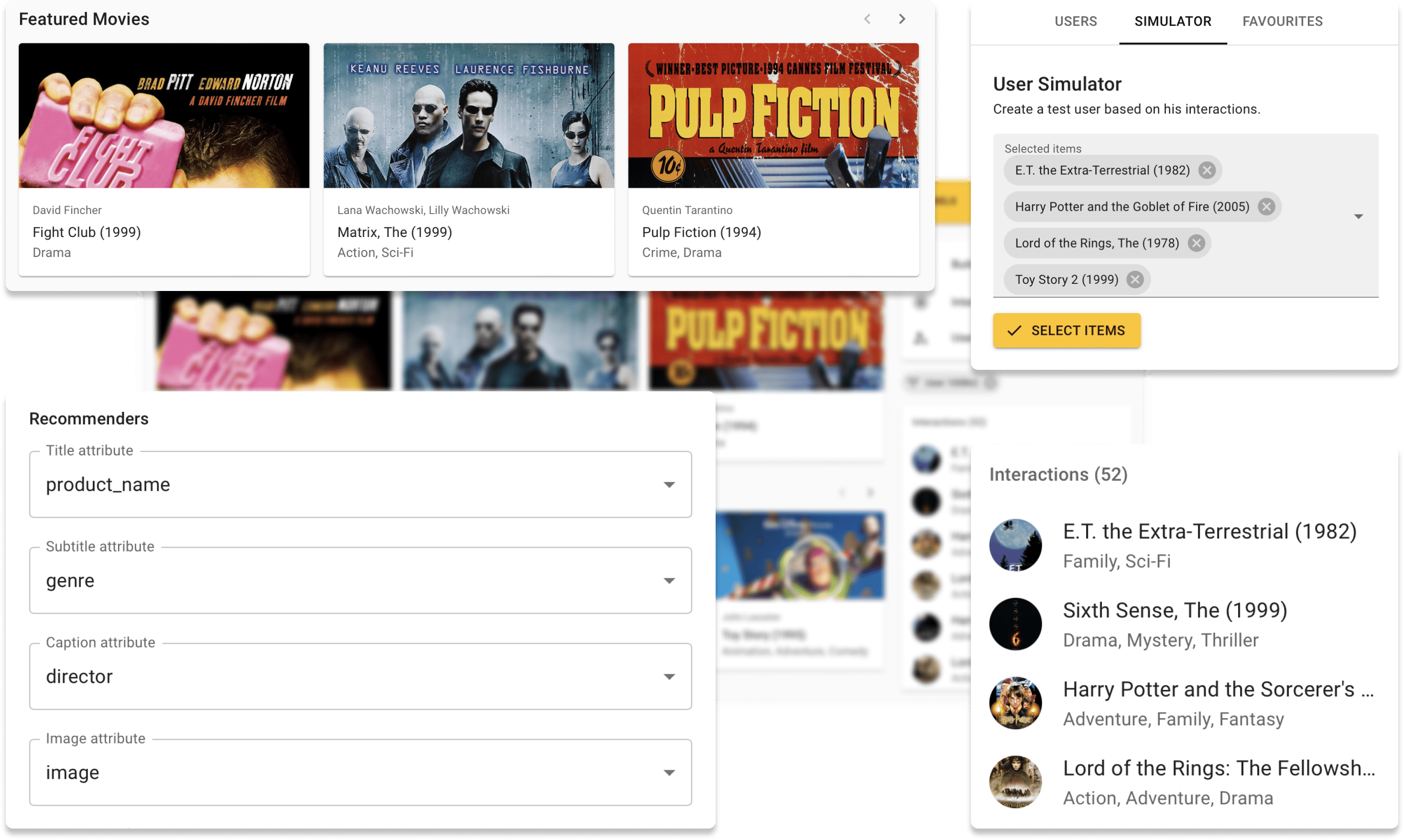
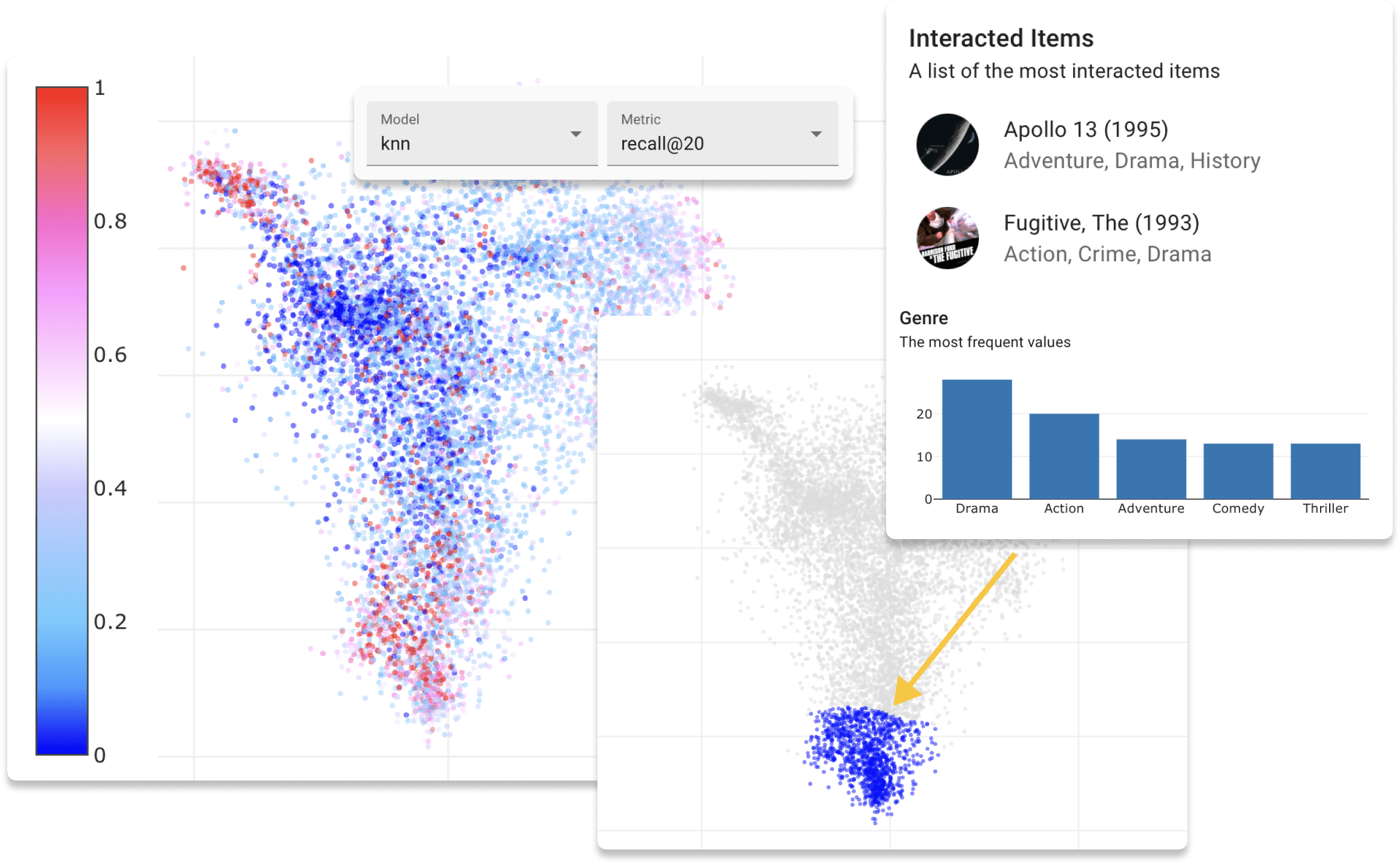

Sie können jetzt Repsys online auf unserer Demo -Website mit dem Movielens -Datensatz ausprobieren. Schauen Sie sich auch einen interaktiven Blog -Beitrag an, den wir mit der Repsys -Widgets -Komponente erstellt haben.
Unser Papier "Repsys: Framework für die interaktive Bewertung von Empfehlungssystemen" wurde auf der Recsys'22 -Konferenz akzeptiert.
Installieren Sie das Paket mit PIP:
$ pip install repsys-framework
Wenn Sie Pymde für die Datenvisualisierung verwenden, müssen Sie Repsys mit den folgenden Extras installieren:
$ pip install repsys-framework[pymde]
Wenn Sie dieses Tutorial überspringen und das Framework ausprobieren möchten, können Sie den Inhalt des Demo -Ordners im Repository ziehen. Wie im nächsten Schritt erwähnt, müssen Sie den Datensatz noch herunterladen, bevor Sie beginnen.
Andernfalls erstellen Sie bitte einen leeren Projektordner, der die Implementierung des Datensatzes und der Modelle enthält.
├── __init__.py
├── dataset.py
├── models.py
├── repsys.ini
└── .gitignore
Zunächst müssen wir unseren Datensatz importieren. Wir werden den 20 -m -Datensatz von Movielens mit 20 Millionen Bewertungen von 138.000 Benutzern zu 27.000 Filmen für den Tutorial -Zweck verwenden. Bitte laden Sie die ml-20m.zip Datei herunter und entpacken Sie die Daten in den aktuellen Ordner. Fügen Sie dann den folgenden Inhalt der Datei dataset.py hinzu:
import pandas as pd
from repsys import Dataset
import repsys . dtypes as dtypes
class MovieLens ( Dataset ):
def name ( self ):
return "ml20m"
def item_cols ( self ):
return {
"movieId" : dtypes . ItemID (),
"title" : dtypes . Title (),
"genres" : dtypes . Tag ( sep = "|" ),
"year" : dtypes . Number ( data_type = int ),
}
def interaction_cols ( self ):
return {
"movieId" : dtypes . ItemID (),
"userId" : dtypes . UserID (),
"rating" : dtypes . Interaction (),
}
def load_items ( self ):
df = pd . read_csv ( "./ml-20m/movies.csv" )
df [ "year" ] = df [ "title" ]. str . extract ( r"((d+))" )
return df
def load_interactions ( self ):
df = pd . read_csv ( "./ml-20m/ratings.csv" )
return dfDieser Code definiert einen neuen Datensatz namens ML20M und importiert sowohl Bewertungen als auch Elemente. Sie müssen Ihre Datenstruktur immer mit vordefinierten Datentypen angeben. Bevor Sie die Daten zurückgeben, können Sie sie auch wie das Extrahieren des Filmjahres aus der Title -Spalte vorab zusammenarbeiten.
Jetzt definieren wir das erste Empfehlungsmodell, das eine einfache Implementierung des benutzerbasierten KNN sein wird.
import numpy as np
import scipy . sparse as sp
from sklearn . neighbors import NearestNeighbors
from repsys import Model
class KNN ( Model ):
def __init__ ( self ):
self . model = NearestNeighbors ( n_neighbors = 20 , metric = "cosine" )
def name ( self ):
return "knn"
def fit ( self , training = False ):
X = self . dataset . get_train_data ()
self . model . fit ( X )
def predict ( self , X , ** kwargs ):
if X . count_nonzero () == 0 :
return np . random . uniform ( size = X . shape )
distances , indices = self . model . kneighbors ( X )
distances = distances [:, 1 :]
indices = indices [:, 1 :]
distances = 1 - distances
sums = distances . sum ( axis = 1 )
distances = distances / sums [:, np . newaxis ]
def f ( dist , idx ):
A = self . dataset . get_train_data ()[ idx ]
D = sp . diags ( dist )
return D . dot ( A ). sum ( axis = 0 )
vf = np . vectorize ( f , signature = "(n),(n)->(m)" )
predictions = vf ( distances , indices )
predictions [ X . nonzero ()] = 0
return predictionsSie müssen die Anpassungsmethode definieren, um Ihr Modell mithilfe der Trainingsdaten zu trainieren oder das zuvor geschulte Modell aus einer Datei zu laden. Alle Modelle werden angepasst, wenn die Webanwendung startet oder der Bewertungsprozess beginnt. Wenn dies keine Trainingsphase ist, laden Sie Ihr Modell immer von einem Kontrollpunkt, um den Prozess zu beschleunigen. Für Tutorialzwecke wird dies weggelassen.
Sie müssen auch die Vorhersagemethode definieren, die eine spärliche Matrix der Interaktionen der Benutzer in der Eingabe empfängt. Für jeden Benutzer (Zeile der Matrix) und des Elements (Spalte der Matrix) sollte die Methode eine vorhergesagte Punktzahl zurückgeben, die angibt, wie sehr der Benutzer das Element genießen wird.
Darüber hinaus können Sie einige Webanwendungsparameter angeben, die Sie während der Erstellung von Empfehlungen festlegen können. Der Wert ist dann im Argument **kwargs der Vorhersagemethode zugänglich. Im Beispiel erstellen wir eine ausgewählte Eingabe mit allen eindeutigen Genres und filtern nur diejenigen Filme heraus, die das ausgewählte Genre nicht enthalten.
Die letzte Datei, die wir erstellen sollten, ist eine Konfiguration, mit der Sie einen Datenspaltenprozess, Servereinstellungen, Framework -Verhalten usw. steuern können.
[general]
seed =1234
[dataset]
train_split_prop =0.85
test_holdout_prop =0.2
min_user_interacts =5
min_item_interacts =0
[evaluation]
precision_recall_k =20,50
ndcg_k =100
coverage_k =20
diversity_k =20
novelty_k =20
percentage_lt_k =20
coverage_lt_k =20
[visualization]
embed_method =pymde
pymde_neighbors =15
umap_neighbors =15
umap_min_dist =0.1
tsne_perplexity =30
[server]
port =3001Bevor wir unsere Modelle trainieren, müssen wir die Daten in Zug-, Validierungs- und Testsätze aufteilen. Führen Sie den folgenden Befehl aus dem aktuellen Verzeichnis aus.
$ repsys dataset split
Dadurch wird 85% der Benutzer als Trainingsdaten festgehalten, und die restlichen 15% werden als Validierungs-/Testdaten mit jeweils 7,5% der Benutzer verwendet. Sowohl für die Validierung als auch für den Testsatz werden auch 20% der Wechselwirkungen für Bewertungszwecke ausgehalten. Der geteilte Datensatz wird im Ordner Standard -Checkpoints gespeichert.
Jetzt können wir zum Trainingsprozess übergehen. Rufen Sie dazu den folgenden Befehl an.
$ repsys model train
Dieser Befehl nennt die Anpassungsmethode jedes Modells mit dem auf True festgelegten Trainingsflag. Sie können die Modelle jederzeit mit dem Flag -m mit dem Namen des Modells als Parameter einschränken.
Wenn die Daten erstellt und die Modelle trainiert werden, können wir die Leistung der Modelle in den Interaktionen der unsichtbaren Benutzer bewerten. Führen Sie dazu den folgenden Befehl aus.
$ repsys model eval
Auch hier können Sie die Modelle mit dem -m -Flag einschränken. Die Ergebnisse werden im Ordner der Checkpoints gespeichert, wenn die Bewertung durchgeführt wird.
Vor Beginn der Webanwendung besteht der letzte Schritt darin, die Daten des Datensatzes zu bewerten. In diesem Verfahren werden Benutzer und Elemente eingebettet, die die Schulungs- und Validierungsdaten einbetten, damit Sie den latenten Raum untersuchen können. Führen Sie den folgenden Befehl aus dem Projektverzeichnis aus.
$ repsys dataset eval
Sie können aus drei Arten von Einbettungsalgorithmus wählen:
--method umap (dies ist die Standardoption).--method pymde .--method tsne .--method custom und fügen Sie die folgende Methode zur Klasse Ihrer Wahl hinzu. In diesem Fall müssen Sie auch den Namen des Modells mit -m -Parameter angeben. from sklearn . decomposition import NMF
def compute_embeddings ( self , X ):
nmf = NMF ( n_components = 2 )
W = nmf . fit_transform ( X )
H = nmf . components_
return W , H . TIm Beispiel wird die negative Matrixfaktorisierung verwendet. Sie müssen ein Benutzer- und Element -Einbettungspaar in dieser Reihenfolge zurückgeben. Außerdem ist es wichtig, die Matrizen in Form von (n_users/n_items, n_dim) zurückzugeben. Wenn die reduzierte Dimension höher als 2 ist, wird die TSNE -Methode angewendet.
Schließlich ist es Zeit, die Webanwendung zu starten, um die Ergebnisse der Bewertungen und die Vorschau -Live -Empfehlungen Ihrer Modelle anzuzeigen.
$ repsys server
Die Anwendung sollte unter der Standardadresse http: // localhost: 3001 zugänglich sein. Wenn Sie den Link öffnen, sehen Sie den Hauptbildschirm, in dem Ihre Empfehlungen angezeigt werden, sobald Sie das Setup beendet haben. Der erste Schritt besteht darin, zu definieren, wie die Datenspalten der Elemente auf die Elementansichtskomponenten abgebildet werden sollten.
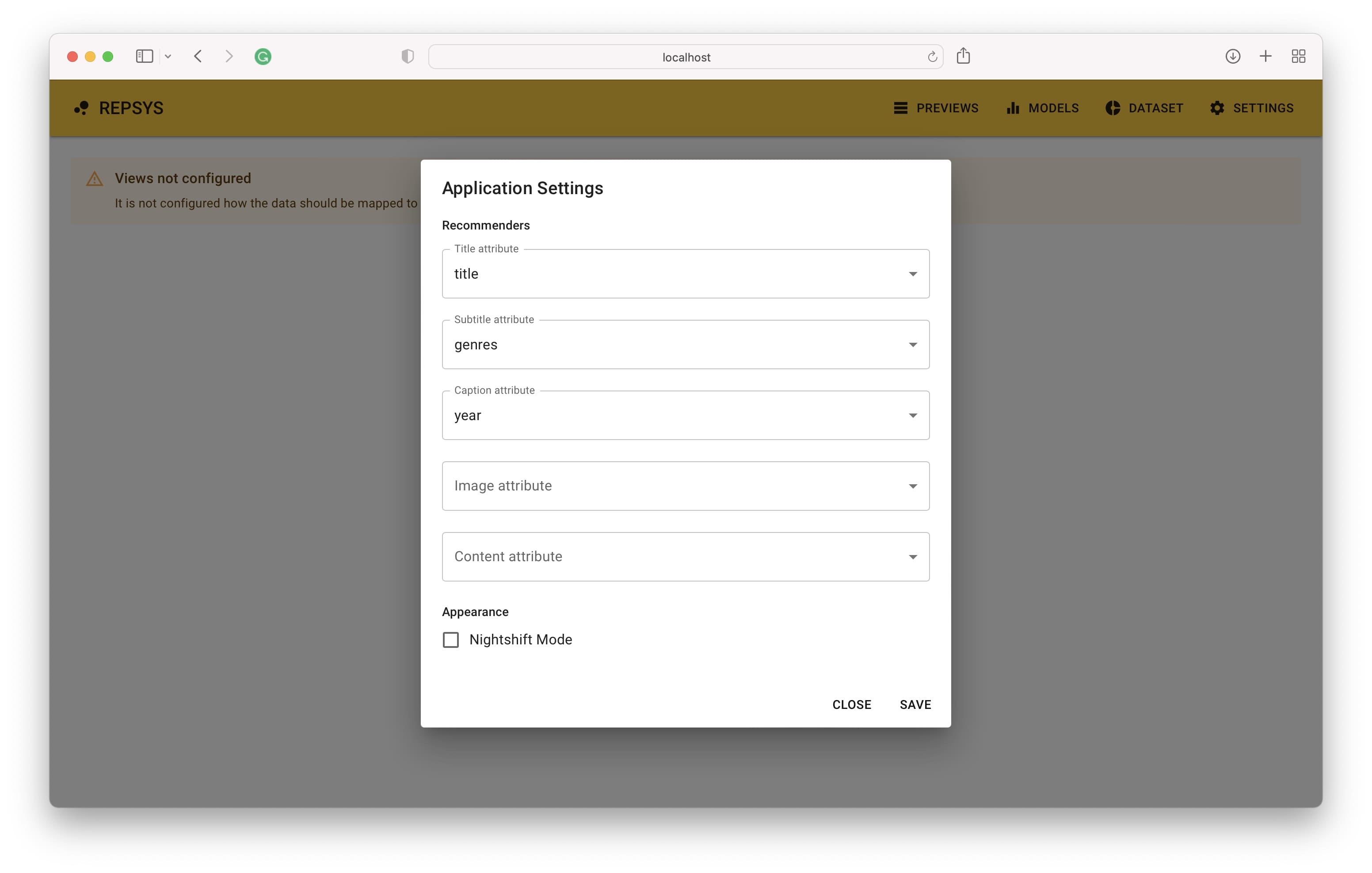
Dann müssen wir zum Build -Modus wechseln und zwei Empfehlungen hinzufügen - einen ohne Filter und den zweiten mit nur Comedy -Filmen enthalten.
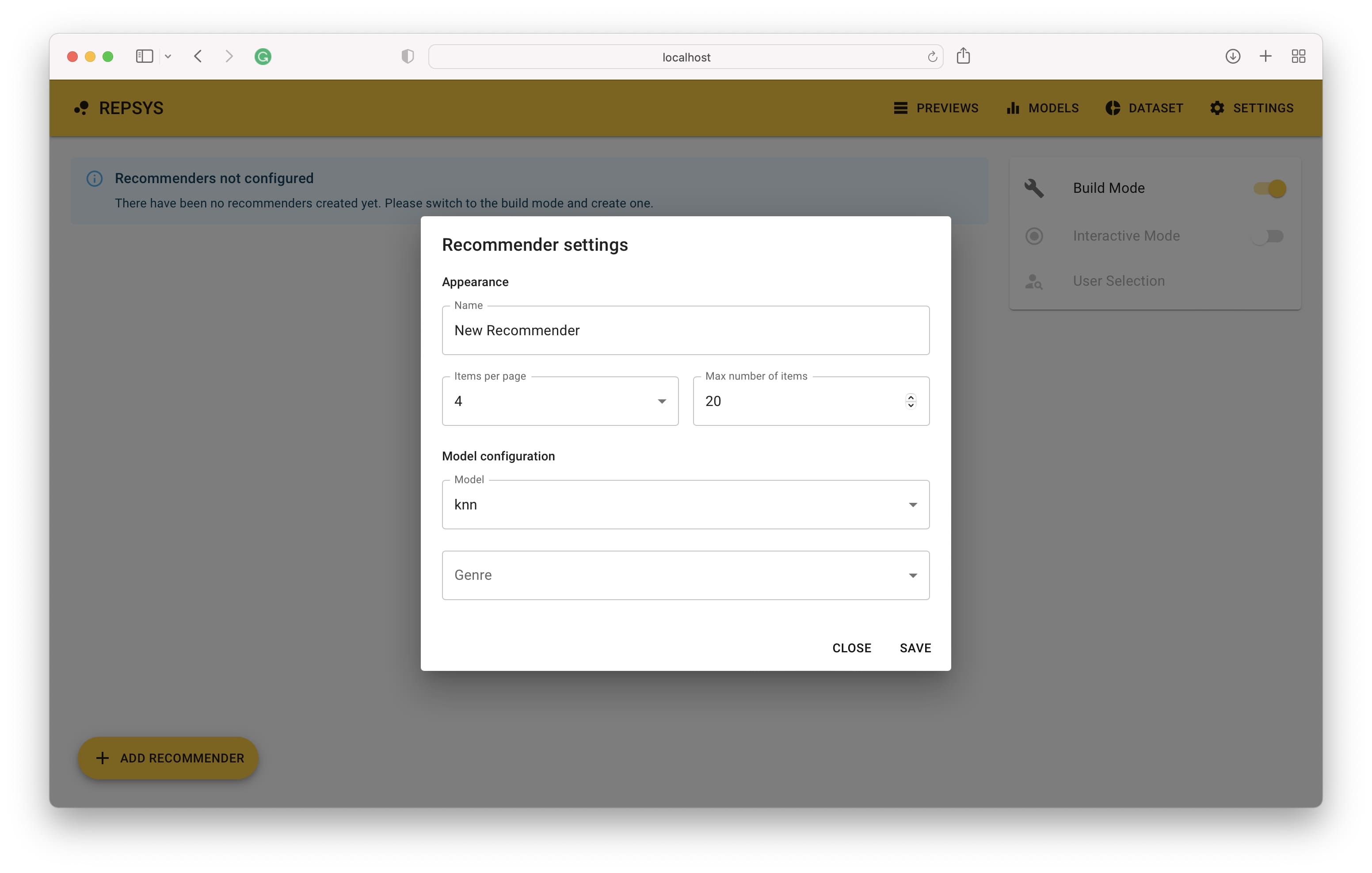
Jetzt wechseln wir aus dem Build -Modus zurück und wählen einen Benutzer aus dem Validierungssatz (noch nie von einem Modell gesehen).
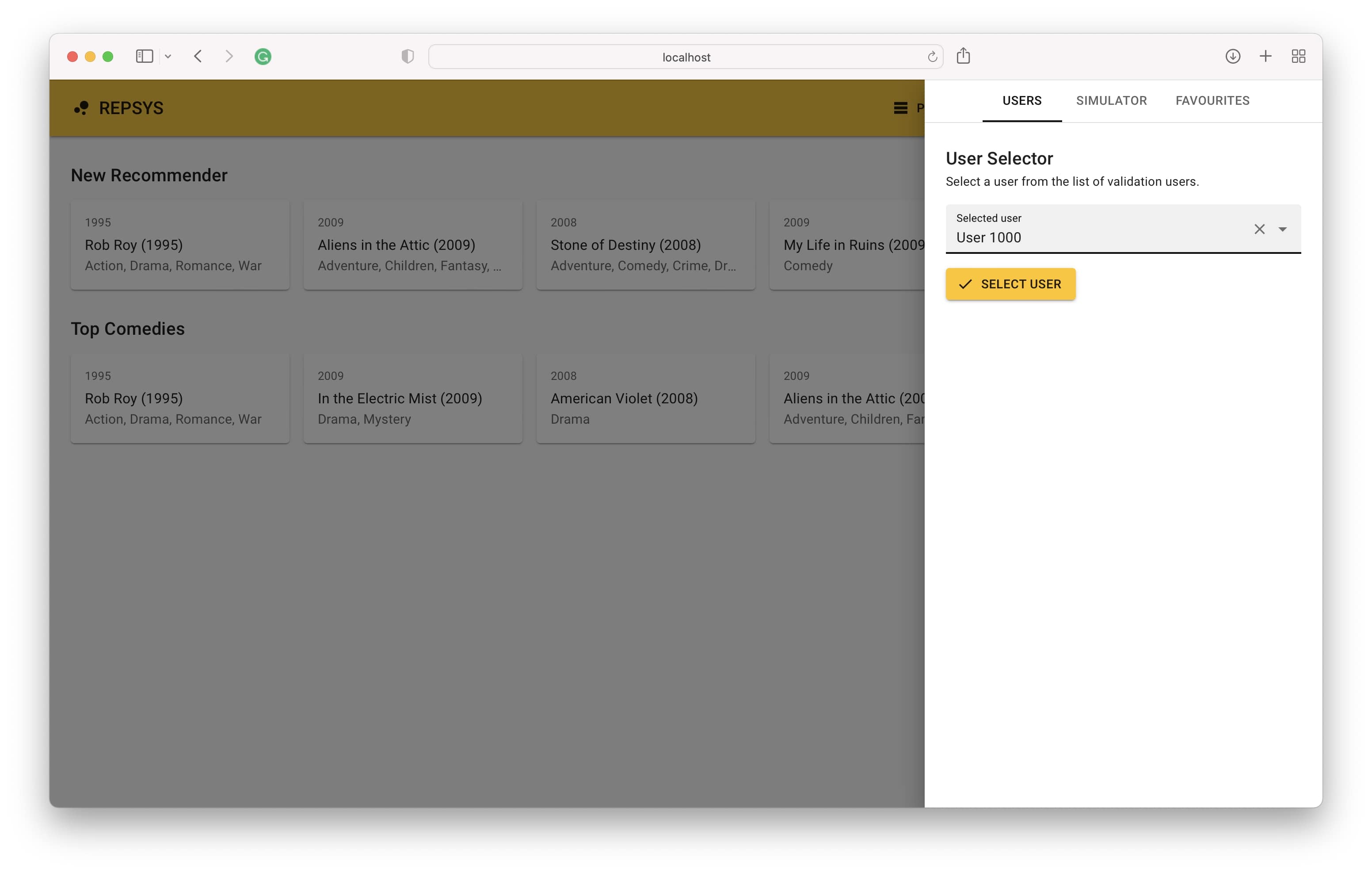
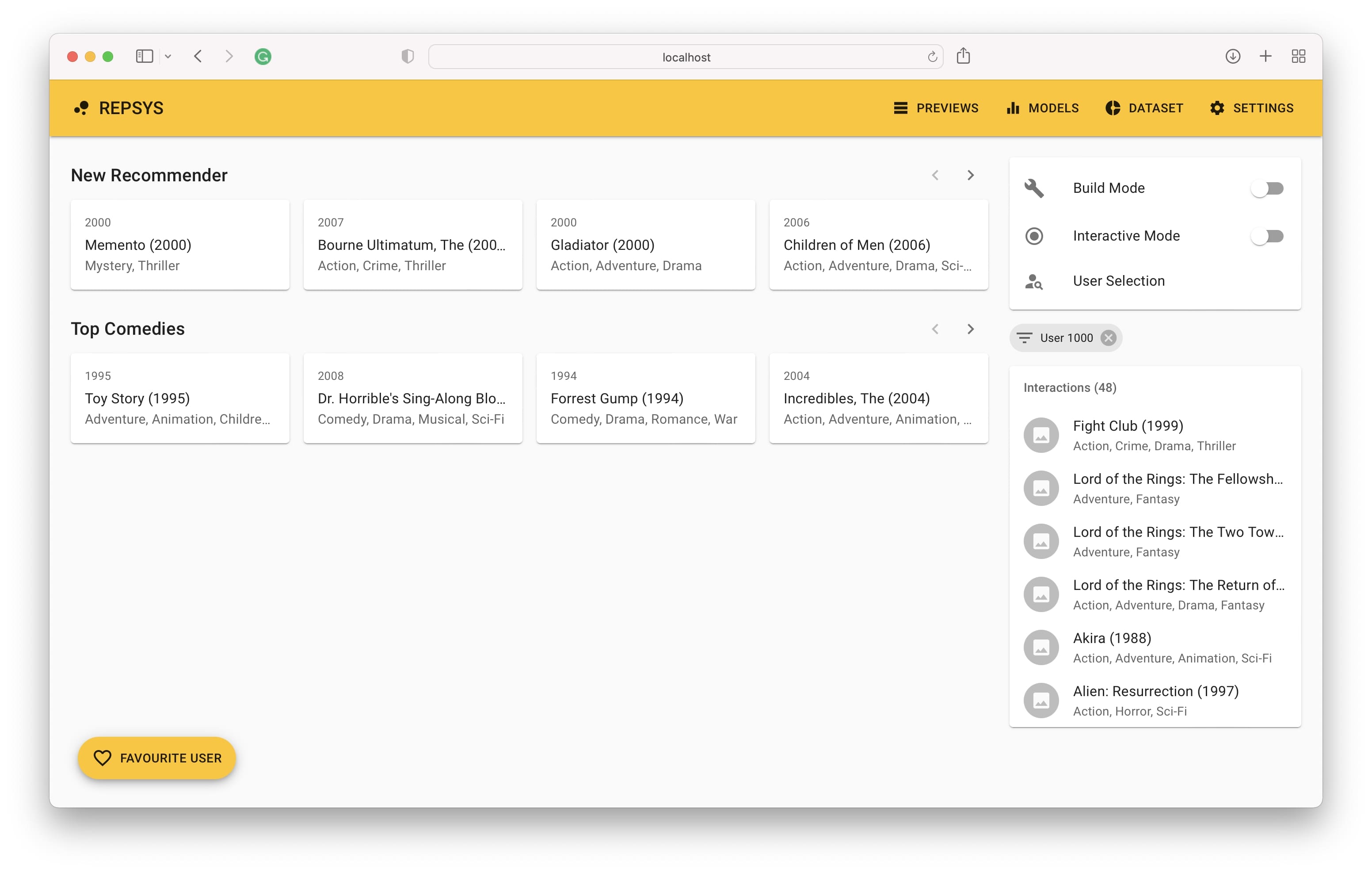
Schließlich sehen wir den Interaktionsverlauf des Benutzers auf der rechten Seite und die Empfehlungen des Modells auf der linken Seite.
Um das Paket aus der Quelle zu erstellen, müssen Sie zunächst die hier dokumentierte Node.js- und NPM -Bibliothek installieren. Anschließend können Sie das folgende Skript aus dem Root -Verzeichnis ausführen, um die Webanwendung zu erstellen und das Paket lokal zu installieren.
$ ./scripts/install-locally.sh
Wenn Sie Repsys in Ihrer Forschungsarbeit beschäftigen, vergessen Sie bitte nicht, das zugehörige Papier zu zitieren:
@inproceedings{10.1145/3523227.3551469,
author = {v{S}afav{r}'{i}k, Jan and Vanv{c}ura, Vojtv{e}ch and Kord'{i}k, Pavel},
title = {RepSys: Framework for Interactive Evaluation of Recommender Systems},
year = {2022},
isbn = {9781450392785},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3523227.3551469},
doi = {10.1145/3523227.3551469},
booktitle = {Proceedings of the 16th ACM Conference on Recommender Systems},
pages = {636–639},
numpages = {4},
keywords = {User simulation, Distribution analysis, Recommender systems},
location = {Seattle, WA, USA},
series = {RecSys '22}
}
Die Entwicklung dieses Rahmens wird von der Rekombee -Firma gesponsert.



