AI Based Healthcare Monitoring System using IOT
1.0.0
El sistema de monitoreo de atención médica propuesto que utiliza IoT y NLP tiene como objetivo crear una plataforma integrada que incluya una banda inteligente, aplicación móvil y un sistema generativo de preguntas sobre preguntas para facilitar el monitoreo de atención médica y la asistencia médica para pacientes y médicos. Smart Band recopila signos vitales y los almacena en una base de datos para el acceso en tiempo real por pacientes y proveedores de atención médica. Biogpt-Pubmedqa-Prefix-Tuning Model , implementado como un chatbot, ayuda a los pacientes con consultas médicas y proporciona recetas iniciales. Además, el chatbot sirve como asistente médico, ayudando a los médicos con preguntas médicas durante las consultas del paciente. La aplicación móvil sirve como la interfaz principal para los usuarios, tanto los pacientes como los médicos. Incluye portales separados para pacientes y médicos, que ofrecen características distintas adaptadas a sus necesidades.
Consulte nuestra demostración, presentación y documentación
| Manifestación | Presentación | Documentación |
|---|---|---|
La aplicación móvil sirve como la interfaz principal para los usuarios, los pacientes y los médicos. Incluye portales separados para pacientes y médicos, que ofrecen características distintas adaptadas a sus necesidades.
API y tokens utilizados en la aplicación
API_URL = "https://api-inference.huggingface.co/models/Amira2045/BioGPT-Finetuned"
headers = {"Authorization": "Bearer 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"}
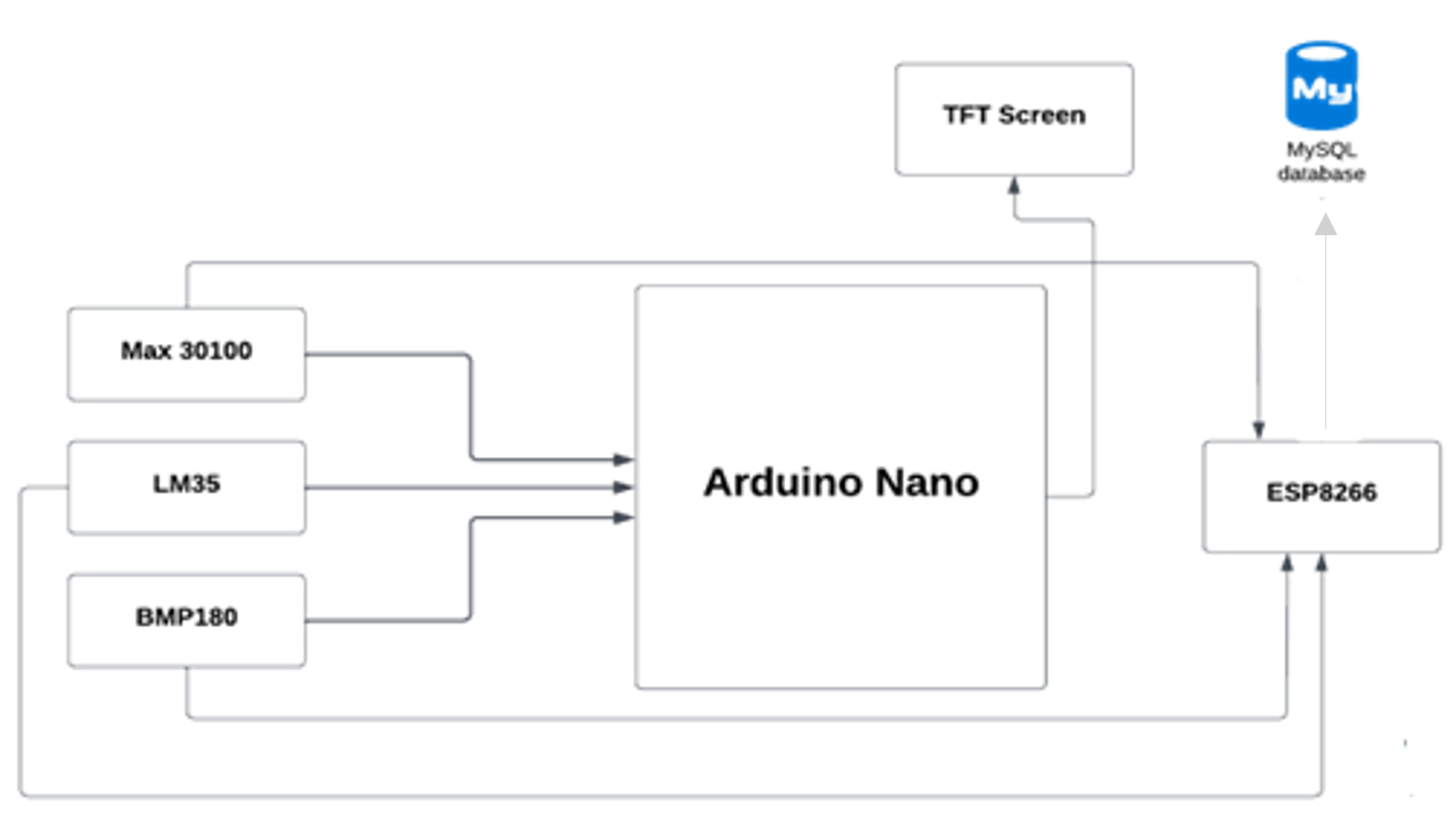
El microcontrolador (Arduino Nano) envía signos vitales a nuestra base de datos utilizando el módulo Wi-Fi ESP8266, luego la aplicación móvil obtiene los datos de la base de datos.
El modelo de ajuste de biogpt-pubmedqa-prefix utilizado para ajustar es biogpt, un modelo de lenguaje grande (LLM) utilizado en el dominio médico, el objetivo del modelo ajustado es responder preguntas médicas. El modelo se implementa como un chatbot dentro de la aplicación móvil, lo que permite a los usuarios solicitar consultas relacionadas con la salud y recibir respuestas precisas. El chatbot actúa como un asistente médico virtual, que proporciona recetas iniciales y guía a los usuarios en función de sus síntomas e historial médico.
| Biogpt-grande | Biogpt-pubmedqa-prefix-ajuste | |
|---|---|---|
| Pérdida | 12.37 | 9.20 |
| Perplejidad | 237016.3 | 1350.9 |
PubMedqa _ Respuesta de preguntas de dominio cerrado Dado PubMed Resumen: El conjunto de datos contiene preguntas sobre investigación biomédica que cubren una amplia gama de temas biomédicos, incluidas enfermedades, tratamientos, genes, proteínas y más. PubMedqa es uno de los conjuntos de datos multimedqa (un punto de referencia para la respuesta de las preguntas médicas). PubMedqa consta de 1k experto etiquetado, 61.2k sin etiquetar y 211.3k generaron instancias de control de calidad artificial con sí/no/tal vez respuestas de opción múltiple y respuestas largas dadas una pregunta junto con un resumen de PubMed como contexto.
Biogpt, que fue anunciado por Microsoft, puede usarse para analizar la investigación biomédica con el objetivo de responder preguntas biomédicas y puede ser especialmente relevante para ayudar a los investigadores a obtener nuevas ideas.
Biogpt es un tipo de modelo de lenguaje generativo, que está capacitado en millones de artículos de investigación biomédica que ya se han publicado. Esto esencialmente significa que Biogpt puede usar esta información para realizar otras tareas como responder preguntas, extraer datos relevantes y generar texto relevante para Biomedical.
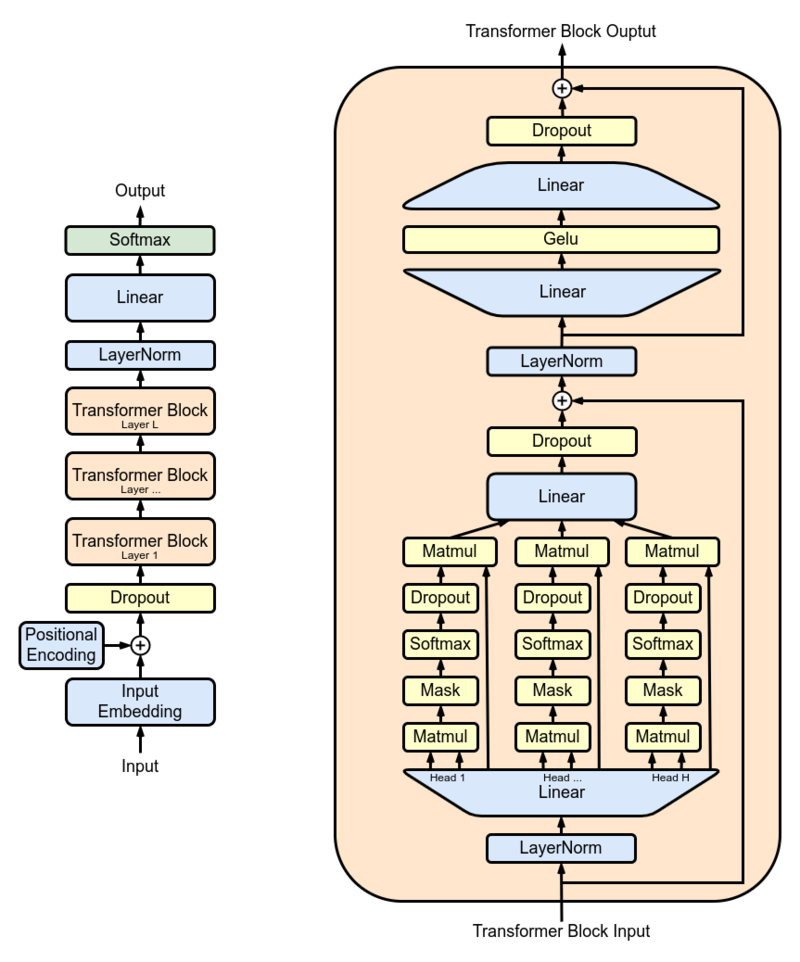
Los investigadores usaron GPT-2 XL como modelo principal y lo entrenaron en 15 millones de resúmenes de PubMed antes de usarlo en el mundo real. GPT-2 XL es un decodificador de transformadores que tiene 48 capas, 1600 tamaños ocultos y 25 cabezas de atención que dan como resultado parámetros 1.5B en total.
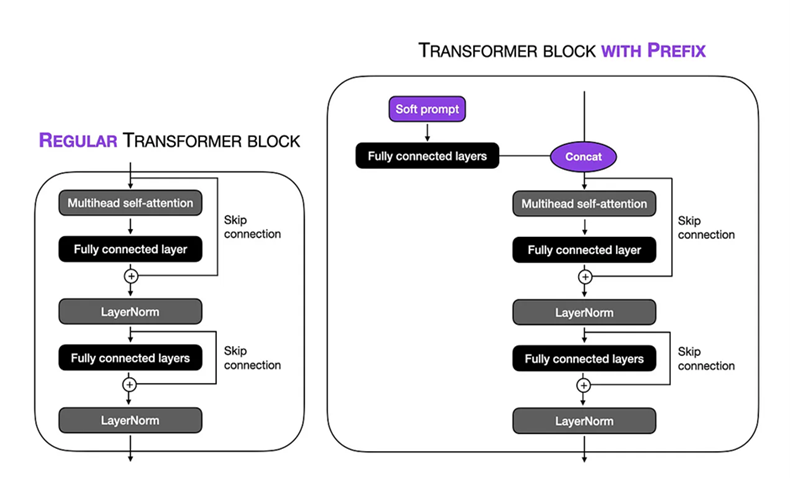
Configuración de ajuste fino: realizamos un aviso suave en la técnica de ajuste de prefijo en el modelo de 1.5b grande Biogpt. La longitud de tokens virtuales se estableció en 10 , lo que nos permitió centrarnos en un contexto específico dentro de la secuencia de entrada. Al congelar las partes restantes del modelo, limitamos el número de parámetros capacitables a 1.5 millones . Durante el proceso de capacitación, utilizamos un TPU VM V3-8 con un tamaño por lotes de 8 y num_warmup_steps = 1000 y gradiente_accumulación_steps = 4 y weight_decay = 0.1 , esto nos permitió ejecutar el procedimiento de capacitación durante 24 pasos, con cada paso que implica el procesamiento de 1024 tokens. Se empleó el Adam Optimizer, utilizando una tasa de aprendizaje máxima de 1 × 10-5 para optimizar el rendimiento del modelo en el transcurso de 3 épocas.
El modelo Biogpt Fineted está alojado en la cara de abrazo , utilizamos la siguiente API para implementar el modelo en nuestra aplicación móvil.
API_URL = "https://api-inference.huggingface.co/models/Amira2045/BioGPT-Finetuned"
headers = {"Authorization": "Bearer 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"}

El microcontrolador (Arduino Nano) envía signos vitales a nuestra base de datos utilizando el módulo Wi-Fi ESP8266, luego la aplicación móvil obtiene los datos de la base de datos.