MedLlama QA Advanced Medical Question Answering with Llama 2 7b and RAG
1.0.0
Explore Medllama-Qa, ein modernes medizinisches Fragen-Answer-System, das von Lama-2-7b angetrieben wird. Das Repository für die Erhöhung der Abruf Augmented Generation (RAG) und fortgeschrittene Einbettungen liefert präzise, kontextuell genaue Antworten und reduziert Halluzinationen. Mit einem robusten Tech-Stack wie Minilm, Splade, Pinecone und Sagemaker erzielt Medllama-QA eine verbesserte Genauigkeit und Relevanz in der medizinischen QA und zeigt im Vergleich zu Standardsprachmodellen eine überlegene Leistung.
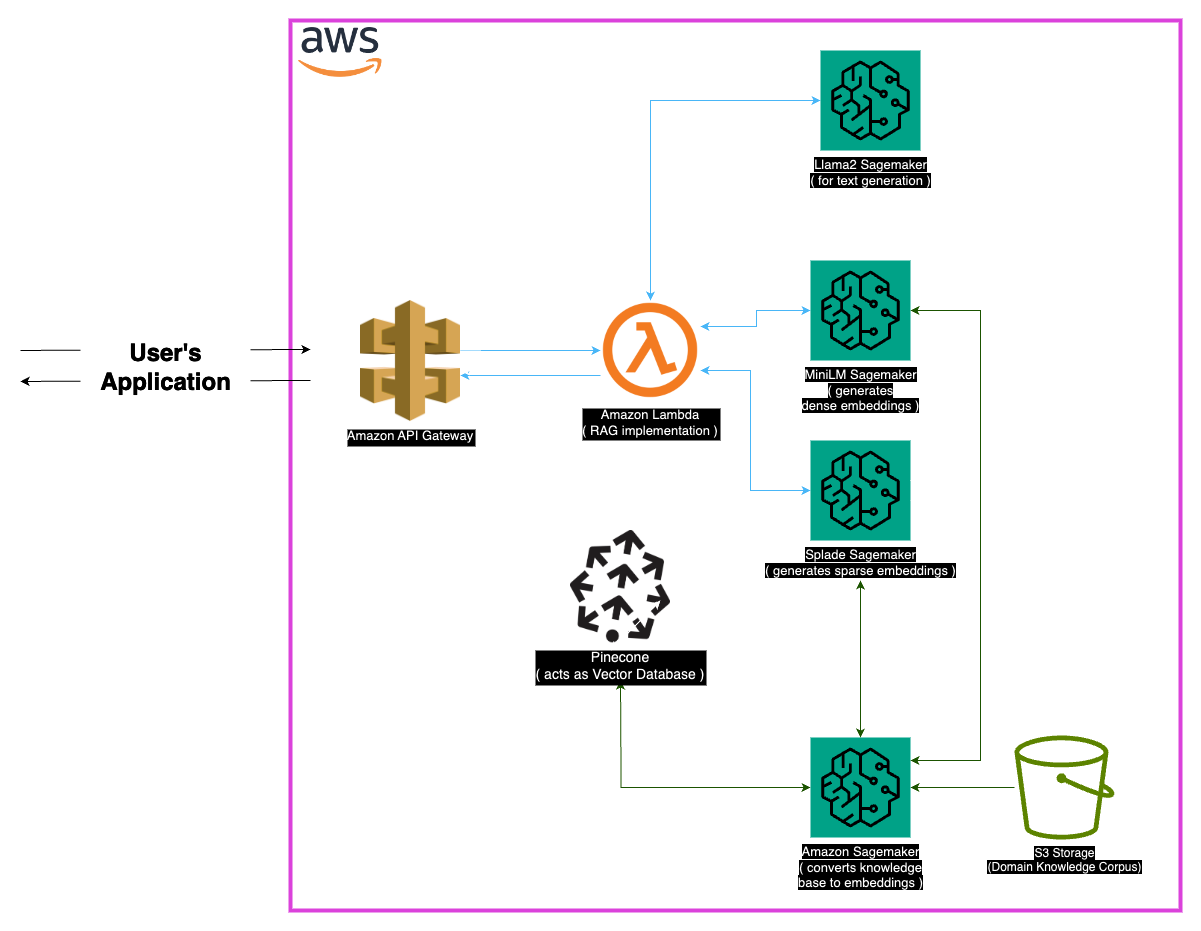
Das medizinische Feld erfordert Präzision in Frage-Anlern-Systemen, und dieses Repository präsentiert eine ausgeklügelte Lösung, die das LLAMA-2-7B-Modell nutzt. Durch den Ansatz der Abruf Augmented Generation (RAG) integriert dieses System eine kuratierte medizinische Wissensbasis mit LLAMA-2-7B, um kontextuell und medizinisch genaue Antworten zu gewährleisten. Durch die Verwendung von Einbettungen und der Rechenleistung von Sagemaker und Pinecone befasst sich dieses Modell mit den Herausforderungen von großer Sprachmodellen und verspricht reduzierte Halluzinationen und präzise, relevante Antworten.
Der "PubMed" -Datensatz dient als riesiger Reservoir für medizinisches Wissen. Angesichts der Einschränkungen der Modellfenstergrößen unterteilt eine Chunking -Strategie die großen Textdatensätze in verwaltbare Teile, sodass das Modell Kontextinformationen effektiv verarbeiten und verstehen kann.
Einbettungen
Dichte Einbettungen (MINILM) : Kompakte Darstellungen von Textdaten, die aus Minilm erzeugt werden, liefern Fixiergrößen Vektoren für jedes Textstück und gewährleisten einheitlich. Diese Einbettungen erfassen wesentliche Informationen aus medizinischen Texten und ermöglichen es dem Modell, Daten effektiv zu verstehen und zu verarbeiten.
Spärdliche Einbettungen (Splade) : gekennzeichnet durch hochdimensionale Vektoren mit hauptsächlich Nullwerten, erfassen die spärlichen Einbettungen von Splade nuancierte Beziehungen in den Daten. Dieser Ansatz ermöglicht es dem Modell, komplizierte Details in medizinischen Texten zu erfassen und seine Fähigkeit zu verbessern, genaue und kontextbezogene Antworten zu geben.
Vektor Store
Der Kern des Ansatzes der Abruf Augmented Generation (RAG) liegt im Vektor Store, der eine entscheidende Rolle bei der Speicherung von Einbettungen und der Erleichterung von schnellen Abrufen spielt. Pinecone, die für seine Optimierung bei der Verwaltung und Abfrage hochdimensionaler Vektoren ausgewählt wurde, ist ein wesentlicher Bestandteil der Wirksamkeit des Lag-Ansatzes. Die Effizienz von Pinecone sorgt für eine schnelle Ähnlichkeitssuche und ermöglicht es dem Modell, den semantisch verwandten Inhalt schnell abzurufen.
Harmingface : Nutzung der Funktionen der Huggingface-Bibliothek für die Verwaltung und Feinabstimmung von Sprachmodellen profitiert von einer Fülle von vorgeborenen Modellen, einschließlich Lama-2-7b.
Pinecone : Die Verwendung von Pinecone als Vektorindex sorgt für eine effiziente Speicherung, Verwaltung und Abfrage hochdimensionaler Vektoren, die Textdaten darstellen. Seine Fähigkeiten sind zentral, um den Lag -Ansatz zu unterstützen.
SAGEMAKER : Die rechnergestützte Fähigkeiten des Sagemakers werden für Aufgaben wie die Einbettung von Erzeugung, Abruf und Gesamtmodellentwicklung genutzt. Sagemaker bietet eine nahtlose Umgebung für die Bereitstellung und Verwaltung von Modellen für maschinelles Lernen im Maßstab.
LLAMA2 : Das von Meta AI entwickelte LLAMA-2-Modell bildet die Grundlage dieses Projekts. LLAMA-2-7B dient mit seiner großen Parametergröße als primäres generatives Modell für medizinische Fragen.
Abruf Augmented Generation (RAG) : Dieser innovative Ansatz kombiniert das inhärente Wissen von LLAMA-2-7B mit einer kuratierten medizinischen Wissensbasis. Die Integration dichter und spärlicher Einbettungen sowie Pinecone für ein effizientes Abruf gewährleistet präzise, relevante und nicht halluzinierte Reaktionen.
In Anbetracht der umfangreichen Natur von medizinischen Daten können bestimmte Randfälle auftreten. Es ist wichtig, Abfragen zu behandeln, die außerhalb der Trainingsdaten des Modells fallen, um genaue Antworten zu gewährleisten. Darüber hinaus sollte das System robust genug sein, um mehrdeutige Abfragen zu bewältigen und aussagekräftige Ausgaben zu liefern.
Während die aktuelle Implementierung robust ist, gibt es immer Platz für die Verbesserung. Mögliche Verbesserungen umfassen die Verfeinerung der Chunking -Strategie für ein besseres kontextbezogenes Verständnis und die Erforschung zusätzlicher Einschreibungen für eine verbesserte Leistung. Die laufenden Forschung in der medizinischen Textverarbeitung und der Fortschritte in Sprachmodellen können integriert werden, um die Funktionen des Systems weiter zu verbessern.
Stellen Sie sicher, dass die folgenden Abhängigkeiten installiert sind:
Befolgen Sie diese Schritte, um das System zu verwenden:
Abhängigkeiten installieren.
MedLlama-QA.ipynb aus Das System zeigt eine verbesserte Genauigkeit und reduzierte Halluzinationen im Vergleich zu Standardsprachmodellen. Präzise und relevante Antworten werden durch den Lag-Ansatz generiert, was es zu einem wertvollen Instrument für medizinische Fragen macht.
Dieses Projekt ist unter der MIT -Lizenz lizenziert.
Für Anfragen kontaktieren Sie mich bitte unter [[email protected]].
Besonderer Dank geht an die Entwickler von Meta AI für ihre Beiträge zur Lama 2 -Familie von Großsprachmodellen. Dieses Projekt baut auf ihrer Arbeit auf und zielt darauf ab, zur verantwortungsbewussten Entwicklung von Sprachmodellen im medizinischen Bereich beizutragen.


