MedLlama QA Advanced Medical Question Answering with Llama 2 7b and RAG
1.0.0
Explorez Medllama-QA, un système de réponse à des questions médicales de pointe propulsé par LLAMA-2-7B. Tirant parti de la génération augmentée (RAG) de récupération et des intérêts avancés, ce référentiel fournit des réponses précises et contextuellement précises, réduisant les hallucinations. Avec une pile technologique robuste comprenant un minimale, un étal, un pince et un sagemaker, Medllama-QA atteint une précision et une pertinence accrue dans la QA médical, présentant des performances supérieures par rapport aux modèles de langage standard.
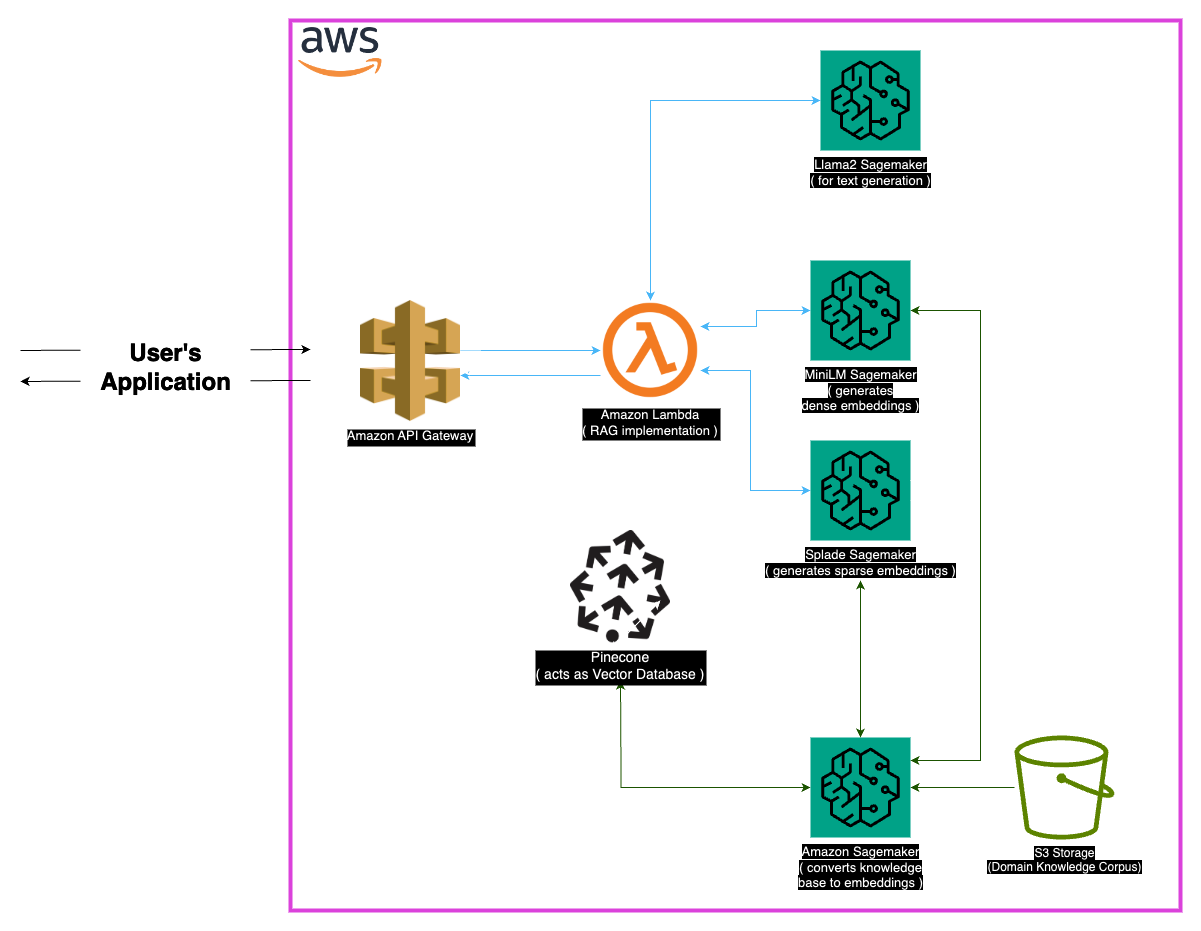
Le domaine médical exige une précision dans les systèmes de réponse aux questions, et ce référentiel présente une solution sophistiquée tirant parti du modèle LLAMA-2-7B. Grâce à l'approche de génération augmentée (RAG) de récupération, ce système intègre une base de connaissances médicale organisée avec LLAMA-2-7B, garantissant des réponses contextuellement et médicalement précises. En utilisant des intérêts et la puissance de calcul de Sagemaker et Pinecone, ce modèle relève les défis des modèles de gros langues, promettant des hallucinations réduites et des réponses précises et pertinentes.
L'ensemble de données «PubMed» sert de vaste réservoir de connaissances médicales. Étant donné les limites des tailles de fenêtre du modèle, une stratégie de section décompose les grands ensembles de données de texte en parties gérables, permettant au modèle de traiter et de comprendre efficacement les informations contextuelles.
Incorporer
Des intérêts denses (minims) : les représentations compactes des données de texte, générées à partir de minimm, fournissent des vecteurs de taille fixe pour chaque morceau de texte, garantissant l'uniformité. Ces intérêts capturent les informations essentielles à partir de textes médicaux, permettant au modèle de comprendre et de traiter efficacement les données d'entrée.
Les incorporations clairsemées (volume) : caractérisées par des vecteurs de haute dimension avec des valeurs principalement zéro, les intérêts clairsemés de Salle capturent des relations nuancées dans les données. Cette approche permet au modèle de capturer des détails complexes dans les textes médicaux, améliorant sa capacité à fournir des réponses précises et contextuellement pertinentes.
Magasin vectoriel
Le cœur de l'approche de génération augmentée (RAG) de récupération réside dans le magasin vectoriel, qui joue un rôle crucial dans le stockage des intérêts et la facilitation des récupérations rapides. Pinecone, choisi pour son optimisation dans la gestion et l'interrogation des vecteurs de haute dimension, fait partie intégrante de l'efficacité de l'approche RAG. L'efficacité de Pinecone garantit des recherches de similitudes rapides et permet au modèle de récupérer rapidement un contenu sémantique.
Huggingface : tirant parti des capacités de la bibliothèque HuggingFace pour la gestion et les modèles de langage affinés, ce projet bénéficie d'une multitude de modèles prélevés, notamment LLAMA-2-7B.
Pinecone : L'utilisation de Pinecone comme indice de vecteur garantit un stockage, une gestion et une interrogation efficaces de vecteurs de haute dimension représentant des données textuelles. Ses capacités sont essentielles pour soutenir l'approche des chiffons.
Sagemaker : Les prouesses informatiques de Sagemaker sont exploitées pour des tâches telles que la génération d'intégration, la récupération et le développement global du modèle. Sagemaker fournit un environnement transparent pour le déploiement et la gestion des modèles d'apprentissage automatique à grande échelle.
LLAMA2 : Le modèle LLAMA-2, développé par Meta AI, constitue la base de ce projet. LLAMA-2-7B, avec sa grande taille de paramètre, sert de modèle génératif principal pour le réponses de questions médicales.
Récupération de génération augmentée (RAG) : cette approche innovante combine la connaissance inhérente du lama-2-7b avec une base de connaissances médicale organisée. L'intégration d'incorporation dense et clairsemée, ainsi que du poireau pour une récupération efficace, assure des réponses précises, pertinentes et non hallucinées.
Compte tenu de la nature étendue des données médicales, certains cas de bord peuvent survenir. Il est essentiel de gérer les requêtes qui tombent en dehors des données de formation du modèle pour garantir des réponses précises. De plus, le système doit être suffisamment robuste pour gérer les requêtes ambiguës et fournir des sorties significatives.
Bien que la mise en œuvre actuelle soit robuste, il y a toujours de la place pour l'amélioration. Les améliorations possibles incluent le raffinement de la stratégie de section pour une meilleure compréhension contextuelle et l'exploration d'intégsing supplémentaires pour améliorer les performances. Des recherches en cours sur le traitement médical de texte et les progrès des modèles de langues peuvent être incorporées pour améliorer encore les capacités du système.
Assurez-vous que les dépendances suivantes sont installées:
Suivez ces étapes pour utiliser le système:
Installez les dépendances.
MedLlama-QA.ipynb Le système présente une précision améliorée et une réduction des hallucinations par rapport aux modèles de langage standard. Des réponses précises et pertinentes sont générées par l'approche RAG, ce qui en fait un outil précieux dans la réponse aux questions médicales.
Ce projet est autorisé sous la licence du MIT.
Pour toute demande, veuillez me contacter à [[email protected]].
Un merci spécial aux développeurs de Meta AI pour leurs contributions à la famille Llama 2 de modèles de grande langue. Ce projet s'appuie sur leur travail, visant à contribuer au développement responsable des modèles linguistiques dans le domaine médical.


