voice dataset creation
1.0.0
此回购概述了创建自己的文本到语音数据集所需的步骤和脚本,以训练语音模型。最终输出为ljspeech格式。
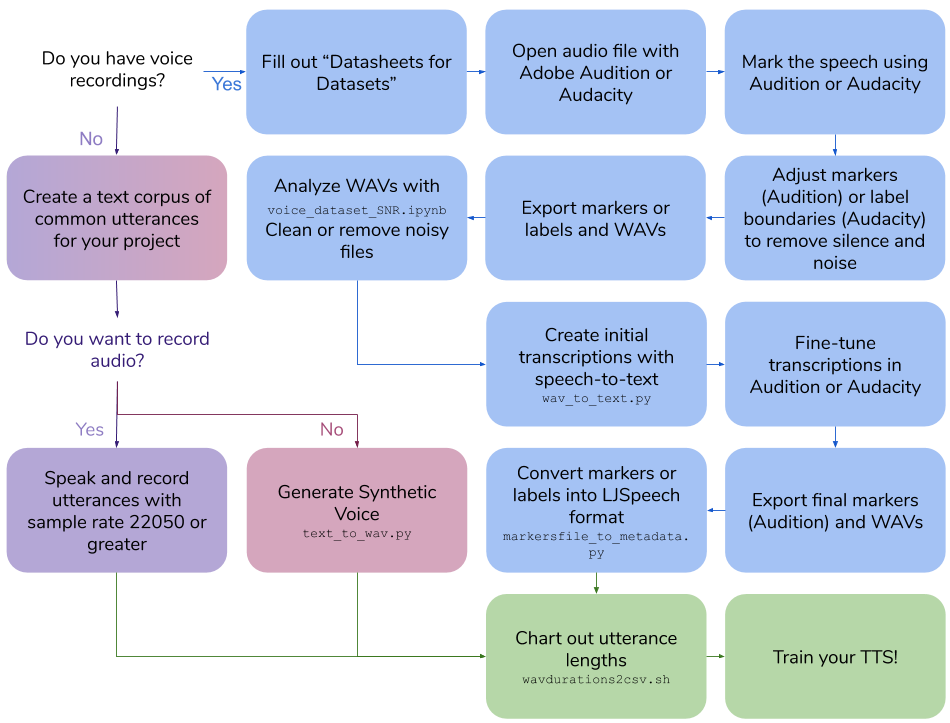
 创建自己的声音录音
创建自己的声音录音100|this is an example sentence运行脚本/wavdurations2csv.sh以绘制句子的长度并验证您对WAV文件长度的分布良好。
 创建一个合成语音数据集
创建一个合成语音数据集Cloud API access scopes选择Allow full access to all Cloud APIs在GCP实例上创建CONDA环境
conda create -n tts python=3.7
conda activate tts
pip install google-cloud-texttospeech==2.1.0 tqdm pandas100|this is an example sentencepython text_to_wav.py tts_generate运行脚本/wavdurations2csv.sh以绘制句子的长度并验证您对WAV文件长度的分布良好。
 为现有语音记录创建抄录
为现有语音记录创建抄录Cloud API access scopes选择Allow full access to all Cloud APIs在GCP实例上创建CONDA环境
conda create -n stt python=3.7
conda activate stt
pip install google-cloud-speech tqdm pandas在Adobe Audition中,打开音频文件:
Diagnostics - > Mark AudioMark the SpeechScanFind LevelsScanMark All或者,在Audacity中,打开音频文件:
Analyze - > Sound Finder在试镜中:
Markers选项卡在试镜中:
在试镜中:
Export Selected Markers to CSV并保存为标记。CSVPreferences - > Media & Disk Cache和Untick Save Peak FilesExport Audio of Selected Range Markers并具有以下选项:Use marker names in filenamesWAV PCM格式22050 Hz Mono, 16-bitwavs_export或者,大胆:
Export multiple...wavs_exportExport labels到Label Track.txt对于试镜,使用导出的Markers.csv和WAVS文件夹运行:
cd scripts
python wav_to_text.py audition该脚本生成一个新文件Markers_STT.csv 。
对于Audacity ,使用导出的Label Track.txt和Wavs文件夹运行:
cd scripts
python wav_to_text.py audacity该脚本生成一个新文件, Label Track STT.csv 。
试镜:
Import Markers from File ,然后选择使用stt转录的文件:markers_stt.csv大胆:
Label Track STT.txt 。试镜:
Export Selected Markers to CSV并保存为标记。CSVExport Audio of Selected Range Markers并具有以下选项:Use marker names in filenamesWAV PCM格式22050 Hz Mono, 16-bitwavs_export大胆:
Export multiple...wavs_export使用导出的Markers.csv (试听)或Label Track STT.txt (Audacity)和Wavs_export中的WAVS,脚本/MarkersFile_to_MetAdata.py将创建一个gerdata.csv和Wav的文件夹和WAV文件夹,以训练您的TTS模型:
试镜:
python markersfile_to_metadata.py audition大胆:
python markersfile_to_metadata.py audacity运行脚本/wavdurations2csv.sh以绘制句子的长度并验证您对WAV文件长度的分布良好。
FFMPEG: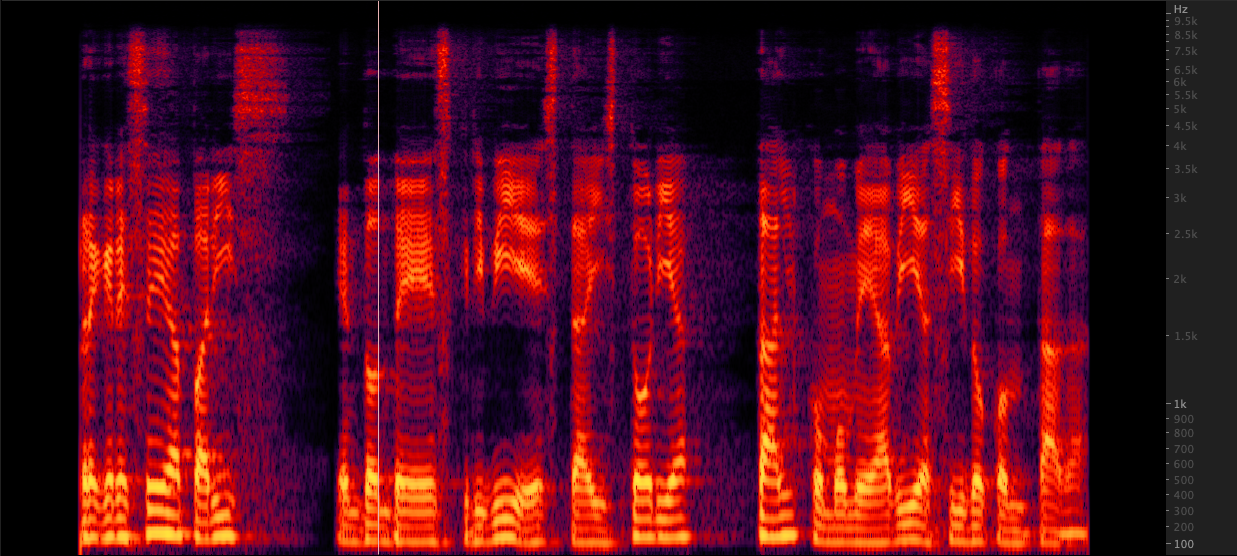 复活:
复活: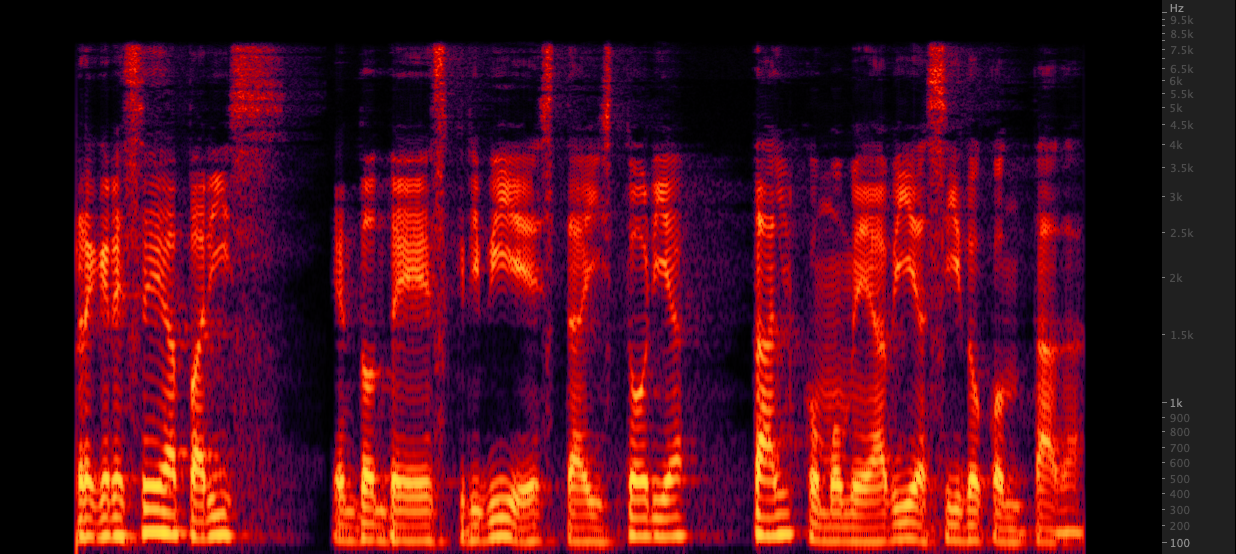 我们测试了三种方法将WAV文件从16,000到22,050 Hz。在审查了频谱图后,我们选择了FFMPEG进行上采样,因为与复兴相比,它还包括另外2 kHz的高端信息。脚本/respamplewav.sh
我们测试了三种方法将WAV文件从16,000到22,050 Hz。在审查了频谱图后,我们选择了FFMPEG进行上采样,因为与复兴相比,它还包括另外2 kHz的高端信息。脚本/respamplewav.sh
scripts/resamplewav.sh


