NewsQA
1.0.0
Dieses Repository enthält einen großen Datensatz von Nachrichtenartikeln, die von verschiedenen pakistanischen Nachrichten -Websites abgeschafft wurden. Der Datensatz deckt verschiedene Kategorien ab, einschließlich:
Wir haben mehrere große Sprachmodelle (LLMs) bewertet, um Fragen-Antwortenpaare aus den abgekratzten Nachrichtenartikeln zu generieren:
Unsere Fallstudie ergab, dass LLAMA2 zwar die beste Qualität bietet, aber im Vergleich zu GPT -Modellen langsamer ist. T5-small hat zwar schnell, aber Einschränkungen bei der Genauigkeit und Duplikation. Infolgedessen haben wir GPT-3.5 Turbo und GPT-4 verwendet, um einen umfangreicheren Datensatz zu generieren.
Dieser Datensatz ist Open-Source und kann verwendet werden für:
Darüber hinaus haben wir in diesem Datensatz fein abgestimmte kleine Lama.
| LAMA22 | T5-Small | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
| GPT-3,5-Turbo | GPT-4 | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
GPT3.5-Turbo und GPT4 erzeugen die gewünschte Antwort.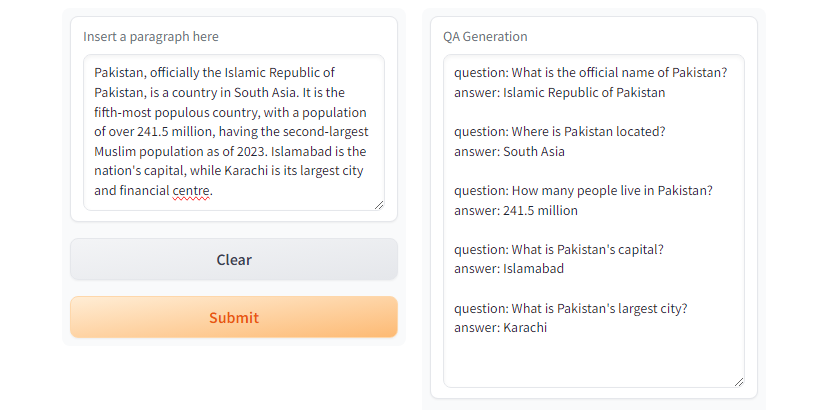 Abb. Gradio Demo mit
Abb. Gradio Demo mit T5-small
git clone https://github.com/faizan1234567/QALLM.git
cd QALLMErstellen Sie eine virtuelle Umgebung mit Python Venv
python3 -m venv qa_llm
source qa_llm/bin/activateAlternativ können Sie Anaconda Paket Manager verwenden
conda create -n qa_llm python=3.8.10 -y
conda activate qa_llmInstallieren Sie nun alle erforderlichen Abhängigkeiten
pip install --upgrade pip
pip install -r requirements.txtQA -Generierung, lesen Sie die Konfigurationen und ersetzen Sie die geeigneten Werte nach Bedarf.
python create_alpaca_format_dataset.py --chunk_size 5000 --dataset < path >und führen Sie die QA -Generation aus
python qa_generator.py --model T5-small --cfg cfg/qa_generator.yaml Und es gibt ein run_qa_llm_repo.ipynb unter notebooks -Verzeichnis, um die QA in Google Colab, Kaggle, Gradienten oder lokaler Maschine mit GPU zu installieren und auszuführen.
Wenn Sie den Datensatz für Feinabstimmungen, Forschung und Entwicklungszwecke nützlich finden, sparen Sie bitte das Repo:
Muhammad Faizan und Sana Zafar
@misc{QALLM,
title={NewsQA: News Dataset for QA Generation},
authors={Muhammad Faizan and Sana Zafar},
howpublished = { url {https://github.com/faizan1234567/QALLM}},
year={2024}
}[1]. Ein schnelles und leistungsstarkes Scraping- und Web -Crawling -Framework. Scrapy. (ND). https://scrapy.org/
[2]. https://huggingface.co/thebloke/llama-2-70b-ggml. (ND).
[3]. A. Ushio, F. Alva-Manchego & J. Camacho-Collados (2023). Ein empirischer Vergleich von LM-basierten Fragen- und Antwortgenerierungsmethoden. Arxiv Preprint Arxiv: 2305.17002.
[4]. OpenAIs GPT-3.5 Turbo, platform.openai.com/docs/models/gpt-3-5-turbo. Zugriff 28. Juli 2024.


