AI Based Healthcare Monitoring System using IOT
1.0.0
Sistem pemantauan layanan kesehatan yang diusulkan menggunakan IoT dan NLP bertujuan untuk membuat platform terintegrasi yang mencakup pita pintar, aplikasi seluler, dan sistem anjir-an generatif untuk memfasilitasi pemantauan perawatan kesehatan yang efisien dan bantuan medis untuk pasien dan dokter. Smart Band mengumpulkan tanda-tanda vital dan menyimpannya dalam database untuk akses real-time oleh pasien dan penyedia layanan kesehatan. Model tuning biogpt-pubmedqa-prefix , diimplementasikan sebagai chatbot, membantu pasien dengan pertanyaan medis dan memberikan resep awal. Selain itu, chatbot berfungsi sebagai asisten dokter, membantu dokter dengan pertanyaan medis selama konsultasi pasien. Aplikasi seluler berfungsi sebagai antarmuka utama bagi pengguna, baik pasien maupun dokter. Ini termasuk portal terpisah untuk pasien dan dokter, menawarkan fitur berbeda yang disesuaikan dengan kebutuhan mereka
Periksa demo, presentasi, dan dokumentasi kami
| Demo | Presentasi | Dokumentasi |
|---|---|---|
Aplikasi seluler berfungsi sebagai antarmuka utama bagi pengguna, baik pasien, dan dokter. Ini termasuk portal terpisah untuk pasien dan dokter, menawarkan fitur berbeda yang disesuaikan dengan kebutuhan mereka.
API dan token yang digunakan dalam aplikasi
API_URL = "https://api-inference.huggingface.co/models/Amira2045/BioGPT-Finetuned"
headers = {"Authorization": "Bearer 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"}
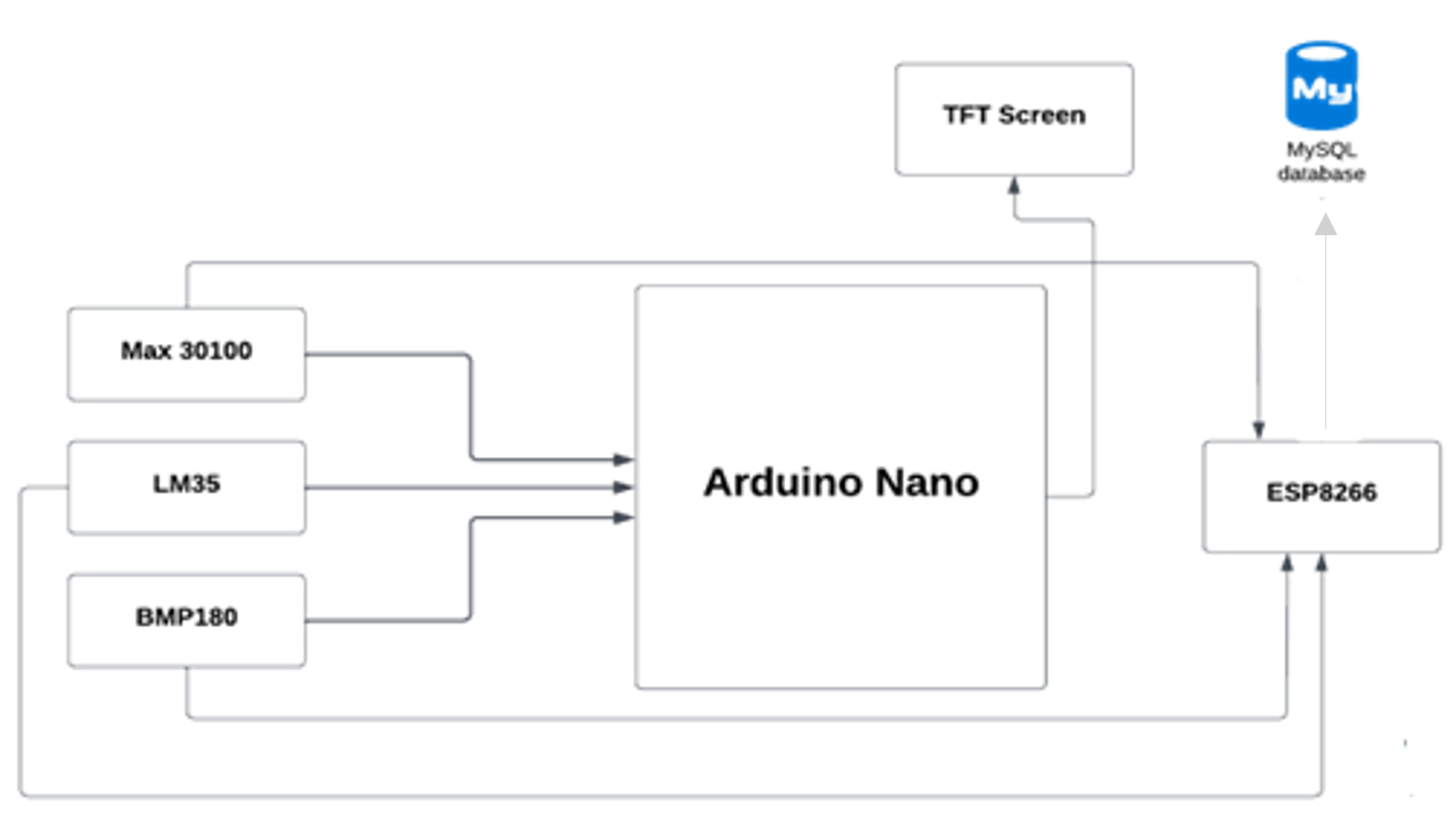
Mikrokontroler (Arduino Nano) mengirimkan tanda-tanda vital ke database kami menggunakan modul Wi-Fi ESP8266, kemudian aplikasi seluler mengambil data dari database.
Model biogpt-Pubmedqa-prefix-tuning yang digunakan untuk fine-tuning adalah Biogpt, model bahasa besar (LLM) yang digunakan dalam domain medis, tujuan dari model yang disesuaikan adalah untuk menjawab pertanyaan medis. Model ini digunakan sebagai chatbot dalam aplikasi seluler, memungkinkan pengguna untuk meminta kueri terkait kesehatan dan menerima tanggapan yang akurat. Chatbot bertindak sebagai asisten medis virtual, memberikan resep awal dan membimbing pengguna berdasarkan gejala dan riwayat medis mereka.
| Biogpt-Large | Biogpt-Pubmedqa-prefix-tuning | |
|---|---|---|
| Kehilangan | 12.37 | 9.20 |
| Kebingungan | 237016.3 | 1350.9 |
PubMedqa _ Pertanyaan domain tertutup menjawab diberikan PubMed Abstrak: Dataset berisi pertanyaan tentang penelitian biomedis yang mencakup berbagai topik biomedis, termasuk penyakit, perawatan, gen, protein, dan banyak lagi. PubMedqa adalah salah satu dataset multimedqa (tolok ukur untuk menjawab pertanyaan medis). PubMedqa terdiri dari 1K Expert berlabel, 61.2k tidak berlabel, dan 211.3K secara artifisial menghasilkan contoh QA dengan jawaban YA/TIDAK/mungkin pilihan ganda dan jawaban panjang yang diberikan pertanyaan bersama dengan PubMed Abstrak sebagai konteks.
Biogpt, yang diumumkan oleh Microsoft, dapat digunakan untuk menganalisis penelitian biomedis dengan tujuan menjawab pertanyaan biomedis dan dapat sangat relevan dalam membantu para peneliti mendapatkan wawasan baru.
Biogpt adalah jenis model bahasa generatif, yang dilatih pada jutaan artikel penelitian biomedis yang telah diterbitkan. Ini pada dasarnya berarti bahwa Biogpt dapat menggunakan informasi ini untuk melakukan tugas -tugas lain seperti menjawab pertanyaan, mengekstraksi data yang relevan, dan menghasilkan teks yang relevan dengan biomedis.
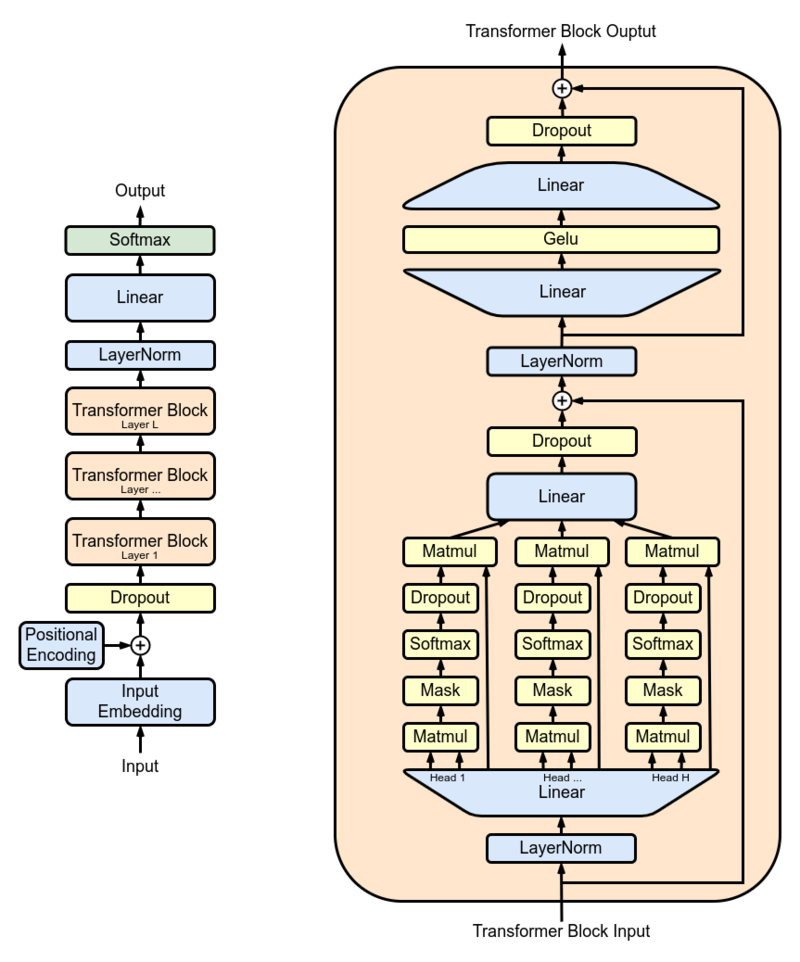
Para peneliti menggunakan GPT-2 XL sebagai model utama dan melatihnya pada 15 juta abstrak PubMed sebelum menggunakannya di dunia nyata. GPT-2 XL adalah dekoder transformator yang memiliki 48 lapisan, 1.600 ukuran tersembunyi dan 25 kepala perhatian menghasilkan total parameter 1.5b.
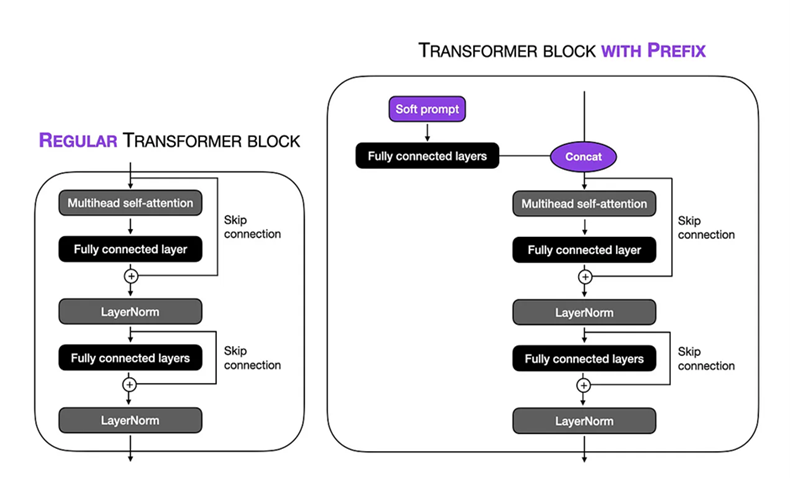
Pengaturan fine-tuning: Kami melakukan soft prompt dalam teknik tuning awalan pada model 1.5b besar biogpt. Panjang token virtual diatur ke 10 , memungkinkan kami untuk fokus pada konteks tertentu dalam urutan input. Dengan membekukan bagian -bagian model yang tersisa, kami membatasi jumlah parameter yang dapat dilatih menjadi 1,5 juta . Selama proses pelatihan, kami menggunakan TPU VM V3-8 dengan ukuran batch 8 dan num_warmup_steps = 1000 dan gradient_accumulation_steps = 4 dan Weight_Decay = 0,1 , ini memungkinkan kami untuk menjalankan prosedur pelatihan lebih dari 24 langkah, dengan setiap langkah yang melibatkan pemrosesan 1024 tocens. Adam Optimizer digunakan, menggunakan tingkat pembelajaran puncak 1 × 10−5 untuk mengoptimalkan kinerja model selama 3 zaman.
Finetuned Biogpt Model di -host pada wajah memeluk , kami menggunakan API berikut untuk menggunakan model pada aplikasi seluler kami.
API_URL = "https://api-inference.huggingface.co/models/Amira2045/BioGPT-Finetuned"
headers = {"Authorization": "Bearer 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"}

Mikrokontroler (Arduino Nano) mengirimkan tanda-tanda vital ke database kami menggunakan modul Wi-Fi ESP8266, kemudian aplikasi seluler mengambil data dari database.