AI Based Healthcare Monitoring System using IOT
1.0.0
O sistema de monitoramento de assistência médica proposto usando a IoT e a PNL visa criar uma plataforma integrada que inclua uma banda inteligente, aplicativo móvel e sistema generativo de resposta a perguntas para facilitar o monitoramento da saúde eficiente e a assistência médica para pacientes e médicos. A banda inteligente coleta sinais vitais e os armazena em um banco de dados para acesso em tempo real de pacientes e profissionais de saúde. O modelo de ajuste de prefixo biogpt-pubMedQA , implementado como um chatbot, auxilia os pacientes com consultas médicas e fornece prescrições iniciais. Além disso, o chatbot atua como assistente de médico, ajudando os médicos com perguntas médicas durante as consultas dos pacientes. O aplicativo móvel serve como interface principal para usuários, pacientes e médicos. Inclui portais separados para pacientes e médicos, oferecendo recursos distintos adaptados às suas necessidades
Verifique nossa demonstração, apresentação e documentação
| Demonstração | Apresentação | Documentação |
|---|---|---|
O aplicativo móvel serve como interface principal para usuários, pacientes e médicos. Inclui portais separados para pacientes e médicos, oferecendo recursos distintos adaptados às suas necessidades.
API e tokens usados no aplicativo
API_URL = "https://api-inference.huggingface.co/models/Amira2045/BioGPT-Finetuned"
headers = {"Authorization": "Bearer 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"}
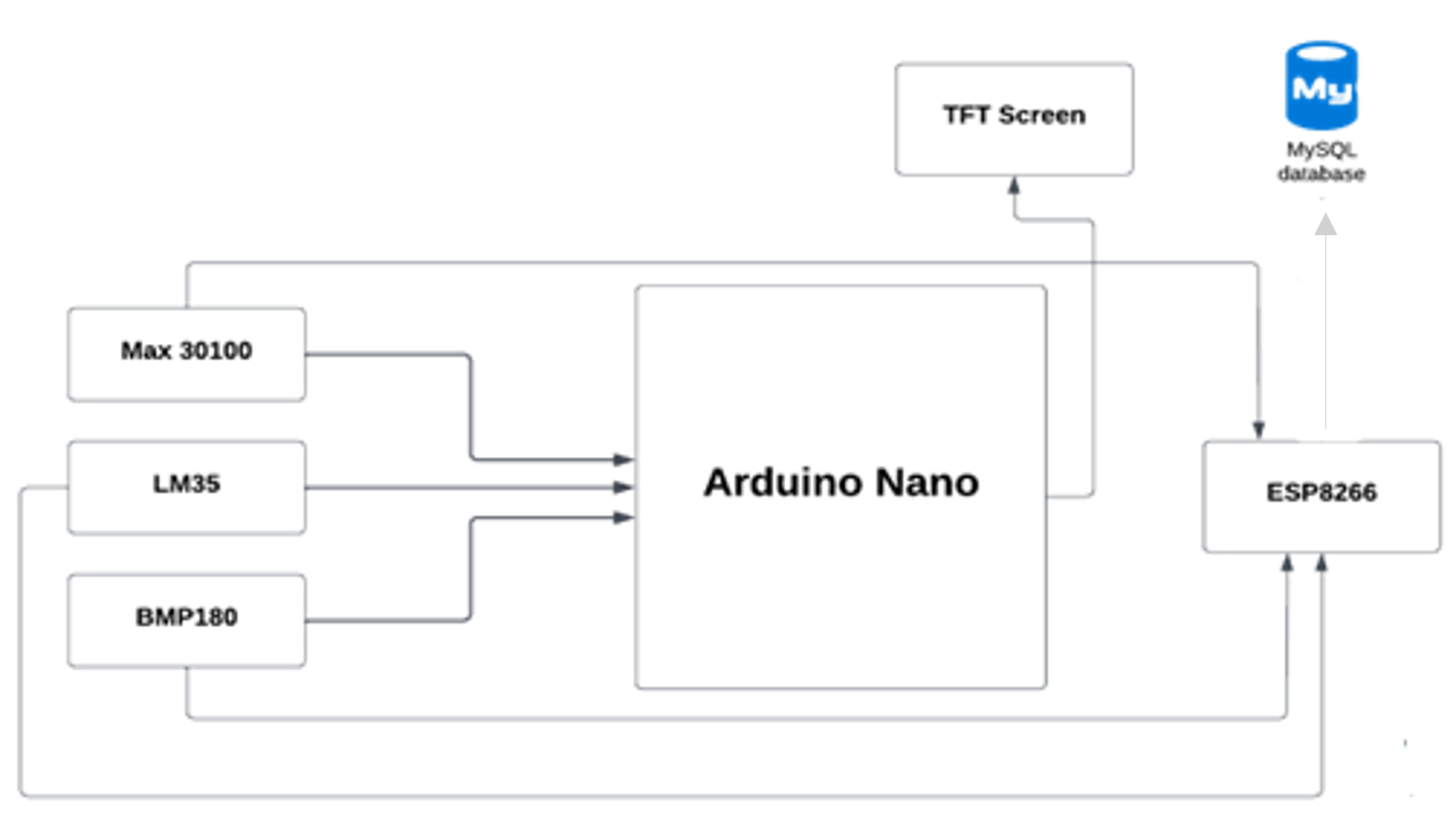
O microcontrolador (Arduino Nano) envia sinais vitais para o nosso banco de dados usando o módulo Wi-Fi ESP8266; em seguida, o aplicativo móvel busca os dados do banco de dados.
O modelo de ajuste de prefixo biogpt-pubMedQA usado para ajuste fino é biogpt, um grande modelo de idioma (LLM) usado no domínio médico, o objetivo do modelo de ajuste fino é responder a perguntas médicas. O modelo é implantado como um chatbot no aplicativo móvel, permitindo que os usuários solicitem consultas relacionadas à saúde e recebam respostas precisas. O chatbot atua como um assistente médico virtual, fornecendo prescrições iniciais e orientando os usuários com base em seus sintomas e histórico médico.
| BioGPT-Large | Tuneamento de prefixos biogpt-pubmedqa | |
|---|---|---|
| Perda | 12.37 | 9.20 |
| Perplexidade | 237016.3 | 1350.9 |
PubMedQa _ Resposta de perguntas do domínio fechado Dado PubMed Resumo: O conjunto de dados contém perguntas sobre pesquisas biomédicas que abrangem uma ampla gama de tópicos biomédicos, incluindo doenças, tratamentos, genes, proteínas e muito mais. O PubMedQA é um dos conjuntos de dados multimedqa (uma referência para responder a perguntas médicas). O PubMedQA consiste em um especialista em 1K rotulado, 61,2k não marcados e 211,3k de qualidade gerados artificialmente com respostas sim/não/talvez de múltipla escolha e respostas longas, dada uma pergunta juntamente com um abstrato do PubMed como contexto.
A BioGPT, anunciada pela Microsoft, pode ser usada para analisar pesquisas biomédicas com o objetivo de responder a perguntas biomédicas e pode ser especialmente relevante para ajudar os pesquisadores a obter novas idéias.
O BioGPT é um tipo de modelo de linguagem generativa, que é treinado em milhões de artigos de pesquisa biomédica que já foram publicados. Isso significa essencialmente que o BioGPT pode usar essas informações para executar outras tarefas, como responder a perguntas, extrair dados relevantes e gerar texto relevante para biomédico.
Os pesquisadores usaram o GPT-2 XL como modelo primário e o treinaram em 15 milhões de resumos do PubMed antes de usá-lo no mundo real. GPT-2 XL é um decodificador do transformador que possui 48 camadas, 1600 tamanhos ocultos e 25 cabeças de atenção, resultando em parâmetros de 1,5b no total.
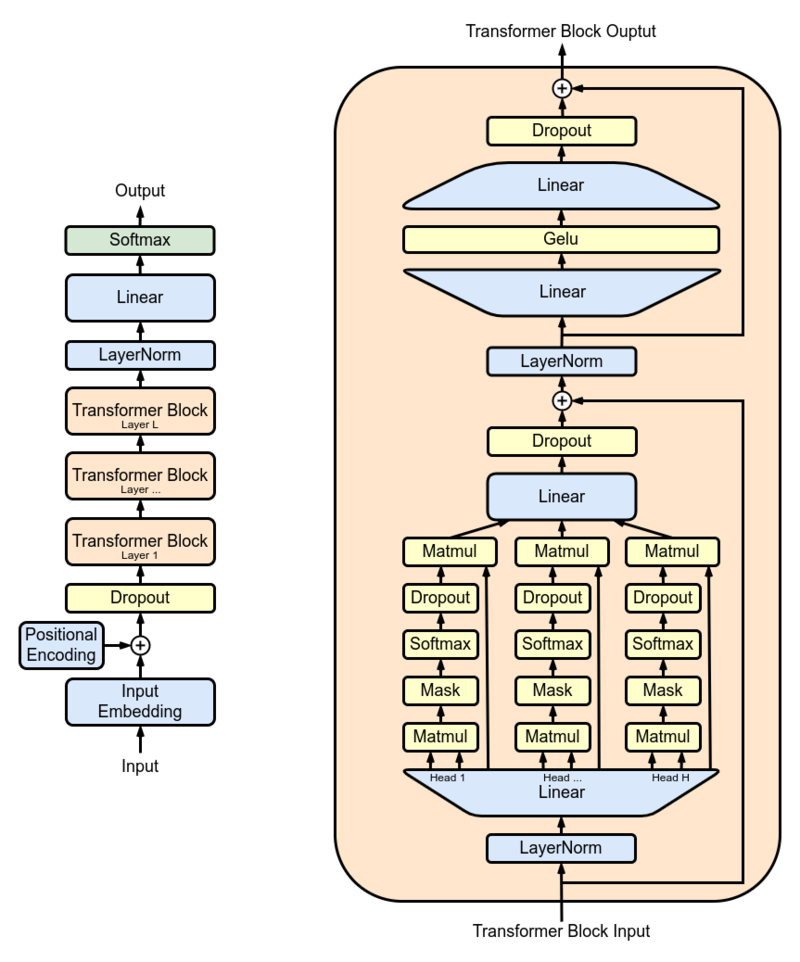
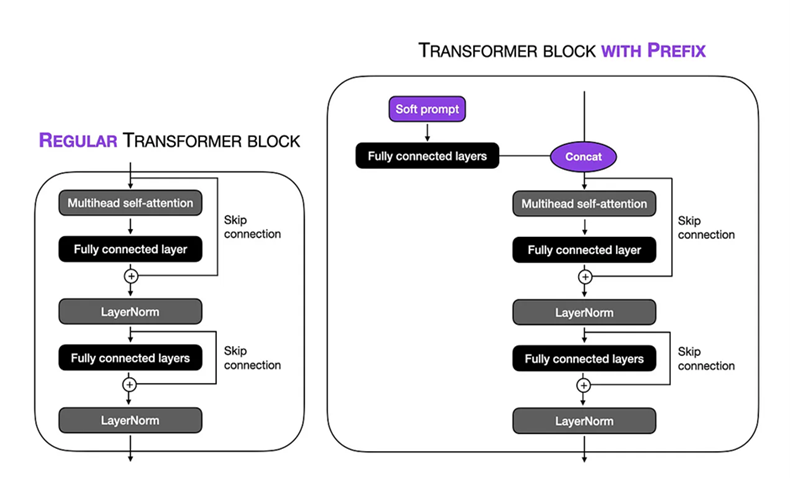
Configuração de ajuste fino: executamos o prompt Soft na técnica de ajuste de prefixo no modelo BioGPT Large 1.5b . O comprimento dos tokens virtuais foi definido como 10 , permitindo -nos focar em um contexto específico na sequência de entrada. Ao congelar as partes restantes do modelo, limitamos o número de parâmetros treináveis a 1,5 milhão . Durante o processo de treinamento, utilizamos um TPU VM V3-8 com um tamanho de lotes de 8 e num_warmup_steps = 1000 e gradient_accumulation_steps = 4 e peso_decay = 0.1 , isso nos permitiu executar o procedimento de treinamento em 24 etapas, com cada etapa envolvendo o processamento de 1024 parakens. O Adam Optimizer foi empregado, utilizando uma taxa de aprendizado de pico de 1 × 10-5 para otimizar o desempenho do modelo ao longo de 3 épocas.
O modelo BioGPT FinetUned está hospedado no rosto abraçado , usamos a seguinte API para implantar o modelo em nosso aplicativo móvel.
API_URL = "https://api-inference.huggingface.co/models/Amira2045/BioGPT-Finetuned"
headers = {"Authorization": "Bearer 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"}

O microcontrolador (Arduino Nano) envia sinais vitais para o nosso banco de dados usando o módulo Wi-Fi ESP8266; em seguida, o aplicativo móvel busca os dados do banco de dados.