AI Based Healthcare Monitoring System using IOT
1.0.0
Das vorgeschlagene System zur Überwachung des Gesundheitswesens unter Verwendung von IoT und NLP zielt darauf ab, eine integrierte Plattform zu erstellen, die ein Smart-Band, eine mobile Anwendung und ein generatives Fragestandssystem umfasst, um die Überwachung der Gesundheitsversorgung und die medizinische Unterstützung für Patienten und Ärzte zu erleichtern. Die Smart Band sammelt wichtige Anzeichen und speichert sie in einer Datenbank für Echtzeitzugriff sowohl von Patienten als auch von Gesundheitsdienstleistern. Biogpt-PubMedqa-Prefix-Tuning-Modell , der als Chatbot implementiert wurde, unterstützt Patienten mit medizinischen Anfragen und liefert erste Rezepte. Darüber hinaus dient der Chatbot als Arzthelferin und unterstützt Ärzte bei medizinischen Fragen während der Patientenkonsultationen. Die mobile Anwendung dient als Hauptschnittstelle für Benutzer, sowohl Patienten als auch Ärzte. Es umfasst separate Portale für Patienten und Ärzte und bietet unterschiedliche Merkmale, die auf ihre Bedürfnisse zugeschnitten sind
Überprüfen Sie unsere Demo, Präsentation und Dokumentation
| Demo | Präsentation | Dokumentation |
|---|---|---|
Die mobile Anwendung dient als Hauptschnittstelle für Benutzer, sowohl für Patienten als auch für Ärzte. Es enthält separate Portale für Patienten und Ärzte, die unterschiedliche Merkmale bieten, die auf ihre Bedürfnisse zugeschnitten sind.
API und Token, die in App verwendet werden
API_URL = "https://api-inference.huggingface.co/models/Amira2045/BioGPT-Finetuned"
headers = {"Authorization": "Bearer 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"}
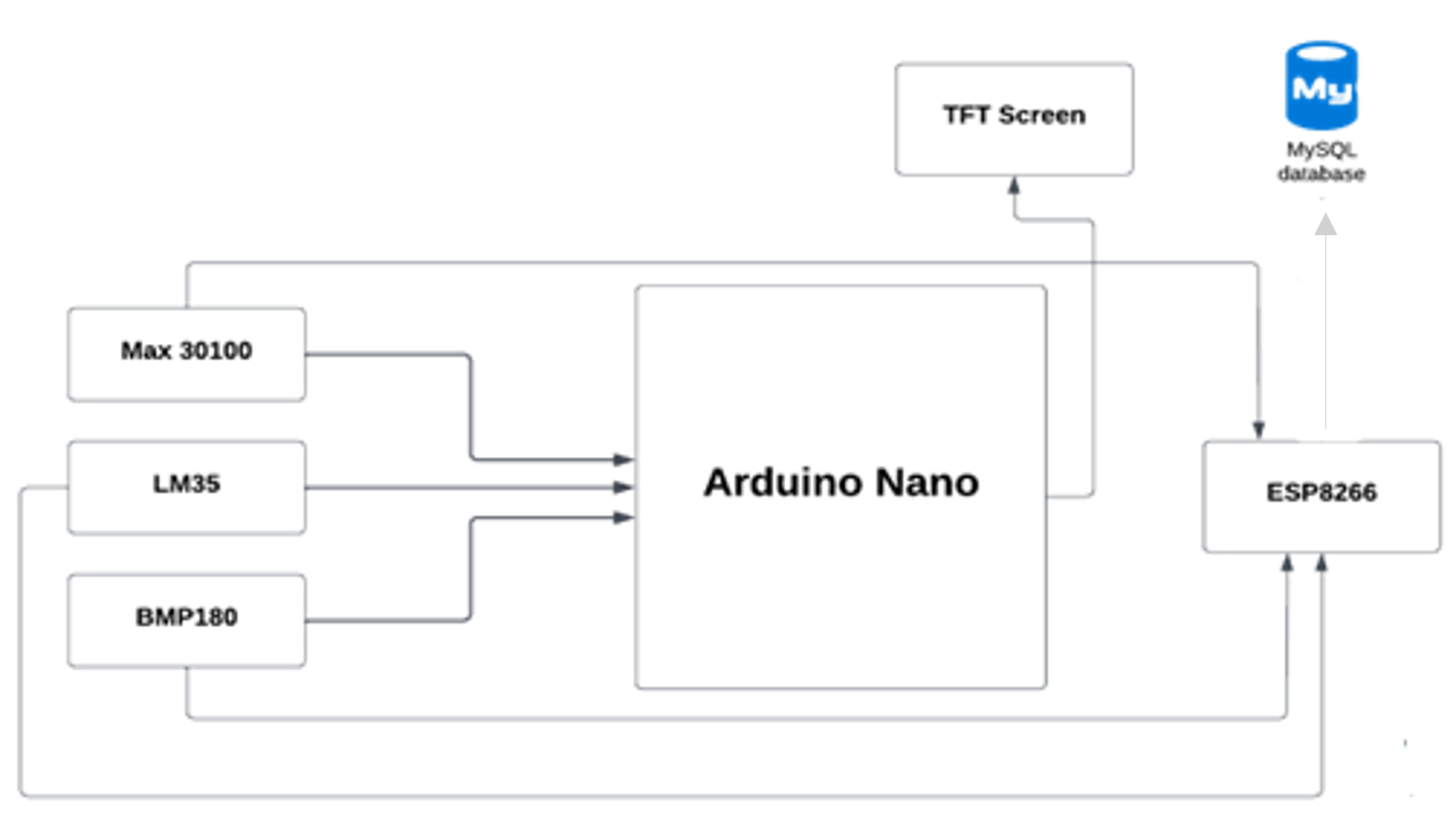
Der Microcontroller (Arduino Nano) sendet wichtige Zeichen in unserer Datenbank mit dem Wi-Fi-Modul ESP8266, dann holt die mobile Anwendung die Daten aus der Datenbank ab.
Biogpt-PubMedqa-Prefix-Tuning-Modell, das für die Feinabstimmung verwendet wird, ist Biogpt, ein im medizinischer Domäne verwendetes großes Sprachmodell (LLM). Das Ziel des fein abgestimmten Modells besteht darin, medizinische Fragen zu beantworten. Das Modell wird in der mobilen Anwendung als Chatbot bereitgestellt, sodass Benutzer gesundheitsbezogene Abfragen fragen und genaue Antworten erhalten können. Der Chatbot fungiert als virtueller medizinischer Assistent, bietet anfängliche Rezepte und führt Benutzer anhand ihrer Symptome und der Krankengeschichte an.
| Biogpt-Large | Biogpt-PubMedqa-Prefix-Tuning | |
|---|---|---|
| Verlust | 12.37 | 9.20 |
| Verwirrung | 237016.3 | 1350.9 |
PubMedqa _ Fragestellbeantwortung für geschlossene Domänen Angesichts PubMed Abstract: Der Datensatz enthält Fragen zur biomedizinischen Forschung, die eine breite Palette von biomedizinischen Themen abdecken, darunter Krankheiten, Behandlungen, Gene, Proteine und mehr. PubMedqa ist eines der multimedQA -Datensätze (ein Maßstab für die Beantwortung von medizinischen Fragen). PubMedqa besteht aus 1K-Experten, die mit dem bezeichneten, 61,2K unmarkierten und 211,3K künstlich mit Ja/Nordwesten erzeugten QA-Instanzen mit Ja/NO/vielleicht-Multiple-Choice-Antworten und langen Antworten generiert wurden, die eine Frage zusammen mit einem PubMed-Abstract als Kontext angegeben haben.
Biogpt, das von Microsoft bekannt gegeben wurde, kann verwendet werden, um die biomedizinische Forschung mit dem Ziel zu analysieren, biomedizinische Fragen zu beantworten, und kann besonders relevant sein, um Forscher zu helfen, neue Erkenntnisse zu gewinnen.
Biogpt ist eine Art generatives Sprachmodell, das auf Millionen von biomedizinischen Forschungsartikeln geschult wird, die bereits veröffentlicht wurden. Dies bedeutet im Wesentlichen, dass Biogpt diese Informationen verwenden kann, um andere Aufgaben wie die Beantwortung von Fragen, das Extrahieren relevanter Daten und das Generieren von Texten für biomedizinische Relevanz zu verwenden.
Die Forscher verwendeten GPT-2 XL als Hauptmodell und trainierten es auf 15 Millionen PubMed-Abstracts, bevor es in der realen Welt verwendet wurde. GPT-2 XL ist ein Transformator-Decoder mit 48 Schichten, 1600 versteckten Größen und 25 Aufmerksamkeitsköpfen, was insgesamt 1,5B-Parameter führt.
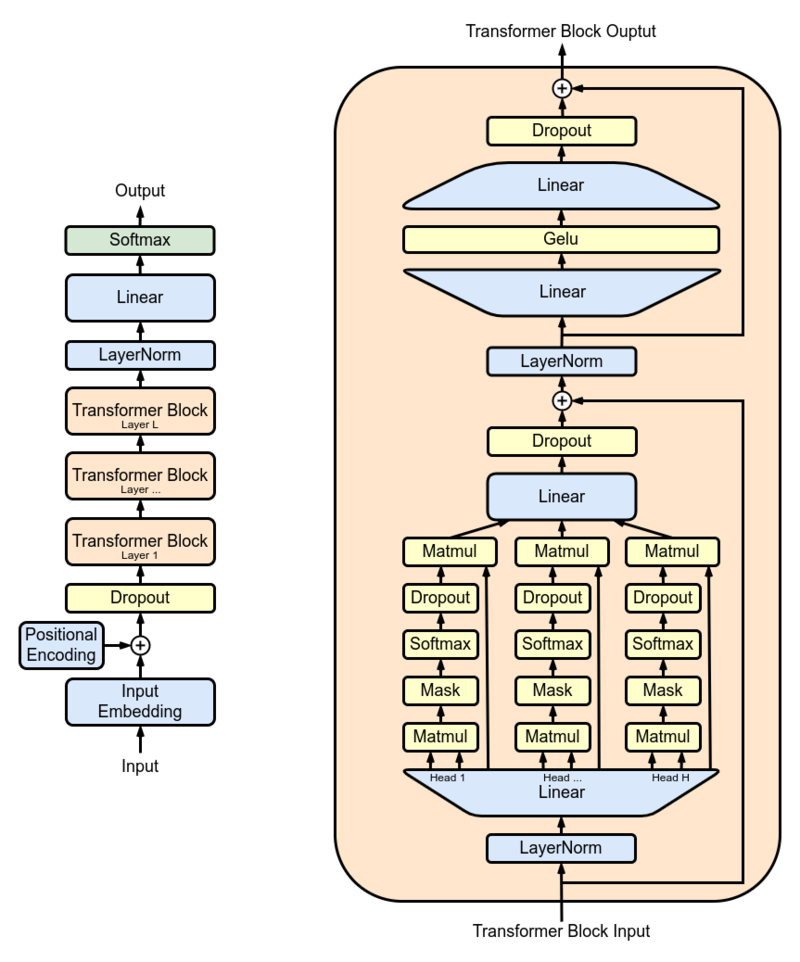
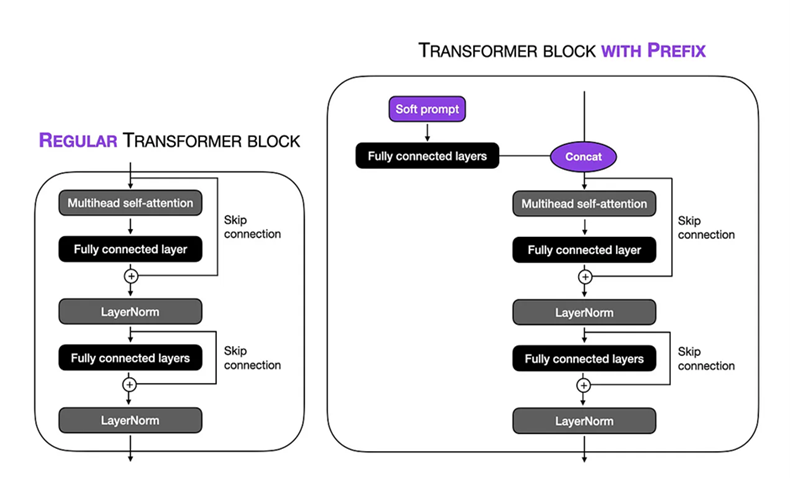
Feinabstimmungs-Setup: Wir haben eine weiche Eingabeaufforderung in der Präfix-Tuning-Technik auf dem Biogpt Large 1,5B- Modell durchgeführt. Die virtuelle Tokenlänge wurde auf 10 eingestellt, sodass wir uns auf einen bestimmten Kontext innerhalb der Eingabesequenz konzentrieren konnten. Durch Einfrieren der verbleibenden Teile des Modells haben wir die Anzahl der trainierbaren Parameter auf 1,5 Millionen eingeschränkt. Während des Schulungsprozesses verwendeten wir einen TPU VM V3-8 mit einer Stapelgröße von 8 und num_warmup_steps = 1000 und gradient_accumulation_steps = 4 und wight_decay = 0.1 , dadurch ermöglichte es uns, den Schulungsverfahren über 24 Schritte auszuführen, wobei jeder Schritt die Bearbeitung von 1024 TOKENs ausführte. Der Adam -Optimierer wurde verwendet, wobei eine Spitzen -Lernrate von 1 × 10–5 verwendet wurde, um die Leistung des Modells im Verlauf von 3 Epochen zu optimieren.
Das Finetuned Biogpt -Modell wird auf dem Umarmungsgesicht gehostet. Wir haben die folgende API verwendet, um das Modell in unserer mobilen App bereitzustellen.
API_URL = "https://api-inference.huggingface.co/models/Amira2045/BioGPT-Finetuned"
headers = {"Authorization": "Bearer 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"}

Der Microcontroller (Arduino Nano) sendet wichtige Zeichen in unserer Datenbank mit dem Wi-Fi-Modul ESP8266, dann holt die mobile Anwendung die Daten aus der Datenbank ab.