voice dataset creation
1.0.0
Este repositorio describe los pasos y scripts necesarios para crear su propio conjunto de datos de texto a voz para capacitar a un modelo de voz. La salida final está en formato ljspeech.
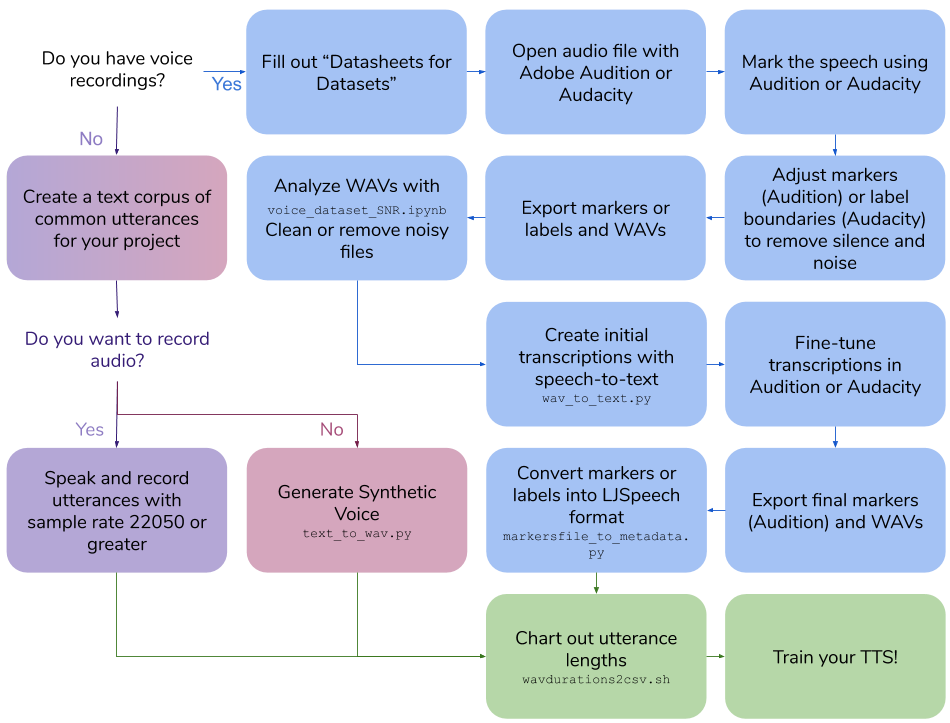
 Crea tus propias grabaciones de voz
Crea tus propias grabaciones de voz100|this is an example sentenceEjecute scripts/wavdurations2csv.sh para trazar la longitud de la oración y verifique que tenga una buena distribución de las longitudes de archivo WAV.
 Crear un conjunto de datos de voz sintético
Crear un conjunto de datos de voz sintéticoCloud API access scopes Seleccione Allow full access to all Cloud APIsCrear entorno de condena en la instancia de GCP
conda create -n tts python=3.7
conda activate tts
pip install google-cloud-texttospeech==2.1.0 tqdm pandas100|this is an example sentencepython text_to_wav.py tts_generateEjecute scripts/wavdurations2csv.sh para trazar la longitud de la oración y verifique que tenga una buena distribución de las longitudes de archivo WAV.
 Crear transcripciones para grabaciones de voz existentes
Crear transcripciones para grabaciones de voz existentesCloud API access scopes Seleccione Allow full access to all Cloud APIsCrear entorno de condena en la instancia de GCP
conda create -n stt python=3.7
conda activate stt
pip install google-cloud-speech tqdm pandasEn Adobe Audition , abra el archivo de audio:
Diagnostics -> Mark AudioMark the SpeechScanFind LevelsScan nuevamenteMark AllO, en audacia , abra el archivo de audio:
Analyze -> Sound FinderEn la audición :
Markers abiertosEn la audición :
En la audición :
Export Selected Markers to CSV y guardar como marcadores.csvPreferences -> Media & Disk Cache y desanimado Save Peak FilesExport Audio of Selected Range Markers con las siguientes opciones:Use marker names in filenamesWAV PCM22050 Hz Mono, 16-bitwavs_export de carpetasO, en audacia :
Export multiple...wavs_export de carpetasExport labels para Label Track.txt Para la audición , utilizando los Markers.csv exportados.csv y la carpeta WAVS ejecutada:
cd scripts
python wav_to_text.py audition El script genera un nuevo archivo, Markers_STT.csv .
Para Audacity , utilizando la Label Track.txt exportada.
cd scripts
python wav_to_text.py audacity El script genera un nuevo archivo, Label Track STT.csv .
Para la audición :
Import Markers from File y seleccione Archivo con Transcripciones STT: Markers_STT.CSVPara la audacia :
Label Track STT.txt en un editor de texto.Para la audición :
Export Selected Markers to CSV y guardar como marcadores.csvExport Audio of Selected Range Markers con las siguientes opciones:Use marker names in filenamesWAV PCM22050 Hz Mono, 16-bitwavs_export de carpetasPara la audacia :
Export multiple...wavs_export de carpetas Utilizando los Markers.csv exportados.csv (audición) o Label Track STT.txt (audacity) y wavs en wavs_export, scripts/markersfile_to_metadata.py creará un metadata.csv y una carpeta de wavs para entrenar su modelo TTS:
Para la audición :
python markersfile_to_metadata.py auditionPara la audacia :
python markersfile_to_metadata.py audacityEjecute scripts/wavdurations2csv.sh para trazar la longitud de la oración y verifique que tenga una buena distribución de las longitudes de archivo WAV.
ffmpeg: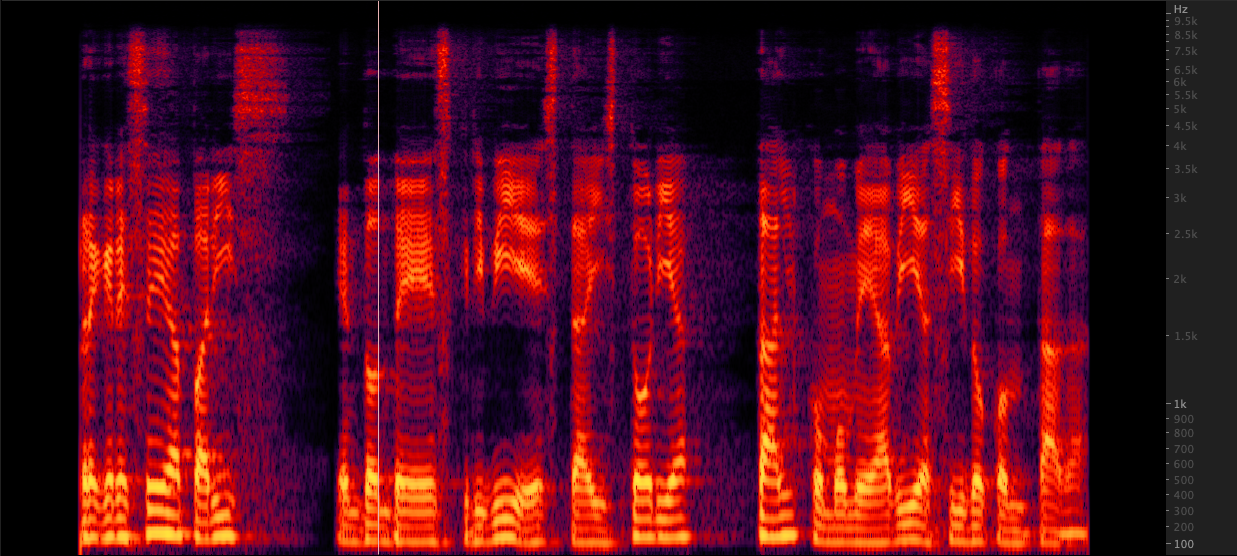 Renaming:
Renaming: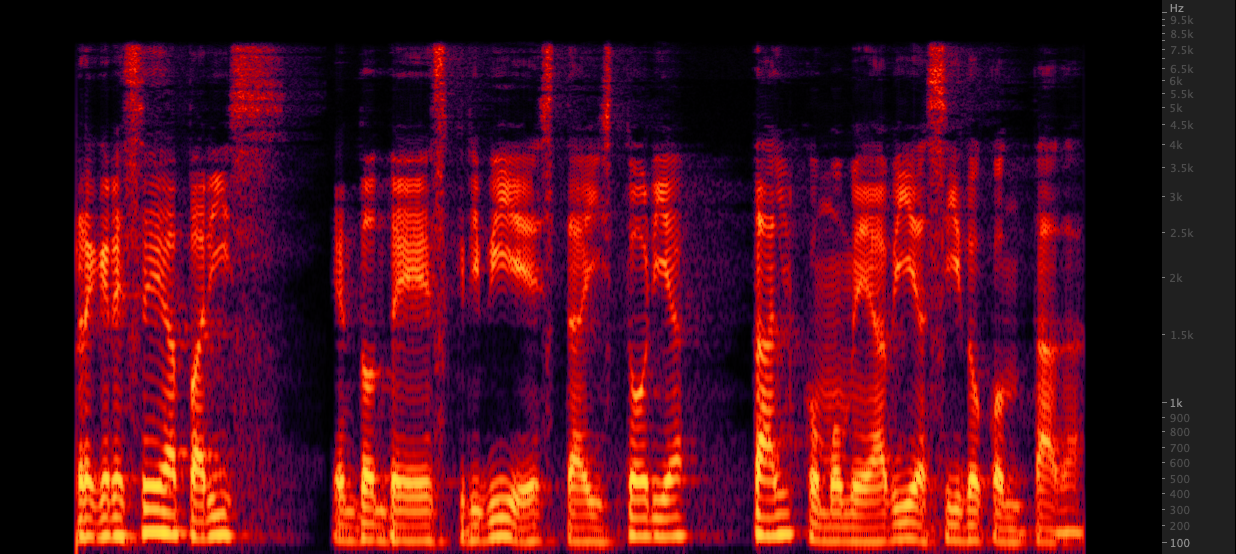 Probamos tres métodos para mejorar los archivos WAV de 16,000 a 22,050 Hz. Después de revisar los espectrogramas, seleccionamos FFMPEG para un muestreo ascendente, ya que incluye otros 2 kHz de información de alta gama en comparación con Renampy. scripts/resamplewav.sh
Probamos tres métodos para mejorar los archivos WAV de 16,000 a 22,050 Hz. Después de revisar los espectrogramas, seleccionamos FFMPEG para un muestreo ascendente, ya que incluye otros 2 kHz de información de alta gama en comparación con Renampy. scripts/resamplewav.sh
scripts/resamplewav.sh


