NEPSE Chatbot Using Retrieval augmented generation and reranking
1.0.0
Fonte da imagem: MK Pavan Kumar
Fonte da imagem: Pinecone
Este projeto aproveita os modelos de código aberto para criar um chatbot para o NEPSE, o Nepal Stock Exchange Ltd, usando a técnica de geração aumentada de recuperação. O livreto NEPSE PDF é utilizado para resposta à pergunta. O projeto utiliza os seguintes modelos de código aberto:
Intel/Chat-7b-V3-1: um LLM de código aberto, originalmente desenvolvido pela Intel e quantizado por TheBloke, é usado. Especificamente, a versão quantizada GPTQ de 8 bits é empregada devido à memória limitada.
All-MPNET-BASE-V2: Um transformador de frase de código aberto do rosto abraçado chamado All-MPNET-BASE-V2 é usado para gerar incorporações de alta qualidade.
AAI/BGE-RERANKER-LARGE: Um modelo de reranquitação de código aberto de Hugging Face chamado BGE-Reranker-Large é usado para reunir novamente os documentos recuperados da loja de vetores.
API do Google Translate: A API gratuita do Google Translate é utilizada para realizar a tradução entre o conteúdo nepalês e o inglês.
Os dados de texto do livreto NEPSE são limpos, divididos em pedaços, e as incorporações são desenvolvidas usando transformadores de frases, que são adicionados ao banco de dados do FAISS Vector. Quando o usuário insere uma pergunta, as incorporações da entrada são desenvolvidas e as perguntas são utilizadas para executar uma pesquisa vetorial para recuperar os principais documentos K. Os documentos recuperados são passados para o modelo de reranger para melhorar a qualidade e a relevância das recuperações. Finalmente, os principais documentos do K-Rerranked são passados como contexto para o LLM, com a engenharia imediata adequada para fornecer respostas aos usuários.
Um front -end simples usando HTML, CSS e JavaScript, e um back -end usando o Flask foram desenvolvidos. As respostas/tokens previstos do LLM são transmitidos para o front-end em tempo real para reduzir a latência do usuário e aprimorar a experiência do usuário. O aplicativo é implantado em uma instância G4DN.XLARGE AWS EC2 para inferência em tempo real.
Com 16 GB de VRAM, todos os três modelos se encaixam facilmente sem problemas. As capturas de tela e clipes abaixo mostram a capacidade de resposta a perguntas em tempo real do Chatbot NEPSE implantado na AWS.
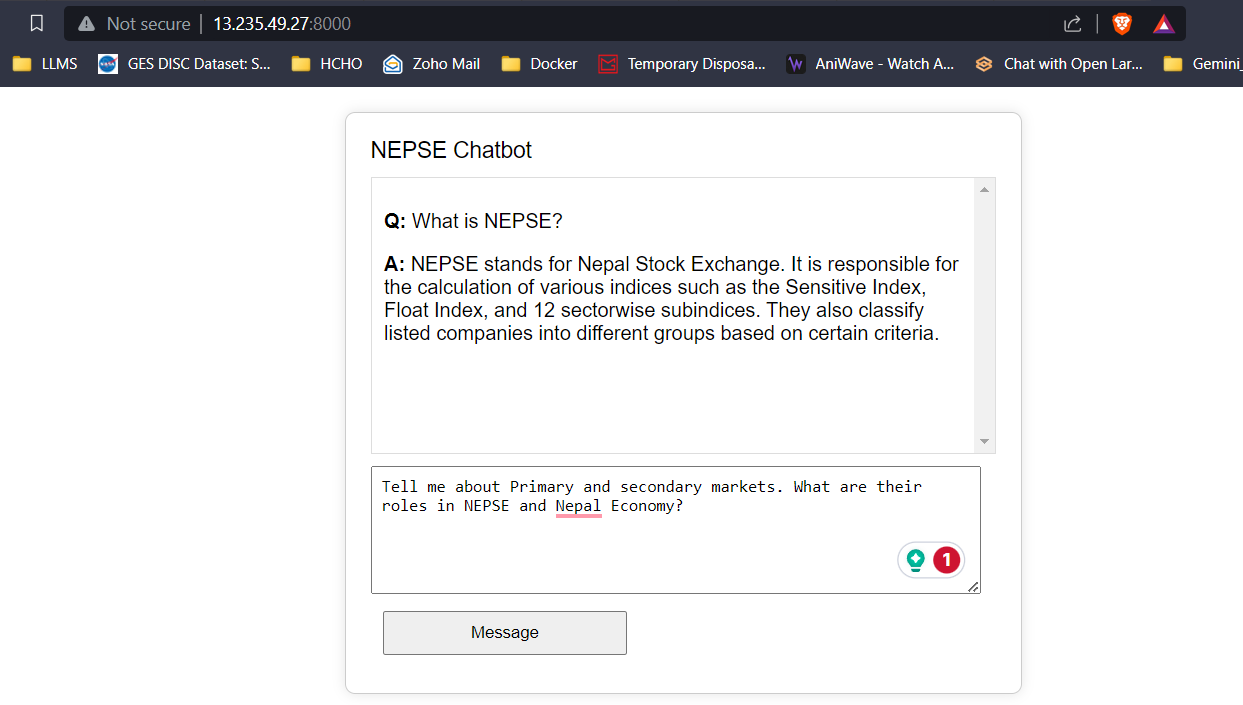
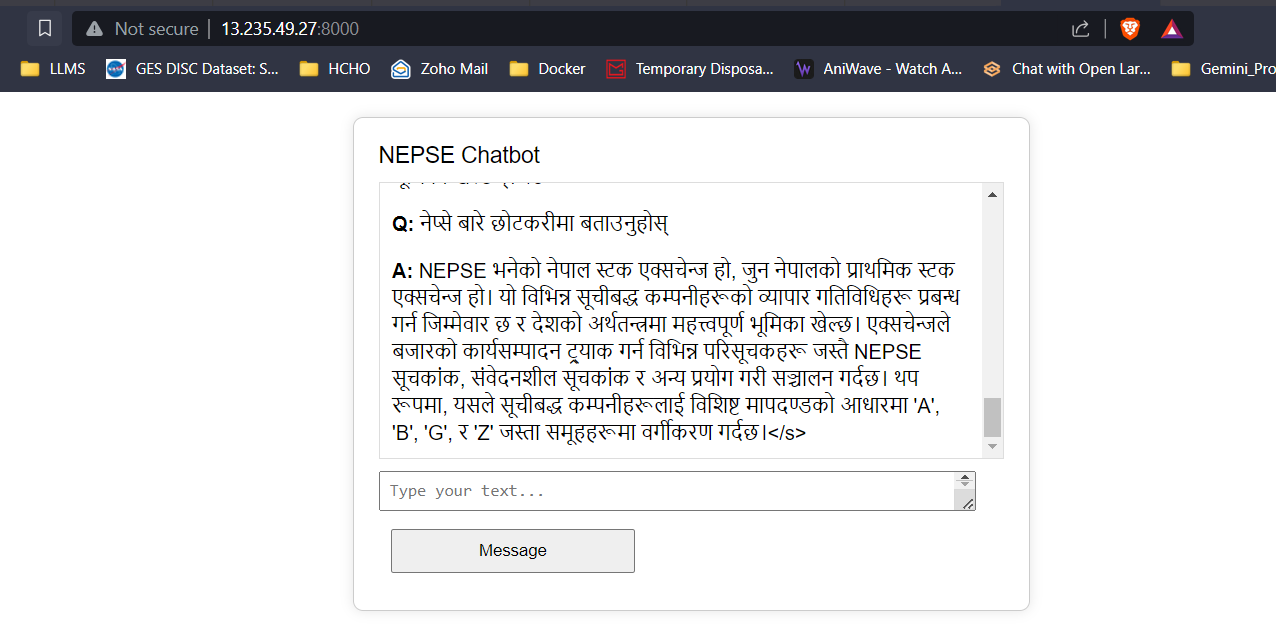
Streaming de resposta LLM (como chatgpt)
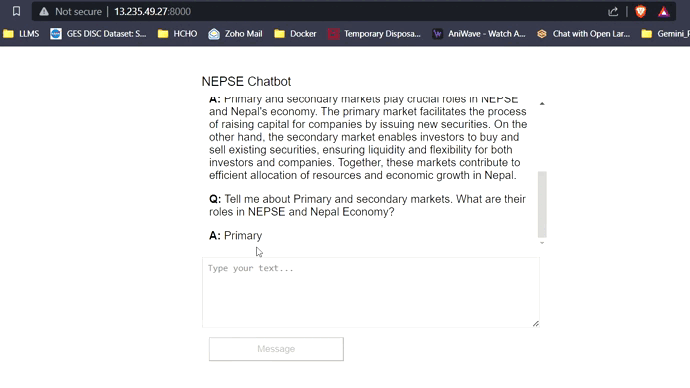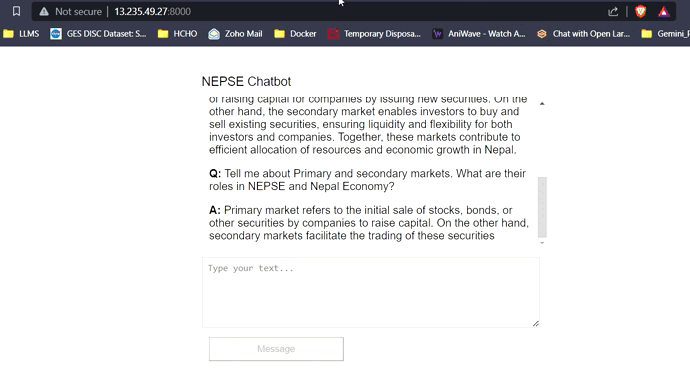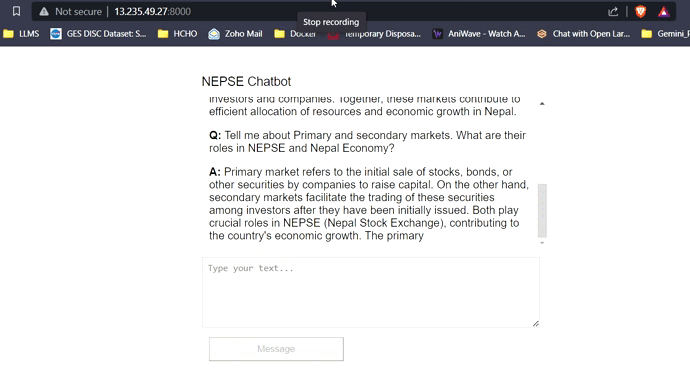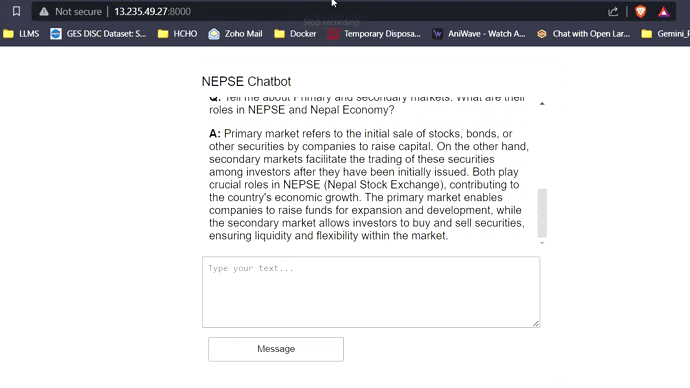
Clique no link abaixo para assistir/baixar o vídeo completo.
Assista ao vídeo


