AI Based Healthcare Monitoring System using IOT
1.0.0
IoT 및 NLP를 사용하는 제안 된 의료 모니터링 시스템은 스마트 밴드, 모바일 애플리케이션 및 생성적인 질문 분석 시스템이 포함 된 통합 플랫폼을 만들기 위해 환자와 의사를위한 효율적인 의료 모니터링 및 의료 지원을 촉진하는 것을 목표로합니다. 스마트 밴드는 활력 징후를 수집하여 환자와 의료 서비스 제공 업체의 실시간 액세스를 위해 데이터베이스에 저장합니다. 챗봇으로 구현 된 Biogpt-PubmedQa-Prefix-Tuning 모델은 환자에게 의료 문의를 지원하고 초기 처방전을 제공합니다. 또한 챗봇은 의사의 조교로 일하며 의사와의 의학적 질문이있는 의사가 환자 상담 중에 도움을줍니다. 모바일 애플리케이션은 사용자, 환자 및 의사 모두의 주요 인터페이스 역할을합니다. 환자와 의사를위한 별도의 포털이 포함되어 있으며, 필요에 맞는 독특한 기능을 제공합니다.
데모, 프레젠테이션 및 문서를 확인하십시오
| 데모 | 프레젠테이션 | 선적 서류 비치 |
|---|---|---|
모바일 애플리케이션은 사용자, 환자 및 의사의 주요 인터페이스 역할을합니다. 여기에는 환자와 의사를위한 별도의 포털이 포함되어 있으며, 필요에 맞는 독특한 기능을 제공합니다.
API 및 앱에 사용되는 토큰
API_URL = "https://api-inference.huggingface.co/models/Amira2045/BioGPT-Finetuned"
headers = {"Authorization": "Bearer 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"}
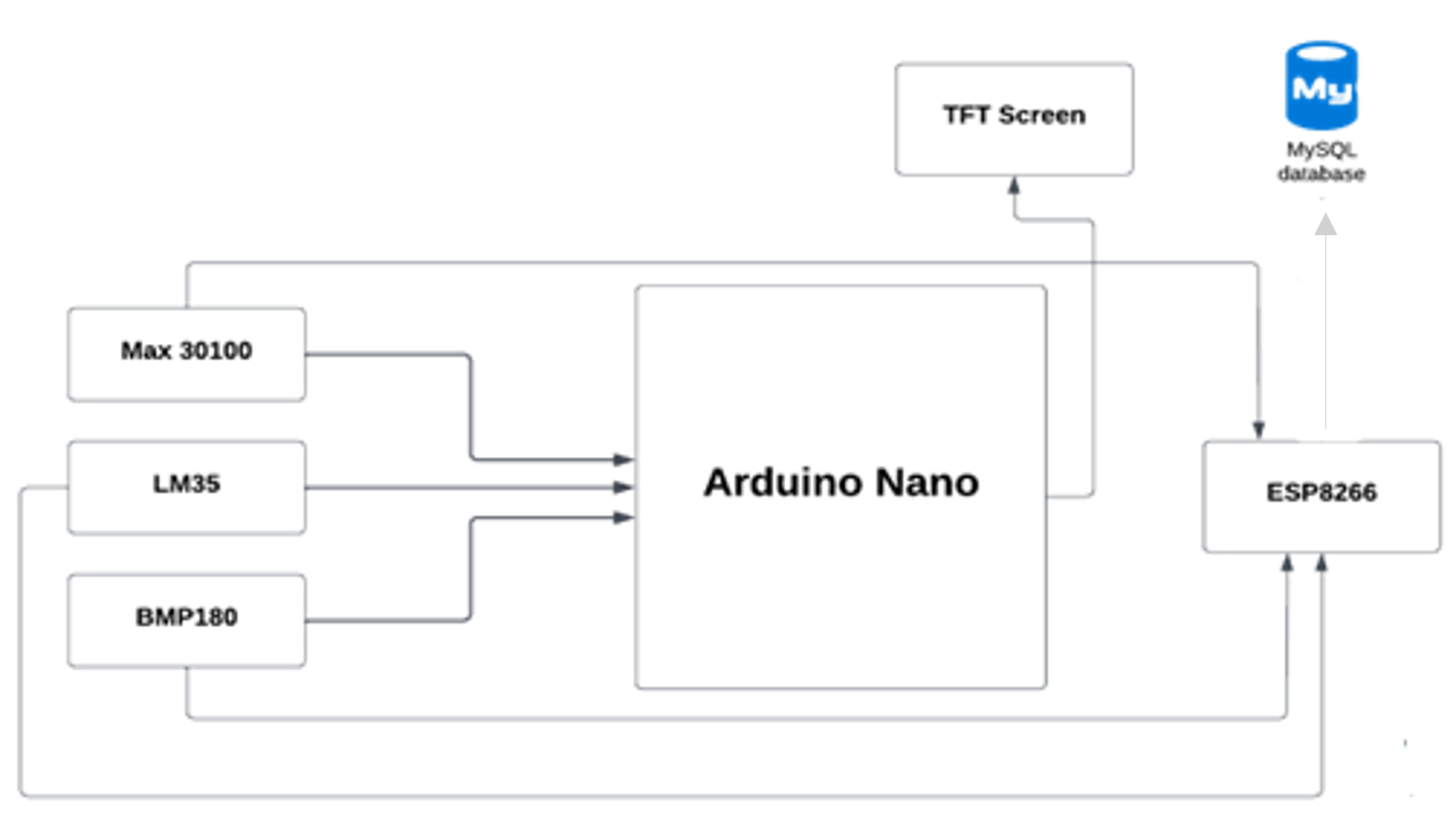
마이크로 컨트롤러 (Arduino Nano)는 Wi-Fi 모듈 ESP8266을 사용하여 데이터베이스에 활력 징후를 보냅니다. 그런 다음 모바일 응용 프로그램은 데이터베이스에서 데이터를 가져옵니다.
미세 조정에 사용되는 Biogpt-PubmedQa-Prefix-Tuning 모델은 의료 영역에 사용되는 대형 언어 모델 (LLM) 인 Biogpt입니다. 미세 조정 모델의 목표는 의료 질문에 답하는 것입니다. 이 모델은 모바일 애플리케이션 내에서 챗봇으로 배포되므로 사용자는 건강 관련 쿼리를 요청하고 정확한 응답을받을 수 있습니다. 챗봇은 가상 의료 보조원 역할을하며, 초기 처방전을 제공하고 증상과 병력을 기반으로 사용자를 안내합니다.
| 바이오 포트 | Biogpt-PubmedQa-Prefix-Tuning | |
|---|---|---|
| 손실 | 12.37 | 9.20 |
| 당황 | 237016.3 | 1350.9 |
PubMedqa _ 폐쇄 도메인 질문에 대한 답변 주어진 PubMed 요약 : 데이터 세트에는 질병, 치료, 유전자, 단백질 등을 포함한 광범위한 생물 의학 주제를 다루는 생의학 연구에 대한 질문이 포함되어 있습니다. PubMedqa는 MultimedQA 데이터 세트 중 하나입니다 (의료 질문 응답을위한 벤치 마크). PubMedqa는 1K 전문가 라벨링, 61.2k 및 211.3K로 구성됩니다. 예/아니오/아마도 객관식 답변과 긴 답변과 함께 PubMed 요약과 함께 컨텍스트와 함께 질문이 주어지면 인위적으로 생성 된 QA 인스턴스로 구성됩니다.
Microsoft가 발표 한 Biogpt는 생물 의학적 질문에 대답하기 위해 생물 의학 연구를 분석하는 데 사용될 수 있으며 연구자들이 새로운 통찰력을 얻도록 도와주는 데 특히 관련이있을 수 있습니다.
Biogpt는 이미 출판 된 수백만 개의 생물 의학 연구 기사에 대해 교육을받은 생성 언어 모델의 한 유형입니다. 이는 본질적으로 BioGPT 가이 정보를 사용하여 질문에 답변하고 관련 데이터를 추출하며 생물 의학과 관련된 텍스트를 생성하는 것과 같은 다른 작업을 수행 할 수 있음을 의미합니다.
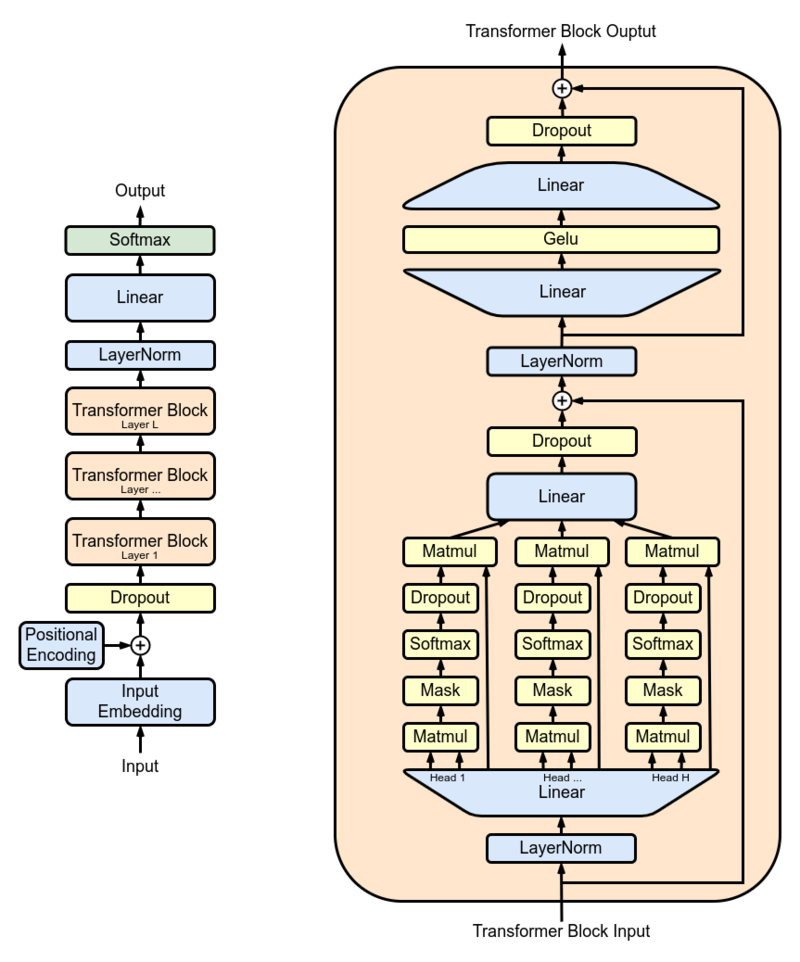
연구원들은 GPT-2 XL을 주요 모델로 사용하고 실제 세계에서 사용하기 전에 1,500 만 개의 PubMed 초록에서 교육했습니다. GPT-2 XL은 48 개의 층, 1600 개의 숨겨진 크기 및 25 개의주의 헤드를 갖는 변압기 디코더로, 총 1.5b 매개 변수를 초래합니다.
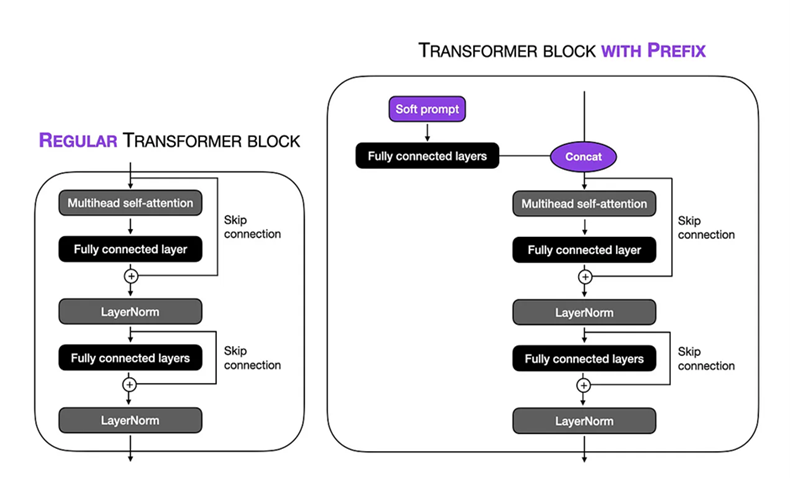
미세 조정 설정 : Biogpt 대형 1.5B 모델에서 접두사 튜닝 기술에서 소프트 프롬프트를 수행했습니다. 가상 토큰 길이는 10 으로 설정되어 입력 순서 내의 특정 컨텍스트에 집중할 수 있습니다. 모델의 나머지 부분을 동결함으로써 훈련 가능한 매개 변수의 수를 150 만으로 제한했습니다. 훈련 과정에서 배치 크기가 8 및 num_warmup_steps = 1000 및 gradient_accumulation_steps = 4 및 weight_decay = 0.1 인 TPU VM V3-8을 사용 하여 24 단계에 걸쳐 훈련 절차를 실행할 수있었습니다. Adam Optimizer는 1 × 10-5 의 피크 학습 속도를 사용하여 3 개의 시대에 걸쳐 모델의 성능을 최적화했습니다.
Finetuned Biogpt 모델은 Hugging Face 에서 호스팅되며 다음 API를 사용하여 모바일 앱에 모델을 배포했습니다.
API_URL = "https://api-inference.huggingface.co/models/Amira2045/BioGPT-Finetuned"
headers = {"Authorization": "Bearer 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"}

마이크로 컨트롤러 (Arduino Nano)는 Wi-Fi 모듈 ESP8266을 사용하여 데이터베이스에 활력 징후를 보냅니다. 그런 다음 모바일 응용 프로그램은 데이터베이스에서 데이터를 가져옵니다.