repsys
1.0.0
REPSYS는 추천 시스템을 개발하고 분석하기위한 프레임 워크이며 다음을 수행 할 수 있습니다.
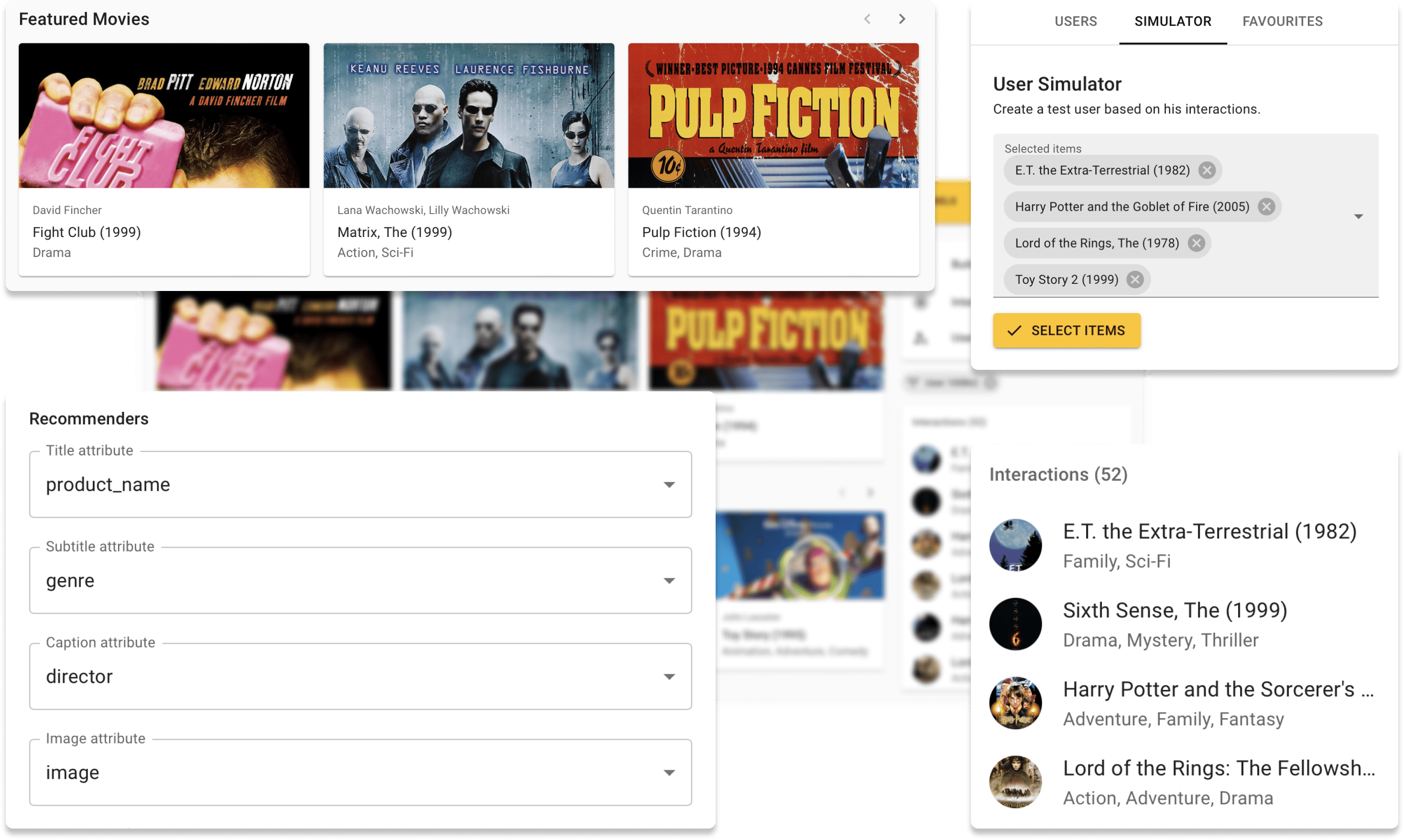
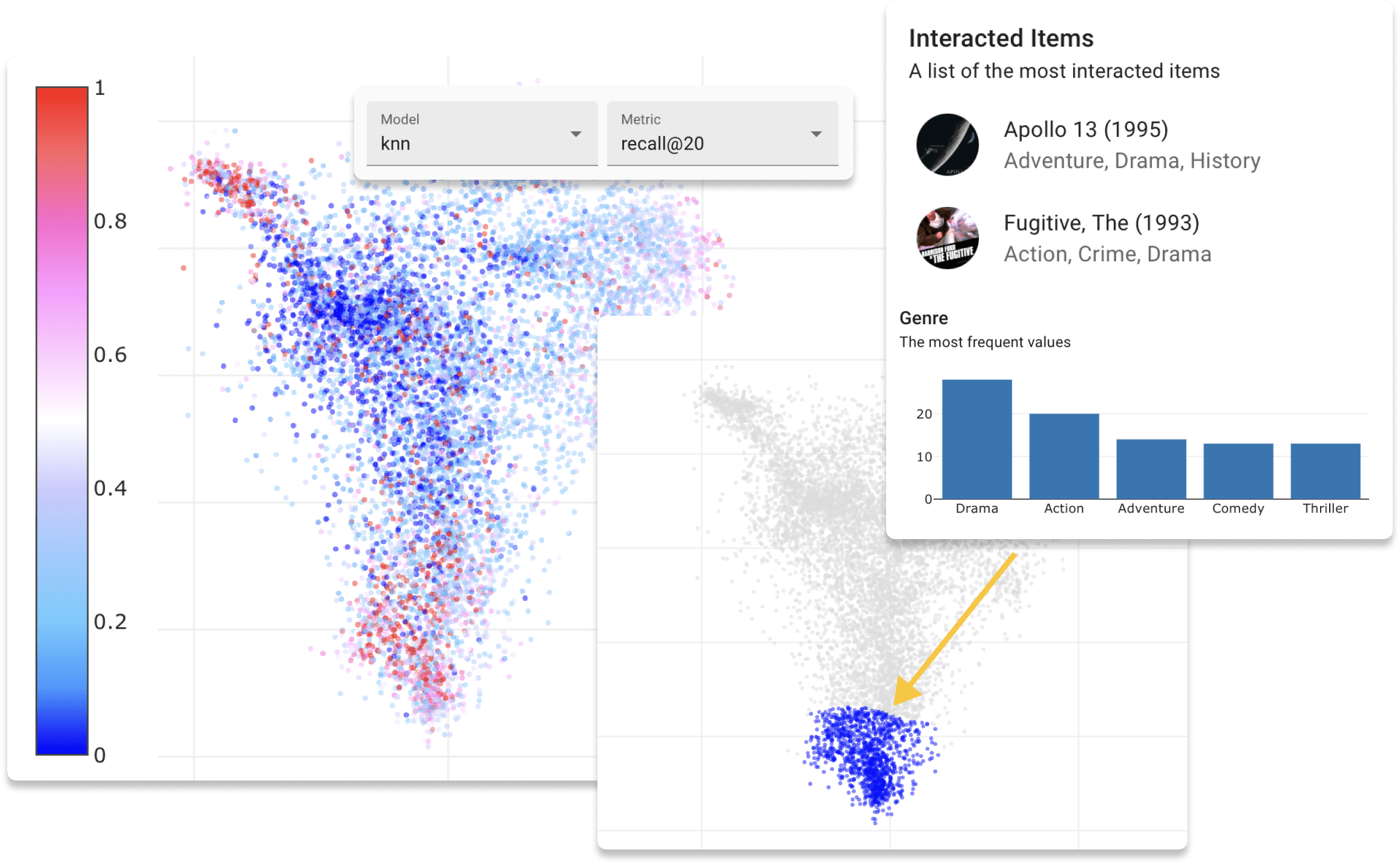

이제 Movielens 데이터 세트와 함께 데모 사이트에서 온라인으로 Repsys를 시도 할 수 있습니다. 또한 Repsys 위젯 구성 요소를 사용하여 만든 대화식 블로그 게시물을 확인하십시오.
우리의 논문 "REPSYS : 추천 시스템의 대화식 평가를위한 프레임 워크"는 Recsys'22 컨퍼런스에 수용되었습니다.
PIP를 사용하여 패키지를 설치하십시오.
$ pip install repsys-framework
데이터 시각화에 PYMDE를 사용하는 경우 다음 엑스트라와 함께 Repsys를 설치해야합니다.
$ pip install repsys-framework[pymde]
이 자습서를 건너 뛰고 프레임 워크를 시도하려면 저장소에있는 데모 폴더의 내용을 가져올 수 있습니다. 다음 단계에서 언급했듯이 시작하기 전에 여전히 데이터 세트를 다운로드해야합니다.
그렇지 않으면 데이터 세트 및 모델 구현이 포함 된 빈 프로젝트 폴더를 작성하십시오.
├── __init__.py
├── dataset.py
├── models.py
├── repsys.ini
└── .gitignore
먼저 데이터 세트를 가져와야합니다. 우리는 튜토리얼 목적을 위해 138,000 명의 사용자가 2 억 2 천만 명의 영화에서 2 천만 등급을 달성 한 Movielens 20M 데이터 세트를 사용할 것입니다. ml-20m.zip 파일을 다운로드하고 데이터를 현재 폴더로 연결하십시오. 그런 다음 dataset.py 파일에 다음 내용을 추가하십시오.
import pandas as pd
from repsys import Dataset
import repsys . dtypes as dtypes
class MovieLens ( Dataset ):
def name ( self ):
return "ml20m"
def item_cols ( self ):
return {
"movieId" : dtypes . ItemID (),
"title" : dtypes . Title (),
"genres" : dtypes . Tag ( sep = "|" ),
"year" : dtypes . Number ( data_type = int ),
}
def interaction_cols ( self ):
return {
"movieId" : dtypes . ItemID (),
"userId" : dtypes . UserID (),
"rating" : dtypes . Interaction (),
}
def load_items ( self ):
df = pd . read_csv ( "./ml-20m/movies.csv" )
df [ "year" ] = df [ "title" ]. str . extract ( r"((d+))" )
return df
def load_interactions ( self ):
df = pd . read_csv ( "./ml-20m/ratings.csv" )
return df이 코드는 ML20M이라는 새 데이터 세트를 정의하며 등급과 항목 데이터를 모두 가져옵니다. 사전 정의 된 데이터 유형을 사용하여 항상 데이터 구조를 지정해야합니다. 데이터를 반환하기 전에 제목 열에서 영화의 연도를 추출하는 것과 같이 전처리 할 수도 있습니다.
이제 사용자 기반 KNN의 간단한 구현이 될 첫 번째 권장 모델을 정의합니다.
import numpy as np
import scipy . sparse as sp
from sklearn . neighbors import NearestNeighbors
from repsys import Model
class KNN ( Model ):
def __init__ ( self ):
self . model = NearestNeighbors ( n_neighbors = 20 , metric = "cosine" )
def name ( self ):
return "knn"
def fit ( self , training = False ):
X = self . dataset . get_train_data ()
self . model . fit ( X )
def predict ( self , X , ** kwargs ):
if X . count_nonzero () == 0 :
return np . random . uniform ( size = X . shape )
distances , indices = self . model . kneighbors ( X )
distances = distances [:, 1 :]
indices = indices [:, 1 :]
distances = 1 - distances
sums = distances . sum ( axis = 1 )
distances = distances / sums [:, np . newaxis ]
def f ( dist , idx ):
A = self . dataset . get_train_data ()[ idx ]
D = sp . diags ( dist )
return D . dot ( A ). sum ( axis = 0 )
vf = np . vectorize ( f , signature = "(n),(n)->(m)" )
predictions = vf ( distances , indices )
predictions [ X . nonzero ()] = 0
return predictions교육 데이터를 사용하여 모델을 훈련 시키거나 파일에서 이전에 훈련 된 모델을로드하려면 적합 메소드를 정의해야합니다. 웹 응용 프로그램이 시작되거나 평가 프로세스가 시작될 때 모든 모델이 적합합니다. 이것이 훈련 단계가 아닌 경우 항상 체크 포인트에서 모델을로드하여 프로세스 속도를 높이십시오. 튜토리얼 목적으로 이것은 생략됩니다.
또한 입력에 대한 사용자의 상호 작용의 희소 행렬을 수신하는 예측 방법을 정의해야합니다. 각 사용자 (행렬의 행) 및 항목 (매트릭스 열)에 대해 메소드는 사용자가 항목을 얼마나 즐길 수 있는지를 나타내는 예측 점수를 반환해야합니다.
또한 추천 작성 중에 설정할 수있는 일부 웹 응용 프로그램 매개 변수를 지정할 수 있습니다. 그런 다음 예측 방법의 **kwargs 인수에서 값에 액세스 할 수 있습니다. 이 예에서는 모든 고유 장르로 선택한 입력을 생성하고 선택한 장르가 포함되지 않은 영화 만 필터링합니다.
마지막으로 작성해야 할 파일은 데이터 분할 프로세스, 서버 설정, 프레임 워크 동작 등을 제어 할 수있는 구성입니다.
[general]
seed =1234
[dataset]
train_split_prop =0.85
test_holdout_prop =0.2
min_user_interacts =5
min_item_interacts =0
[evaluation]
precision_recall_k =20,50
ndcg_k =100
coverage_k =20
diversity_k =20
novelty_k =20
percentage_lt_k =20
coverage_lt_k =20
[visualization]
embed_method =pymde
pymde_neighbors =15
umap_neighbors =15
umap_min_dist =0.1
tsne_perplexity =30
[server]
port =3001모델을 훈련시키기 전에 데이터를 기차, 검증 및 테스트 세트로 분할해야합니다. 현재 디렉토리에서 다음 명령을 실행하십시오.
$ repsys dataset split
이는 사용자의 85%가 교육 데이터로 유지되며 나머지 15%는 각각 7.5%의 사용자와 함께 검증/테스트 데이터로 사용됩니다. 검증 및 테스트 세트의 경우 평가 목적으로 상호 작용의 20%도 유지됩니다. 분할 데이터 세트는 기본 체크 포인트 폴더에 저장됩니다.
이제 우리는 훈련 과정으로 이동할 수 있습니다. 이렇게하려면 다음 명령에 전화하십시오.
$ repsys model train
이 명령은 각 모델의 적합 메소드를 트레이닝 플래그를 true로 설정 한 상태에서 호출합니다. 모델의 이름을 매개 변수로 사용하는 -m 플래그를 사용하여 모델을 항상 제한 할 수 있습니다.
데이터가 준비되고 모델이 훈련되면 보이지 않는 사용자의 상호 작용에서 모델의 성능을 평가할 수 있습니다. 그렇게하려면 다음 명령을 실행하십시오.
$ repsys model eval
다시, -m 플래그를 사용하여 모델을 제한 할 수 있습니다. 결과는 평가가 완료되면 체크 포인트 폴더에 저장됩니다.
웹 응용 프로그램을 시작하기 전에 최종 단계는 데이터 세트의 데이터를 평가하는 것입니다. 이 절차는 교육 및 유효성 검사 데이터의 사용자 및 항목 임베딩을 만들어 잠재적 인 공간을 탐색 할 수 있습니다. 프로젝트 디렉토리에서 다음 명령을 실행하십시오.
$ repsys dataset eval
세 가지 유형의 임베딩 알고리즘 중에서 선택할 수 있습니다.
--method umap (기본 옵션입니다).--method pymde .--method tsne .--method custom 사용하고 선택한 모델의 클래스에 다음 방법을 추가하십시오. 이 경우 -m 매개 변수를 사용하여 모델의 이름을 지정해야합니다. from sklearn . decomposition import NMF
def compute_embeddings ( self , X ):
nmf = NMF ( n_components = 2 )
W = nmf . fit_transform ( X )
H = nmf . components_
return W , H . T이 예에서, 음의 매트릭스 인수 화가 사용된다. 이 순서대로 사용자 및 항목 임베딩 쌍을 반환해야합니다. 또한 (n_users/n_items, n_dim)의 모양으로 행렬을 반환하는 것이 필수적입니다. 감소 된 차원이 2보다 높으면 TSNE 방법이 적용됩니다.
마지막으로, 웹 애플리케이션을 시작하여 모델의 평가 결과를 확인하고 모델의 실시간 권장 사항을 미리 볼 시간입니다.
$ repsys server
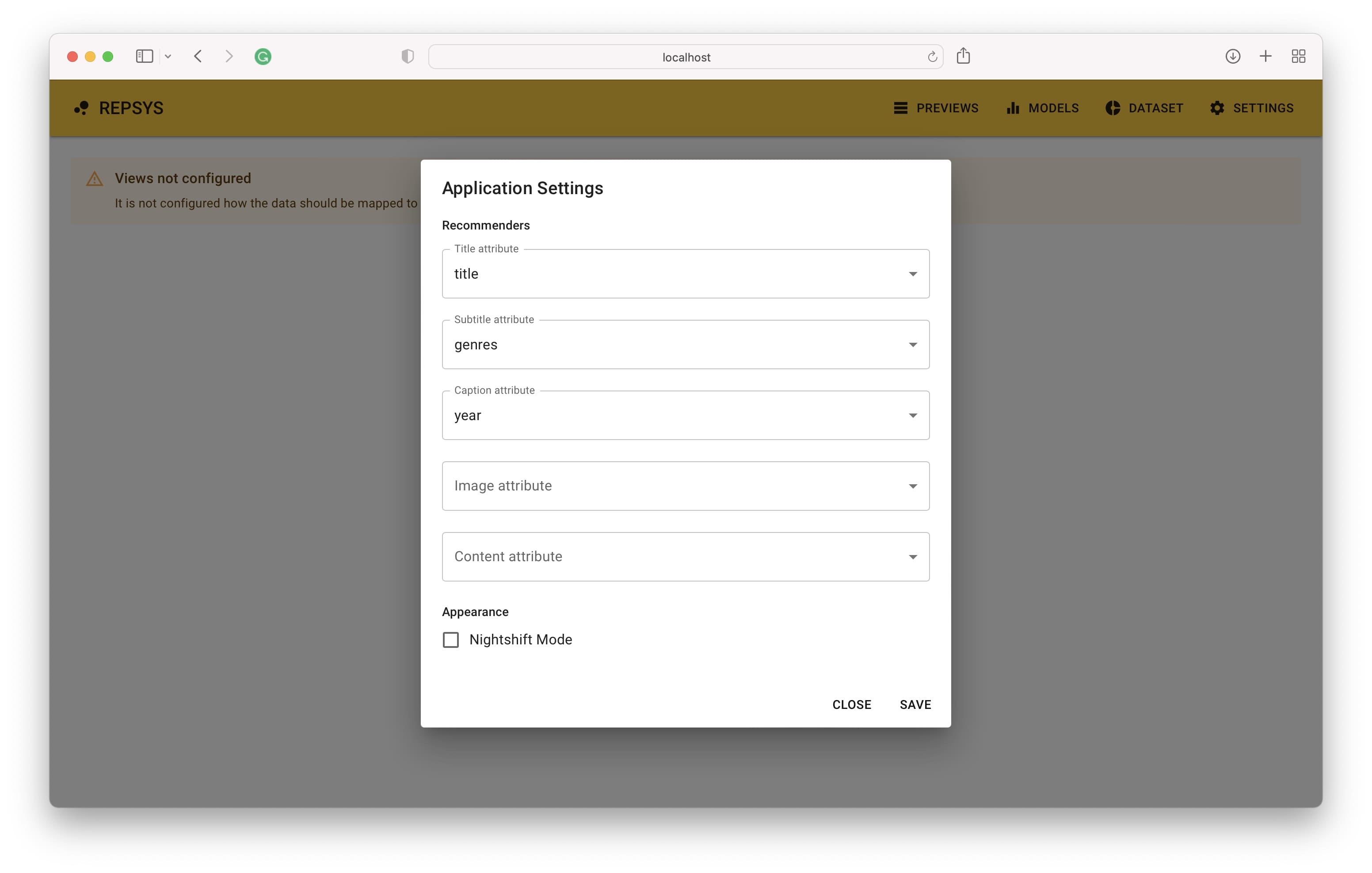
기본 주소 http : // localhost : 3001에서 응용 프로그램에 액세스 할 수 있어야합니다. 링크를 열면 설정이 완료되면 권장 사항이 나타나는 기본 화면이 표시됩니다. 첫 번째 단계는 항목의 데이터 열이 항목보기 구성 요소에 어떻게 매핑되는지 정의하는 것입니다.
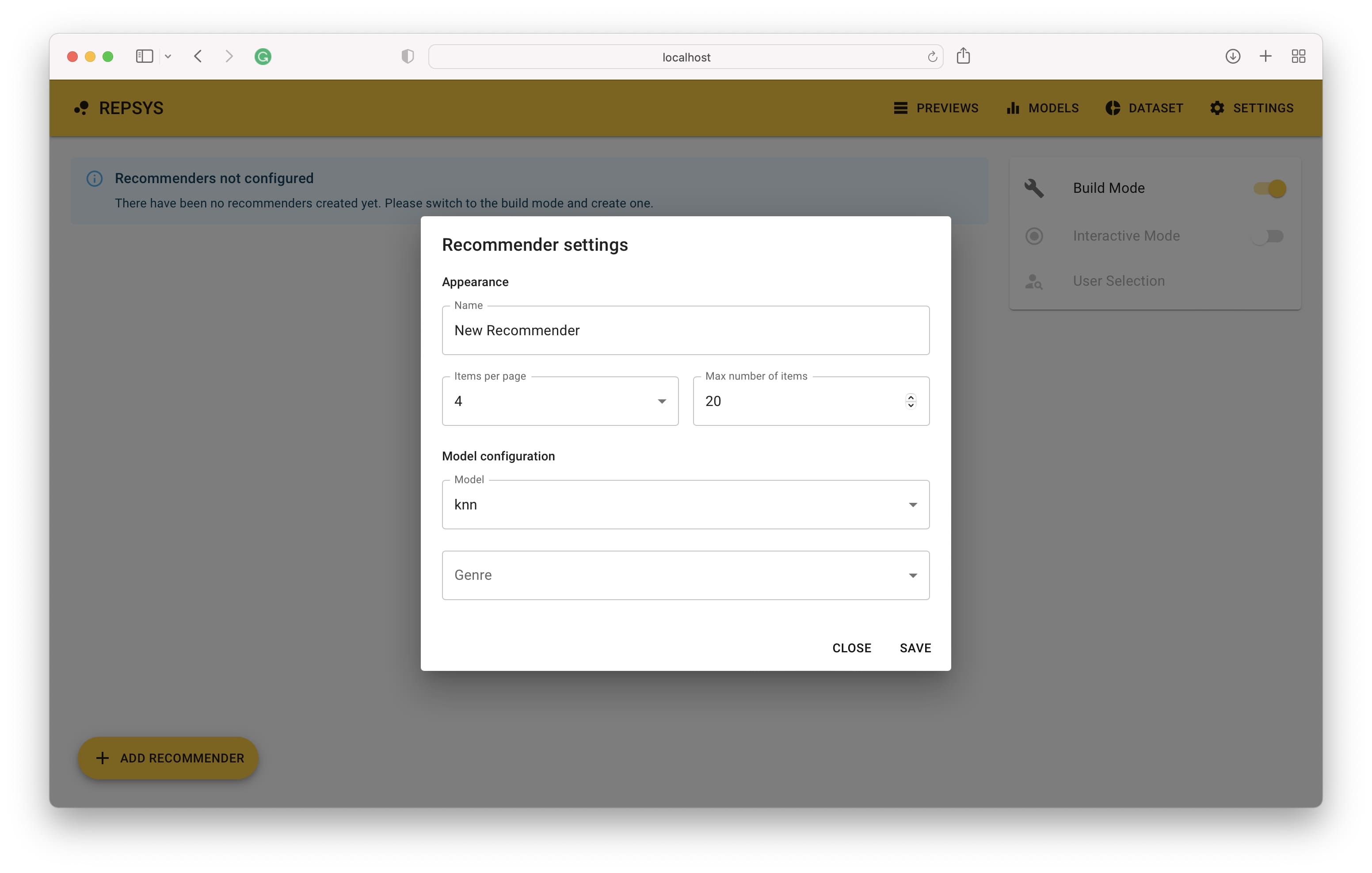
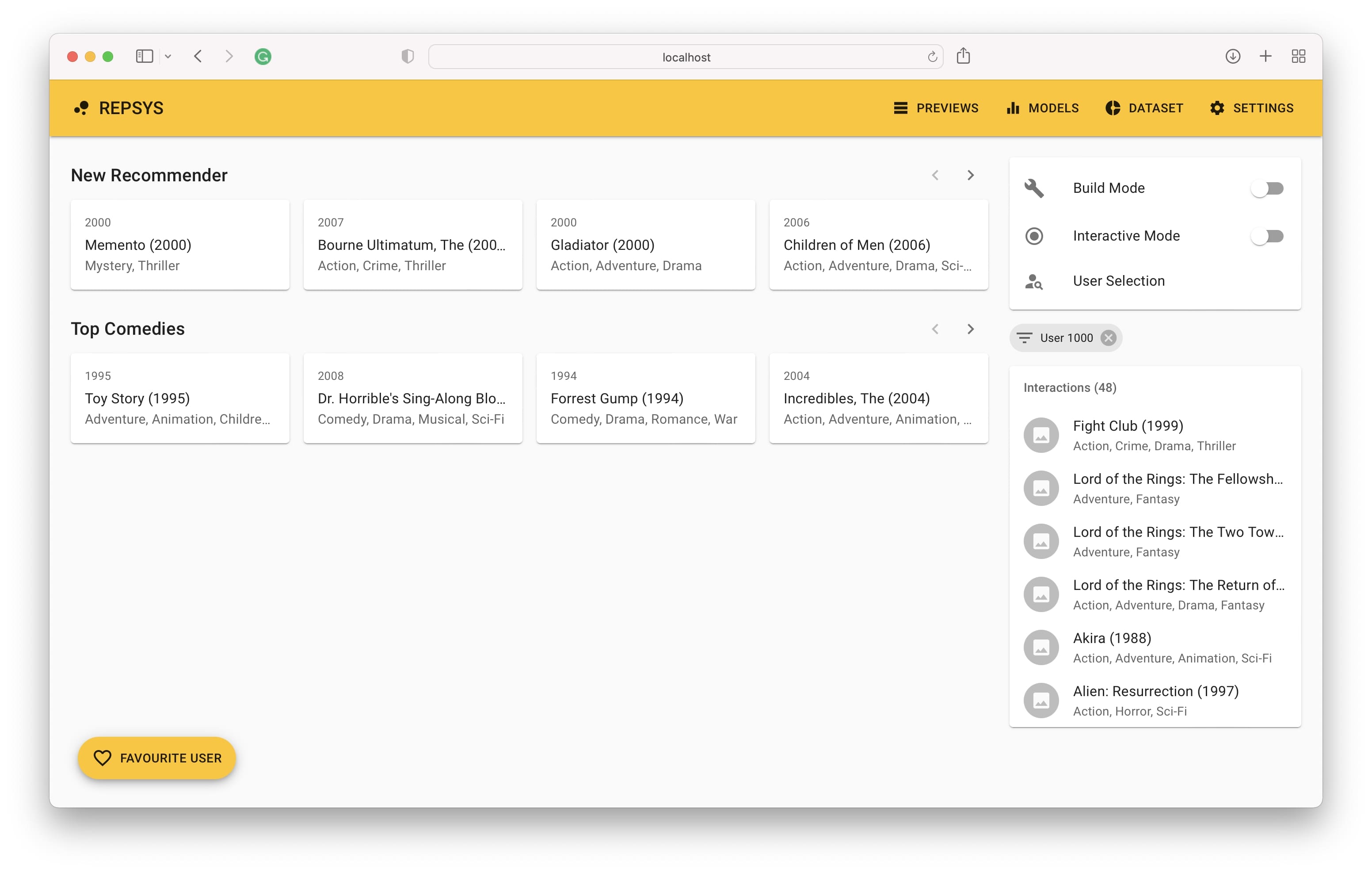
그런 다음 빌드 모드로 전환하고 두 명의 추천자를 추가해야합니다. 하나는 필터가없고 두 번째는 코미디 영화 만 포함되어 있습니다.
이제 빌드 모드에서 다시 전환하고 유효성 검사 세트에서 사용자를 선택합니다 (이전 모델에서는 보지 못했습니다).
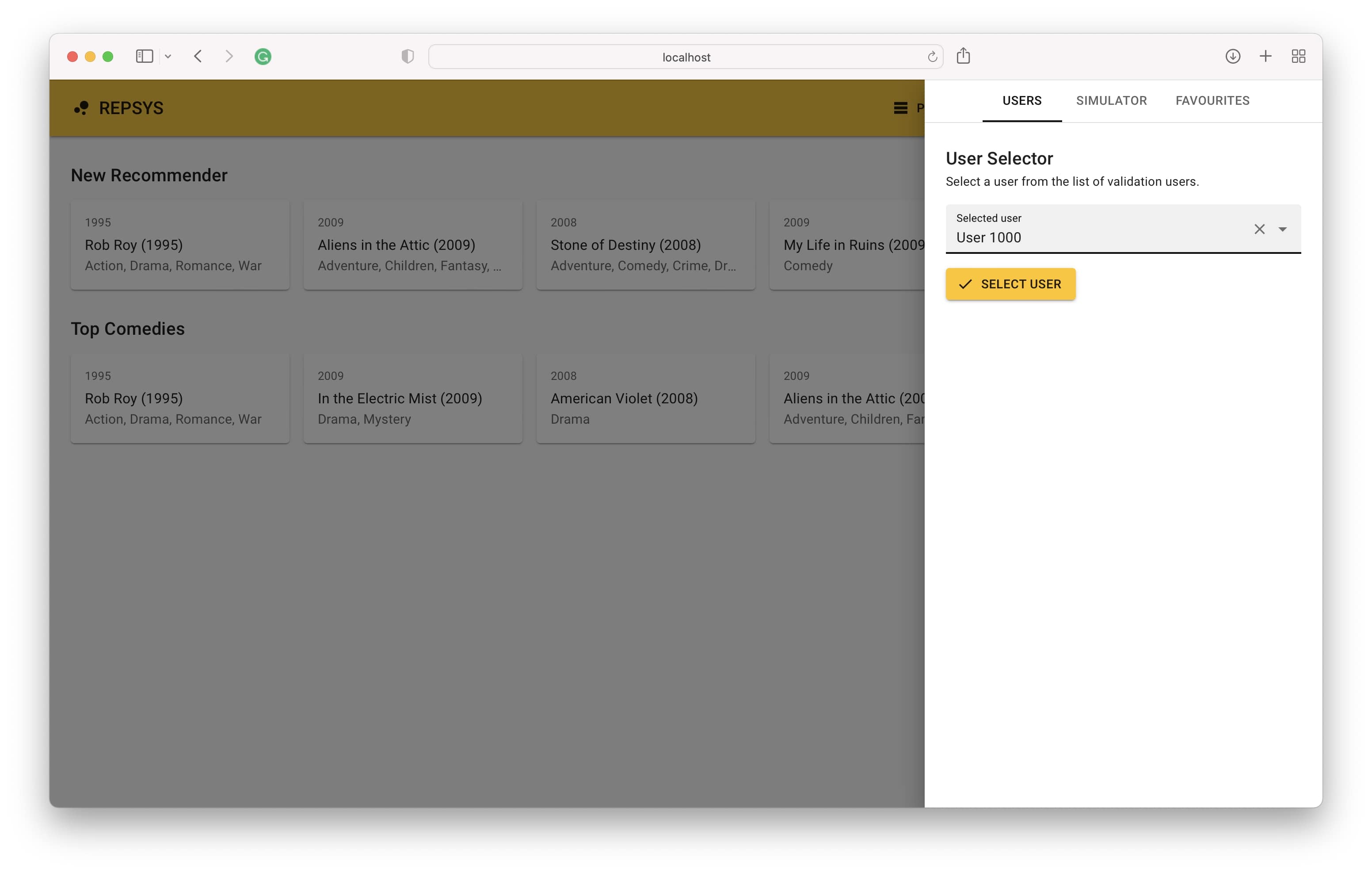
마지막으로, 우리는 사용자의 상호 작용 기록이 오른쪽에 있고 왼쪽 모델의 권장 사항을 볼 수 있습니다.
소스에서 패키지를 작성하려면 먼저 여기에 문서화 된대로 Node.js 및 NPM 라이브러리를 설치해야합니다. 그런 다음 루트 디렉토리에서 다음 스크립트를 실행하여 웹 응용 프로그램을 작성하고 로컬로 패키지를 설치할 수 있습니다.
$ ./scripts/install-locally.sh
연구 작업에 REPSY를 사용하는 경우 관련 논문을 인용하는 것을 잊지 마십시오.
@inproceedings{10.1145/3523227.3551469,
author = {v{S}afav{r}'{i}k, Jan and Vanv{c}ura, Vojtv{e}ch and Kord'{i}k, Pavel},
title = {RepSys: Framework for Interactive Evaluation of Recommender Systems},
year = {2022},
isbn = {9781450392785},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3523227.3551469},
doi = {10.1145/3523227.3551469},
booktitle = {Proceedings of the 16th ACM Conference on Recommender Systems},
pages = {636–639},
numpages = {4},
keywords = {User simulation, Distribution analysis, Recommender systems},
location = {Seattle, WA, USA},
series = {RecSys '22}
}
이 프레임 워크의 개발은 Recombee Company가 후원합니다.



