voice dataset creation
1.0.0
Esse repositório descreve as etapas e scripts necessários para criar seu próprio conjunto de dados de texto para fala para treinar um modelo de voz. A saída final está no formato LJSpeech.
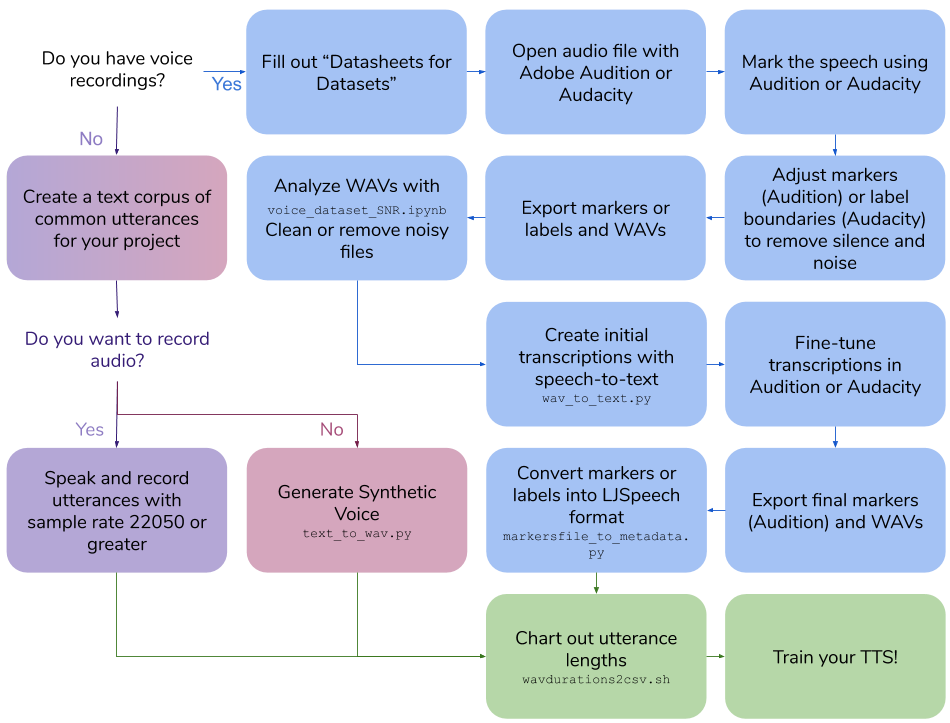
 Crie suas próprias gravações de voz
Crie suas próprias gravações de voz100|this is an example sentenceExecute scripts/wavdurations2csv.sh para traçar o comprimento da frase e verificar se você tem uma boa distribuição de comprimentos de arquivo WAV.
 Crie um conjunto de dados de voz sintético
Crie um conjunto de dados de voz sintéticoCloud API access scopes Selecione Allow full access to all Cloud APIsCrie o ambiente do CONDA na instância do GCP
conda create -n tts python=3.7
conda activate tts
pip install google-cloud-texttospeech==2.1.0 tqdm pandas100|this is an example sentencepython text_to_wav.py tts_generateExecute scripts/wavdurations2csv.sh para traçar o comprimento da frase e verificar se você tem uma boa distribuição de comprimentos de arquivo WAV.
 Crie transcrições para gravações de voz existentes
Crie transcrições para gravações de voz existentesCloud API access scopes Selecione Allow full access to all Cloud APIsCrie o ambiente do CONDA na instância do GCP
conda create -n stt python=3.7
conda activate stt
pip install google-cloud-speech tqdm pandasNa Adobe Audition , Abra o arquivo de áudio:
Diagnostics -> Mark AudioMark the SpeechScanFind LevelsScan novamenteMark AllOu, em Audacity , abra o arquivo de áudio:
Analyze -> Sound FinderNa audição :
Markers abertosNa audição :
Na audição :
Export Selected Markers to CSV e salvar como marcadores.csvPreferences -> Media & Disk Cache e Descondecer Save Peak FilesExport Audio of Selected Range Markers com as seguintes opções:Use marker names in filenamesWAV PCM22050 Hz Mono, 16-bitwavs_exportOu, em audácia :
Export multiple...wavs_exportExport labels para Label Track.txt Para audição , usando os Markers.csv exportados.csv e a pasta WAVS Run:
cd scripts
python wav_to_text.py audition O script gera um novo arquivo, Markers_STT.csv .
Para Audacity , usando o Label Track.txt e Wavs Pasta Run:
cd scripts
python wav_to_text.py audacity O script gera um novo arquivo, Label Track STT.csv .
Para audição :
Import Markers from File e selecione Arquivo com STT Transcrições: Markers_Stt.csvPara Audacity :
Label Track STT.txt Em um editor de texto.Para audição :
Export Selected Markers to CSV e salvar como marcadores.csvExport Audio of Selected Range Markers com as seguintes opções:Use marker names in filenamesWAV PCM22050 Hz Mono, 16-bitwavs_exportPara Audacity :
Export multiple...wavs_export Usando os Markers.csv exportados.csv (audição) ou Label Track STT.txt (audacity) e wavs em wavs_export, scripts/markersfile_to_metadata.py criará um metadado.csv e a pasta de ondas para treinar seu modelo TTS:
Para audição :
python markersfile_to_metadata.py auditionPara Audacity :
python markersfile_to_metadata.py audacityExecute scripts/wavdurations2csv.sh para traçar o comprimento da frase e verificar se você tem uma boa distribuição de comprimentos de arquivo WAV.
ffmpeg: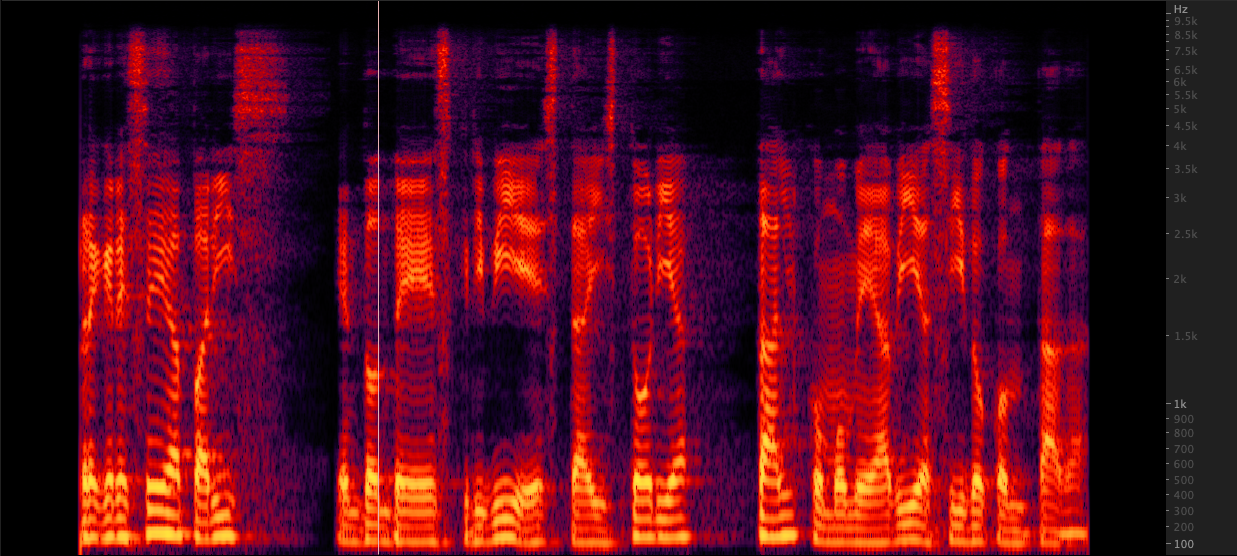 Resampado:
Resampado: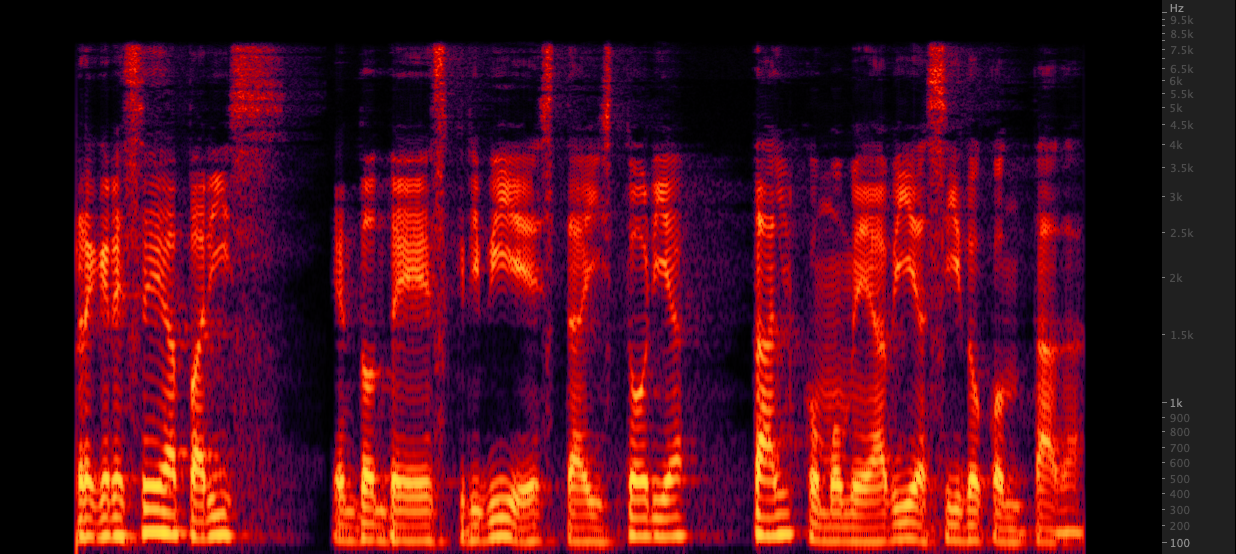 Testamos três métodos para aumentar os arquivos WAV de 16.000 a 22.050 Hz. Depois de revisar os espectrogramas, selecionamos o FFMPEG para o upsampling, pois inclui outros 2 kHz de informações de ponta quando comparado ao reperdício. scripts/resamplewav.sh
Testamos três métodos para aumentar os arquivos WAV de 16.000 a 22.050 Hz. Depois de revisar os espectrogramas, selecionamos o FFMPEG para o upsampling, pois inclui outros 2 kHz de informações de ponta quando comparado ao reperdício. scripts/resamplewav.sh
scripts/resamplewav.sh


