NEPSE Chatbot Using Retrieval augmented generation and reranking
1.0.0
Fuente de la imagen: Mk Pavan Kumar
Fuente de la imagen: pinecone
Este proyecto aprovecha los modelos de código abierto para construir un chatbot para Nepse, el Nepal Stock Exchange Ltd, utilizando la técnica de generación aumentada de recuperación. El folleto de Nepse PDF se utiliza para la respuesta de preguntas. El proyecto utiliza los siguientes modelos de código abierto:
Se utiliza Intel/Neural-Chat-7B-V3-1: se utiliza un LLM de código abierto, desarrollado originalmente por Intel y cuantificado por TheBloke. Específicamente, la versión cuantificada GPTQ de 8 bits se emplea debido a la memoria limitada.
All-MPNET-Base-V2: un transformador de oración de código abierto de la cara abrazada llamada All-MPNET-Base-V2 se utiliza para generar incrustaciones de alta calidad.
AAI/BGE-Reranker-Large: un modelo de rehacer de código abierto de la cara abrazada llamada BGE-Reranker-Large se usa para volver a clasificar los documentos recuperados de la tienda Vector.
API de traducción de Google: la API gratuita de Google Translate se utiliza para realizar la traducción entre el contenido nepalí y el inglés.
Los datos de texto del folleto NEPSE se limpian, se dividen en trozos y se desarrollan integradores utilizando transformadores de oraciones, que se agregan a la base de datos FAISS Vector. Cuando el usuario ingresa una pregunta, se desarrollan incrustaciones de la entrada y se utilizan los incrustaciones de preguntas para realizar una búsqueda vectorial para recuperar los principales documentos K. Los documentos recuperados de Top-K se pasan al modelo Reranking para mejorar la calidad y la relevancia de las recuperaciones. Finalmente, los principales documentos de Reranked se pasan como contexto a la LLM con una ingeniería rápida adecuada para proporcionar respuestas a los usuarios.
Se ha desarrollado un frontend simple con HTML, CSS y JavaScript, y un backend usando Flask. Las respuestas/tokens predichos del LLM se transmiten a la frontend en tiempo real para reducir la latencia del usuario y mejorar la experiencia del usuario. La aplicación se implementa en una instancia G4DN.XLARGE AWS EC2 para inferencia en tiempo real.
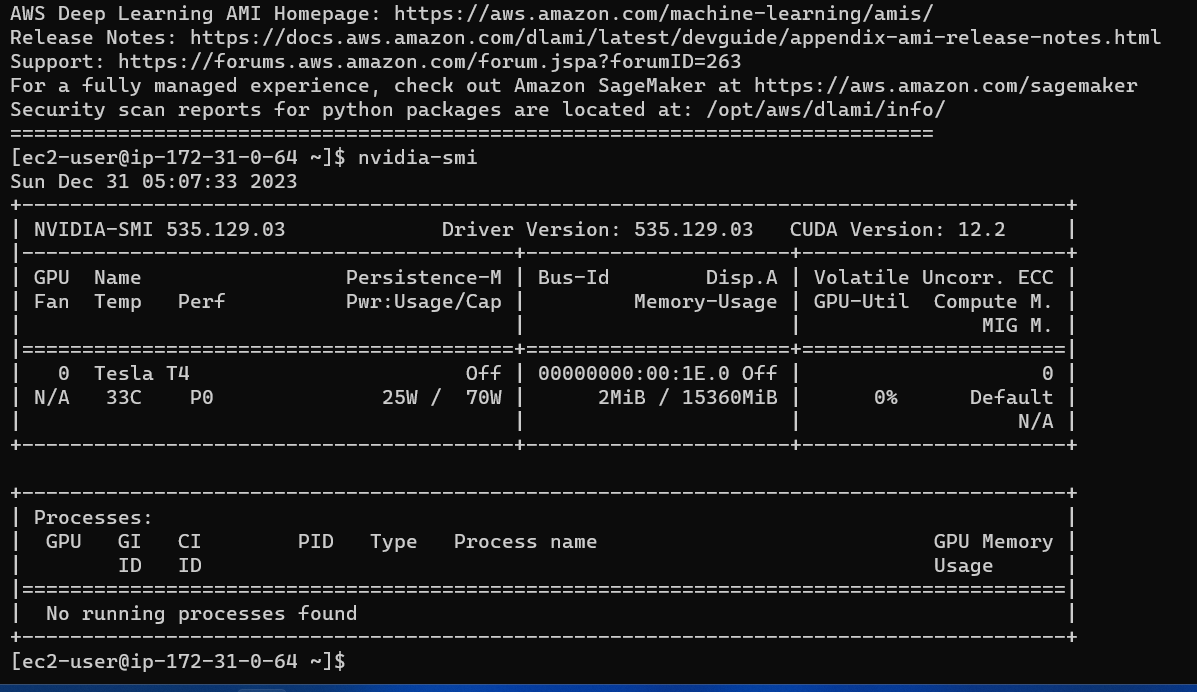
Con 16 GB de VRAM, los tres modelos encajarán fácilmente sin ningún problema. Las capturas de pantalla y los clips a continuación muestran la capacidad de respuesta de preguntas en tiempo real del chatbot Nepse implementado en AWS.
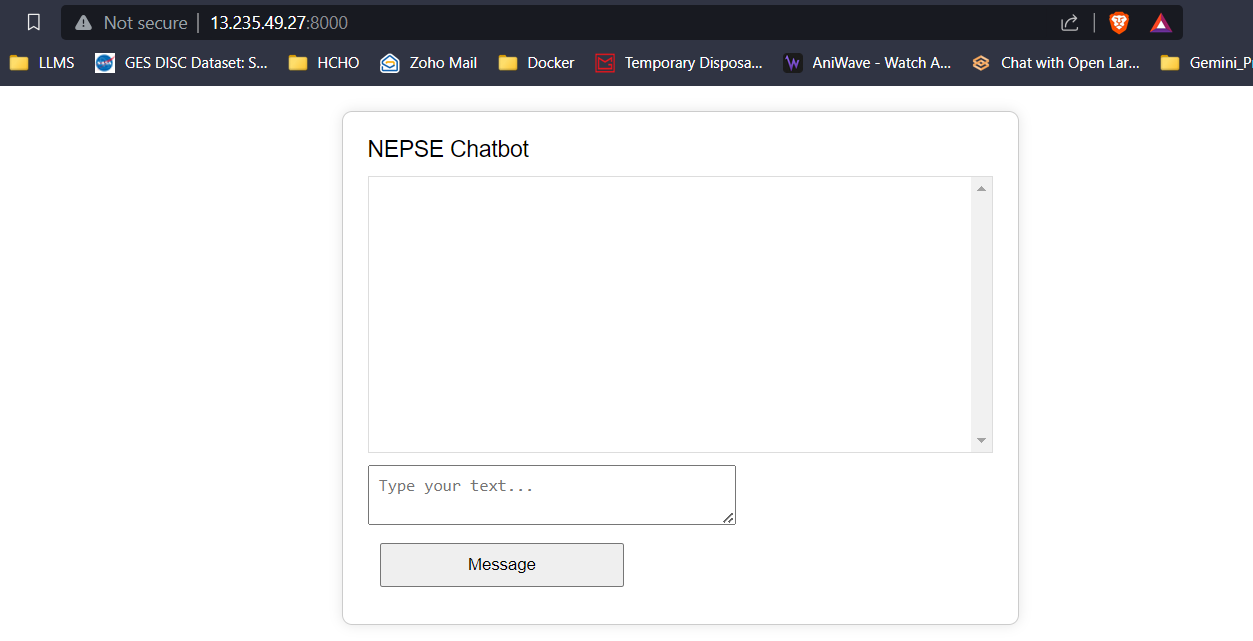
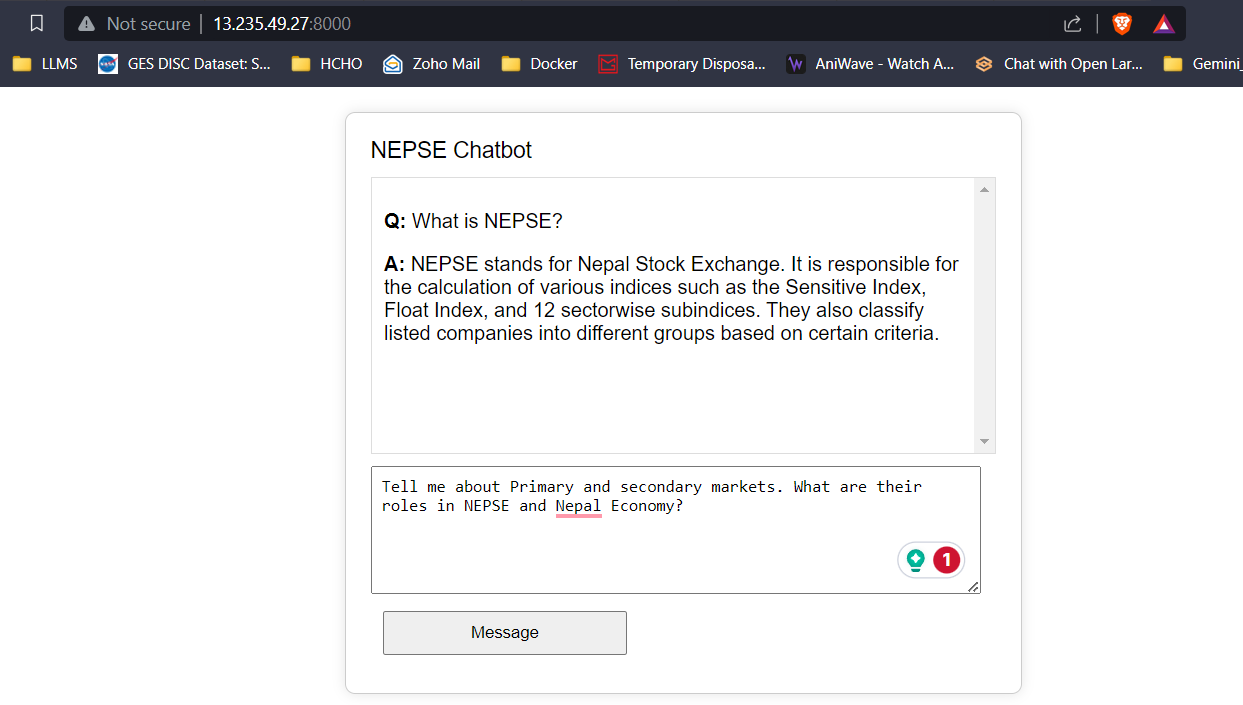
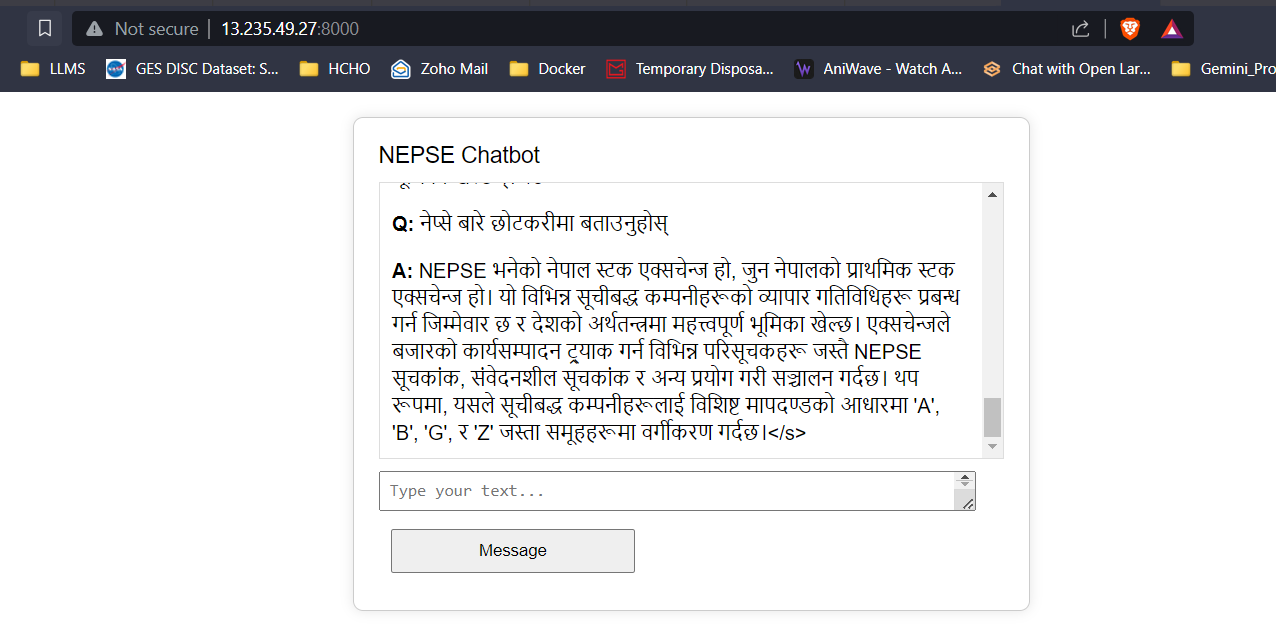
Transmisión de respuesta LLM (como chatgpt)
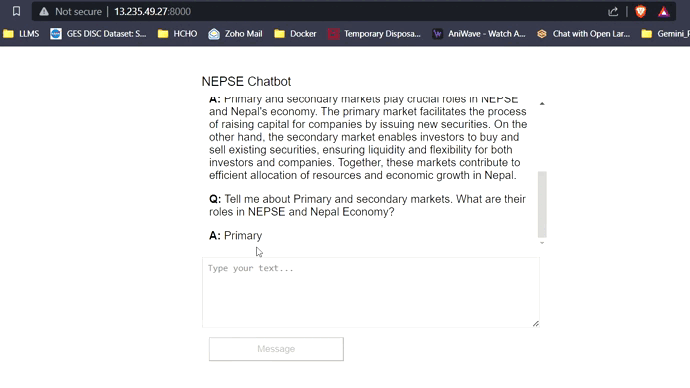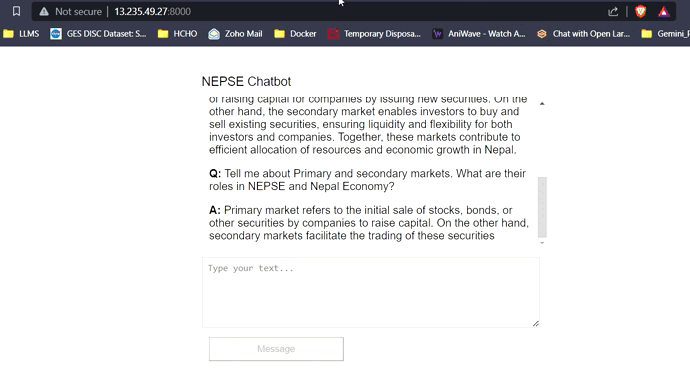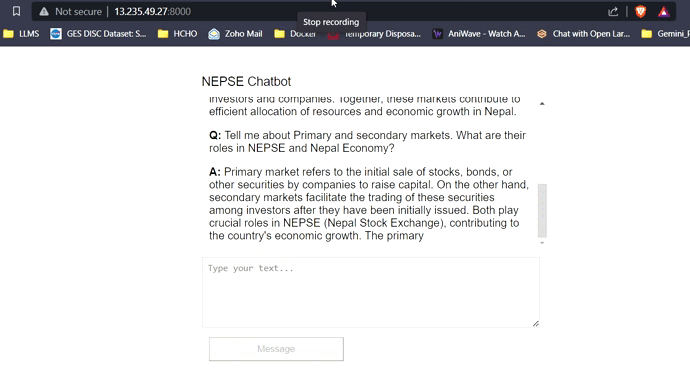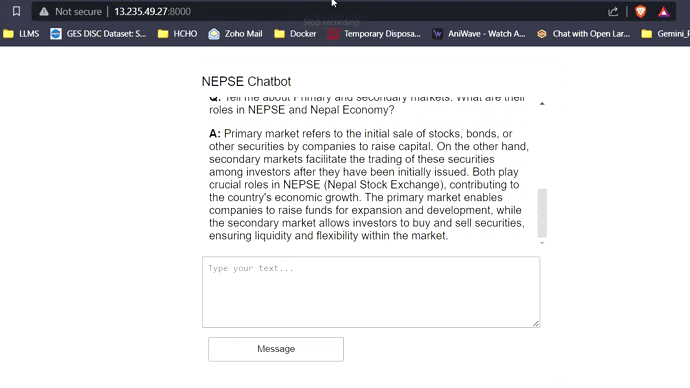
Haga clic en el enlace a continuación para ver/descargar el video completo.
Ver video


