NEPSE Chatbot Using Retrieval augmented generation and reranking
1.0.0
Source de l'image: MK Pavan Kumar
Source de l'image: Pinecone
Ce projet tire parti des modèles open-source pour construire un chatbot pour NEPSE, le Nepal Stock Exchange Ltd, en utilisant la technique de génération augmentée de récupération. Le livret NEPSE PDF est utilisé pour la réponse aux questions. Le projet utilise les modèles open source suivants:
Intel / Neural-Chat-7b-V3-1: Un LLM open-source, développé à l'origine par Intel et quantifié par TheBloke, est utilisé. Plus précisément, la version quantifiée GPTQ 8 bits est utilisée en raison de la mémoire limitée.
All-MPNET-Base-V2: Un transformateur de phrase open-source à partir de la face étreinte appelée All-Mpnet-Base-V2 est utilisé pour générer des incorporations de haute qualité.
AAI / BGE-RERANKER-GARD: Un modèle de rediffusion open source de l'étreinte Called Bge-Reranker-Large est utilisé pour recommencer les documents récupérés du magasin vectoriel.
API Google Translate: L'API Google Translate gratuite est utilisée pour effectuer une traduction entre le contenu népalais et anglais.
Les données de texte du livret NEPSE sont nettoyées, divisées en morceaux et intégres sont développées à l'aide de Transformers de phrase, qui sont ajoutés à la base de données vectorielle FAISS. Lorsque l'utilisateur saisit une question, des intégres de l'entrée sont développés et les incorporations de questions sont utilisées pour effectuer une recherche vectorielle pour récupérer les K supérieurs. Les documents récupérés supérieurs sont transmis au modèle de rediffusion pour améliorer la qualité et la pertinence des récupérations. Enfin, les principaux documents de lance en K sont passés en tant que contexte au LLM avec une ingénierie rapide appropriée pour fournir des réponses aux utilisateurs.
Un frontend simple utilisant HTML, CSS et JavaScript, et un backend utilisant Flask ont été développés. Les réponses / jetons prévus de la LLM sont diffusés vers le frontend en temps réel pour réduire la latence des utilisateurs et améliorer l'expérience utilisateur. L'application est déployée sur une instance G4DN.xlarge AWS EC2 pour une inférence en temps réel.
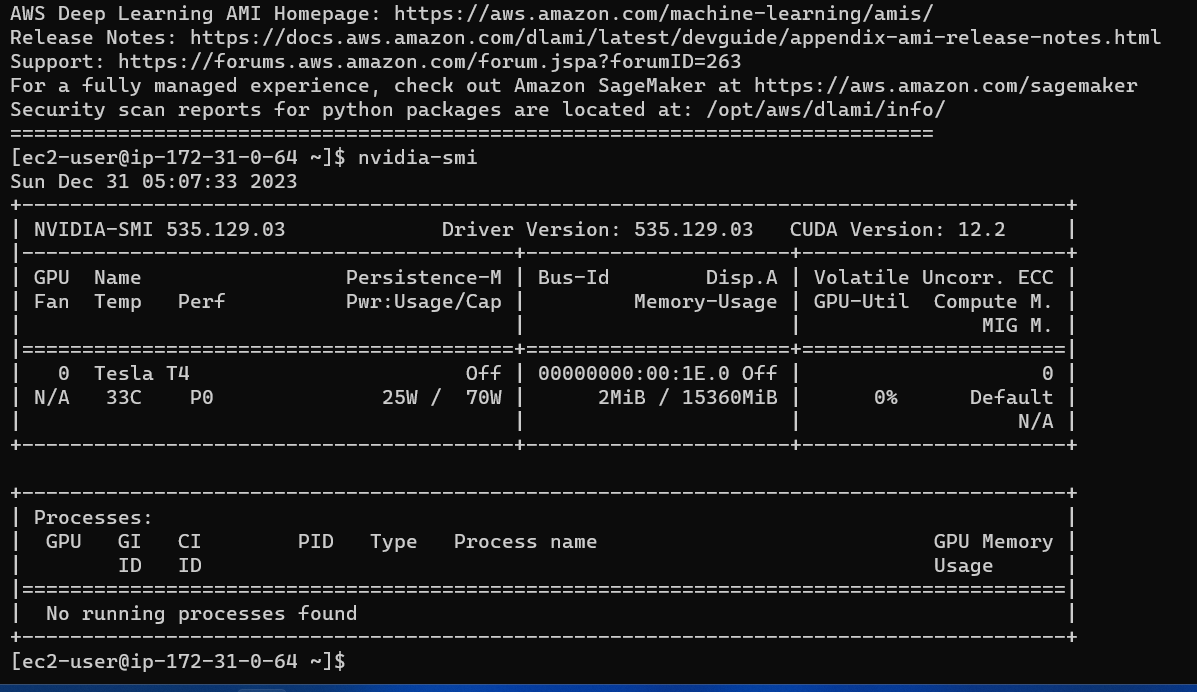
Avec 16 Go de VRAM, les trois modèles s'adapteront facilement sans aucun problème. Les captures d'écran et les clips ci-dessous mettent en valeur la capacité de réponse aux questions en temps réel du chatbot NEPSE déployé sur AWS.
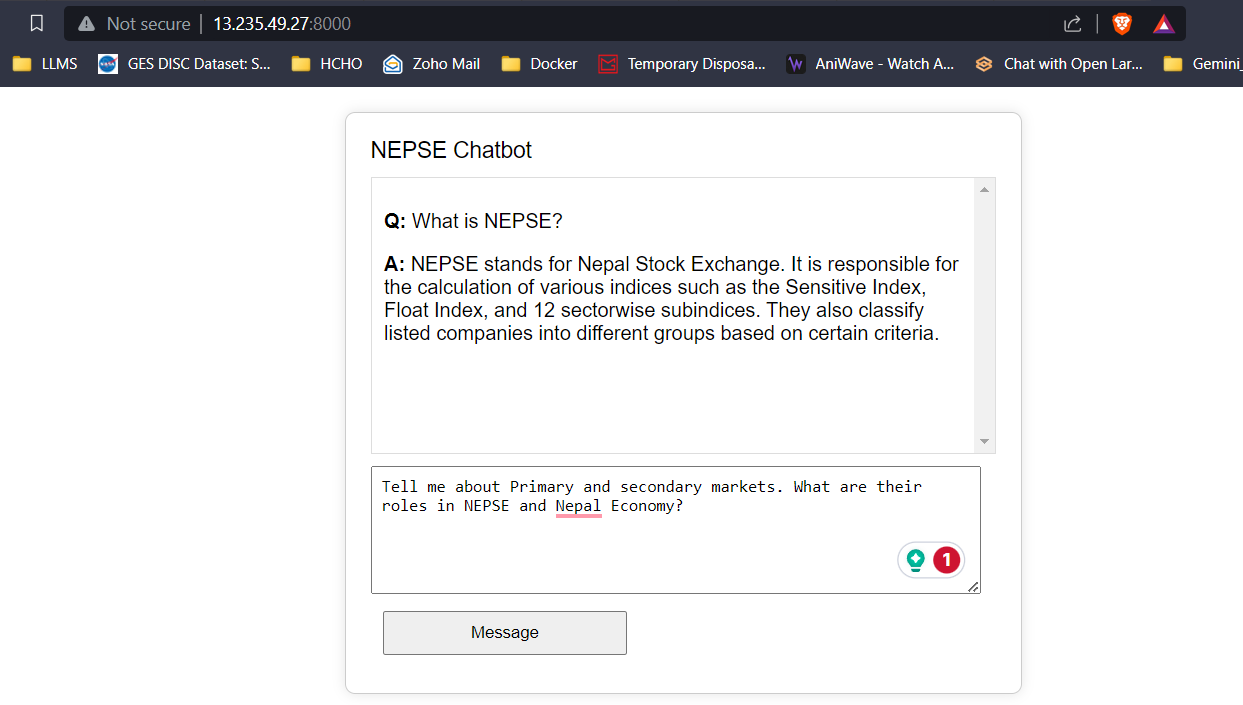
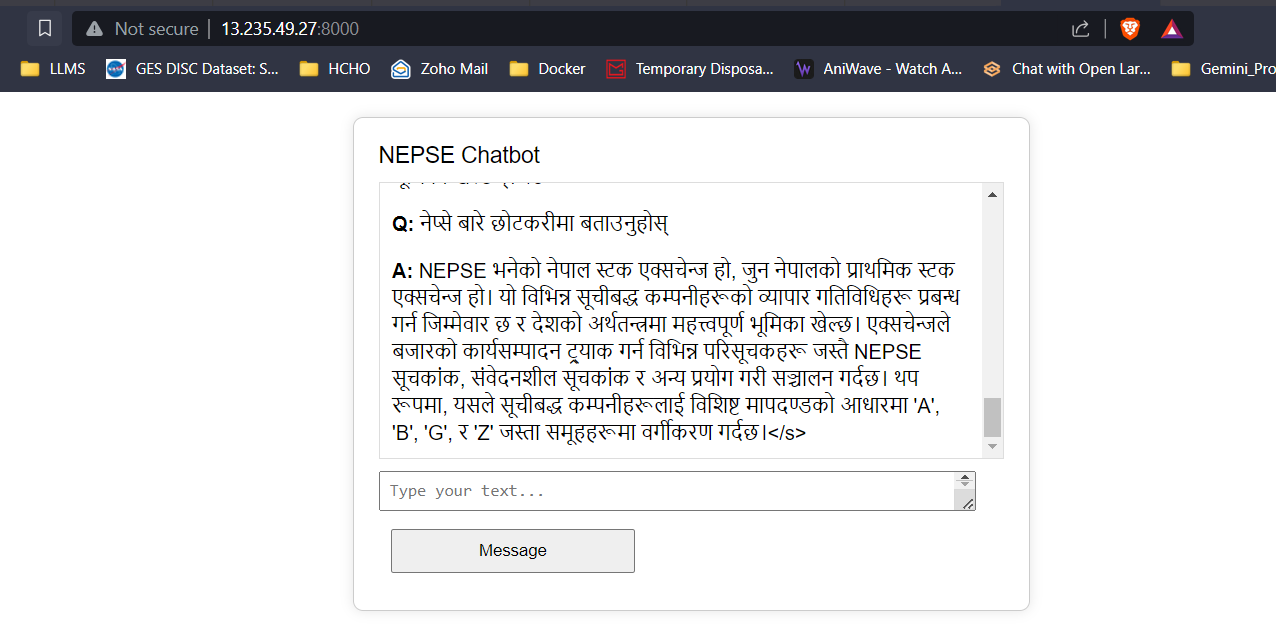
LLM Response Streaming (comme Chatgpt)
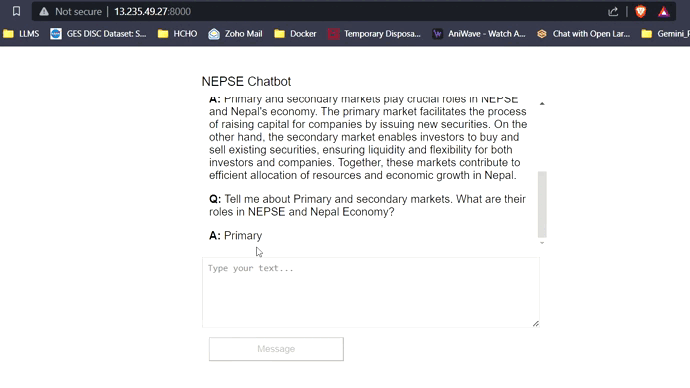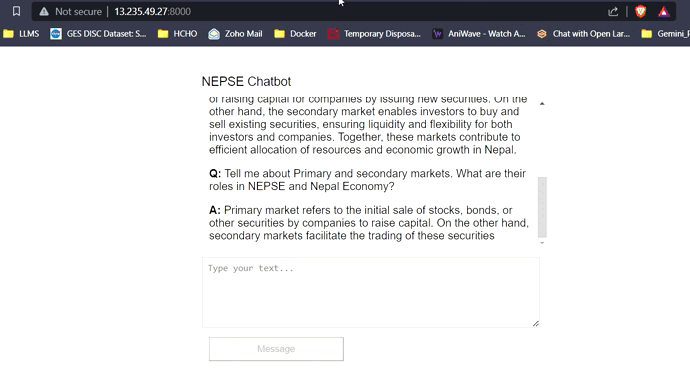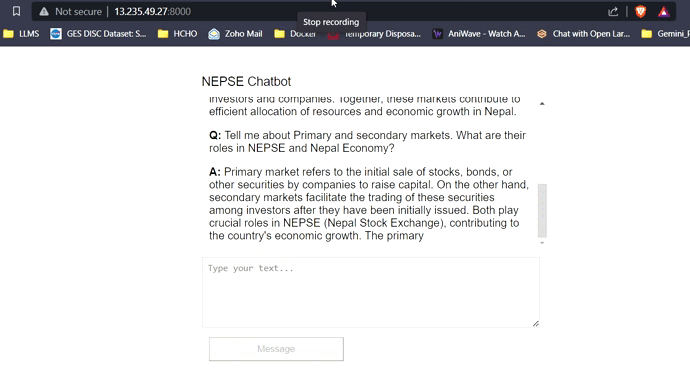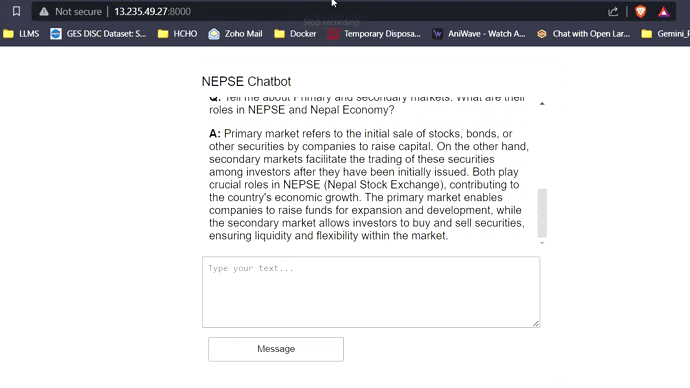
Cliquez sur le lien ci-dessous pour regarder / télécharger la vidéo complète.
Regarder la vidéo


