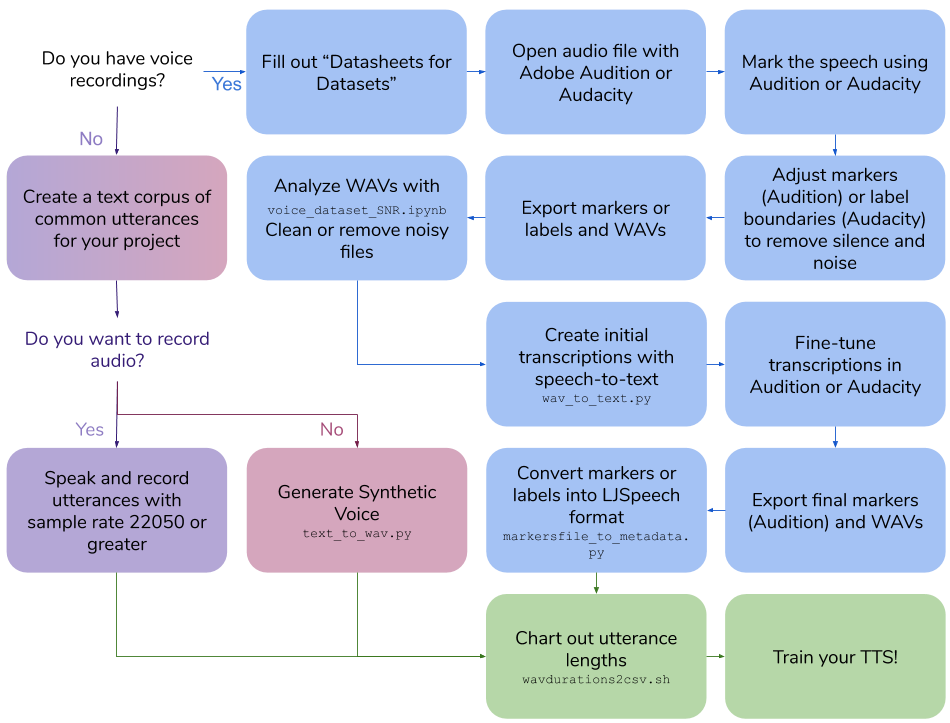
Sprachdatensatzerstellung
Dieses Repo beschreibt die Schritte und Skripte, die erforderlich sind, um Ihr eigenes Text-zu-Sprach-Datensatz für das Training eines Sprachmodells zu erstellen. Die endgültige Ausgabe erfolgt im LJspeech -Format.
Inhaltsverzeichnis
- Erstellen Sie Ihre eigenen Sprachaufnahmen
- Erstellen Sie einen synthetischen Sprachdatensatz
- Erstellen Sie Transkriptionen für vorhandene Sprachaufzeichnungen
- Andere Versorgungsunternehmen
 Erstellen Sie Ihre eigenen Sprachaufnahmen
Erstellen Sie Ihre eigenen Sprachaufnahmen
Anforderungen
- Sprachaufzeichnungssoftware
- Omni-Regisseur-Kopfmikrofon
- Hörkarte gute Qualität
Erstellen Sie einen Textkorpus von Sätzen
- Erstellen Sie Sätze, die etwa 3-10 Sekunden dauern, wenn sie gesprochen werden
- Verwenden Sie das LJspeech -Format
- "|" getrennte Werte, WAV -Datei -ID dann Satztext
-
100|this is an example sentence
Sätze sprechen und aufnehmen
- Sprechen Sie jeden Satz wie geschrieben
- Die Probenrate sollte 22050 oder höher sein
Satzlängen
Führen Sie Skripte/WavDurations2csv.sh aus, um die Satzlänge auszusagen und zu überprüfen, ob Sie eine gute Verteilung der WAV -Dateilängen haben.
 Erstellen Sie einen synthetischen Sprachdatensatz
Erstellen Sie einen synthetischen Sprachdatensatz
Anforderungen
- Google Cloud Platform Compute Engine -Instanz berechnen
-
Cloud API access scopes Wählen Sie Allow full access to all Cloud APIs
- Conda
Installation
Erstellen Sie die Conda -Umgebung in der GCP -Instanz
conda create -n tts python=3.7
conda activate tts
pip install google-cloud-texttospeech==2.1.0 tqdm pandas
Erstellen Sie einen Textkorpus von Sätzen
- Erstellen Sie Sätze, die etwa 3-10 Sekunden dauern, wenn sie gesprochen werden
- Verwenden Sie das LJspeech -Format
- "|" getrennte Werte, WAV -Datei -ID dann Satztext
-
100|this is an example sentence
Generieren Sie einen synthetischen Sprachdatensatz
-
python text_to_wav.py tts_generate
Satzlängen
Führen Sie Skripte/WavDurations2csv.sh aus, um die Satzlänge auszusagen und zu überprüfen, ob Sie eine gute Verteilung der WAV -Dateilängen haben.
 Erstellen Sie Transkriptionen für vorhandene Sprachaufzeichnungen
Erstellen Sie Transkriptionen für vorhandene Sprachaufzeichnungen
Anforderungen
- Adobe Audition oder Kühnheit
- Google Cloud Platform Compute Engine -Instanz berechnen
-
Cloud API access scopes Wählen Sie Allow full access to all Cloud APIs
- Conda
Installation
Erstellen Sie die Conda -Umgebung in der GCP -Instanz
conda create -n stt python=3.7
conda activate stt
pip install google-cloud-speech tqdm pandas
Füllen Sie ein Datenblatt für den Sprachdatensatz aus
- Überprüfen Sie Datenblätter für Datensätze von Gebru et al.: Https://arxiv.org/pdf/1803.09010.pdf
- Markdown-Datenblatt: https://github.com/jrmeyer/markdown-datasheet-for-datasets/blob/master/datasheet.md
Markieren Sie die Rede
Öffnen Sie in Adobe Audition die Audiodatei:
- Wählen Sie
Diagnostics -> Mark Audio - Wählen Sie die
Mark the Speech aus - Klicken Sie auf
Scan - Klicken Sie
Find Levels - Klicken Sie erneut auf
Scan - Klicken Sie
Mark All - Stellen Sie das Audio- und Stillesignal dB und die Länge ein, bis die Clips zwischen 3-10 Sekunden liegen
Oder in Audacity die Audiodatei öffnen:
- Wählen Sie
Analyze -> Sound Finder - Stellen Sie das Audio- und Stillesignal dB und die Länge ein, bis die Clips zwischen 3-10 Sekunden liegen
Stellen Sie Markierungen oder Etikettengrenzen ein
Im Vorsprechen :
- Registerkarte "
Markers öffnen - Stellen Sie Markierungen ein, entfernen Sie Stille und Rauschen, um die Cliplänge zwischen 3 und 10 Sekunden lang zu machen
Im Vorsprechen :
- Stellen Sie die Etikettengrenzen ein, entfernen Sie Stille und Rauschen, um die Cliplänge zwischen 3 und 10 Sekunden lang zu langen
Exportmarkierungen/Etiketten und Wellen
Im Vorsprechen :
- Wählen Sie alle Marker in der Liste aus
- Wählen Sie
Export Selected Markers to CSV und speichern Sie als Marker.CSV - Wählen Sie
Preferences aus -> Media & Disk Cache und Untick Save Peak Files - Wählen Sie mit den folgenden Optionen
Export Audio of Selected Range Markers :- Überprüfen Sie
Use marker names in filenames - Aktualisieren Sie das Format auf
WAV PCM - Aktualisieren Sie Beispieltyp
22050 Hz Mono, 16-bit - Verwenden Sie Ordner
wavs_export
Oder in Kühnheit :
- Wählen Sie
Export multiple...- Format: WAV
- Optionen: Signiert 16-Bit-PCM
- Dateien basierend auf Etiketten teilen
- Namensdateien mit dem Label-/Tracknamen Name
- Verwenden Sie Ordner
wavs_export
- Wählen Sie
Export labels zum Label Track.txt aus
Analysieren Sie WAVs mit Signal -Rausch -Verhältnis Colab
- Führen Sie Colabs/Voice_Dataset_Snr.ipynb aus
- Laute Dateien reinigen oder entfernen
Erstellen Sie erste Transkriptionen mit STT
Für das Audition unter Verwendung der exportierten Markers.csv und WAVS -Ordnerlauf:
cd scripts
python wav_to_text.py audition
Das Skript generiert eine neue Datei, Markers_STT.csv .
Für die Audacity verwenden Sie den exportierten Label Track.txt und WAVs -Ordner.
cd scripts
python wav_to_text.py audacity
Das Skript generiert eine neue Datei, Label Track STT.csv .
Feinabstimmungstranskriptionen
Für das Vorsprechen :
- Alle Marker löschen
- Wählen Sie
Import Markers from File und Datei mit STT -Transkriptionen auswählen: markers_stt.csv - Feines Feld Beschreibungsfeld in Markierungen, um genau mit den gesprochenen Wörtern übereinzustimmen
Für Kühnheit :
- Öffnen Sie
Label Track STT.txt in einem Texteditor. - Tunzieren Sie das Feld Etiketten in der Textdatei so, dass sie genau den gesprochenen Wörtern übereinstimmen
Exportmarkierungen (nur Vorsprechen) und WAVs
Für das Vorsprechen :
- Wählen Sie alle Marker in der Liste aus
- Wählen Sie
Export Selected Markers to CSV und speichern Sie als Marker.CSV - Wählen Sie mit den folgenden Optionen
Export Audio of Selected Range Markers :- Überprüfen Sie
Use marker names in filenames - Aktualisieren Sie das Format auf
WAV PCM - Aktualisieren Sie Beispieltyp
22050 Hz Mono, 16-bit - Verwenden Sie Ordner
wavs_export
Für Kühnheit :
- Wählen Sie
Export multiple...- Format: WAV
- Optionen: Signiert 16-Bit-PCM
- Dateien basierend auf Etiketten teilen
- Namensdateien mit dem Label-/Tracknamen Name
- Verwenden Sie Ordner
wavs_export
Umwandeln
Verwenden der exportierten Markers.csv (Audition) oder Label Track STT.txt (Audacity) und WAVs in WAVS_Export werden Skripte/MarkersFile_to_Metadata.py ein metadata.csv und einen Ordner von WAVs erstellt, um Ihr TTS -Modell zu trainieren:
Für das Vorsprechen :
python markersfile_to_metadata.py audition
Für Kühnheit :
python markersfile_to_metadata.py audacity
Satzlängen
Führen Sie Skripte/WavDurations2csv.sh aus, um die Satzlänge auszusagen und zu überprüfen, ob Sie eine gute Verteilung der WAV -Dateilängen haben.
Andere Versorgungsunternehmen
Upsample WAV -Datei
ffmpeg: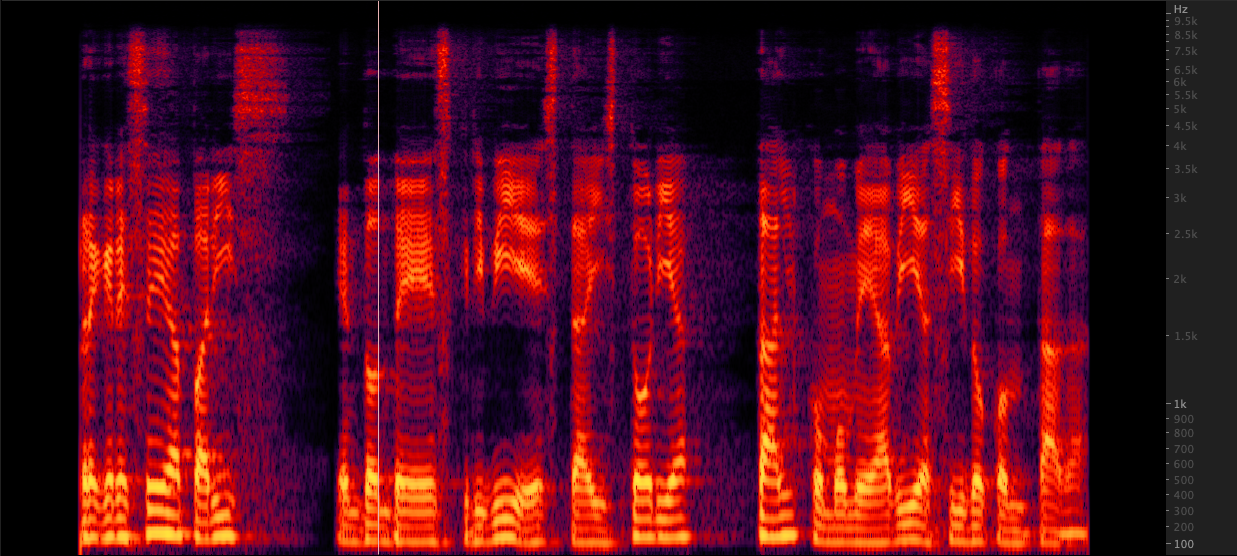 radeln:
radeln: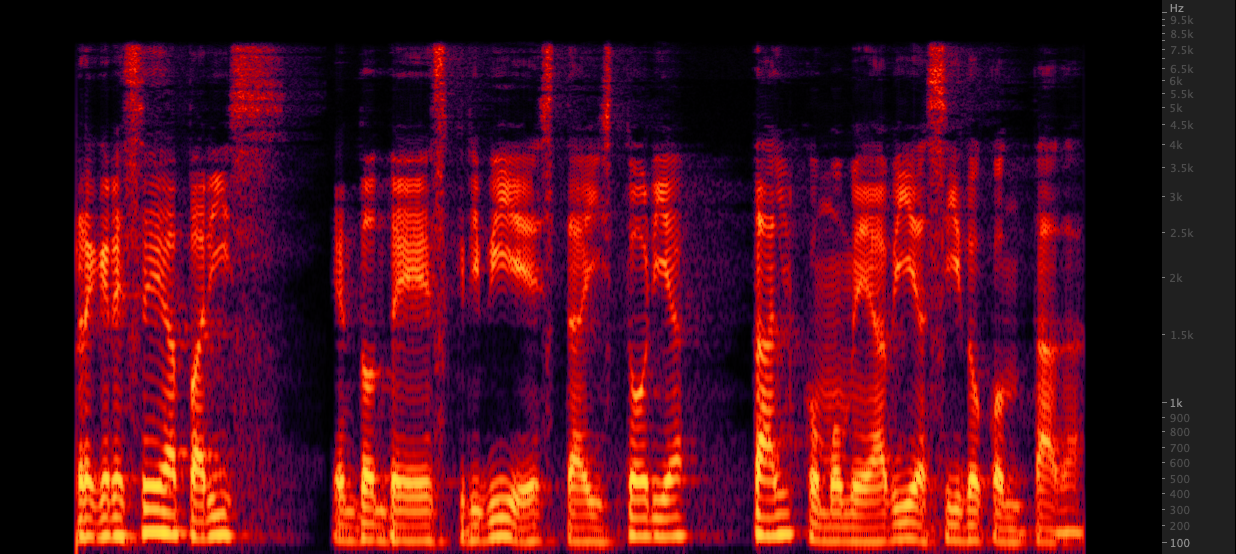 Wir haben drei Methoden getestet, um WAV -Dateien von 16.000 bis 22.050 Hz zu verbessern. Nach der Überprüfung der Spektrogramme haben wir FFMPEG zum Up -Sampling ausgewählt, da es im Vergleich zu Resamente weitere 2 kHz High -End -Informationen enthält. Skripte/resamplewav.sh
Wir haben drei Methoden getestet, um WAV -Dateien von 16.000 bis 22.050 Hz zu verbessern. Nach der Überprüfung der Spektrogramme haben wir FFMPEG zum Up -Sampling ausgewählt, da es im Vergleich zu Resamente weitere 2 kHz High -End -Informationen enthält. Skripte/resamplewav.sh
Referenzen
- Mozilla TTS: https://github.com/mozilla/tts
- Automatisierung der Ausrichtung, umfasst Segment-Audio zu Stille, Google-Sprach-API und Erkennungsausrichtung: https://github.com/carpedm20/multispeaker-tacotron-tensorflow#2-2-2-Generate-Korean-Datasetsetsetssätze
- Vorbereitungen auf großen synthetischen Korpussen und Feinabstimmung auf bestimmten https://twitter.com/garygarywang
- Datenblätter für Datensätze https://arxiv.org/abs/1803.0901010


