voice dataset creation
1.0.0
Repo ini menguraikan langkah-langkah dan skrip yang diperlukan untuk membuat dataset teks-ke-ucapan Anda sendiri untuk melatih model suara. Output akhir adalah dalam format LJSPEECH.
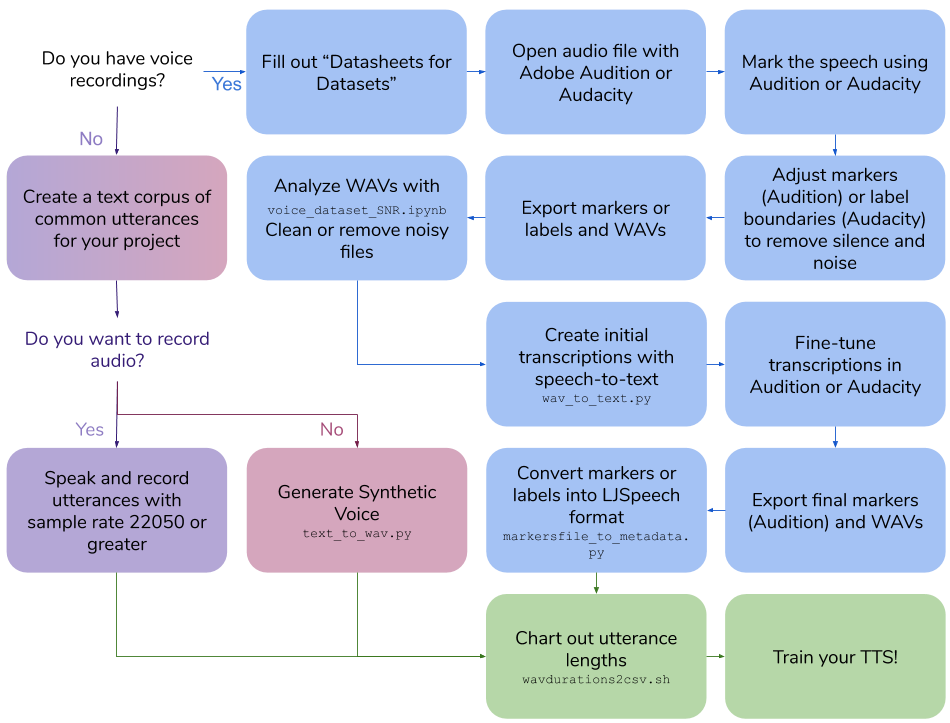
 Buat rekaman suara Anda sendiri
Buat rekaman suara Anda sendiri100|this is an example sentenceJalankan skrip/wavdurations2csv.sh untuk memetakan panjang kalimat dan memverifikasi bahwa Anda memiliki distribusi panjang file wav yang baik.
 Buat dataset suara sintetis
Buat dataset suara sintetisCloud API access scopes Pilih Allow full access to all Cloud APIsBuat Lingkungan Conda di Instance GCP
conda create -n tts python=3.7
conda activate tts
pip install google-cloud-texttospeech==2.1.0 tqdm pandas100|this is an example sentencepython text_to_wav.py tts_generateJalankan skrip/wavdurations2csv.sh untuk memetakan panjang kalimat dan memverifikasi bahwa Anda memiliki distribusi panjang file wav yang baik.
 Buat transkripsi untuk rekaman suara yang ada
Buat transkripsi untuk rekaman suara yang adaCloud API access scopes Pilih Allow full access to all Cloud APIsBuat Lingkungan Conda di Instance GCP
conda create -n stt python=3.7
conda activate stt
pip install google-cloud-speech tqdm pandasDalam Audisi Adobe , buka file audio:
Diagnostics -> Mark AudioMark the SpeechScanFind LevelsScan LagiMark AllAtau, di Audacity , buka file audio:
Analyze -> Sound FinderDalam audisi :
MarkersDalam audisi :
Dalam audisi :
Export Selected Markers to CSV dan Simpan sebagai Markers.CSVPreferences -> Media & Disk Cache dan Tentar Save Peak FilesExport Audio of Selected Range Markers dengan opsi berikut:Use marker names in filenamesWAV PCM22050 Hz Mono, 16-bitwavs_exportAtau, dalam keberanian :
Export multiple...wavs_exportExport labels ke Label Track.txt Untuk audisi , menggunakan folder yang diekspor Markers.csv dan WAVS:
cd scripts
python wav_to_text.py audition Script menghasilkan file baru, Markers_STT.csv .
Untuk Audacity , menggunakan Label Track.txt dan WAVS Folder Run:
cd scripts
python wav_to_text.py audacity Script menghasilkan file baru, Label Track STT.csv .
Untuk audisi :
Import Markers from File dan Pilih File dengan Transkripsi STT: Markers_stt.csvUntuk keberanian :
Label Track STT.txt dalam editor teks.Untuk audisi :
Export Selected Markers to CSV dan Simpan sebagai Markers.CSVExport Audio of Selected Range Markers dengan opsi berikut:Use marker names in filenamesWAV PCM22050 Hz Mono, 16-bitwavs_exportUntuk keberanian :
Export multiple...wavs_export Menggunakan Markers.csv yang diekspor.csv (audisi) atau Label Track STT.txt (Audacity) dan wavs di wavs_export, skrip/markersfile_to_metadata.py akan membuat metadata.csv dan folder wavs untuk melatih model tts Anda:
Untuk audisi :
python markersfile_to_metadata.py auditionUntuk keberanian :
python markersfile_to_metadata.py audacityJalankan skrip/wavdurations2csv.sh untuk memetakan panjang kalimat dan memverifikasi bahwa Anda memiliki distribusi panjang file wav yang baik.
FFMPEG: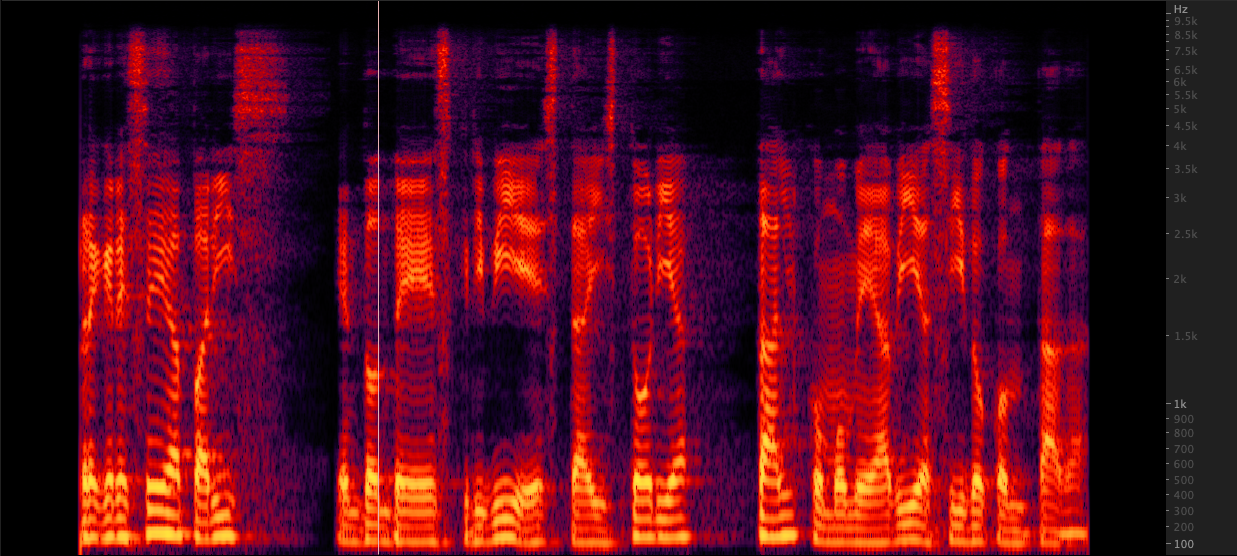 Resampy:
Resampy: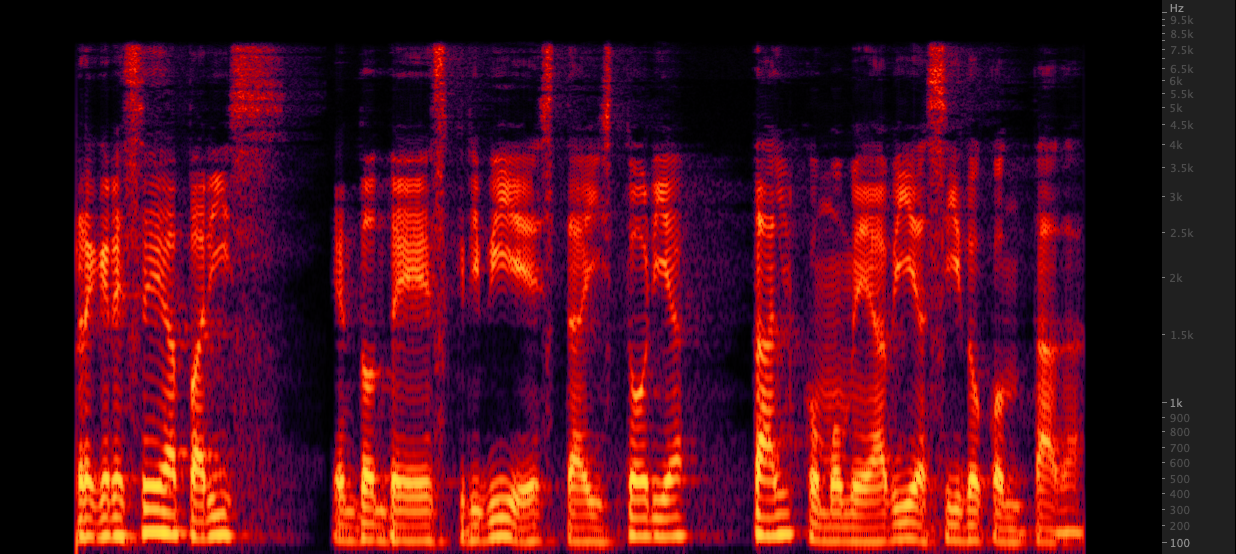 Kami menguji tiga metode untuk meningkatkan file WAV dari 16.000 menjadi 22.050 Hz. Setelah meninjau spektrogram, kami memilih FFMPEG untuk upampling karena mencakup 2 kHz informasi kelas atas lainnya bila dibandingkan dengan resampy. Scripts/ResampleWav.sh
Kami menguji tiga metode untuk meningkatkan file WAV dari 16.000 menjadi 22.050 Hz. Setelah meninjau spektrogram, kami memilih FFMPEG untuk upampling karena mencakup 2 kHz informasi kelas atas lainnya bila dibandingkan dengan resampy. Scripts/ResampleWav.sh
scripts/resamplewav.sh


