TutorKD
1.0.0
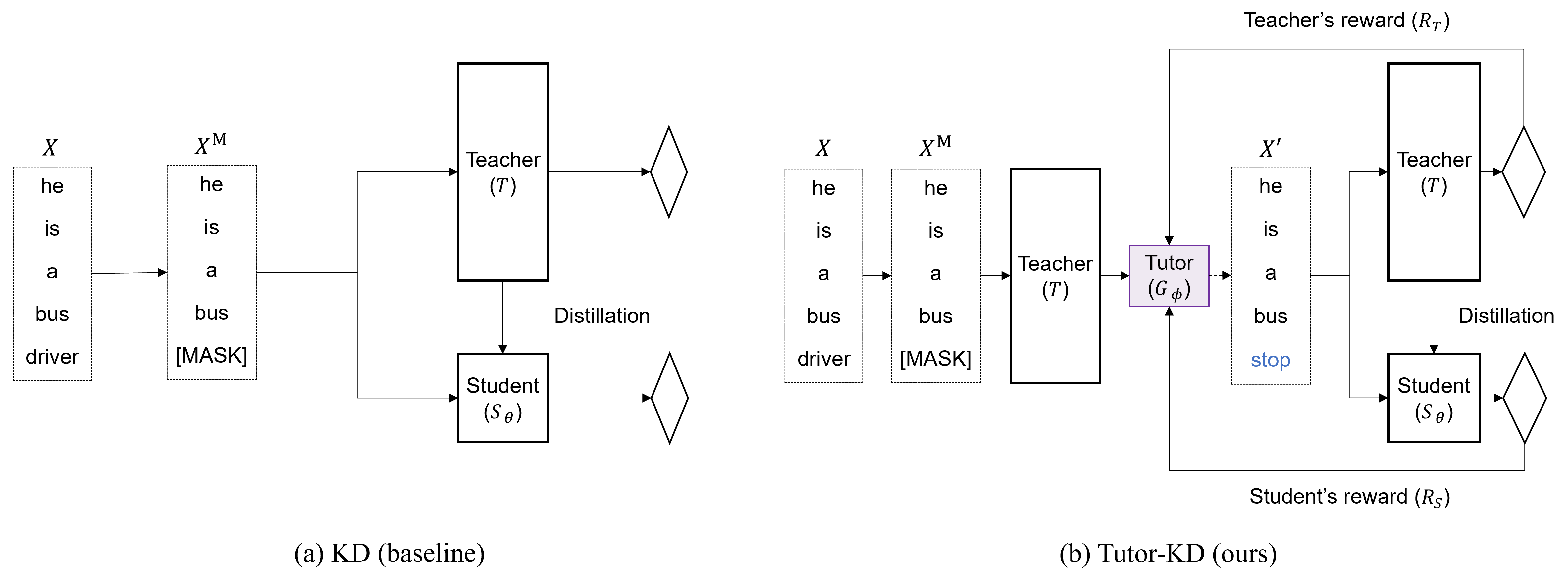
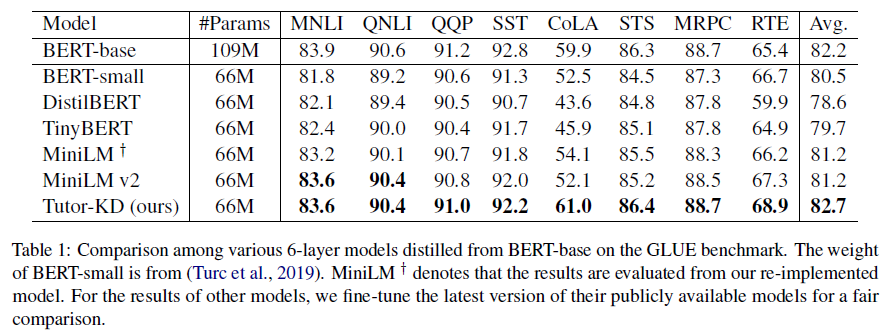
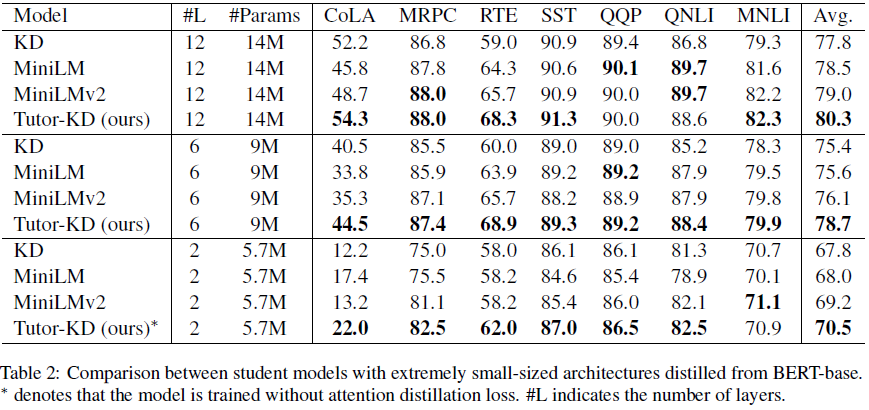
Ce référentiel concerne le document de tuteur-kd long: le tutorat aide les élèves à mieux apprendre: améliorer la distillation des connaissances pour Bert avec un réseau de tuteurs publié dans EMNLP 2022. Dans ce projet, nous sommes intéressés à générer des échantillons de transmission qui peuvent atténuer les prédictions incorrectes des enseignants et l'apprentissage répétitif pour les étudiants.
Préparez les corpus pré-formation (Wikipedia et BookCorpus) dans le dossier de données. Utilisez python preprocess.py .
--data_path : un répertoire contenant des exemples prétraités (fichier de cornichon).--raw_data_path : Un répertoire contenant des exemples de texte bruts. Enfin, utilisez python distillation.py pour la distillation.
--config : une architecture du modèle étudiant. Choisissez l'architecture du modèle parmi: Half, Extreme-12, ext-6, ext-2--lr : définissez le taux d'apprentissage.--epochs : définissez le nombre d'époches.--batch_size : Réglez la taille du lot pour la conduite en même temps.--step_batch_size : définissez la taille du lot pour la mise à jour par chaque étape (si la mémoire de GPU est suffisante, définissez le Batch_Size et Step_Batch_Size le même.--data_path : un répertoire contenant des exemples prétraités.--model_save_path : définissez le répertoire pour enregistrer le modèle étudiant Pour obtenir de l'aide ou des problèmes à l'aide de Tutor-KD, veuillez soumettre un problème GitHub.
Pour la communication personnelle liée à Tutor-KD, veuillez contacter Junho Kim <[email protected]> .


