AI Based Healthcare Monitoring System using IOT
1.0.0
擬議的使用IoT和NLP的醫療保健監測系統旨在創建一個集成平台,其中包括智能樂隊,移動應用程序和生成性問答系統,以促進對患者和醫生的有效醫療保健監測和醫療援助。智能樂隊收集生命體徵,並將其存儲在數據庫中,以供患者和醫療保健提供者實時訪問。以聊天機器人的形式實施的Biogpt-Pubmedqa-Prefix-tuning模型可以協助患者進行醫學查詢並提供初始處方。此外,聊天機器人是醫生的助手,在患者諮詢期間協助醫生提出醫療問題。移動應用程序是用戶,患者和醫生的主要接口。它包括針對患者和醫生的單獨門戶,提供滿足其需求的獨特功能
檢查我們的演示,演示和文檔
| 演示 | 推介會 | 文件 |
|---|---|---|
移動應用程序是用戶,患者和醫生的主要接口。它包括針對患者和醫生的單獨門戶網站,提供了根據他們的需求量身定制的獨特功能。
應用中使用的API和令牌
API_URL = "https://api-inference.huggingface.co/models/Amira2045/BioGPT-Finetuned"
headers = {"Authorization": "Bearer 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"}
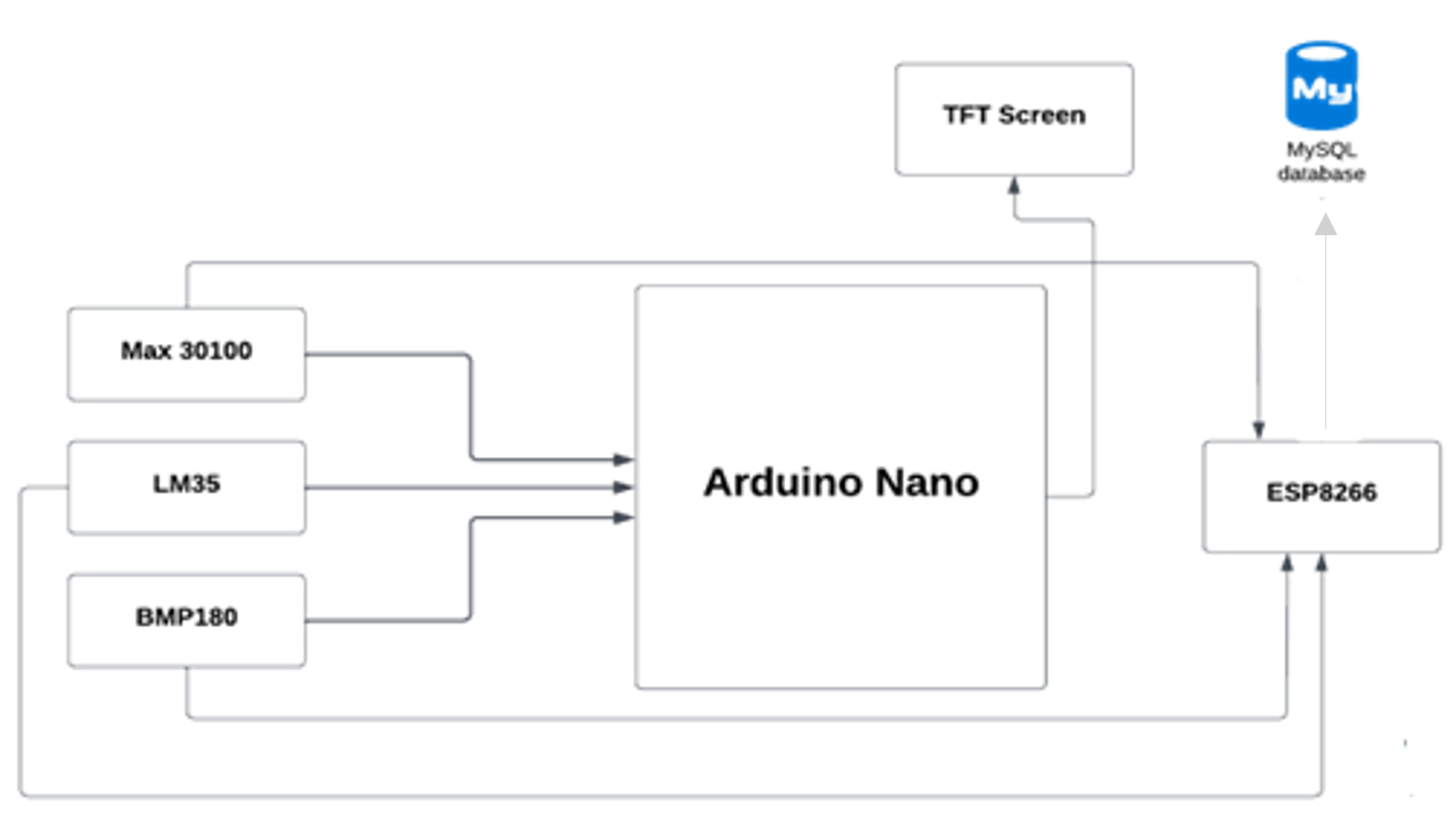
MicroController(Arduino Nano)使用Wi-Fi模塊ESP8266向我們的數據庫發送生命體徵,然後移動應用程序從數據庫中獲取數據。
用於微調的Biogpt-PubmedQA-Prefix-tuning模型是MioGPT,這是一種大型語言模型(LLM),用於醫療領域中,微型模型的目標是回答醫療問題。該模型在移動應用程序中被部署為聊天機器人,使用戶可以詢問與健康相關的查詢並獲得準確的響應。聊天機器人充當虛擬醫療助理,根據症狀和病史提供初始處方並指導用戶。
| 沼氣大 | Miogpt-Pubmedqa-Prefix-tuning | |
|---|---|---|
| 損失 | 12.37 | 9.20 |
| 困惑 | 237016.3 | 1350.9 |
PubMedQA _封閉域問題回答給定的PubMed摘要:數據集包含有關生物醫學研究的問題,這些問題涵蓋了廣泛的生物醫學主題,包括疾病,治療,基因,蛋白質等。 PubMedQA是MultiMEDQA數據集之一(醫學問答的基準)。 PubMedQA由標記為1K專家,61.2K未標記的未標記和211.3k人工生成的QA實例,具有是/否/也許是多項選擇的答案,並給出了帶有PubMed摘要作為上下文的問題。
Microsoft宣布的Biogpt可用於分析生物醫學研究,以回答生物醫學問題,並且在幫助研究人員獲得新的見解方面尤其重要。
BioGPT是一種生成語言模型,該模型接受了已經發表的數百萬生物醫學研究文章的培訓。從本質上講,這意味著BioGPT可以使用此信息執行其他任務,例如回答問題,提取相關數據並生成與生物醫學相關的文本。
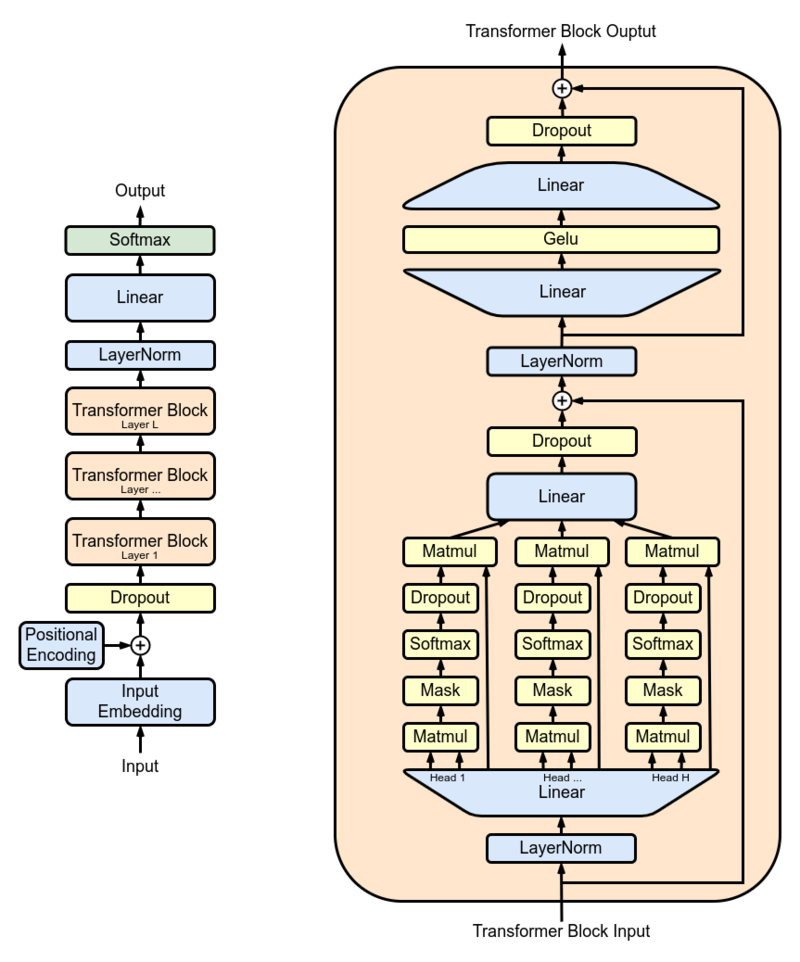
研究人員使用GPT-2 XL作為主要模型,並在現實世界中使用它之前對1500萬個PubMed摘要進行了培訓。 GPT-2 XL是一個變壓器解碼器,具有48層,1600個隱藏尺寸和25個注意力頭,總共有1.5B參數。
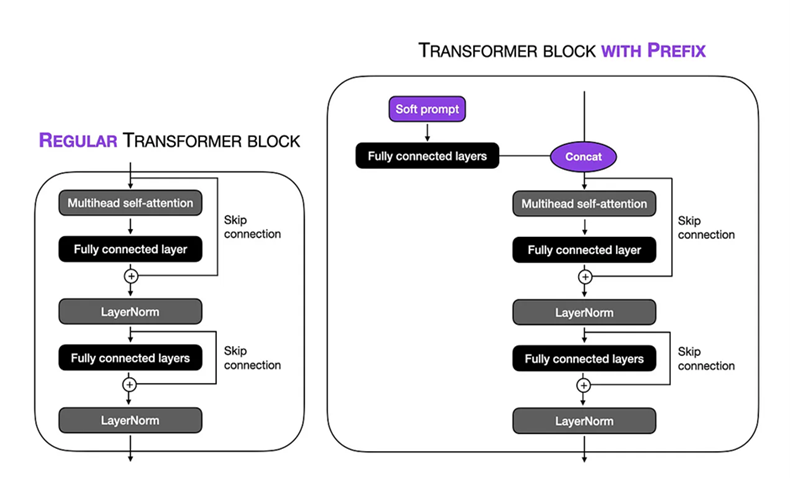
微調設置:我們在Biogpt大型1.5B型號上執行了前綴調整技術的軟提示。虛擬令牌長度設置為10 ,使我們可以專注於輸入序列中的特定上下文。通過凍結模型的其餘部分,我們將可訓練參數的數量限制在150萬。在訓練過程中,我們使用了批量8的TPU VM VM V3-8 ,num_warmup_steps = 1000和gradient_accumulation_steps = 4和stoge_decay = 0.1 ,這使我們能夠在24個步驟上執行訓練過程,每個步驟涉及1024個下貴的處理。採用了ADAM優化器,利用1×10-5的峰值學習率在3個時期內優化了模型的性能。
FineTuned BioGPT模型託管在擁抱面上,我們使用以下API在移動應用程序上部署該模型。
API_URL = "https://api-inference.huggingface.co/models/Amira2045/BioGPT-Finetuned"
headers = {"Authorization": "Bearer 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"}

MicroController(Arduino Nano)使用Wi-Fi模塊ESP8266向我們的數據庫發送生命體徵,然後移動應用程序從數據庫中獲取數據。