AI Based Healthcare Monitoring System using IOT
1.0.0
Le système de surveillance des soins de santé proposé utilisant l'IoT et la PNL vise à créer une plate-forme intégrée qui comprend une bande intelligente, une application mobile et un système génératif de réponses de questions pour faciliter une surveillance efficace des soins de santé et une assistance médicale pour les patients et les médecins. La bande intelligente collecte des signes vitaux et les stocke dans une base de données pour un accès en temps réel par les patients et les prestataires de soins de santé. Le modèle Biogpt-PubMedqa-Prefix-Tuning , mis en œuvre en tant que chatbot, aide les patients à des demandes médicales et fournit des prescriptions initiales. De plus, le chatbot est assistant du médecin, aidant les médecins à des questions médicales lors des consultations des patients. L'application mobile sert d'interface principale pour les utilisateurs, les patients et les médecins. Il comprend des portails séparés pour les patients et les médecins, offrant des fonctionnalités distinctes adaptées à leurs besoins
Vérifiez notre démo, notre présentation et notre documentation
| Démo | Présentation | Documentation |
|---|---|---|
L'application mobile sert d'interface principale pour les utilisateurs, les patients et les médecins. Il comprend des portails séparés pour les patients et les médecins, offrant des fonctionnalités distinctes adaptées à leurs besoins.
API et jetons utilisés dans l'application
API_URL = "https://api-inference.huggingface.co/models/Amira2045/BioGPT-Finetuned"
headers = {"Authorization": "Bearer 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"}
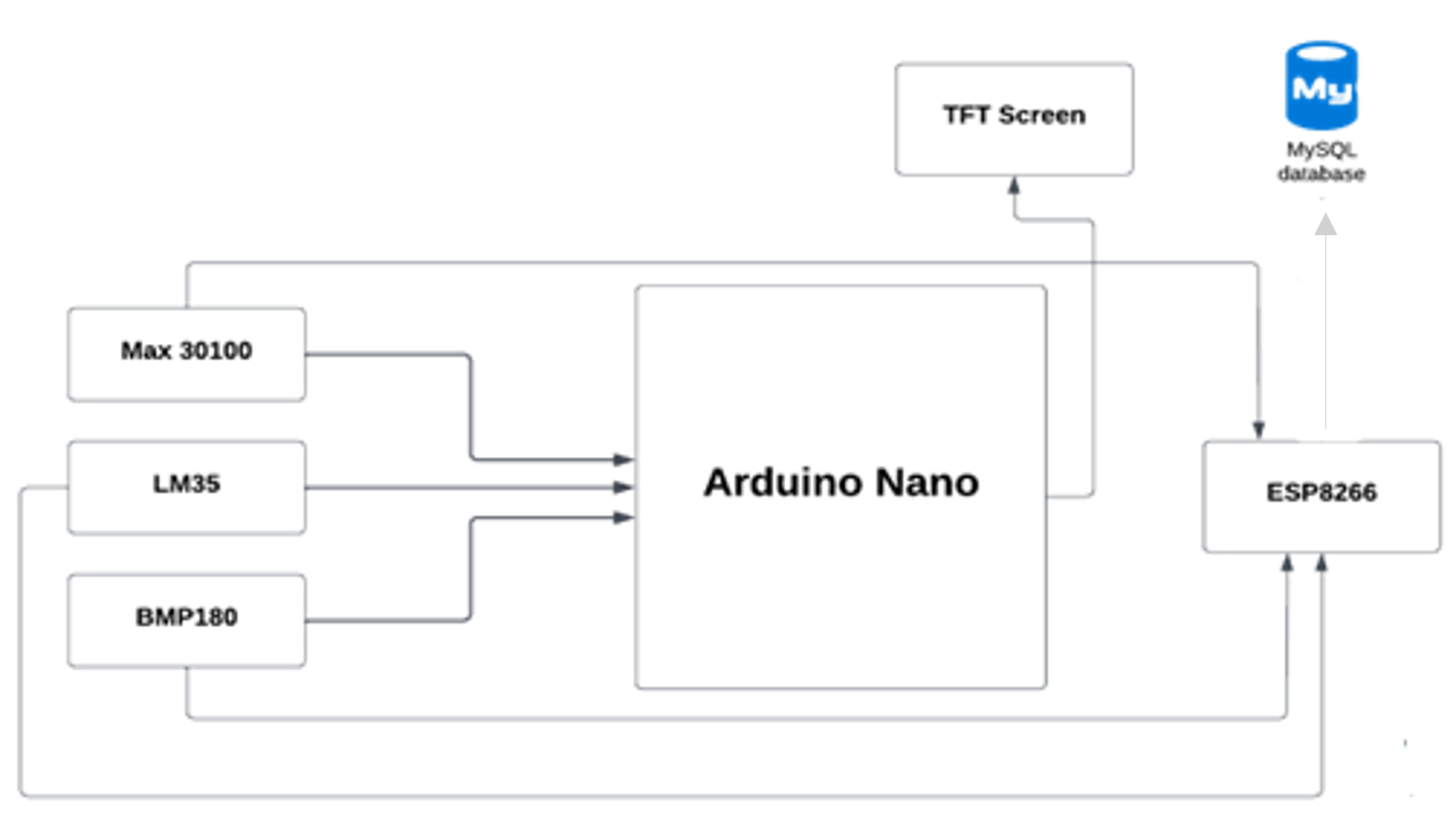
Le microcontrôleur (Arduino Nano) envoie des signes vitaux à notre base de données à l'aide du module Wi-Fi ESP8266, puis l'application mobile récupère les données de la base de données.
Biogpt-pubmedqa-prefix-tuning modèle utilisé pour le réglage fin est Biogpt, un modèle grand langage (LLM) utilisé dans le domaine médical, l'objectif du modèle affiné est de répondre aux questions médicales. Le modèle est déployé sous forme de chatbot dans l'application mobile, permettant aux utilisateurs de demander des requêtes liées à la santé et de recevoir des réponses précises. Le chatbot agit comme un assistant médical virtuel, fournissant des prescriptions initiales et guidant les utilisateurs en fonction de leurs symptômes et de leurs antécédents médicaux.
| Biogpt | Biogpt-pubmedqa-prefix-tun | |
|---|---|---|
| Perte | 12.37 | 9.20 |
| Perplexité | 237016.3 | 1350.9 |
PubMedqa _ Question du domaine fermé Réponse donnée par PubMed Résumé: L'ensemble de données contient des questions sur la recherche biomédicale qui couvrent un large éventail de sujets biomédicaux, y compris les maladies, les traitements, les gènes, les protéines, etc. PubMedqa est l'un des ensembles de données MultimedQA (une référence pour la réponse aux questions médicales). PubMedqa se compose d'un expert 1K étiqueté, 61,2k sans étiquette et 211,3k générés par artificiel avec des instances de QA avec oui / non / peut-être des réponses à choix multiples et de longues réponses étant donné une question avec un résumé PubMed comme contexte.
Biogpt, annoncé par Microsoft, peut être utilisé pour analyser la recherche biomédicale dans le but de répondre aux questions biomédicales et peut être particulièrement pertinente pour aider les chercheurs à obtenir de nouvelles informations.
Biogpt est un type de modèle de langage génératif, qui est formé sur des millions d'articles de recherche biomédicale qui ont déjà été publiés. Cela signifie essentiellement que Biogpt peut utiliser ces informations pour effectuer d'autres tâches comme répondre aux questions, extraire des données pertinentes et générer du texte pertinent pour le biomédical.
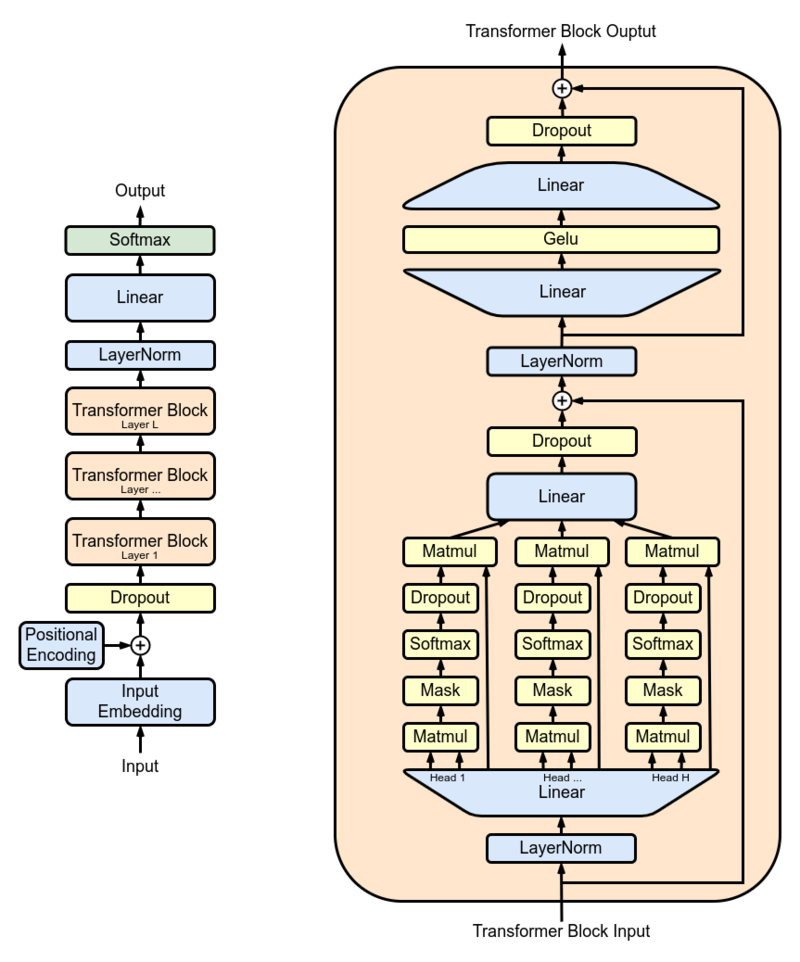
Les chercheurs ont utilisé GPT-2 XL comme modèle principal et l'ont formé sur 15 millions de résumés PubMed avant de l'utiliser dans le monde réel. GPT-2 XL est un décodeur de transformateur qui a 48 couches, 1600 tailles cachées et 25 têtes d'attention, ce qui a résulté en des paramètres de 1,5 million au total.
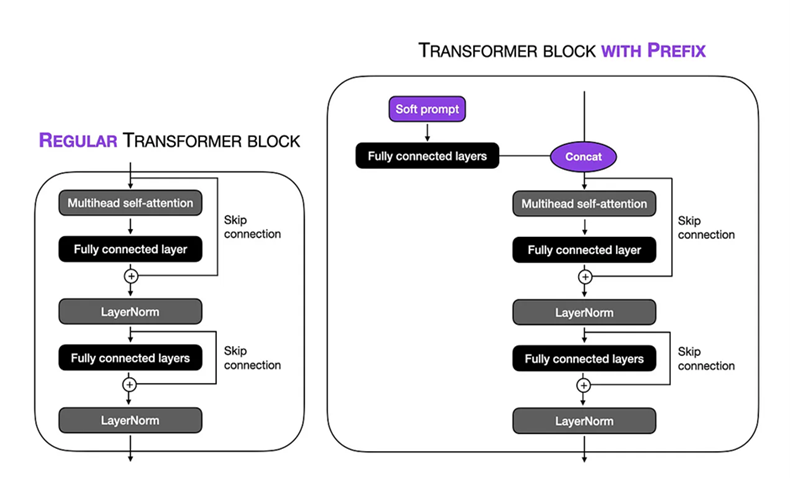
Configuration du réglage fin: nous avons effectué une invite douce dans la technique de réglage du préfixe sur le grand modèle 1.5b Biogpt. La longueur des jetons virtuels a été défini sur 10 , ce qui nous permet de nous concentrer sur un contexte spécifique dans la séquence d'entrée. En gelant les parties restantes du modèle, nous avons limité le nombre de paramètres formables à 1,5 million . Pendant le processus de formation, nous avons utilisé une VM VM V3-8 avec une taille de lot de 8 et NUM_WARMUP_STEPS = 1000 et Gradient_Accumulation_steps = 4 et Weight_decay = 0,1 , cela nous a permis d'exécuter la procédure de formation sur 24 étapes, avec chaque étape impliquant le traitement de 1024 jetons. L'optimiseur ADAM a été utilisé, utilisant un taux d'apprentissage de pointe de 1 × 10−5 pour optimiser les performances du modèle au cours de 3 époques.
Le modèle Biogpt Finetuned est hébergé sur une face étreinte , nous avons utilisé l'API suivante pour déployer le modèle sur notre application mobile.
API_URL = "https://api-inference.huggingface.co/models/Amira2045/BioGPT-Finetuned"
headers = {"Authorization": "Bearer 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"}

Le microcontrôleur (Arduino Nano) envoie des signes vitaux à notre base de données à l'aide du module Wi-Fi ESP8266, puis l'application mobile récupère les données de la base de données.