Création de l'ensemble de données vocal
Ce repo décrit les étapes et scripts nécessaires pour créer votre propre ensemble de données de texte vocal pour la formation d'un modèle vocal. La sortie finale est au format LJSpeech.
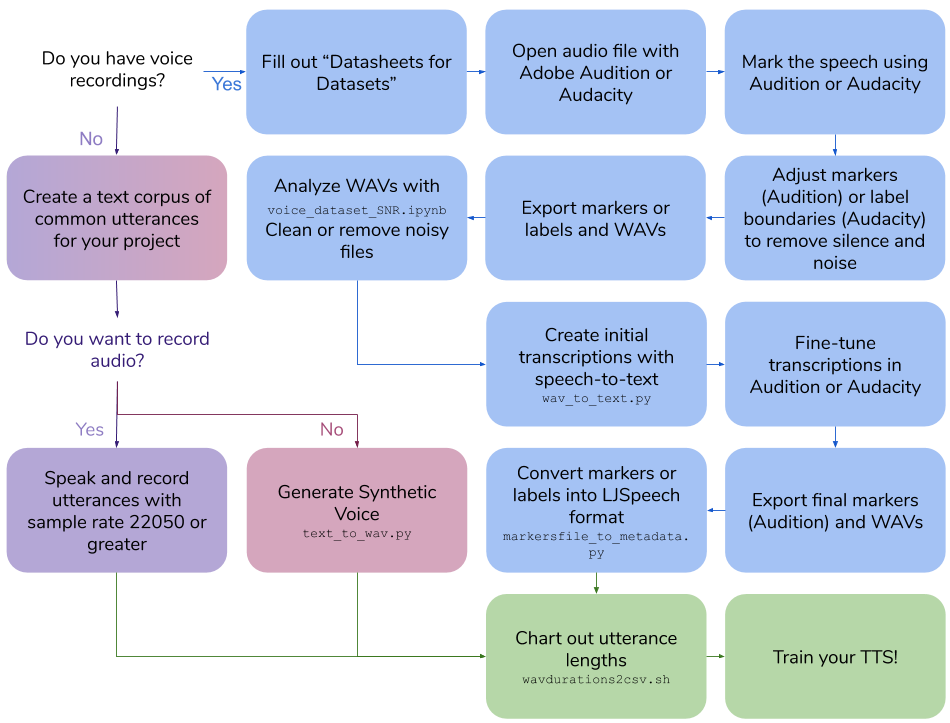
Table des matières
- Créez vos propres enregistrements vocaux
- Créer un ensemble de données vocales synthétiques
- Créer des transcriptions pour les enregistrements vocaux existants
- Autres services publics
 Créez vos propres enregistrements vocaux
Créez vos propres enregistrements vocaux
Exigences
- Logiciel d'enregistrement vocal
- Microphone monté sur la tête omnidirectionnel
- Carte audio de bonne qualité
Créer un corpus de phrases texte
- Créer des phrases qui seront environ 3 à 10 secondes lorsqu'elles seront parlées
- Utiliser le format LJSpeech
- "|" Valeurs séparées, ID de fichier WAV puis texte de la phrase
-
100|this is an example sentence
Parler et enregistrer des phrases
- Parlez chaque phrase comme écrit
- La fréquence d'échantillonnage doit être de 22050 ou plus
Durée de la phrase
Exécutez les scripts / wavdurations2csv.sh pour tracer la longueur de la phrase et vérifier que vous avez une bonne distribution des longueurs de fichiers WAV.
 Créer un ensemble de données vocales synthétiques
Créer un ensemble de données vocales synthétiques
Exigences
- Google Cloud Platform Calculer le moteur Instance
-
Cloud API access scopes SELECT Allow full access to all Cloud APIs
- Conda
Installation
Créer un environnement conda sur l'instance GCP
conda create -n tts python=3.7
conda activate tts
pip install google-cloud-texttospeech==2.1.0 tqdm pandas
Créer un corpus de phrases texte
- Créer des phrases qui seront environ 3 à 10 secondes lorsqu'elles seront parlées
- Utiliser le format LJSpeech
- "|" Valeurs séparées, ID de fichier WAV puis texte de la phrase
-
100|this is an example sentence
Générer un ensemble de données vocales synthétiques
-
python text_to_wav.py tts_generate
Durée de la phrase
Exécutez les scripts / wavdurations2csv.sh pour tracer la longueur de la phrase et vérifier que vous avez une bonne distribution des longueurs de fichiers WAV.
 Créer des transcriptions pour les enregistrements vocaux existants
Créer des transcriptions pour les enregistrements vocaux existants
Exigences
- Audition Adobe ou audace
- Google Cloud Platform Calculer le moteur Instance
-
Cloud API access scopes SELECT Allow full access to all Cloud APIs
- Conda
Installation
Créer un environnement conda sur l'instance GCP
conda create -n stt python=3.7
conda activate stt
pip install google-cloud-speech tqdm pandas
Remplissez une fiche technique pour l'ensemble de données vocale
- Examiner les feuilles de données pour les ensembles de données par Gebru et al .: https://arxiv.org/pdf/1803.09010.pdf
- Fiche technique de Markdown: https://github.com/jrmeyer/markdown-datasheet-for-datasets/blob/master/datasheet.md
Marquer le discours
Dans Adobe Audition , ouvrez le fichier audio:
- Sélectionnez
Diagnostics -> Mark Audio - Sélectionnez la
Mark the Speech - Cliquer sur
Scan - Cliquez sur
Find Levels - Cliquez à nouveau sur
Scan - Cliquez sur
Mark All - Ajustez le signal audio et le signal de silence et la longueur jusqu'à ce que les clips se situent entre 3 et 10 secondes
Ou, dans Audacity , ouvrez le fichier audio:
- Sélectionnez
Analyze -> Sound Finder - Ajustez le signal audio et le signal de silence et la longueur jusqu'à ce que les clips se situent entre 3 et 10 secondes
Ajuster les marqueurs ou les limites de l'étiquette
En audition :
- Onglet
Markers ouverts - Ajustez les marqueurs, en supprimant le silence et le bruit pour faire une longueur de clip entre 3 et 10 secondes
En audition :
- Ajustez les limites des étiquettes, en supprimant le silence et le bruit pour faire de la longueur du clip entre 3 et 10 secondes
Marqueurs / étiquettes et vagues d'exportation
En audition :
- Sélectionnez tous les marqueurs de la liste
- Sélectionnez
Export Selected Markers to CSV et enregistrez en tant que marqueurs.csv - Sélectionnez
Preferences -> Media & Disk Cache et UNTICK SAVE Save Peak Files - Sélectionnez
Export Audio of Selected Range Markers avec les options suivantes:- Vérifiez
Use marker names in filenames - Mettre à jour le format vers
WAV PCM - Mettre à jour le type d'échantillon
22050 Hz Mono, 16-bit - Utiliser le dossier
wavs_export
Ou, en audace :
- Sélectionnez
Export multiple...- Format: wav
- Options: PCM 16 bits signé
- Fichier divisé en fonction des étiquettes
- Fichiers de noms à l'aide de l'étiquette / piste Nom
- Utiliser le dossier
wavs_export
- Sélectionnez
Export labels pour Label Track.txt
Analyser les ondes avec le rapport signal / bruit Colab
- Exécutez Colabs / Voice_Dataset_Snr.ipynb
- Nettoyer ou supprimer des fichiers bruyants
Créer des transcriptions initiales avec STT
Pour l'audition , en utilisant les Markers.csv exportées.CSV et le dossier Wavs:
cd scripts
python wav_to_text.py audition
Le script génère un nouveau fichier, Markers_STT.csv .
Pour Audacity , en utilisant la Label Track.txt et le dossier Wavs:
cd scripts
python wav_to_text.py audacity
Le script génère un nouveau fichier, Label Track STT.csv .
Transcriptions de tonnelle
Pour l'audition :
- Supprimer tous les marqueurs
- Sélectionnez
Import Markers from File et sélectionnez Fichier avec STT Transcriptions: Markers_Stt.CSV - Affinez le champ de description en marqueurs pour correspondre exactement aux mots prononcés
Pour Audacity :
- Open
Label Track STT.txt dans un éditeur de texte. - Affinez le champ des étiquettes dans le fichier texte pour correspondre exactement aux mots prononcés
Marqueurs d'exportation (audition uniquement) et wavs
Pour l'audition :
- Sélectionnez tous les marqueurs de la liste
- Sélectionnez
Export Selected Markers to CSV et enregistrez en tant que marqueurs.csv - Sélectionnez
Export Audio of Selected Range Markers avec les options suivantes:- Vérifiez
Use marker names in filenames - Mettre à jour le format vers
WAV PCM - Mettre à jour le type d'échantillon
22050 Hz Mono, 16-bit - Utiliser le dossier
wavs_export
Pour Audacity :
- Sélectionnez
Export multiple...- Format: wav
- Options: PCM 16 bits signé
- Fichier divisé en fonction des étiquettes
- Fichiers de noms à l'aide de l'étiquette / piste Nom
- Utiliser le dossier
wavs_export
Convertir les marqueurs (audition) ou les étiquettes (Audacity) en format LJSpeech
En utilisant les Markers.csv exportés.csv (audition) ou Label Track STT.txt (Audacity) et les wavs dans wavs_export, scripts / karkersfile_to_metadata.py créera un métadata.csv et un dossier de wavs pour former votre modèle TTS:
Pour l'audition :
python markersfile_to_metadata.py audition
Pour Audacity :
python markersfile_to_metadata.py audacity
Durée de la phrase
Exécutez les scripts / wavdurations2csv.sh pour tracer la longueur de la phrase et vérifier que vous avez une bonne distribution des longueurs de fichiers WAV.
Autres services publics
Fichier WAV à haut échantillon
ffmpeg: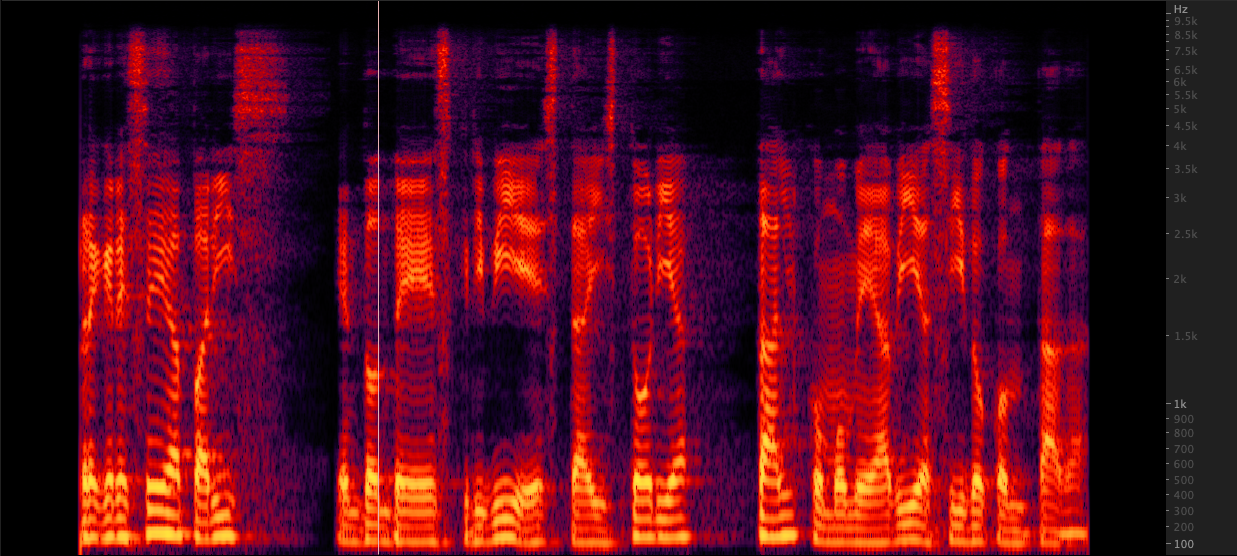 Resampy:
Resampy: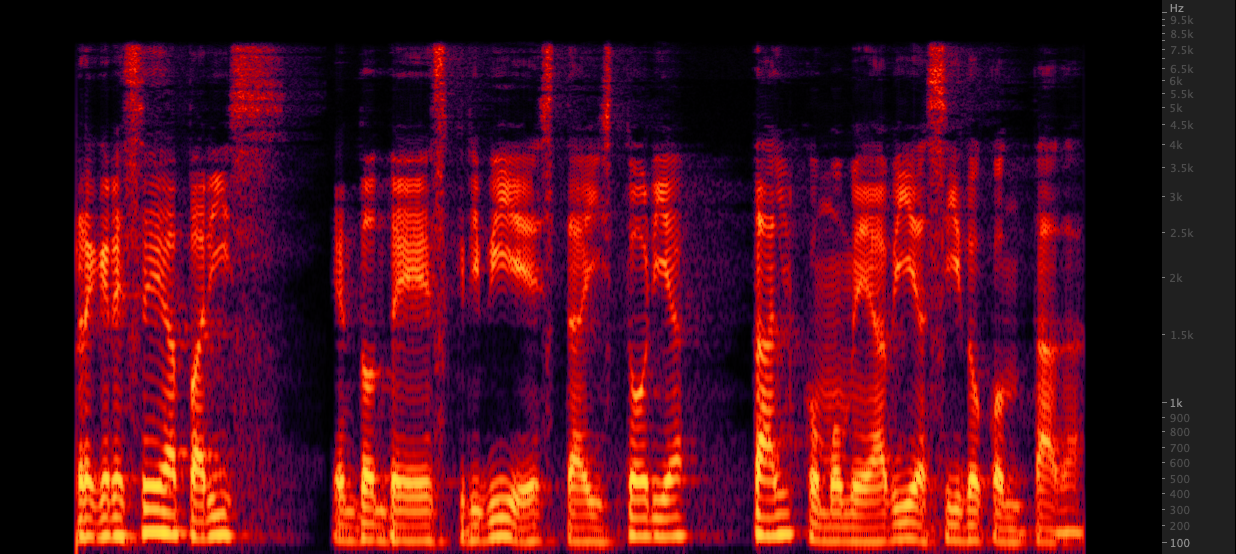 Nous avons testé trois méthodes pour augmenter les fichiers WAV de 16 000 à 22 050 Hz. Après avoir examiné les spectrogrammes, nous avons sélectionné FFMPEG pour l'échantillonnage car il comprend 2 kHz d'informations haut de gamme par rapport à la réévolution. scripts / resamplewav.sh
Nous avons testé trois méthodes pour augmenter les fichiers WAV de 16 000 à 22 050 Hz. Après avoir examiné les spectrogrammes, nous avons sélectionné FFMPEG pour l'échantillonnage car il comprend 2 kHz d'informations haut de gamme par rapport à la réévolution. scripts / resamplewav.sh
Références
- Mozilla tts: https://github.com/mozilla/tts
- Automatisation de l'alignement, comprend l'audio du segment sur le silence, l'API Google Speech et l'alignement de reconnaissance: https://github.com/carpedm20/multi-speaker-tacotron-tensorflow#2-2-generate-korean-datasets
- Pré-dresser sur de grands corpus synthétiques et un réglage fin sur des spécifications https://twitter.com/garygarywang
- Feuilles de données pour ensembles de données https://arxiv.org/abs/1803.09010


