AI Based Healthcare Monitoring System using IOT
1.0.0
Предлагаемая система мониторинга здравоохранения с использованием IoT и NLP направлена на создание интегрированной платформы, которая включает в себя интеллектуальную полосу, мобильное приложение и генеративную систему ответов на вопросы для облегчения эффективного мониторинга здравоохранения и медицинской помощи для пациентов и врачей. Smart Band собирает жизненно важные признаки и хранит их в базе данных для доступа в режиме реального времени как пациентами, так и медицинскими поставщиками. Biogpt-Pubmedqa-Prefix-модель , внедренная в качестве чат-бота, помогает пациентам с медицинскими расследованием и предоставляет первоначальные рецепты. Кроме того, чат -бот служит помощником врача, помогая врачам с медицинскими вопросами во время консультаций с пациентами. Мобильное приложение служит основным интерфейсом для пользователей, как пациентов, так и врачей. Он включает в себя отдельные порталы для пациентов и врачей, предлагая различные особенности, адаптированные к их потребностям
Проверьте нашу демонстрацию, презентацию и документацию
| Демо | Презентация | Документация |
|---|---|---|
Мобильное приложение служит основным интерфейсом для пользователей, как пациентов, так и врачей. Он включает в себя отдельные порталы для пациентов и врачей, предлагая различные особенности, адаптированные к их потребностям.
API и токены, используемые в приложении
API_URL = "https://api-inference.huggingface.co/models/Amira2045/BioGPT-Finetuned"
headers = {"Authorization": "Bearer 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"}
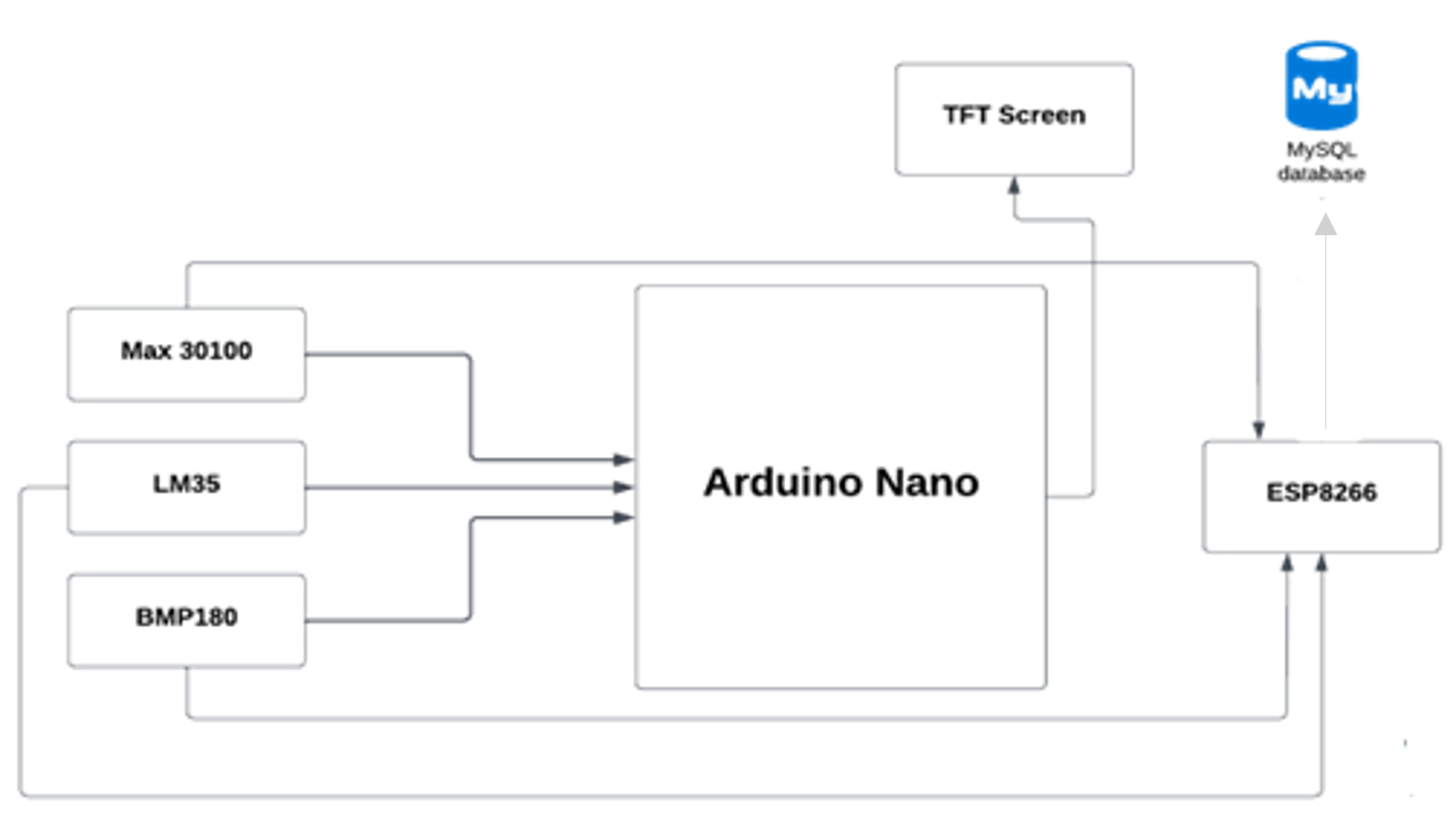
Микроконтроллер (arduino nano) отправляет жизненно важные знаки в нашу базу данных с использованием модуля Wi-Fi ESP8266, затем мобильное приложение извлекает данные из базы данных.
Biogpt-pubmedqa-Prefix-модель, используемая для точной настройки, представляет собой Biogpt, большая языковая модель (LLM), используемая в медицинской области, целью тонкой модели является ответ на медицинские вопросы. Модель развернута как чат-бот в мобильном приложении, что позволяет пользователям задавать вопросы, связанные с здоровьем, и получать точные ответы. Чатбот выступает в качестве виртуального медицинского помощника, предоставляя первоначальные рецепты и направляющие пользователей на основе их симптомов и истории болезни.
| Биогпт-широкий | Biogpt-pubmedqa-prefix-tuning | |
|---|---|---|
| Потеря | 12.37 | 9.20 |
| Недоумение | 237016.3 | 1350.9 |
PubMedqa _ Ответ на вопрос с закрытым доменом. Приведенный PubMed Abstract: набор данных содержит вопросы о биомедицинских исследованиях, которые охватывают широкий спектр биомедицинских тем, включая заболевания, лечение, гены, белки и многое другое. PubmedQA является одним из наборов данных мультимедки (эталон ответа на медицинский вопрос). PubMedQA состоит из 1K-эксперта, помеченного на маркировке, 61,2K немеченой, и 211,3K искусственно сгенерированных экземпляров QA с ответами Yes/No/может быть/, возможно, с множественным выбором и длинными ответами, предоставленными вопросом вместе с Abstract PubMed в качестве контекста.
BIOGPT, который был объявлен Microsoft, может быть использован для анализа биомедицинских исследований с целью ответа на биомедицинские вопросы и может быть особенно актуальным для оказания помощи исследователям получить новое понимание.
BIOGPT - это тип генеративной языковой модели, которая обучается миллионам биомедицинских исследовательских статей, которые уже были опубликованы. По сути, это означает, что BIOGPT может использовать эту информацию для выполнения других задач, таких как ответы на вопросы, извлечение соответствующих данных и генерирование текста, относящегося к биомедицинскому языку.
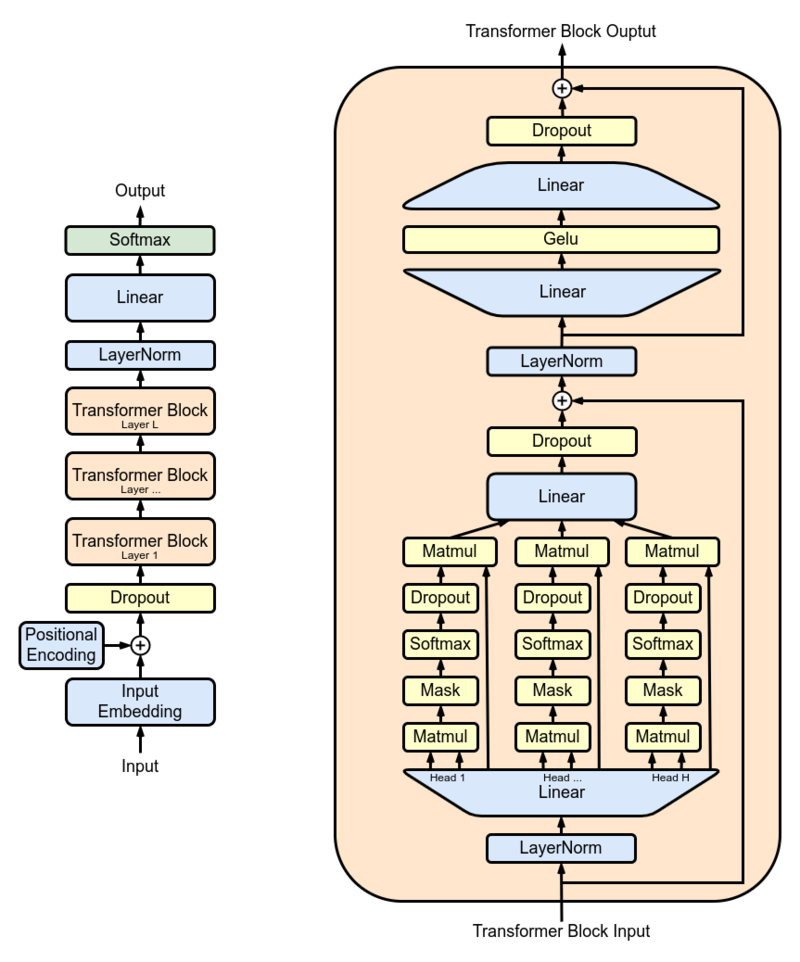
Исследователи использовали GPT-2 XL в качестве основной модели и обучили ее на 15 миллионов тезисов PubMed, прежде чем использовать его в реальном мире. GPT-2 XL-это декодер трансформатора, который имеет 48 слоев, 1600 скрытых размеров и 25 голов внимания, в результате чего в общей сложности 1,5B параметры.
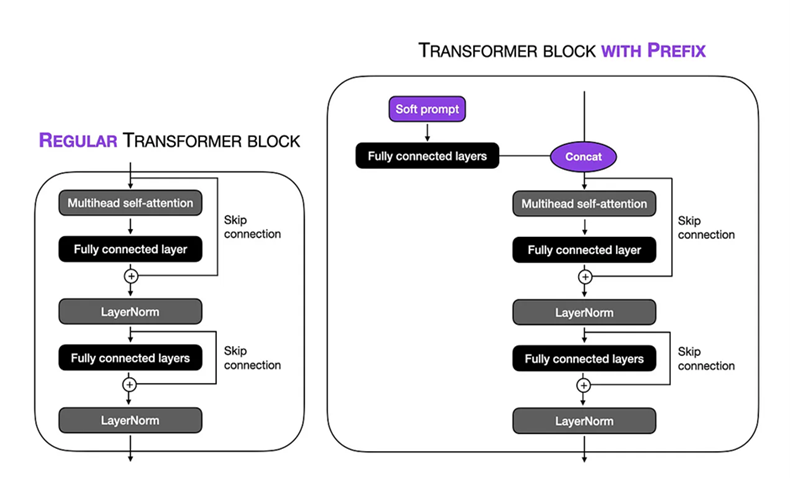
Настройка тонкой настройки: мы выполнили мягкую подсказку в методике настройки префикса на большой модели 1,5B BIOGPT. Длина виртуальных токенов была установлена на 10 , что позволило нам сосредоточиться на конкретном контексте в входной последовательности. Заморозив оставшиеся части модели, мы ограничиваем количество обучаемых параметров до 1,5 миллиона . Во время учебного процесса мы использовали TPU VM V3-8 с размером партии 8 и num_warmup_steps = 1000 и gradient_accumulation_steps = 4 и weet_decay = 0.1 , это позволило нам выполнить процедуру обучения на 24 шага, причем каждый шаг включает в себя обработку из 1024 Tokens. Был использован оптимизатор ADAM, используя пиковую скорость обучения 1 × 10-5 для оптимизации производительности модели в течение 3 эпох.
Menetuned Biogpt Model размещена на обнимании лица , мы использовали следующий API для развертывания модели в нашем мобильном приложении.
API_URL = "https://api-inference.huggingface.co/models/Amira2045/BioGPT-Finetuned"
headers = {"Authorization": "Bearer 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"}

Микроконтроллер (arduino nano) отправляет жизненно важные знаки в нашу базу данных с использованием модуля Wi-Fi ESP8266, затем мобильное приложение извлекает данные из базы данных.