NEPSE Chatbot Using Retrieval augmented generation and reranking
1.0.0
Bildquelle: Mk Pavan Kumar
Bildquelle: Pnecone
Dieses Projekt nutzt Open-Source-Modelle, um einen Chatbot für NEPSE, die Nepal Stock Exchange Ltd, unter Verwendung der Technik zur Augmented Abruf Augmented zu erstellen. Das NEPSE-Broschüren-PDF wird für Fragen zur Beantwortung verwendet. Das Projekt verwendet die folgenden Open-Source-Modelle:
Intel/Neural-CHAT-7B-V3-1: Eine Open-Source-LLM, die ursprünglich von Intel entwickelt und durch den Blok zu quantifiziert ist, wird verwendet. Insbesondere wird die 8-Bit-GPTQ-quantisierte Version aufgrund des begrenzten Speichers verwendet.
All-MPNET-Base-V2: Ein Open-Source-Satztransformator aus dem Umarmungsgesicht namens All-MPNET-Base-V2 wird verwendet, um qualitativ hochwertige Einbettungen zu erzeugen.
AAI/BGE-RERANKER-LARGE: Ein Open-Source-Umlagerungsmodell aus dem Umarmungsgesicht namens BGE-Reranker-Large wird verwendet, um die abgerufenen Dokumente aus dem Vektor Store erneut zu beziehen.
Google Translate API: Die kostenlose Google Translate -API wird verwendet, um die Übersetzung zwischen Nepali und englischer Inhalt durchzuführen.
Die Textdaten aus der NEPSE -Broschüre werden gereinigt, in Stücke unterteilt und Emetten mit Satztransformatoren entwickelt, die der FAISS Vektor -Datenbank hinzugefügt werden. Wenn der Benutzer eine Frage eingibt, werden Einbettungen aus der Eingabe entwickelt, und die Frage -Einbettungen werden verwendet, um eine Vektorsuche durchzuführen, um die oberen K -Dokumente abzurufen. Die am Top-K abgerufenen Dokumente werden an das leitende Modell übergeben, um die Qualität und Relevanz der Abrufe zu verbessern. Schließlich werden die Dokumente der Top-K-Lerank-Dokumente als Kontext an die LLM übergeben und mit ordnungsgemäßen Eingabeaufforderung technisch eingestuft, um den Benutzern Antworten zu geben.
Eine einfache Frontend mit HTML, CSS und JavaScript und ein Backend mit Flask wurden entwickelt. Die Antworten/vorhergesagten Token aus dem LLM werden in Echtzeit an den Frontend gestreamt, um die Benutzerlatenz zu verringern und die Benutzererfahrung zu verbessern. Die Anwendung wird in einer G4DN.xlarge AWS EC2-Instanz für Echtzeit-Inferenz bereitgestellt.
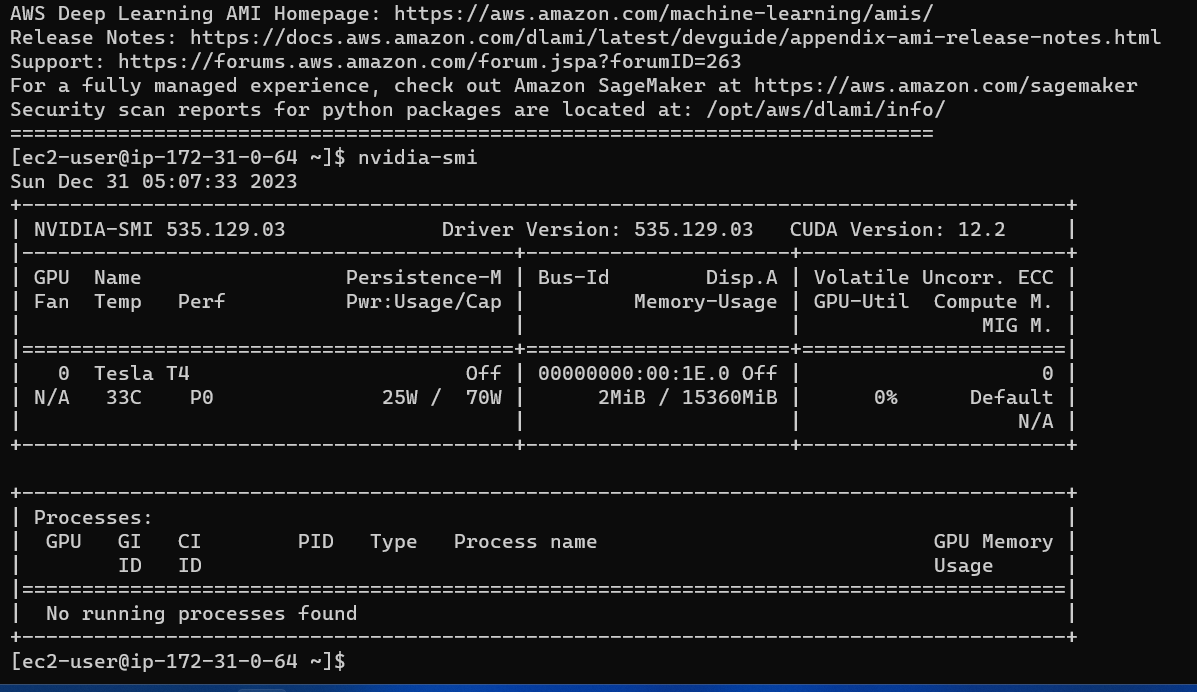
Mit 16 GB VRAM passen alle drei Modelle leicht ohne Probleme. Die Screenshots und Clips unten zeigen die Echtzeit-Fragen-Answer-Fähigkeit des auf AWS bereitgestellten Nepse-Chatbot.
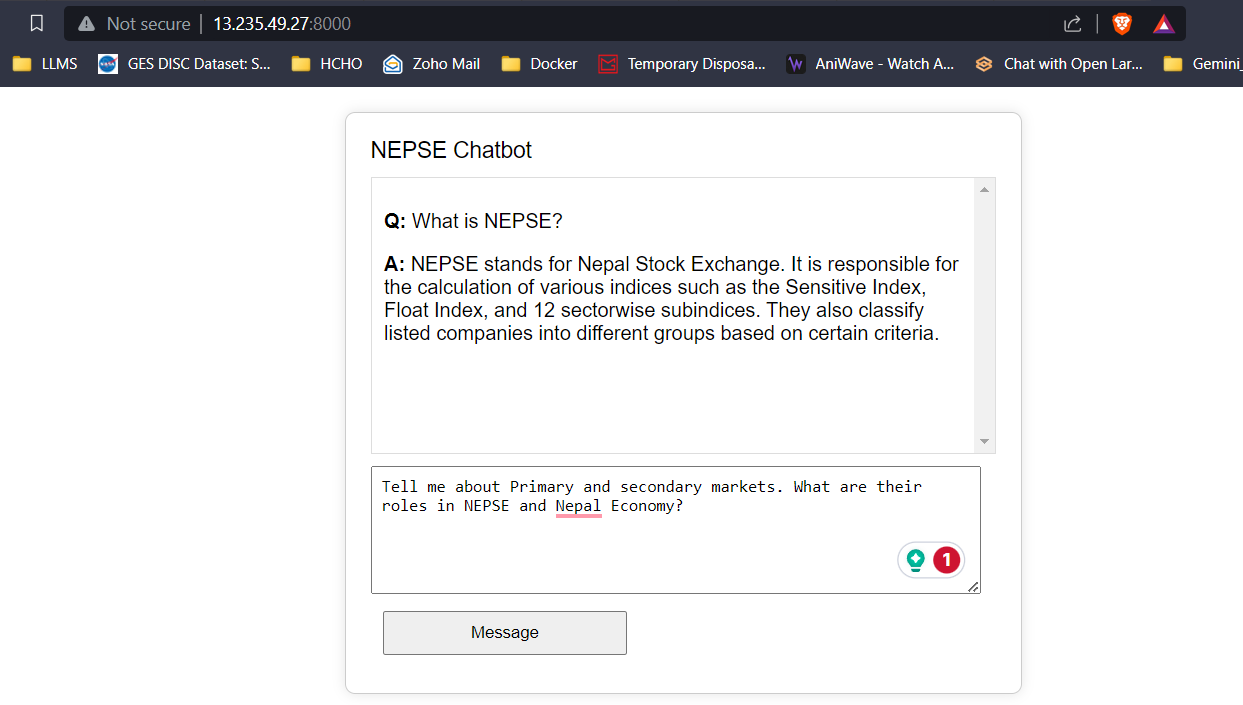
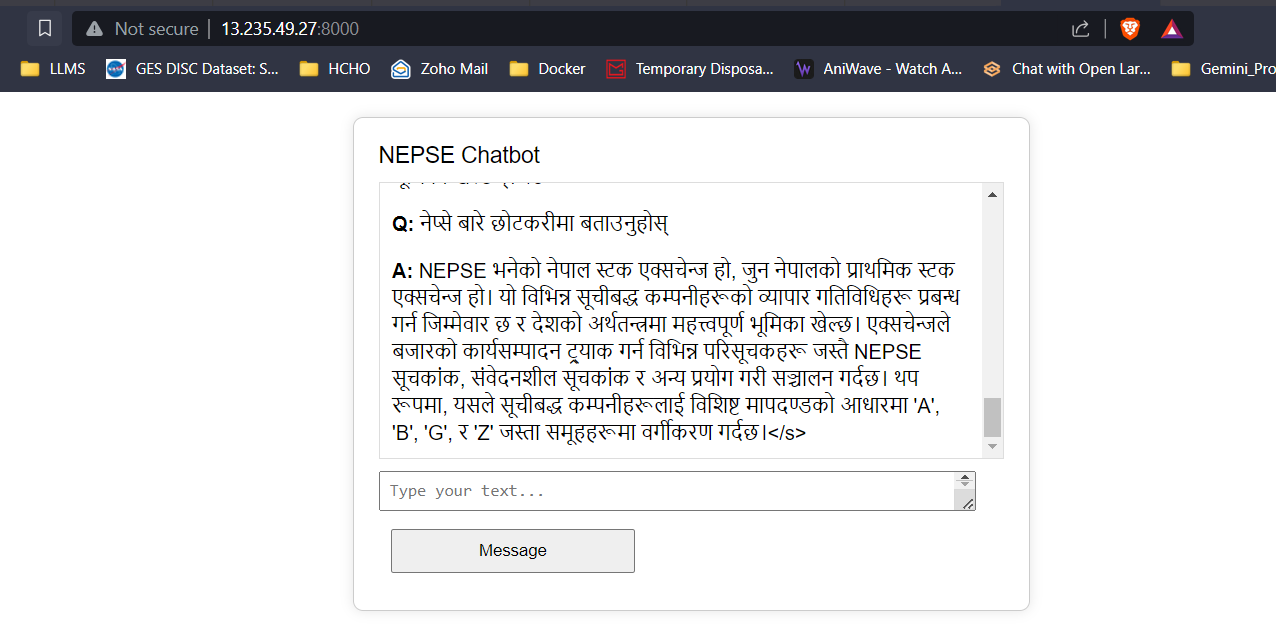
LLM -Antwort -Streaming (wie Chatgpt)
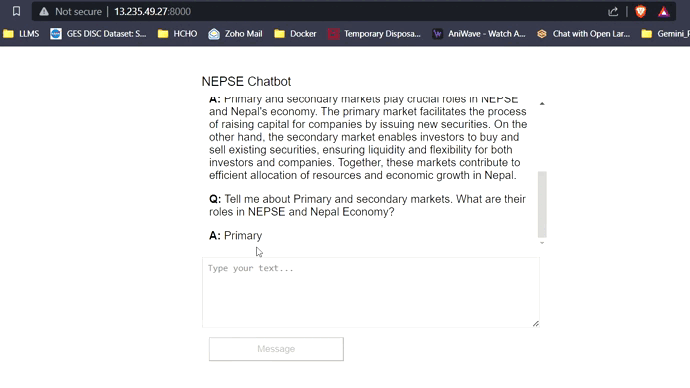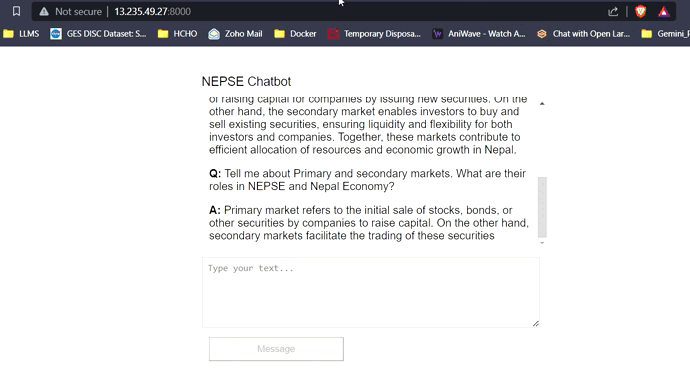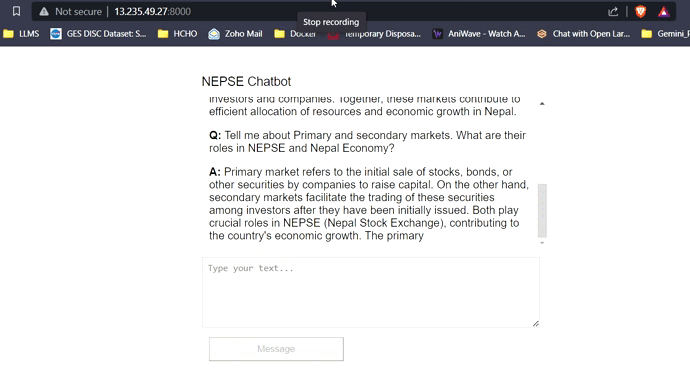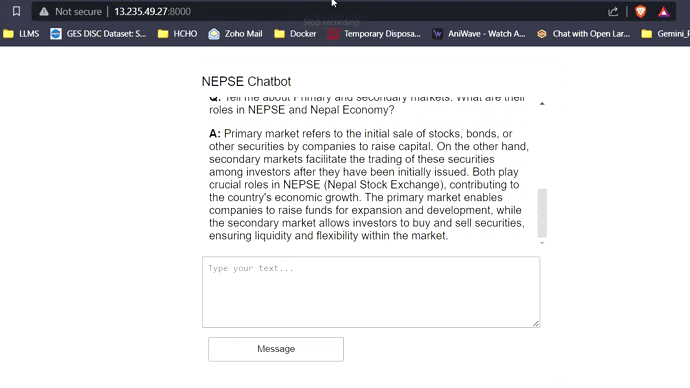
Klicken Sie auf den Link unten, um das vollständige Video anzusehen/herunterzuladen.
Video ansehen


