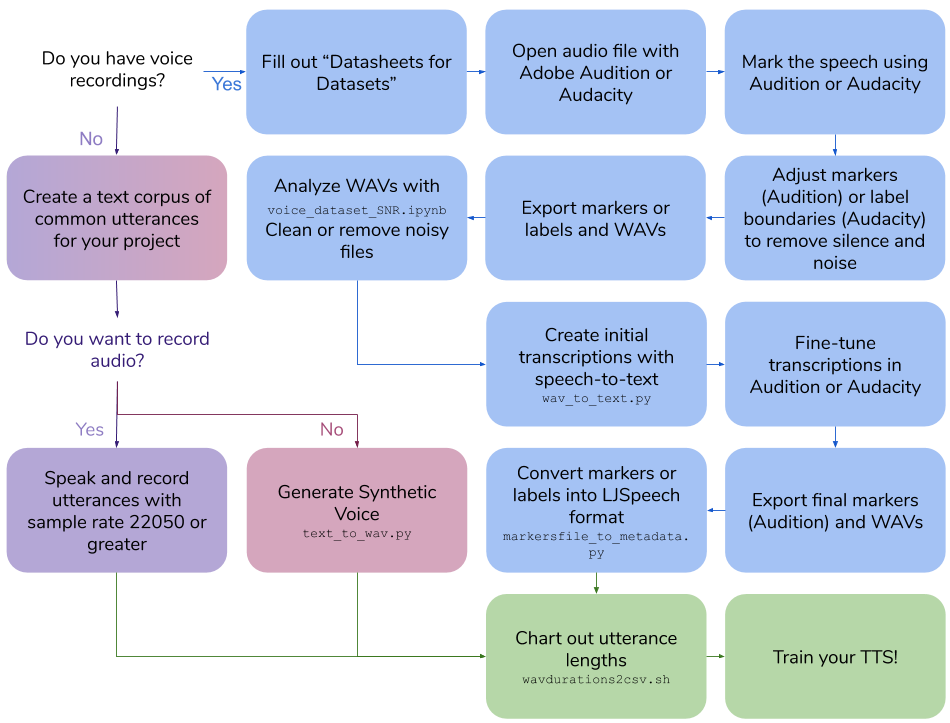
Создание голосового набора данных
В этом репо изложены шаги и сценарии, необходимые для создания собственного набора данных текста в речь для обучения голосовой модели. Окончательный результат в формате LJSPEECH.
Оглавление
- Создайте свои собственные голосовые записи
- Создать синтетический набор данных голоса
- Создать транскрипции для существующих голосовых записей
- Другие утилиты
 Создайте свои собственные голосовые записи
Создайте свои собственные голосовые записи
Требования
- Программное обеспечение для голосовой записи
- Omni-направляющий головочный микрофон
- Аудиокарта хорошего качества
Создать текстовое корпус предложений
- Создайте предложения, которые будут составлять около 3-10 секунд, когда они говорят
- Используйте формат LJSPEECH
- "|" " разделенные значения, идентификатор файла wav, затем текст предложения
-
100|this is an example sentence
Говорить и записывать предложения
- Говорить каждое предложение, как написано
- Скорость дискретизации должна быть 22050 или выше
Длина предложения
Запустите Scripts/Wavdurations2CSV.SH, чтобы наметить длину предложения и убедитесь, что у вас есть хорошее распределение длины файлов WAV.
 Создать синтетический набор данных голоса
Создать синтетический набор данных голоса
Требования
- Google Cloud Platform Platform Compute Encence
-
Cloud API access scopes Select Allow full access to all Cloud APIs
- Конда
Установка
Создать среду Conda в экземпляре GCP
conda create -n tts python=3.7
conda activate tts
pip install google-cloud-texttospeech==2.1.0 tqdm pandas
Создать текстовое корпус предложений
- Создайте предложения, которые будут составлять около 3-10 секунд, когда они говорят
- Используйте формат LJSPEECH
- "|" " разделенные значения, идентификатор файла wav, затем текст предложения
-
100|this is an example sentence
Генерировать синтетический набор данных голоса
-
python text_to_wav.py tts_generate
Длина предложения
Запустите Scripts/Wavdurations2CSV.SH, чтобы наметить длину предложения и убедитесь, что у вас есть хорошее распределение длины файлов WAV.
 Создать транскрипции для существующих голосовых записей
Создать транскрипции для существующих голосовых записей
Требования
- Прослушивание Adobe или смелость
- Google Cloud Platform Platform Compute Encence
-
Cloud API access scopes Select Allow full access to all Cloud APIs
- Конда
Установка
Создать среду Conda в экземпляре GCP
conda create -n stt python=3.7
conda activate stt
pip install google-cloud-speech tqdm pandas
Заполните таблицу данных для голосового набора данных
- Просмотреть таблицы данных для наборов данных Gebru et al.: Https://arxiv.org/pdf/1803.09010.pdf
- Markdown DataSheet: https://github.com/jrmeyer/markdown-datasheet-for-datasets/blob/master/datasheet.md
Отметьте речь
На прослушивании Adobe , откройте аудиофайл:
- Выберите
Diagnostics -> Mark Audio - Выберите
Mark the Speech предустановки - Нажмите на
Scan - Нажмите
Find Levels - Нажмите
Scan еще раз - Нажмите
Mark All - Отрегулируйте аудио и сигнал молчания DB и длину, пока клипы не станут между 3-10 секундами
Или, в смещении , откройте аудиофайл:
- Выберите
Analyze -> Sound Finder - Отрегулируйте аудио и сигнал молчания DB и длину, пока клипы не станут между 3-10 секундами
Регулировать маркеры или границы маркировки
В прослушивании :
- Вкладка открытых
Markers - Отрегулируйте маркеры, удаляя молчание и шум, чтобы составить длину зажима от 3 до 10 секунд в длину
В прослушивании :
- Отрегулируйте границы метки, удаляя молчание и шум, чтобы составить длину зажима от 3 до 10 секунд
Экспортные маркеры/ярлыки и волны
В прослушивании :
- Выберите все маркеры в списке
- Выберите
Export Selected Markers to CSV и сохраните как markers.csv - Выберите
Preferences -> Media & Disk Cache и разоблачьте Save Peak Files - Выберите
Export Audio of Selected Range Markers со следующими параметрами:- Проверьте
Use marker names in filenames - Обновление формата для
WAV PCM - Обновление образца типа
22050 Hz Mono, 16-bit - Используйте папки
wavs_export
Или, в смещении :
- Выберите
Export multiple...- Формат: Wav
- Варианты: подписанный 16-битный PCM
- Разделенные файлы на основе метков
- Имя файлы с использованием названия метки/трека
- Используйте папки
wavs_export
- Выберите
Export labels для Label Track.txt
Анализировать WAVs с помощью колабации сигнал к шуму Colab
- Запустите Colabs/Voice_dataset_snr.ipynb
- Очистить или удалить шумные файлы
Создать начальные транскрипции с помощью STT
Для прослушивания , используя экспортируемые Markers.csv .
cd scripts
python wav_to_text.py audition
Скрипт генерирует новый файл, Markers_STT.csv .
Для Audacity , используя экспортируемую Label Track.txt и папки Wavs:
cd scripts
python wav_to_text.py audacity
Скрипт генерирует новый файл, Label Track STT.csv .
Транспиральные транскрипции тонкой настройки
Для прослушивания :
- Удалить все маркеры
- Выберите
Import Markers from File и выберите файл с помощью транскрипций STT: markers_stt.csv - Настраивать поле описания в маркерах, чтобы точно соответствовать произнесенным словам
Для смелости :
- Открыть
Label Track STT.txt в текстовом редакторе. - Настраивать поле метки в текстовом файле, чтобы точно соответствовать произнесенным словам
Экспортные маркеры (только прослушивание) и Wavs
Для прослушивания :
- Выберите все маркеры в списке
- Выберите
Export Selected Markers to CSV и сохраните как markers.csv - Выберите
Export Audio of Selected Range Markers со следующими параметрами:- Проверьте
Use marker names in filenames - Обновление формата для
WAV PCM - Обновление образца типа
22050 Hz Mono, 16-bit - Используйте папки
wavs_export
Для смелости :
- Выберите
Export multiple...- Формат: Wav
- Варианты: подписанный 16-битный PCM
- Разделенные файлы на основе метков
- Имя файлы с использованием названия метки/трека
- Используйте папки
wavs_export
Конвертировать маркеры (прослушивание) или метки (смелость) в формат LJSPEECH
Используя экспортируемые Markers.csv (прослушивание) или Label Track STT.txt (audacity) и wavs в wavs_export, scripts/markersfile_to_metadata.py создаст метадату.csv и папку волн для обучения вашей модели TTS:
Для прослушивания :
python markersfile_to_metadata.py audition
Для смелости :
python markersfile_to_metadata.py audacity
Длина предложения
Запустите Scripts/Wavdurations2CSV.SH, чтобы наметить длину предложения и убедитесь, что у вас есть хорошее распределение длины файлов WAV.
Другие утилиты
Файл upsample wav
ffmpeg: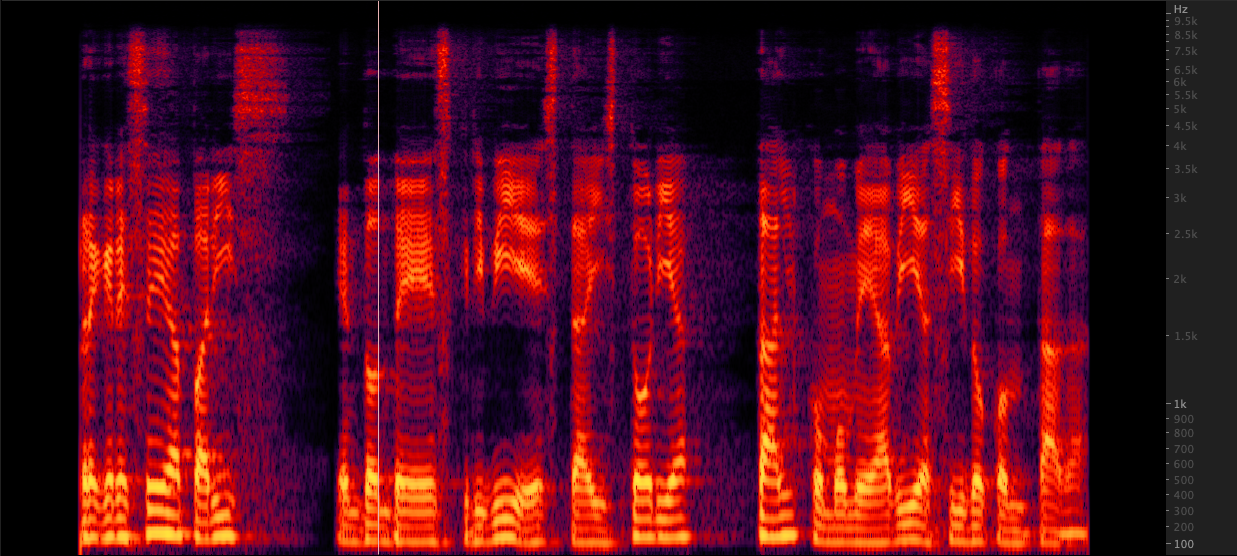 Resampy:
Resampy: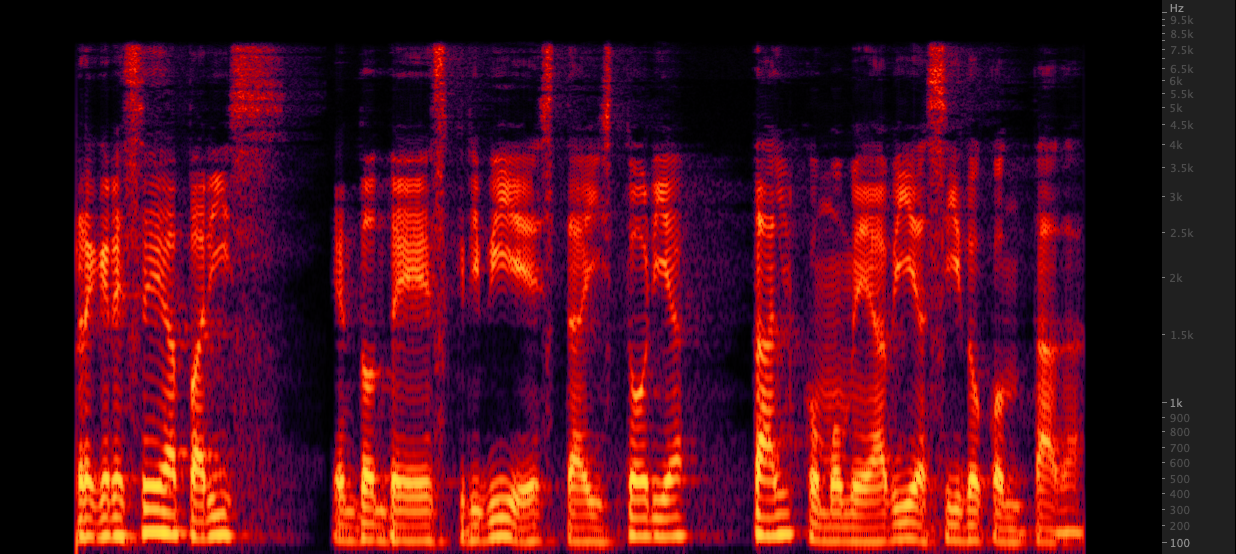 Мы протестировали три метода в файлах WAV upsample от 16 000 до 22 050 Гц. После просмотра спектрограмм мы выбрали FFMPEG для повышения дискретизации, поскольку она включает в себя еще 2 кГц информации высокого класса по сравнению с Resampy. Scripts/ResampleWav.Sh
Мы протестировали три метода в файлах WAV upsample от 16 000 до 22 050 Гц. После просмотра спектрограмм мы выбрали FFMPEG для повышения дискретизации, поскольку она включает в себя еще 2 кГц информации высокого класса по сравнению с Resampy. Scripts/ResampleWav.Sh
Ссылки
- Mozilla TTS: https://github.com/mozilla/tts
- Автоматизация выравнивания, включает в себя сегментный звук на молчание, Google Speech API и выравнивание признания: https://github.com/carpedm20/multi-peaker-tacotron-tensorflow#2-2-generate-korean-datasets
- Предварительная подготовка на больших синтетических корпусах и тонкую настройку на определенных https://twitter.com/garygarywang
- Таблицы данных для наборов данных https://arxiv.org/abs/1803.09010


