DiffDock Pocket
Additional Data
Diffdock-pocket adalah model docking all-atom yang beroperasi pada level saku. Ini mengimplementasikan difusi di atas sudut torsi rantai samping dan dioptimalkan untuk struktur yang dihasilkan secara komputasi. Dalam repositori ini, Anda akan menemukan kode untuk melatih model, menjalankan inferensi, visualisasi, dan bobot yang kami gunakan untuk mencapai angka yang disajikan dalam makalah. Repositori ini awalnya merupakan garpu dari Diffdock, sehingga beberapa perintah mungkin tampak akrab - tetapi telah diperpanjang, diadaptasi dan diubah di banyak tempat sehingga Anda tidak dapat mengharapkan kompatibilitas kedua program tersebut. Waspadai, dan jangan mencampur dua program ini!
Jika Anda menginginkan cara mudah untuk menjalankan inferensi, Anda dapat menggunakan antarmuka Huggingface di sini.
Jangan ragu untuk membuat masalah, atau PRS jika Anda memiliki masalah dengan repositori ini! Harap pertimbangkan kode etik.
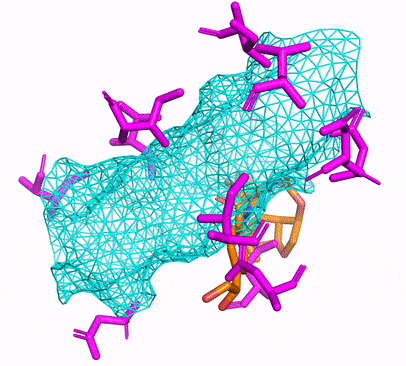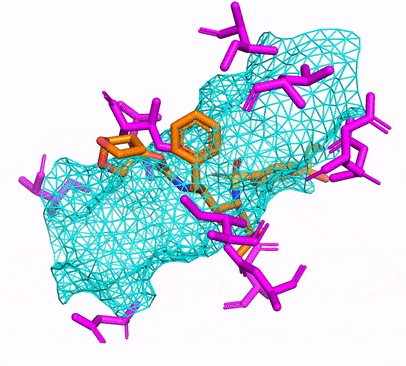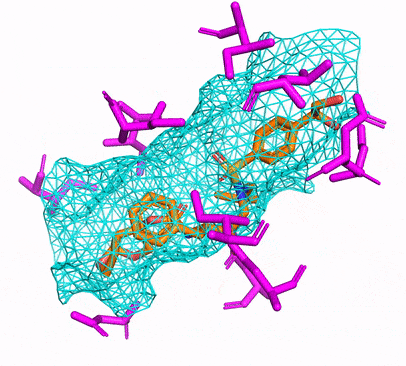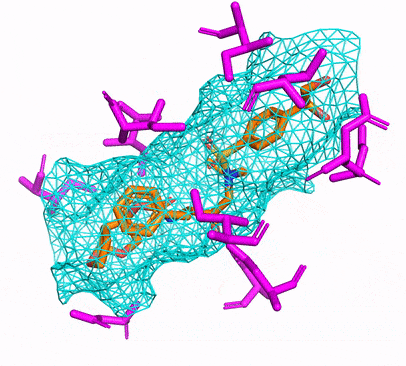
Anda dapat membuat lingkungan CPU atau CUDA CONDA hanya dengan berlari
conda env create -f environment[-cpu].yml
dengan, atau tanpa bendera CPU. Versi CUDA direkomendasikan, karena jauh lebih cepat.
Dalam contoh minimal ini, kami menggunakan 3dpf kompleks dan mengunci kembali ligan dengan Cahins sisi yang fleksibel. Kami menggambar 40 sampel, dan memberi peringkat mereka dengan model kepercayaan. Semua prediksi akan disimpan dalam results/ .
python inference.py --protein_path example_data/3dpf_protein.pdb --ligand example_data/3dpf_ligand.sdf --batch_size 20 --samples_per_complex 40 --keep_local_structures --save_visualisation
Di sini, kami menentukan bendera --keep_local_structures untuk tidak memodifikasi ligan. Dengan ini, saku dan rantai samping mana yang memodelkan fleksibel secara otomatis ditentukan.
Jika perintah ini kehabisan memori, Anda dapat mengurangi parameter --batch_size atau --samples_per_complex . Menurun --batch_size tidak akan memengaruhi kualitas hasil, tetapi akan meningkatkan runtime.
Perintah serupa untuk struktur yang dihasilkan secara komputasi adalah:
python inference.py --protein_path example_data/3dpf_protein_esm.pdb --ligand example_data/3dpf_ligand.sdf --batch_size 20 --samples_per_complex 40 --keep_local_structures --save_visualisation
Untuk melakukan minimalisasi energi pada pose ligan yang diprediksi top-1, Anda dapat menggunakan flag --relax .
Jika Anda tahu saku pengikat Anda dan rantai samping mana yang harus dimodelkan sebagai fleksibel, Anda dapat menentukannya. Dalam hal ini, Anda juga dapat menjatuhkan --keep_local_structures . Kami menyarankan menggunakan model yang disediakan kami hanya dengan asam amino fleksibel yang memiliki setidaknya satu atom berat dalam 3,5A dari setiap atom ligan berat. Ini mencegah data di luar distribusi.
python inference.py --protein_path example_data/3dpf_protein.pdb --ligand example_data/3dpf_ligand.sdf --batch_size 20 --samples_per_complex 40 --save_visualisation --pocket_center_x 9.7742 --pocket_center_y 27.2863 --pocket_center_z 14.6573 --flexible_sidechains A:160-A:193-A:197-A:198-A:222-A:224-A:227
Atau jika Anda tidak memiliki ligan, Anda juga dapat menggunakan representasi senyum.
--ligand [H]/N=C1/C(=O)C(=O)[C@@]1([H])[N@@+]1([H])C([H])([H])c2c([H])c(C([H])([H])N([H])C(=O)c3nc4sc5c(c4c(=O)n3[H])C([H])([H])C([H])([H])S(=O)(=O)C5([H])[H])c([H])c([H])c2C([H])([H])C1([H])[H]
Namun, dalam hal ini Anda harus menentukan pusat saku dan rantai samping yang fleksibel.
Jika Anda berurusan dengan beberapa kompleks, lihat data/protein_ligand_example_csv dengan bendera --protein_ligand_csv data/protein_ligand_example_csv.csv . Ini memungkinkan Anda untuk menentukan inferensi pada beberapa kompleks sekaligus, di mana Anda dapat menentukan pusat saku dan rantai samping yang fleksibel untuk setiap kompleks.
Saat memilih pusat saku, yang terbaik adalah menentukan asam amino yang dekat dengan situs pengikatan dan menghitung rata-rata koordinat c-alpha mereka. Dalam pelatihan kami, kami telah memilih semua asam amino di mana atom c-alpha mereka berada dalam 5A dari setiap atom berat dari ligan.
Kami menggunakan PDBBind yang dapat Anda unduh dari banyak sumber. Namun, kami juga menyediakan dataset PDBBind yang telah diproses di sini yang dapat Anda bongkar dengan unzip . Semua protein telah difiksasi dengan PDBFixer dan disejajarkan untuk meminimalkan RMSD di saku. Bongkar ke data/PDBBIND_atomCorrected .
Latih model skor besar:
python -m train --run_name big_score_model --test_sigma_intervals --log_dir workdir --lr 1e-3 --tr_sigma_min 0.1 --tr_sigma_max 5 --rot_sigma_min 0.03 --rot_sigma_max 1.55 --tor_sigma_min 0.03 --sidechain_tor_sigma_min 0.03 --batch_size 16 --ns 60 --nv 10 --num_conv_layers 6 --distance_embed_dim 64 --cross_distance_embed_dim 64 --sigma_embed_dim 64 --dynamic_max_cross --scheduler plateau --scale_by_sigma --dropout 0.1 --sampling_alpha 1 --sampling_beta 1 --remove_hs --c_alpha_max_neighbors 24 --atom_max_neighbors 8 --receptor_radius 15 --num_dataloader_workers 1 --cudnn_benchmark --rot_alpha 1 --rot_beta 1 --tor_alpha 1 --tor_beta 1 --val_inference_freq 5 --use_ema --scheduler_patience 30 --n_epochs 750 --all_atom --sh_lmax 1 --split_train data/splits/timesplit_no_lig_overlap_train --split_val data/splits/timesplit_no_lig_overlap_val_aligned --pocket_reduction --pocket_buffer 10 --flexible_sidechains --flexdist 3.5 --flexdist_distance_metric prism --protein_file protein_esmfold_aligned_tr_fix --compare_true_protein --conformer_match_sidechains --conformer_match_score exp --match_max_rmsd 2 --use_original_conformer_fallback --use_original_conformer
Bobot model disimpan di direktori workdir dan dapat digunakan untuk inferensi.
Untuk melatih model kepercayaan, Anda dapat menggunakan model skor yang sebelumnya terlatih untuk menghasilkan sampel. Namun, kami memilih untuk melatih model skor lain (lebih kecil) dengan terjemahan ligan maksimum yang lebih tinggi, sehingga model kepercayaan melihat sampel yang lebih beragam dan data pelatihan dapat diproduksi lebih cepat.
Untuk melatih model skor yang lebih kecil ini dengan terjemahan maksimum yang lebih tinggi, jalankan yang berikut:
python -m train --run_name small_score_model --test_sigma_intervals --esm_embeddings_path data/esm2_3billion_embeddings.pt --cache_path data/cache --log_dir workdir --lr 1e-3 --tr_sigma_min 0.1 --tr_sigma_max 15 --rot_sigma_min 0.03 --rot_sigma_max 1.55 --tor_sigma_min 0.03 --sidechain_tor_sigma_min 0.03 --batch_size 16 --ns 32 --nv 6 --num_conv_layers 5 --dynamic_max_cross --scheduler plateau --scale_by_sigma --dropout 0.1 --sampling_alpha 1 --sampling_beta 1 --remove_hs --c_alpha_max_neighbors 24 --atom_max_neighbors 12 --receptor_radius 15 --num_dataloader_workers 1 --cudnn_benchmark --rot_alpha 1 --rot_beta 1 --tor_alpha 1 --tor_beta 1 --val_inference_freq 5 --use_ema --scheduler_patience 30 --n_epochs 500 --all_atom --sh_lmax 1 --split_train data/splits/timesplit_no_lig_overlap_train --split_val data/splits/timesplit_no_lig_overlap_val_aligned --pocket_reduction --pocket_buffer 10 --flexible_sidechains --flexdist 3.5 --flexdist_distance_metric prism --protein_file protein_esmfold_aligned_tr_fix --compare_true_protein --conformer_match_sidechains --conformer_match_score exp --match_max_rmsd 2 --use_original_conformer_fallback --use_original_conformer
Model skor yang digunakan untuk menghasilkan sampel untuk melatih model kepercayaan tidak harus sama dengan model skor yang digunakan dengan model kepercayaan selama inferensi.
Latih model kepercayaan diri dengan menjalankan yang berikut:
python -m filtering.filtering_train --run_name confidence_model --original_model_dir workdir/small_score_model --ckpt best_ema_inference_epoch_model.pt --inference_steps 20 --samples_per_complex 7 --batch_size 16 --n_epochs 100 --lr 3e-4 --scheduler_patience 50 --ns 24 --nv 6 --num_conv_layers 5 --dynamic_max_cross --scale_by_sigma --dropout 0.1 --all_atoms --sh_lmax 1 --split_train data/splits/timesplit_no_lig_overlap_train --split_val data/splits/timesplit_no_lig_overlap_val_aligned --log_dir workdir --cache_path .cache/data_filtering data/PDBBIND_atomCorrected --remove_hs --c_alpha_max_neighbors 24 --receptor_radius 15 --esm_embeddings_path data/esm2_3billion_embeddings.pt --main_metric loss --main_metric_goal min --best_model_save_frequency 5 --rmsd_classification_cutoff 2 --sc_rmsd_classification_cutoff 1 --protein_file protein_esmfold_aligned_tr_fix --use_original_model_cache --pocket_reduction --pocket_buffer 10 --cache_creation_id 1 --cache_ids_to_combine 1 2 3 4
Pertama dengan --cache_creation_id 1 lalu --cache_creation_id 2 dll. Hingga 4
Sekarang semuanya dilatih dan Anda dapat menjalankan inferensi dengan model baru Anda :).
Jika Anda menggunakan diffdock-pocket dalam penelitian Anda, silakan kutip makalah berikut:
@article{plainer2023diffdockpocket,
author = {Plainer, Michael and Toth, Marcella and Dobers, Simon and St{"a}rk, Hannes and Corso, Gabriele and Marquet, C{'e}line and Barzilay, Regina},
title = {{DiffDock-Pocket}: Diffusion for Pocket-Level Docking with Sidechain Flexibility},
year = {2023},
maintitle = {Advances in Neural Information Processing Systems},
booktitle = {Machine Learning in Structural Biology},
}
Terima kasih @jsilter karena membuat kode ini lebih mudah digunakan dan untuk membuat antarmuka HuggingFace!


