voice dataset creation
1.0.0
이 repo는 음성 모델을 훈련시키는 데 자신만의 텍스트 음성 정보 데이터 세트를 작성하는 데 필요한 단계와 스크립트를 간략하게 설명합니다. 최종 출력은 ljspeech 형식입니다.
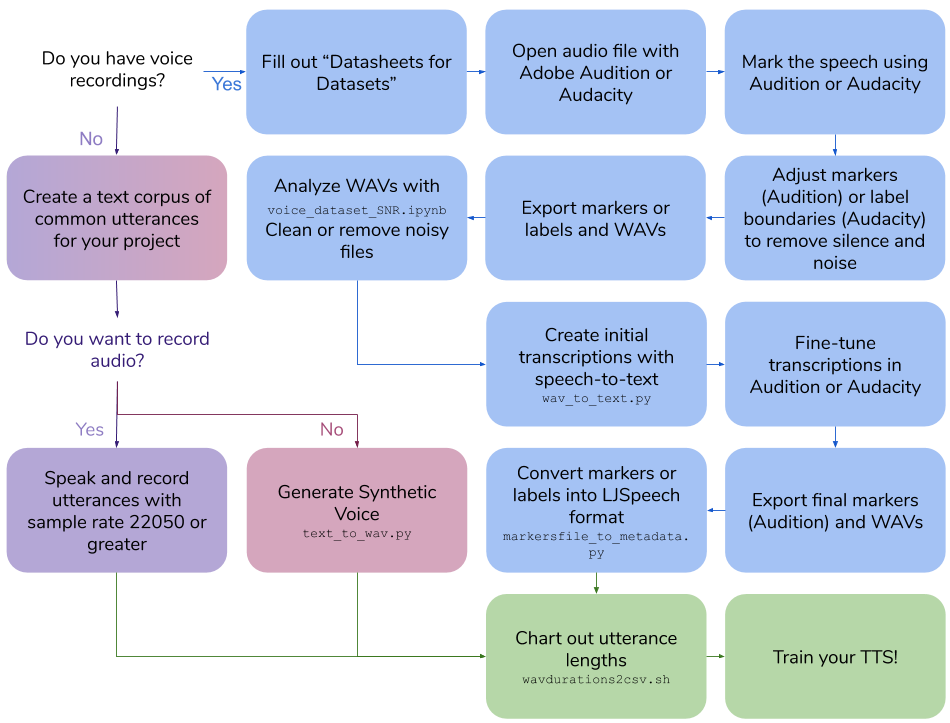
 나만의 음성 녹음을 만듭니다
나만의 음성 녹음을 만듭니다100|this is an example sentence스크립트/wavdurations2csv.sh를 실행하여 문장 길이를 차트로 작성하고 WAV 파일 길이가 양호한 지 확인하십시오.
 합성 음성 데이터 세트를 만듭니다
합성 음성 데이터 세트를 만듭니다Cloud API access scopes 선택 Allow full access to all Cloud APIsGCP 인스턴스에서 콘다 환경을 만듭니다
conda create -n tts python=3.7
conda activate tts
pip install google-cloud-texttospeech==2.1.0 tqdm pandas100|this is an example sentencepython text_to_wav.py tts_generate스크립트/wavdurations2csv.sh를 실행하여 문장 길이를 차트로 작성하고 WAV 파일 길이가 양호한 지 확인하십시오.
 기존 음성 녹음에 대한 전사를 만듭니다
기존 음성 녹음에 대한 전사를 만듭니다Cloud API access scopes 선택 Allow full access to all Cloud APIsGCP 인스턴스에서 콘다 환경을 만듭니다
conda create -n stt python=3.7
conda activate stt
pip install google-cloud-speech tqdm pandasAdobe Audition 에서 오디오 파일을 엽니 다.
Diagnostics -> Mark Audio 선택하십시오Mark the Speech 선택하십시오Scan 클릭하십시오Find Levels 클릭하십시오Scan 다시 클릭하십시오Mark All 클릭하십시오또는 Audacity 에서 오디오 파일을 엽니 다.
Analyze -> Sound Finder 선택하십시오오디션 에서 :
Markers 탭오디션 에서 :
오디션 에서 :
Export Selected Markers to CSV Markers.csv로 저장하십시오.Preferences 선택 -> Media & Disk Cache 및 Save Peak Files 해제합니다.Export Audio of Selected Range Markers 선택하십시오.Use marker names in filenames 확인하십시오WAV PCM 으로 형식을 업데이트하십시오22050 Hz Mono, 16-bit 업데이트wavs_export 를 사용하십시오또는 대담한 :
Export multiple...wavs_export 를 사용하십시오Label Track.txt 에 대한 Export labels 선택하십시오 오디션 의 경우 내보내기 Markers.csv 사용하여 CSV 및 WAVS 폴더가 실행됩니다.
cd scripts
python wav_to_text.py audition 스크립트는 새 파일 인 Markers_STT.csv 생성합니다.
Audacity 의 경우 내보내는 Label Track.txt 및 WAVS 폴더 실행 :
cd scripts
python wav_to_text.py audacity 스크립트는 새 파일, Label Track STT.csv 생성합니다.
오디션 용 :
Import Markers from File 선택하고 STT 전사가있는 파일을 선택하십시오 : Markers_stt.csv대담함 :
Label Track STT.txt 열 수 있습니다.오디션 용 :
Export Selected Markers to CSV Markers.csv로 저장하십시오.Export Audio of Selected Range Markers 선택하십시오.Use marker names in filenames 확인하십시오WAV PCM 으로 형식을 업데이트하십시오22050 Hz Mono, 16-bit 업데이트wavs_export 를 사용하십시오대담함 :
Export multiple...wavs_export 를 사용하십시오 내보내기 Markers.csv (오디션) 또는 Label Track STT.txt (Audacity) 및 Wavs_export의 Wavs를 사용하여 Scripts/Markersfile_to_metadata.py를 Metadata.csv 및 폴더를 만들어 TTS 모델을 훈련시킵니다.
오디션 용 :
python markersfile_to_metadata.py audition대담함 :
python markersfile_to_metadata.py audacity스크립트/wavdurations2csv.sh를 실행하여 문장 길이를 차트로 작성하고 WAV 파일 길이가 양호한 지 확인하십시오.
ffmpeg :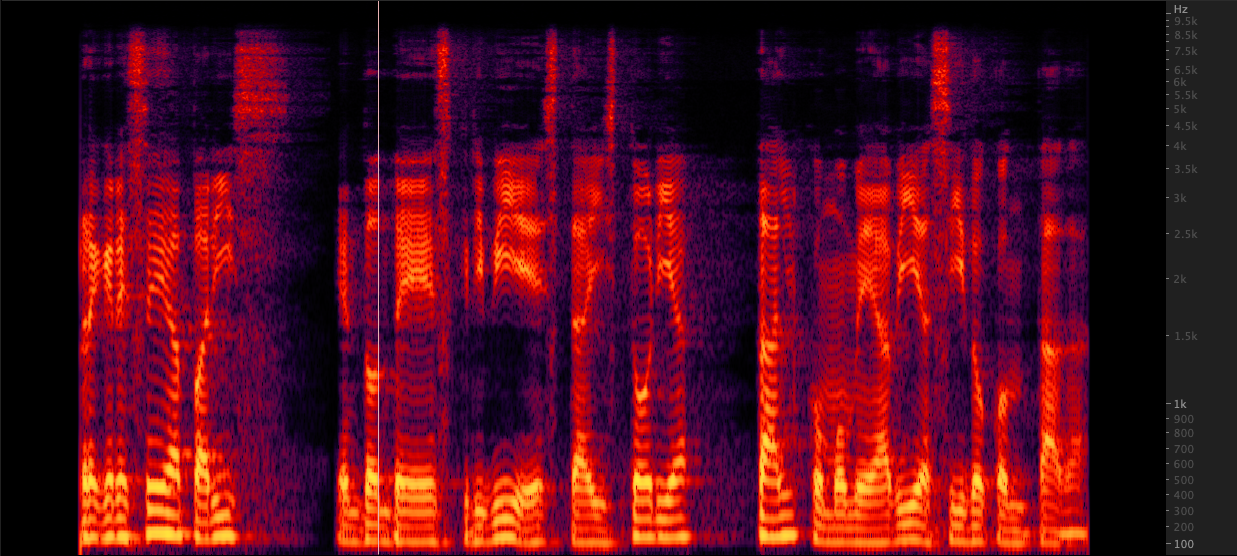 재판매 :
재판매 :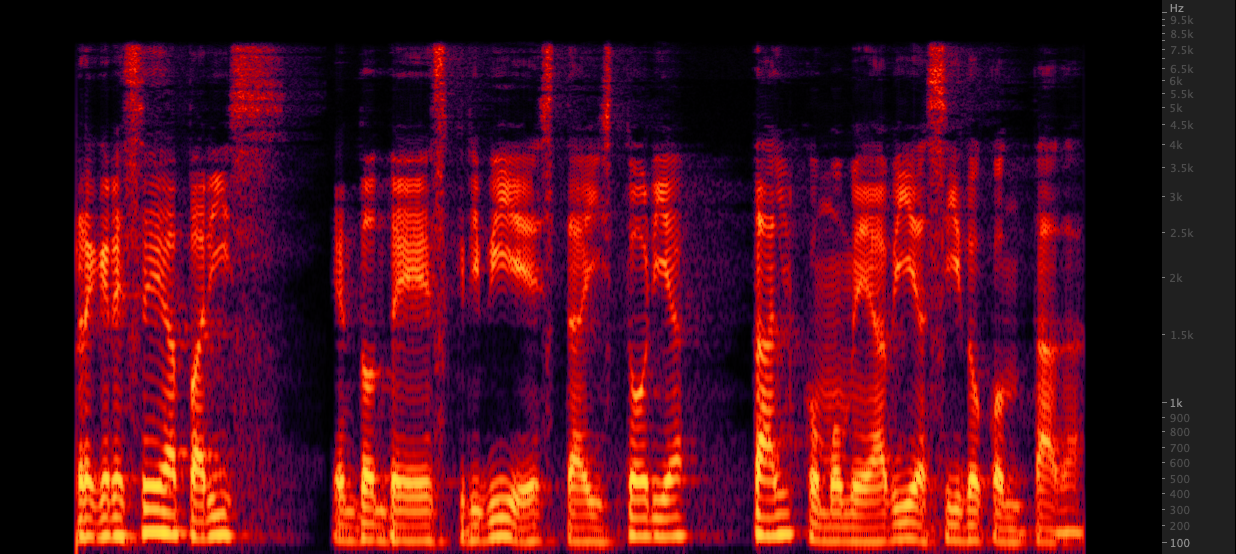 16,000에서 22,050 Hz의 파일을 상승시키기 위해 세 가지 방법을 테스트했습니다. 스펙트로 그램을 검토 한 후, 우리는 재 샘플과 비교할 때 2 kHz의 고급 정보를 포함하므로 Upsampling을 위해 FFMPEG를 선택했습니다. 스크립트/리 샘플 wav.sh
16,000에서 22,050 Hz의 파일을 상승시키기 위해 세 가지 방법을 테스트했습니다. 스펙트로 그램을 검토 한 후, 우리는 재 샘플과 비교할 때 2 kHz의 고급 정보를 포함하므로 Upsampling을 위해 FFMPEG를 선택했습니다. 스크립트/리 샘플 wav.sh
scripts/resamplewav.sh


