sapbert
1.0.0
[Berita | 22 Agustus 2021] Sapbert diintegrasikan ke dalam perangkat pembelajaran mendalam Nvidia Nemo sebagai modul penghubung entitasnya (terima kasih Nvidia!). Anda dapat bermain dengannya di Google Colab ini.
Repo ini memiliki kode, data, dan bobot pretrained untuk (1) model Sapbert yang disajikan dalam makalah NAACL 2021 kami: pretraining penyelarasan diri untuk representasi entitas biomedis ; (2) Sapbert lintas-bahasa dan entitas biomedis lintas-bahasa yang menghubungkan tolok ukur ( XL-BEL ) yang diusulkan dalam makalah ACL 2021 kami: belajar representasi khusus domain untuk penghubung entitas biomedis lintas-bahasa .
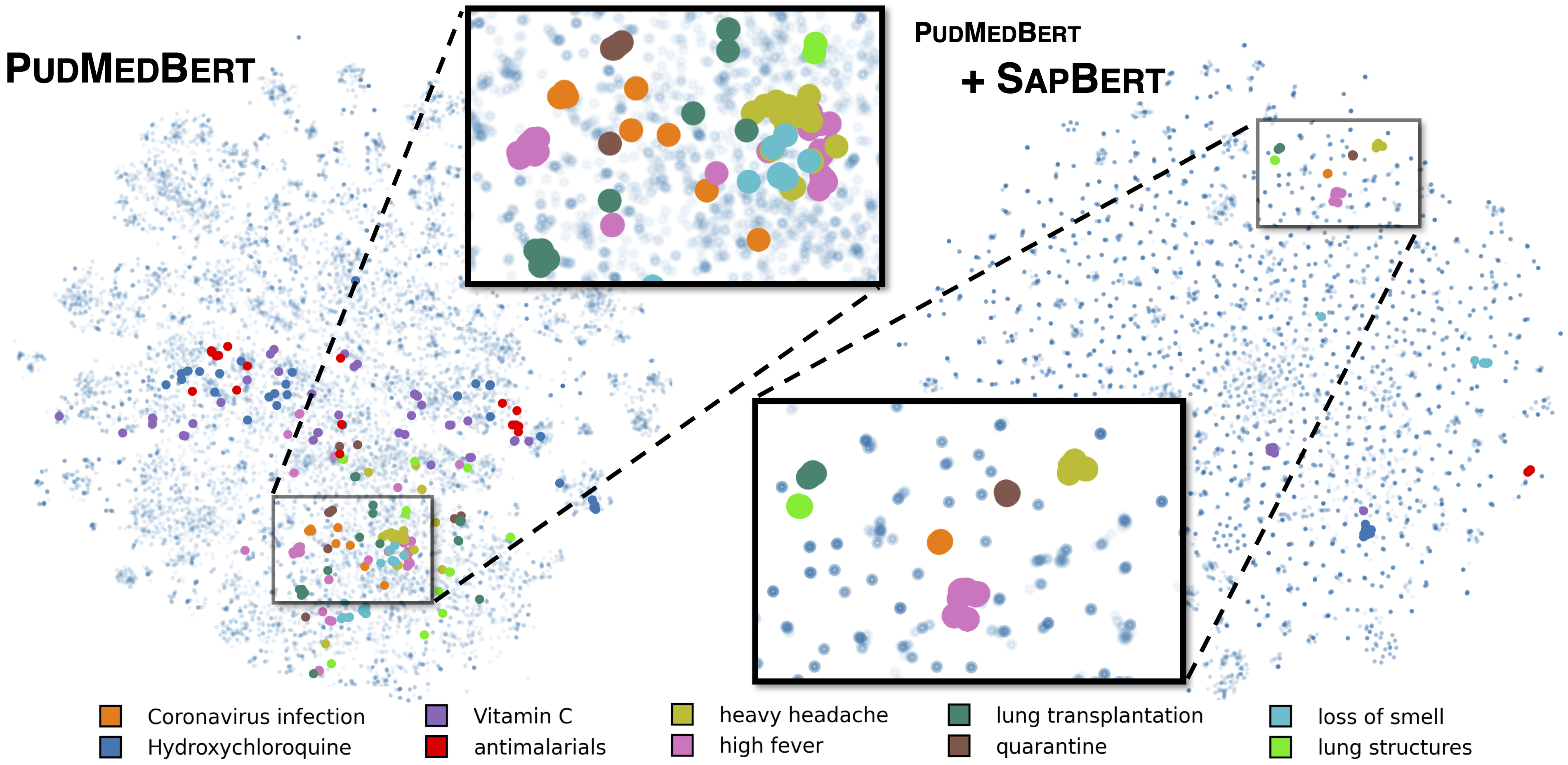
Sapbert standar seperti yang dijelaskan dalam [Liu et al., NAACL 2021]. Dilatih dengan UMLS 2020AA (hanya bahasa Inggris), menggunakan microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext sebagai model dasar. Untuk [Sapbert], gunakan [CLS] (sebelum Pooler) sebagai representasi input; Untuk [Sapbert-Mean-Token], gunakan pemetik rata-rata di semua token.
Sapbert lintas-bahasa seperti yang dijelaskan dalam [Liu et al., ACL 2021]. Dilatih dengan UMLS 2020AB (semua bahasa), menggunakan xlm-roberta-base / xlm-roberta-large sebagai model dasar. Gunakan [CLS] (sebelum Pooler) sebagai representasi input.
Kode ini diuji dengan Python 3.8, Torch 1.7.0 dan Huggingface Transformers 4.4.2. Harap lihat requirements.txt untuk lebih jelasnya.
Script berikut mengubah daftar string (nama entitas) menjadi embeddings.
import numpy as np
import torch
from tqdm . auto import tqdm
from transformers import AutoTokenizer , AutoModel
tokenizer = AutoTokenizer . from_pretrained ( "cambridgeltl/SapBERT-from-PubMedBERT-fulltext" )
model = AutoModel . from_pretrained ( "cambridgeltl/SapBERT-from-PubMedBERT-fulltext" ). cuda ()
# replace with your own list of entity names
all_names = [ "covid-19" , "Coronavirus infection" , "high fever" , "Tumor of posterior wall of oropharynx" ]
bs = 128 # batch size during inference
all_embs = []
for i in tqdm ( np . arange ( 0 , len ( all_names ), bs )):
toks = tokenizer . batch_encode_plus ( all_names [ i : i + bs ],
padding = "max_length" ,
max_length = 25 ,
truncation = True ,
return_tensors = "pt" )
toks_cuda = {}
for k , v in toks . items ():
toks_cuda [ k ] = v . cuda ()
cls_rep = model ( ** toks_cuda )[ 0 ][:, 0 ,:] # use CLS representation as the embedding
all_embs . append ( cls_rep . cpu (). detach (). numpy ())
all_embs = np . concatenate ( all_embs , axis = 0 )Silakan lihat inferensi/inferensi_on_snomed.ipynb untuk contoh inferensi yang lebih luas.
Ekstrak data pelatihan dari UMLS sebagai insruntar di training_data/generate_pretraining_data.ipynb (kami tidak dapat secara langsung merilis file pelatihan karena masalah lisensi).
Berlari:
>> cd train/
>> ./pretrain.sh 0,1 di mana 0,1 menentukan perangkat GPU.
Untuk finetuning pada dataset khusus Anda, hasilkan data dalam format
concept_id || entity_name_1 || entity_name_2
...
di mana entity_name_1 dan entity_name_2 adalah pasangan sinonim (termasuk konsep yang sama concept_id ) yang diambil sampelnya dari dataset berlabel yang diberikan. Jika satu konsep dikaitkan dengan banyak nama entitas dalam dataset, Anda dapat melintasi semua kombinasi berpasangan.
Untuk sap-tuning lintas-bahasa dengan data paralel domain umum (Muse, judul wiki, atau keduanya), data dapat ditemukan di training_data/general_domain_parallel_data/ . Contoh skrip: train/xling_train.sh .
Untuk evaluasi (baik monlingual dan cross-lingual), silakan lihat evaluation/README.md untuk detailnya. evaluation/xl_bel/ berisi tolok ukur XL-Bel yang diusulkan dalam [Liu et al., ACL 2021].
Sapbert:
@inproceedings { liu2021self ,
title = { Self-Alignment Pretraining for Biomedical Entity Representations } ,
author = { Liu, Fangyu and Shareghi, Ehsan and Meng, Zaiqiao and Basaldella, Marco and Collier, Nigel } ,
booktitle = { Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies } ,
pages = { 4228--4238 } ,
month = jun,
year = { 2021 }
}Cross-Lingual Sapbert dan XL-Bel:
@inproceedings { liu2021learning ,
title = { Learning Domain-Specialised Representations for Cross-Lingual Biomedical Entity Linking } ,
author = { Liu, Fangyu and Vuli{'c}, Ivan and Korhonen, Anna and Collier, Nigel } ,
booktitle = { Proceedings of ACL-IJCNLP 2021 } ,
pages = { 565--574 } ,
month = aug,
year = { 2021 }
}Bagian kode dimodifikasi dari Biosyn. Kami menghargai penulis karena membuat biosyn open-source.
Sapbert berlisensi MIT. Lihat file lisensi untuk detailnya.


