voice dataset creation
1.0.0
このレポは、音声モデルをトレーニングするための独自のテキストからスピーチデータセットを作成するために必要な手順とスクリプトの概要を説明します。最終出力はljspeech形式です。
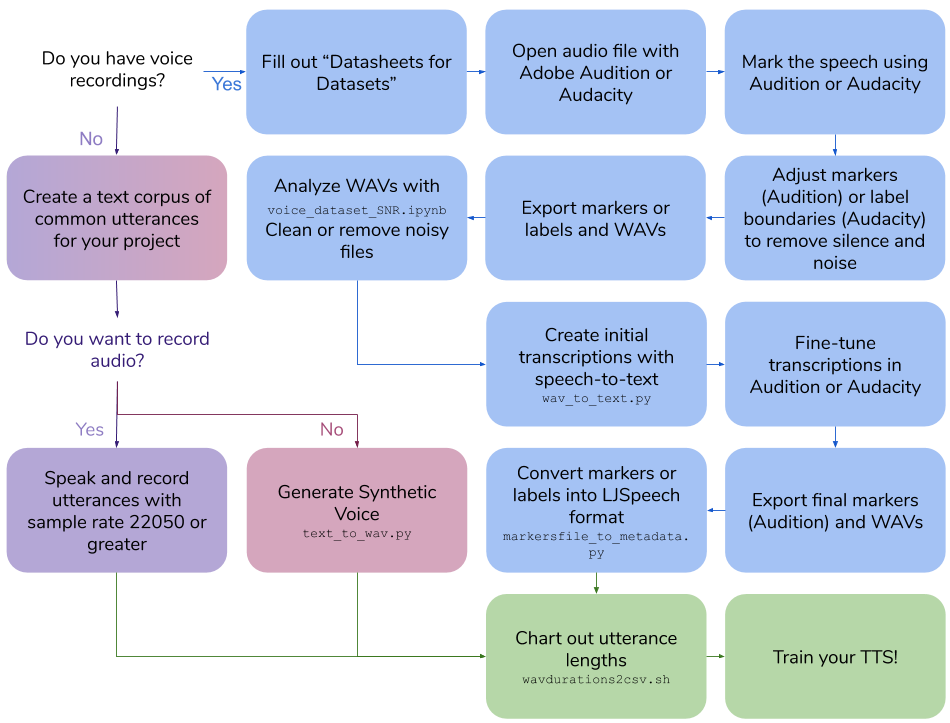
 独自の音声録音を作成します
独自の音声録音を作成します100|this is an example sentenceScripts/Wavdurations2csv.shを実行して、文の長さを作成し、WAVファイルの長さの適切な分布があることを確認します。
 合成音声データセットを作成します
合成音声データセットを作成しますCloud API access scopes選択Allow full access to all Cloud APIsGCPインスタンスでコンドラ環境を作成します
conda create -n tts python=3.7
conda activate tts
pip install google-cloud-texttospeech==2.1.0 tqdm pandas100|this is an example sentencepython text_to_wav.py tts_generateScripts/Wavdurations2csv.shを実行して、文の長さを作成し、WAVファイルの長さの適切な分布があることを確認します。
 既存の音声録音の転写を作成します
既存の音声録音の転写を作成しますCloud API access scopes選択Allow full access to all Cloud APIsGCPインスタンスでコンドラ環境を作成します
conda create -n stt python=3.7
conda activate stt
pip install google-cloud-speech tqdm pandasAdobe Auditionでは、オーディオファイルを開く:
Diagnostics - > Mark Audioを選択しますMark the Speechを選択しますScanをクリックしますFind LevelsをクリックしますScanをクリックしますMark Allをクリックしますまたは、 Audacityでは、オーディオファイルを開きます。
Analyze - > Sound Finderを選択しますオーディションで:
Markersタブオーディションで:
オーディションで:
Export Selected Markers to CSV 、Markers.csvとして保存しますPreferencesを選択 - > Media & Disk CacheとアンティックのSave Peak FilesExport Audio of Selected Range Markersを選択して、次のオプションを選択します。Use marker names in filenamesくださいWAV PCMに更新します22050 Hz Mono, 16-bit更新しますwavs_exportを使用しますまたは、 Audacityで:
Export multiple...wavs_exportを使用しますExport labelsを選択しますLabel Track.txtオーディションの場合、エクスポートされたMarkers.csvおよびWAVSフォルダーを使用して実行します。
cd scripts
python wav_to_text.py auditionスクリプトは、新しいファイルMarkers_STT.csvを生成します。
Audacityの場合、エクスポートされたLabel Track.txtとWavsフォルダーの実行を使用してください。
cd scripts
python wav_to_text.py audacityスクリプトは、新しいファイル、 Label Track STT.csvを生成します。
オーディションの場合:
Import Markers from Fileを選択し、STT転写を使用してファイルを選択します:markers_stt.csvAudacityのために:
Label Track STT.txtを開きます。オーディションの場合:
Export Selected Markers to CSV 、Markers.csvとして保存しますExport Audio of Selected Range Markersを選択して、次のオプションを選択します。Use marker names in filenamesくださいWAV PCMに更新します22050 Hz Mono, 16-bit更新しますwavs_exportを使用しますAudacityのために:
Export multiple...wavs_exportを使用しますexported Markers.csv (audition)またはLabel Track STT.txt (audacity)とwavs_exportのwavsを使用して、scripts/markersfile_to_metadata.pyは、ttsモデルをトレーニングするために波状のメタデータとフォルダーを作成します。
オーディションの場合:
python markersfile_to_metadata.py auditionAudacityのために:
python markersfile_to_metadata.py audacityScripts/Wavdurations2csv.shを実行して、文の長さを作成し、WAVファイルの長さの適切な分布があることを確認します。
ffmpeg: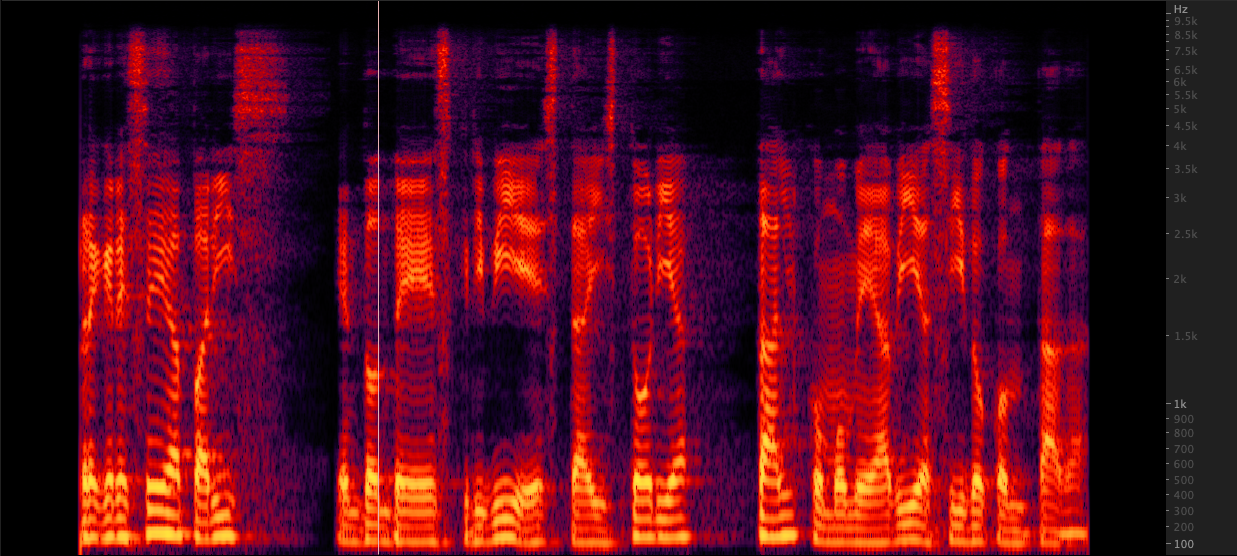 再sampy:
再sampy: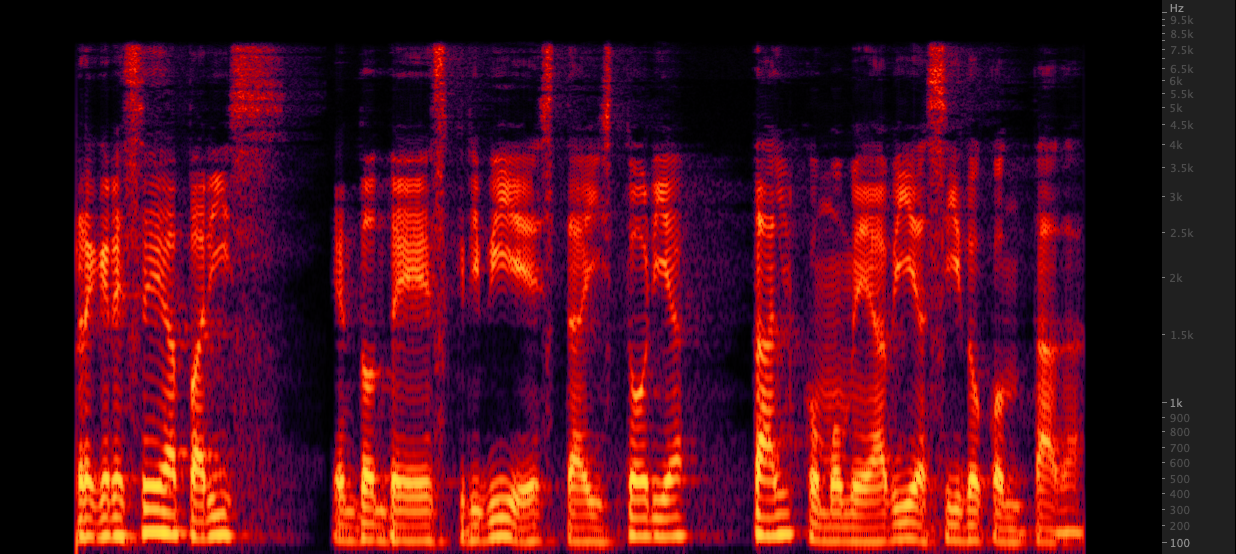 WAVファイルを16,000から22,050 Hzにアップサンプリングするための3つの方法をテストしました。スペクトログラムを確認した後、Resampyと比較した場合、さらに2 kHzのハイエンド情報が含まれているため、FFMPEGをアップサンプリング用に選択しました。スクリプト/resamplewav.sh
WAVファイルを16,000から22,050 Hzにアップサンプリングするための3つの方法をテストしました。スペクトログラムを確認した後、Resampyと比較した場合、さらに2 kHzのハイエンド情報が含まれているため、FFMPEGをアップサンプリング用に選択しました。スクリプト/resamplewav.sh
scripts/resamplewav.sh


