NewsQA
1.0.0
このリポジトリには、さまざまなパキスタンのニュースWebサイトから削られたニュース記事の大規模なデータセットが含まれています。データセットは、次のような多様なカテゴリをカバーしています。
スクレイプされたニュース記事から質問回答ペアを生成するために、いくつかの大きな言語モデル(LLM)を評価しました。
私たちのケーススタディでは、Llama2は最高品質を提供しますが、GPTモデルと比較して遅くなることが明らかになりました。 T5-small 、高速ですが、精度と重複に制限があります。その結果、 GPT-3.5 TurboとGPT-4を使用して、より実質的なデータセットを生成しました。
このデータセットはオープンソースであり、以下に使用できます。
さらに、このデータセットには小さなラマが微調整されています。
| llama2 | T5-Small | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
| GPT-3.5-ターボ | GPT-4 | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
GPT3.5-TurboとGPT4 、望ましい応答を生成します。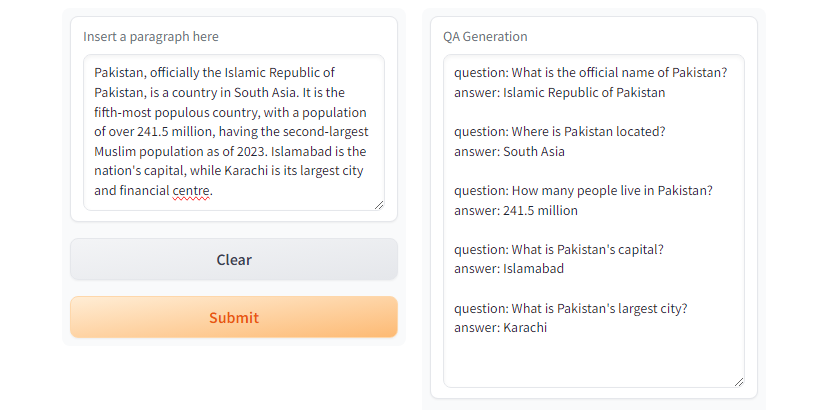 図
図T5-smallを使用したグラデーションデモ
git clone https://github.com/faizan1234567/QALLM.git
cd QALLMPython venvを使用して仮想環境を作成します
python3 -m venv qa_llm
source qa_llm/bin/activateまたは、Anacondaパッケージマネージャーを使用することもできます
conda create -n qa_llm python=3.8.10 -y
conda activate qa_llm必要なすべての依存関係をインストールします
pip install --upgrade pip
pip install -r requirements.txtQA生成、設定を読んで理解し、必要に応じて適切な値を置き換えるようにしてください。
python create_alpaca_format_dataset.py --chunk_size 5000 --dataset < path >QA生成を実行します
python qa_generator.py --model T5-small --cfg cfg/qa_generator.yamlまた、Google Colab、Kaggle、Gradient、またはGPUを使用してローカルマシンにQAをインストールおよび実行するためのnotebooksディレクトリの下にrun_qa_llm_repo.ipynbがあります。
データセットが微調整、研究、開発の目的に役立つと思う場合は、リポジトリを主演して引用してください。
ムハンマド・ファイザンとサナ・ザファー
@misc{QALLM,
title={NewsQA: News Dataset for QA Generation},
authors={Muhammad Faizan and Sana Zafar},
howpublished = { url {https://github.com/faizan1234567/QALLM}},
year={2024}
}[1]。高速で強力なスクレイピングとウェブクロールのフレームワーク。スクラピー。 (nd)。 https://scrapy.org/
[2]。 https://huggingface.co/thebloke/llama-2-70b-ggml。 (nd)。
[3]。 Ushio、A.、Alva-Manchego、F。、&Camacho-Collados、J。(2023)。 LMベースの質問と回答生成方法の経験的比較。 arxiv preprint arxiv:2305.17002。
[4]。 OpenaiのGPT-3.5 Turbo、Platform.openai.com/docs/models/gpt-3-5-turbo。 2024年7月28日アクセス。


