Open Power/Performance Analysis Tool (OPPAT)
Inhaltsverzeichnis
- Einführung
- Arten von Daten unterstützt
- Oppat -Visualisierung
- Diagrammfunktionen
- Diagrammtypen
- Datenerfassung für OPPAT
- PCM -Datenunterstützung
- Bauen von Oppat
- Oppat laufen
- Abgeleitete Ereignisse
- Verwenden der Browswer GUI -Schnittstelle
- Einschränkungen
Einführung
Open Power/Performance Analysis Tool (OPPAT) ist ein Cross-OS-, Cross-Architecture-Power- und Leistungsanalyse-Tool.
- Cross-OS: Unterstützt Windows ETW Trace-Dateien und Linux/Android Perf/Trace-CMD Trace-Dateien
- Cross-Architecture: Unterstützt Hardware-Ereignisse von Intel und Arm Chips (mit Perf und/oder PCM)
Die Projektwebseite lautet https://patinnc.github.io
Das Quellcode -Repo ist https://github.com/patinnc/oppat
Ich habe der CPU -Blockdiagrammfunktion ein Betriebssystem (OS_View) hinzugefügt. Dies basiert auf den Seiten von Brendan Gregg wie http://www.brendangregg.com/linuxperf.html. Hier finden Sie einige Beispieldaten zum Ausführen einer alten Version von Geekbench V2.4.2 (32 -Bit -Code) auf Arm 64bit Ubuntu Mate V18.04.2 Raspberry Pi 3 B+, 4 Arm Cortex A53 CPUs:
- Ein Video der Änderungen an der OS_View- und ARM A53 -CPU -Blockdiagramm, die Geekbench ausführen:
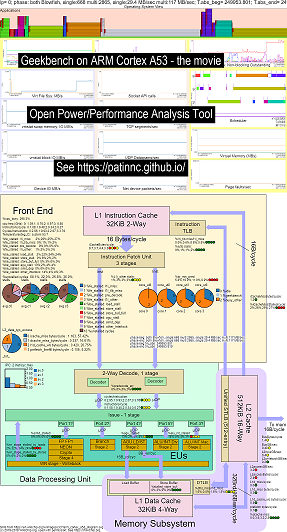
- Es gibt einige einführende Folien, die versuchen, das Layout os_view und cpu_diagram zu erklären, und dann 1 Folie, die die Ergebnisse jeweils jeweils die Ergebnisse der 30 Subtests zeigen
- Eine Excel -Datei der Daten im Film: Excel -Datei von Geekbench The Movie
- Das HTML der Daten im Film ... siehe Geekbench v2.4.2 im 4 Core Arm Cortext A53 mit OS_View, CPU -Diagramm.
- Das Dashboard PNG für alle 30 Phasen, die durch Erhöhen von Anweisungen/Sekunden sortiert sind ... Siehe Arm Cortex A53 Raspberry Pi 3 mit CPU-Diagramm 4-Core-Chip-Dashboard Running Geekbench.
Hier sind einige Beispieldaten zum Ausführen meines Spin-Benchmarks (Speicher-/Cache-Bandbreitentests, ein "Spin" -Keep-CPU-Buy-Test) auf Raspberry Pi 3 B+ (Cortex A53) CPUs:
- Ein Video der Änderungen an OS_View und ARM A53 CPU -Blockdiagramm, das Spin lauft:
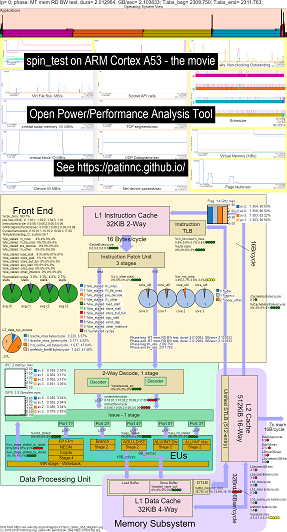
- Es gibt einige einführende Folien, die versuchen, die OS_View-Diagramme und das CPU_Diagram-Layout zu erklären, eine Folie, die zu welchem Zeitpunkt (in Sekunden) jeder Untertest angezeigt wird (so können Sie zu t = x Sekunden gehen, um direkt zu diesem Untertest zu gehen) und dann eine Folie für jeden der 5 Untertests
- Eine Excel -Datei der Daten im Film: Excel -Datei von Geekbench The Movie
- Das HTML der Daten im Film ... siehe Arm Cortex A53 Raspberry Pi 3 mit CPU-Diagramm 4-Core-Chip-Spin-Benchmark.
- Das Dashboard PNG für alle 5 Phasen, die durch Erhöhen von Anweisungen/Sekunden sortiert sind ... Siehe Arm Cortex A53 Raspberry Pi 3 mit CPU-Diagramm 4-Core-Chip-Dashboard Running Spin Benchmark.
Hier finden Sie einige Beispieldaten zum Ausführen von Geekbench auf Haswell CPUs:
- Ein Video der Änderungen an OS_View und Haswell CPU -Blockdiagramm, das Geekbench ausführt:
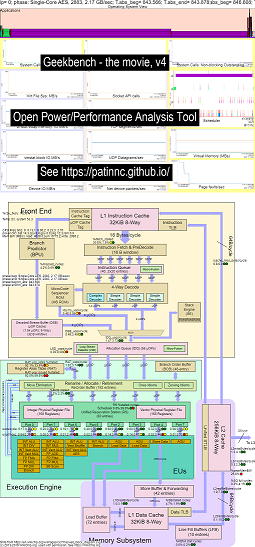
- Es gibt einige einführende Folien, die versuchen, die OS_View-Diagramme und das CPU_Diagram-Layout zu erklären, eine Folie, die zu welchem Zeitpunkt (in Sekunden) jeder Untertest angezeigt wird (so können Sie zu t = x Secs gehen, um direkt zu diesem Untertest zu gehen) und dann eine Folie für jeden der 50 Untertests
- Eine Excel -Datei der Daten im Film: Excel -Datei von Geekbench The Movie
- Das HTML der Daten im Film ... siehe Intel Haswell mit dem CPU-Diagramm 4-CPU-Chip Geekbench.
- Das Dashboard PNG für alle 50 Phasen, die durch Erhöhen von UOPS im Ruhestand/Sekunden sortiert sind ... Siehe Intel Haswell Dashboard mit CPU-Diagramm 4-Core-Chip-Dashboard Running Geekbench.
Hier sind einige Daten zum Ausführen meines "Spin" -Benchmarks mit 4 Untertests auf Haswell-CPUs:
- Der 1. Subtest ist ein Lese -Speicherbandbreitentest. Der L2/L3/Speicherblock wird während des Tests stark verwendet und ins Stocken geraten. Die Ratten -UOPS/-zyklus ist niedrig, da die Ratte größtenteils ins Stocken gerät.
- Der 2. Subtest ist ein L3 -Lese -Bandbreitentest. Die Speicher -BW ist jetzt niedrig. Der L2- und L3 -Block wird während des Tests stark verwendet und ins Stocken geraten. Die Ratten -UOPS/-zyklus ist höher, da die Ratte weniger blockiert ist.
- Der 3. Subtest ist ein L2 -Lese -Bandbreitentest. Der L3 und der Speicher BW sind jetzt niedrig. Der L2 -Block wird während des Tests stark verwendet und ins Stocken geraten. Die Ratten -UOPS/der Rattenzyklus ist sogar noch höher, da die Ratte noch weniger blockiert ist.
- Der 4. Subtest ist ein Spin -Test (nur ein Add -Loop). Die BW L2, L3 und Memory ist nahe Null. Der Ratten -UOPS/Cycle beträgt etwa 3,3 UOPS/Cycle, der sich den 4 UOPS/Cycle Max nähert.
- Ein Video der Änderungen am Haswell -CPU -Blockdiagramm, das mit der Analyse "Spin" ausgeführt wird. Sehen
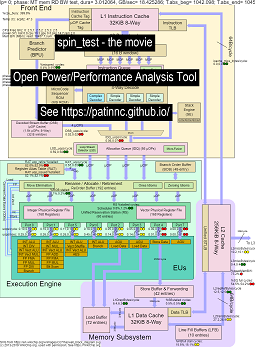
- Eine Excel -Datei der Daten im Film: Excel -Datei aus Spin The Movie
- Das HTML der Daten im Film ... siehe Intel Haswell mit dem CPU-Diagramm 4-CPU-Chip, der Spin-Benchmark läuft.
Der Intel Haswell mit CPU-Diagrammdatensammlungen gilt für einen 4-CPU-Intel-Chip, ein Linux-Betriebssystem, eine HTML-Datei mit 50 HW-Ereignissen über Perf-Sampling und andere gesammelte Daten. CPU_Diagram -Funktionen:
- Beginnen Sie mit einem Blockdiagramm SVG von Wikichip.org (mit Genehmigung verwendet).
- Schauen Sie sich die Ressourcenbeschränkungen an (z. B. Max BW, Max -Bytes/Zyklus auf verschiedenen Pfaden, Mindestzyklen/UOP usw.).
- Berechnen Sie Metriken für die Ressourcennutzung
- Im Folgenden finden Sie eine Tabelle eines Speicher -Lese -Bandbreitentests, in dem die Ressourcenverbrauchsinformationen in einer Tabelle angezeigt werden (zusammen mit einer Schätzung, ob die CPU aufgrund der Verwendung ins Stocken gerät). Die HTML -Tabelle (aber nicht die PNG) enthält Popup -Informationen, wenn Sie über Felder schweben. Die Tabelle zeigt das:
- Der Kern wird mit 55% der max. Möglichen 25,9 GB/s BW in der Speicherbandbreite ins Stocken geraten. Es ist ein Speicher -BW -Test
- Der Superqueue (SQ) ist voll (54,5% für Core0 und 62,3% Core1) der Zyklen (so dass mehr L2 -Anfragen nicht behandelt werden können)
- Der Leitungsfüllpuffer FB ist voll (30% und 51%), sodass Leitungen von L2 nicht auf L1D verschoben werden können
- Das Ergebnis ist, dass das Backend ins Stocken geraten (88% und 87%) der Zyklen, die keine UOPs im Ruhestand sind.
- UOPS scheinen aus dem Schleifenstromdetektor zu kommen (da die LSD -Zyklen/UOP ungefähr dem Ratten -UOPS/-zyklus sind.
- Ein Screenshot des Haswell -CPU -Diagrammspeichers BW -Tabelle
- Unten finden Sie eine Tabelle eines L3 -Lese -Bandbreitentests.
- Jetzt sind die Speicher -BW und der L3 Miss Bytes/Cycle ungefähr Null.
- Der SQ ist weniger blockiert (da wir nicht auf Speicher warten).
- L2 -Transaktionen Bytes/Zyklen sind etwa 2x höher und etwa 67% der maximalen 64 Bytes/Zyklus.
- Der UOPS_RETIRERIRED_STALLS/Cycle ist aus dem MEM -BW -Teststand von 88% auf 66% gesunken.
- Füllpufferstände sind jetzt mehr als 2x höher. Die UOPS kommen immer noch aus der LSD.
- Ein Screenshot des Haswell -CPU -Diagramms L3 BW -Tisch
- Unten finden Sie eine Tabelle eines L2 -Lese -Bandbreitentests.
- Der L2 vermisst Bytes/Zyklus ist viel niedriger als der L3 -Test.
- Der UOPS_RETIRED% Stilled ist jetzt etwa die Hälfte des L3 -Tests bei 34% und die FB -Stände sind ebenfalls etwa 17%.
- UOPS kommen immer noch aus der LSD.
- Ein Screenshot des Haswell -CPU -Diagramms L2 BW -Tisch
- Im Folgenden finden Sie eine Tabelle eines Spin -Tests (keine Ladungen, nur in einer Schleife hinzuzufügen).
- Jetzt gibt es fast Null -Speicher -Subsystemstände.
- Die UOPS stammen aus dem Decodes -Stream -Puffer (DSB).
- RAT RETIRED_UOPS/Zyklus bei 3,31 Zyklen/UOP liegt in der Nähe des maximalen 4,0 -UOPS/-zyklus.
- Die Ratte renoviert_uops %Stilled ist bei %8 ziemlich niedrig.
- Ein Screenshot des Haswell -CPU -Diagramm -Spin -Tisches
Derzeit habe ich nur CPU_Diagram -Filme für Haswell und ARM A53 (da ich keine anderen Systeme zum Testen habe), aber es sollte nicht schwierig sein, andere Blockdiagramme hinzuzufügen. Sie erhalten immer noch alle Diagramme, aber nicht das CPU_diagram.
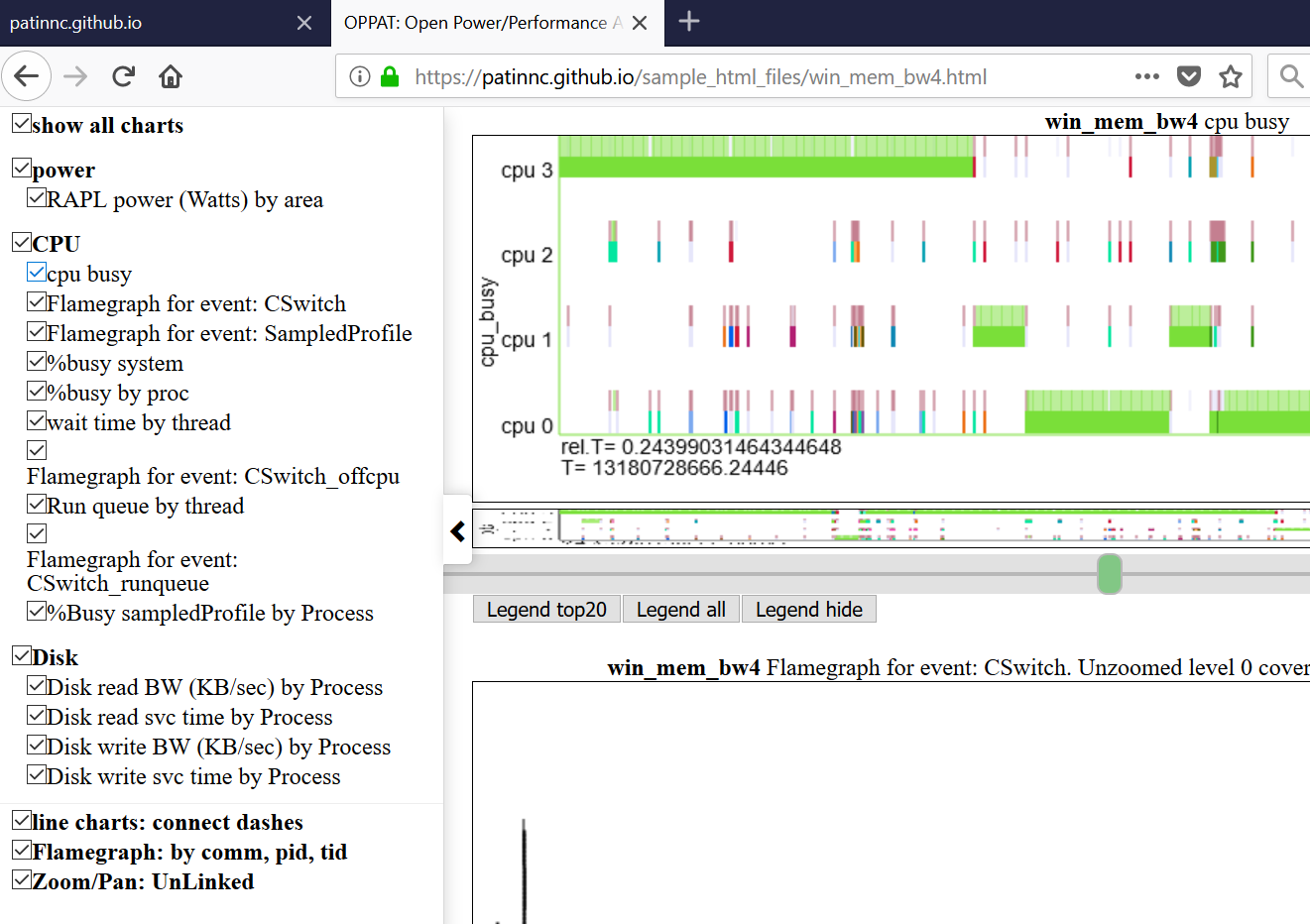
Unten finden Sie eine der Oppat -Charts. Die Tabelle "CPU_BUSY" zeigt, was auf jeder CPU ausgeführt wird, und die Ereignisse, die auf jeder CPU stattfinden. Zum Beispiel zeigt der grüne Kreis einen Spin.x -Faden, der auf CPU ausgeführt wird. Der rote Kreis zeigt einige der Ereignisse, die auf CPU1 auftreten. Dieses Diagramm ist nach dem Kernelshark-Diagramm von Trace-CMD modelliert. Weitere Informationen zum CPU_Busy-Diagramm finden Sie im Abschnitt "Chart-Typen". Das Callout -Feld zeigt die Ereignisdaten (einschließlich Callstack (falls vorhanden) für das Ereignis unter dem Cursor. Leider erfasst Windows Screenshot den Cursor nicht. 
Hier sind einige Beispiele für HTML -Dateien. Die meisten Dateien sind für ein kürzeres ~ 2 -Intervall, einige sind jedoch 8 Sekunden lang. Die Dateien werden nicht direkt aus dem Repo geladen, aber sie werden von der Projektwebseite geladen: https://patinnc.github.io
- Intel Haswell mit dem CPU-Diagramm 4-CPU-Chip, Linux OS, HTML
- Intel 4-CPU-Chip, Windows-Betriebssystem, HTML-Datei mit 1 HW-Ereignissen über Xperf-Sampling oder
- Full ~ 8 Second Intel 4-CPU-Chip, Windows-Betriebssystem, HTML-Datei mit PCM- und Xperf-Sampling oder
- Intel 4-CPU-Chip, Linux-Betriebssystem, HTML-Datei mit 10 HW-Ereignissen in 2 Multiplex-Gruppen.
- ARM (Broadcom A53) Chip, Raspberry Pi3 Linux HTML -Datei mit 14 HW -Ereignissen (für CPI, L2 -Fehler, Mem BW usw. in 2 Multiplex -Gruppen).
- 11 MB, Vollversion der oben genannten ARM (Broadcom A53) Chip, Raspberry Pi3 Linux HTML -Datei mit 14 HW -Ereignissen (für CPI, L2 -Misserschaften, Mem BW usw. in 2 Multiplex -Gruppen).
Einige der oben genannten Dateien sind ~ 2 Sekunden -Intervalle, die aus ~ 8 Sekunden langen Läufen extrahiert wurden. Hier ist der volle 8 -Sekunden -Lauf:
- Die volle 8 -Sekunden -Linux -Beispiel -HTML -komprimierte Datei für eine vollständigere Datei. In der Datei wird ein JavaScript -ZLIB -Dekomprimieren der Diagrammdaten durchgeführt, sodass Sie Nachrichten sehen, die Sie während des Dekompresses zum Warten (ca. 20 Sekunden) sehen.
Oppat -Daten unterstützt
- Linux Perf und/oder Trace-CMD-Leistungsdateien (sowohl binäre als auch Textdateien),
- Perf STAT -Ausgabe auch akzeptiert
- Intel PCM -Daten,
- Andere Daten (importiert mit LUA -Skripten),
- Dies sollte also mit Daten von regulären Linux oder Android funktionieren
- Derzeit benötigt OPPAT für Perf- und Trace-CMD-Daten sowohl die binären als auch die postverarbeiteten Textdateien und es gibt einige Einschränkungen in der Befehlszeile "Datensatz" und die Befehlszeile "Perf Skript/Trace-CMD-Bericht".
- OPPAT könnte gemacht werden, um nur die Perf/Trace-CMD-Textausgabedateien zu verwenden, aber derzeit sind sowohl binäre als auch Textdateien erforderlich
- Windows ETW -Daten (von Xperf gesammelt und in Text abgeladen) oder Intel PCM -Daten,
- Mit LUA -Skripten unterstützte beliebige Leistungsdaten oder Leistungsdaten (daher müssen Sie den C ++ - Code nicht neu kompilieren, um andere Daten zu importieren (es sei denn, die LUA -Leistung wird zu einem Problem))
- Lesen Sie die Datendateien unter Linux oder Windows, unabhängig davon, wo die Dateien stammen (also lesen Sie Perf/Trace-CMD-Dateien unter Windows- oder ETW-Textdateien unter Linux).
Oppat -Visualisierung
Hier finden Sie einige vollständige Beispiele für VisualZation -HTML -Dateien: Windows -Beispiel -HTML -Datei oder diese Linux -Beispiel -HTML -Datei. Wenn Sie sich auf dem Repo befinden (nicht auf der Github.io -Projekt -Website), müssen Sie die Datei herunterladen und dann in Ihren Browser laden. Dies sind eigenständige Webdateien, die von OPPAT erstellt wurden, die beispielsweise per E -Mail an andere oder (wie hier) auf einem Webserver gesendet werden können.
Oppat Viz funktioniert in Chrom besser als Firefox, vor allem, weil der Zoom mit Touchpad 2 -Finger -Scrollen auf Chrom besser funktioniert.
OPPAT hat 3 Visualisierungsmodi:
- Der übliche Diagrammmechanismus (bei dem OPPAT -Backend die Datendateien liest und Daten an den Browser sendet)
- Sie können auch eine eigenständige Webseite erstellen, die dem "regulären Diagrammmechanismus" entspricht, aber mit anderen Benutzern ausgetauscht werden kann ... Die eigenständige Webseite enthält alle Skripte und Daten integriert, damit sie an jemanden per E-Mail gesendet werden können und sie in ihrem Browser laden können. Siehe die oben genannten HTML -Dateien in sample_html_files und (für eine längere Version von lnx_mem_bw4) siehe die komprimierte Datei sample_html_files/lnx_mem_bw4_full.html
- Sie können eine Daten-JSON-Datei "-Save" und dann die Datei später laden. Die gespeicherte JSON -Datei hat die Daten, die OPPAT an den Browser senden muss. Dadurch wird das Neulesen der Eingabe-Perf/Xperf-Dateien vermieden, aber es wird keine Änderungen in Diagramme.json erfasst. Die mit der Option -Web_file erstellte vollständige HTML -Datei ist nur geringfügig größer als die -Save -Datei. Der Lastmodus-SAVE/-muss OPPAT erstellen. Siehe die Beispieldateien in Sample_Data_JSON_FILES Subdir.
Viz Allgemeine Info
- Diagramm alle Daten in einem Browser (unter Linux oder Windows)
- Die Diagramme sind in einer JSON -Datei definiert, sodass Sie Ereignisse und Diagramme hinzufügen können, ohne OPPAT neu zu kompilieren
- Die Browser -Schnittstelle ist wie Windows WPA (NAVABAR links).
- Unten zeigt die linke Navigatte (linke Siebmenü).
- Die Diagramme werden nach Kategorie gruppiert (GPU, CPU, Strom usw.)
- Die Kategorien werden in input_files/chabrics.json definiert und zugeordnet
- Diagramme können alle versteckt oder selektiv angezeigt werden, indem Sie in der NAVABAR auf das Diagramm klicken.
- Über einen Diagrammtitel im linken NAV -Menü rollen, die die Diagramme in die Anzeige haben
- Daten aus einer Gruppe von Dateien können neben einer anderen Gruppe aufgetragen werden
- Sie können also sagen, dass Sie eine Linux -Perf -Leistung mit einem Windows ETW -Lauf vergleichen
- Unten Diagramm anzeigen Linux vs Windows -Stromverbrauch:
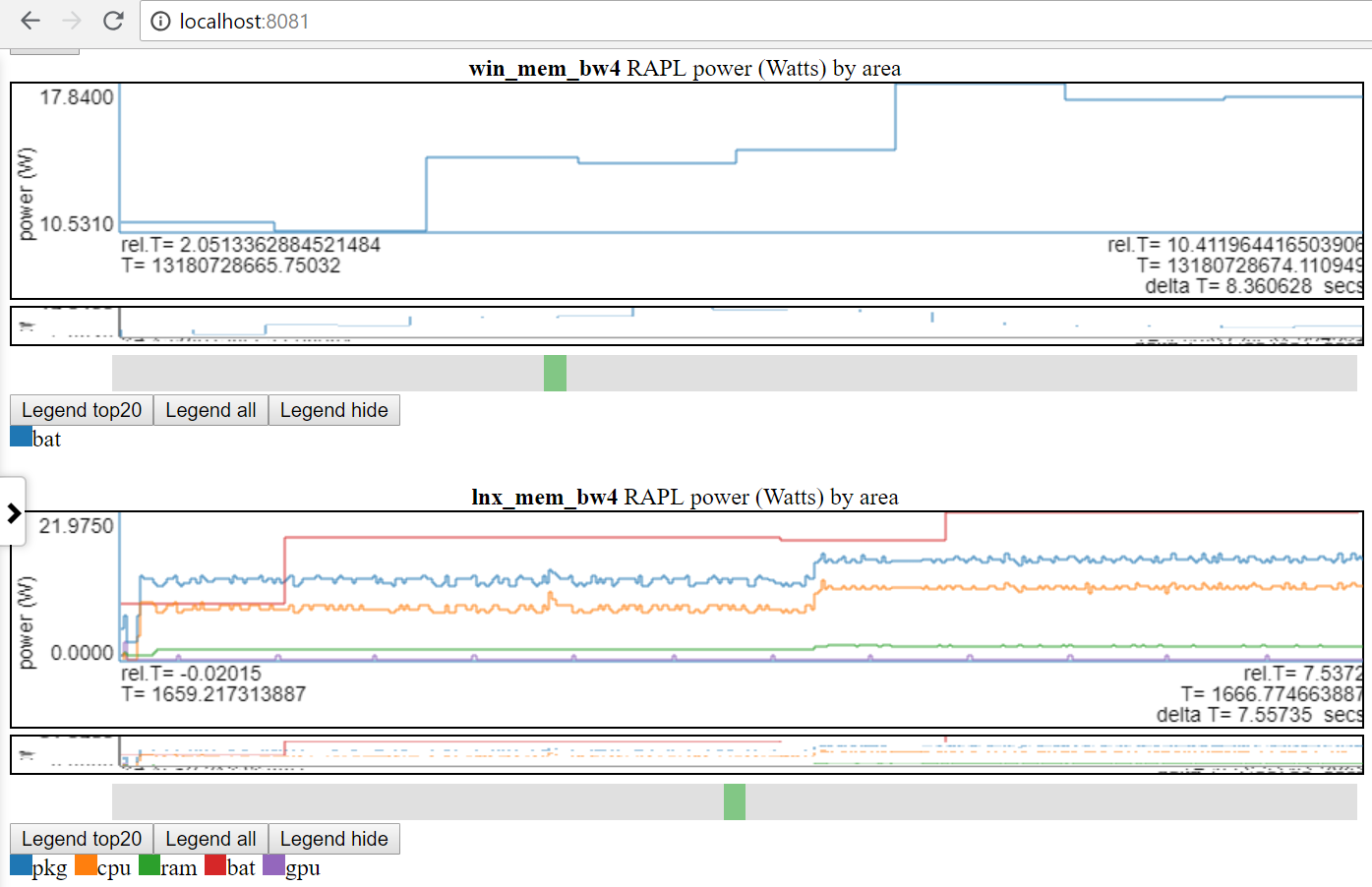
- Ich habe nur Zugriff auf Batteriestrom sowohl auf Linux als auch auf Windows.
- Viele Websites haben viel bessere Stromversorgungsdaten (Spannungen/Ströme/Leistung in der MSEC -Rate (oder besser). Es wäre einfach, diese Arten von Stromdaten (z. B. von Kratos oder Qualcomm MDPs) einzubeziehen, aber ich habe keinen Zugriff auf die Daten.
- Oder vergleichen Sie 2 verschiedene Läufe auf derselben Plattform
- Ein Dateigruppen -Tag (File_Tag) wird dem Titel vorangestellt, um Diagramme zu unterscheiden
- Ein 'Tag' ist in der Dateidatei von Data DIRE_LIST.JSON und/oder input_files/input_data_files.json definiert
- Die input_files/input_data_files.json ist eine Liste aller Oppat -Datendirschen (der Benutzer muss sie jedoch verwalten).
- Diagramme mit demselben Titel werden nacheinander geplant, um einen einfachen Vergleich zu ermöglichen
Diagrammfunktionen:
Über einen Abschnitt einer Zeile des Diagramms zu schweben, zeigt den Datenpunkt für diese Zeile zu diesem Zeitpunkt
- Dies funktioniert nicht für die vertikalen Linien, da sie nur 2 Punkte verbinden ... nur die horizontalen Teile jeder Zeile werden nach dem Datenwert gesucht
- Unten finden Sie einen Screenshot des Schweberns über das Ereignis. Dies zeigt die relative Zeit des (CSWTICH) Ereignisses, einige Informationen wie Prozess/PID/TID und die Zeilennummer in der Textdatei, damit Sie weitere Informationen erhalten können.

- Im Folgenden finden Sie einen Screenshot, der die CallStack -Informationen (falls vorhanden) für Ereignisse zeigt.

Zoomen
- Unbegrenztes Zoomen in die Nanosec -Ebene und das Zoomen zurück.
- Es gibt wahrscheinlich Größenordnungen mehr Punkte zum Diagramm als Pixel, sodass beim Zoomen mehr Daten angezeigt werden.
- Im Folgenden finden Sie einen Screenshot, der das Zooming der Mikrosekundenebene zeigt. Dadurch wird der CallStack für Sched_Switch -Ereignis angezeigt, bei dem Spin.x durch den Speicherzuordnungsvorgang und den Leerlauf blockiert wird. Das "CPU -belebte" -Argabendium zeigt "Leerlauf" als leer.
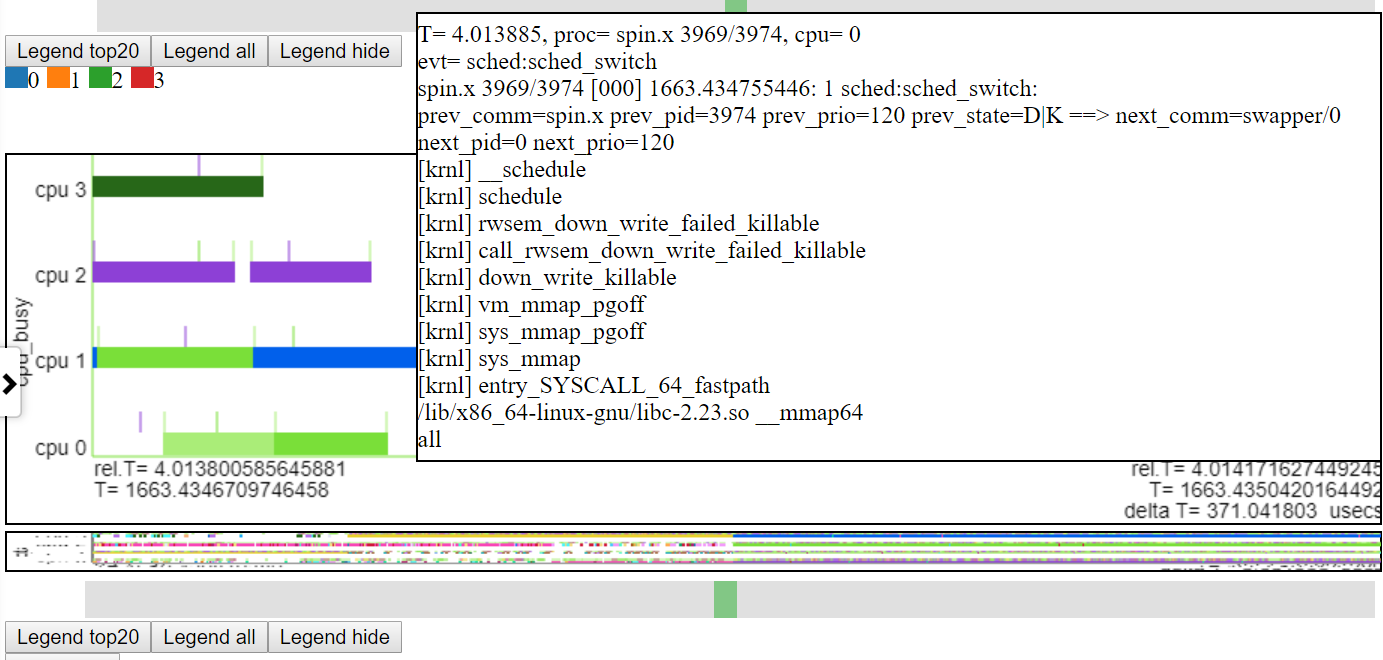 .
.
- Diagramme können einzeln vergrößert werden oder Diagramme mit demselben Datei_Tag können verknüpft werden, sodass das Zoomen/Panning 1 -Diagramm das Intervall aller Diagramme mit demselben Datei_Tag ändert
- Scrollen Sie zum Ende der linken Navigation und klicken Sie auf 'Zoom/Pan: Unverinked'. Dadurch wird der Menüelement in "Zoom/Pan: Linked" geändert. Dadurch wird alle Diagramme in einer Dateigruppe zur letzten Zoom/Pan -Absolute Zeit vergrößert. Dies wird einige Zeit dauern, um alle Diagramme neu zu zeichnen.
- Zunächst wird jedes Diagramm gezeichnet, wobei alle verfügbaren Daten angezeigt werden. Wenn Ihre Diagramme aus verschiedenen Quellen stammen, sind die T_Begin und T_end (für Diagramme aus verschiedenen Quellen) wahrscheinlich unterschiedlich.
- Sobald ein Zoom-/PAN -Betrieb ausgeführt wird und die Verknüpfung in Kraft ist, werden alle Diagramme in der Dateigruppe in das gleiche absolute Intervall vergrößert.
- Aus diesem Grund muss die für jede Quelle verwendete "Uhr" gleich sein.
- Oppat könnte von einer Uhr in eine andere (z.
- Alle Flamgraphs für ein Intervall werden unabhängig vom Verknüpfungsstatus immer in das Intervall der "Besitzkarten" verkleinert.
- Sie können ein-/ausgrocken von:
- Zoomen in: Mausrad vertikal im Diagrammbereich. Der Diagramm vergrößert die Zeit in der Mitte des Diagramms.
- Auf meinem Laptop scrollen Sie 2 Finger vertikal auf dem Touchpad
- Zoomen: Klicken Sie auf Diagramm und ziehen Sie die Maus nach rechts und veröffentlichen Sie die Maus (das Diagramm vergrößert das ausgewählte Intervall).
- Zoomen: Klicken Sie auf Diagramm und ziehen Sie die Maus nach links und veröffentlichen Sie die Maus, die umgekehrt proportional zu dem, was Sie ausgewählt haben, umgekehrt proportional ausgehen. Das heißt, wenn Sie fast den gesamten Diagrammbereich ziehen lassen, wird das Diagramm ~ 2x wieder vergrößert. Wenn Sie gerade ein kleines Intervall gezogen haben, wird das Diagramm den ganzen Weg vergrößert.
- Zoom aus: Auf meinem Laptop einen Touchpad 2 Finger vertikaler Schriftrolle in die entgegengesetzte Richtung von Zoom
- Sie müssen vorsichtig sein, wo der Cursor ist ... Sie könnten versehentlich ein Diagramm vergrößern, wenn Sie die Liste der Diagramme scrollen möchten. Deshalb lege ich den Cursor normalerweise an der linken Rande des Bildschirms, wenn ich die Diagramme scrollen möchte.
Schwung
- Auf meinem Laptop macht dies 2 Finger auf horizontaler Schriftrollenbewegung auf dem Touchpad
- Verwenden Sie die grüne Box auf dem Miniaturbild unterhalb des Diagramms
- Panning funktioniert auf jeder Zoomebene
- Ein 'Miniaturbild' des vollständigen Diagramms wird unter jedem Diagramm mit einem Cursor über das Miniaturbild gebracht, damit Sie beim Zoomen/Schwingen durch das Diagramm navigieren können
- Nachfolgend zeigt das Schwingen im Diagramm 'CPU-Busy' auf t = 1,8-2,37 Sekunden. Die relative Zeit und die absolute Beginn sind im linken roten Oval erhöht. Die Endzeit wird im rechten roten Oval hervorgehoben. Die relative Position auf dem Miniaturbild wird vom mittleren Red Oval gezeigt.
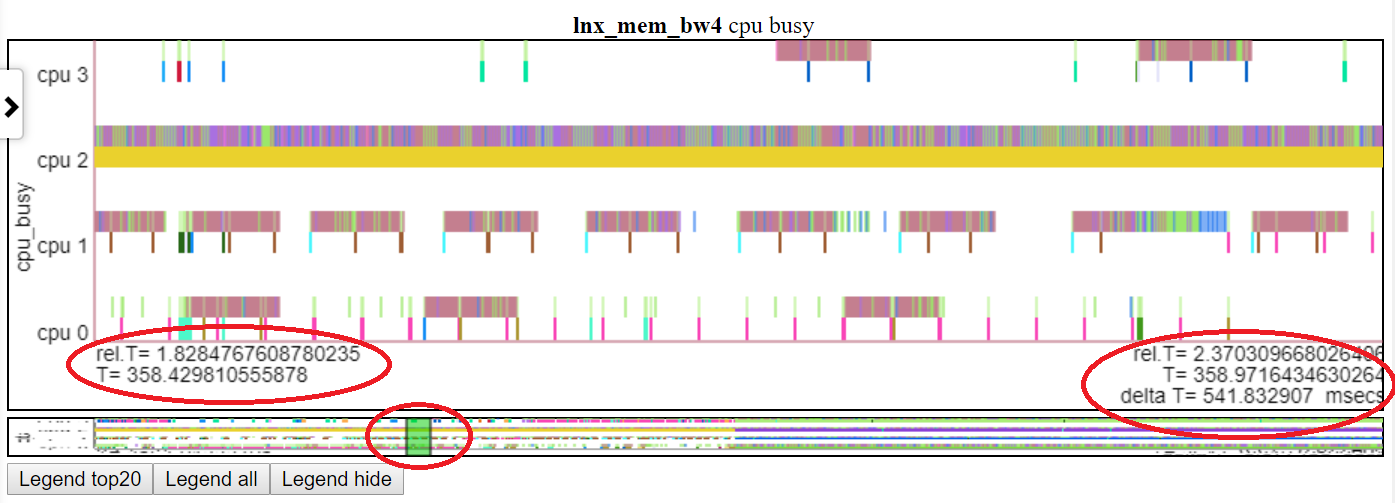 .
.
Wenn Sie in einem Diagramm -Legendeintrag schweben, wird diese Linie hervorgehoben.
- Unten ist ein Screenshot, bei dem die Leistung von 'PKG' (Paket) hervorgehoben wird
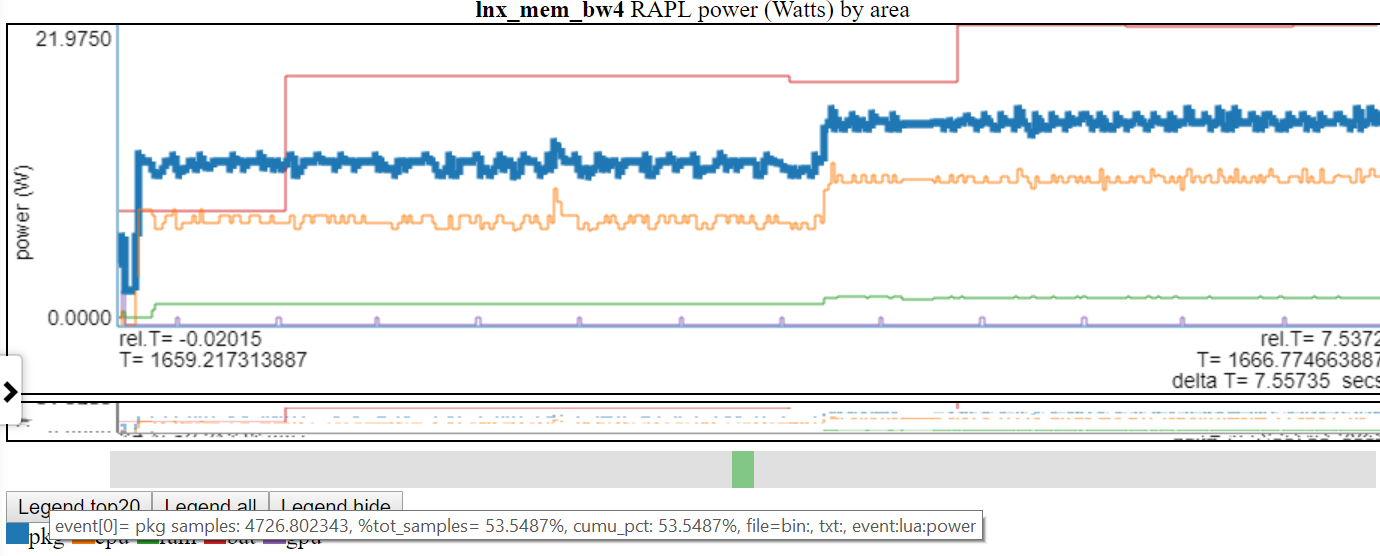
Wenn Sie auf eine Tabelle Legendeintrag klicken, wird die Sichtbarkeit dieser Zeile umgeschaltet.
Wenn Sie auf einen Legendeintrag klicken, ist nur dieser Eintrag sichtbar/versteckt
- Unten ist ein Screenshot, bei dem die PKG -Stromversorgung doppelt geklickt wurde, sodass nur die PKG -Linie sichtbar ist.
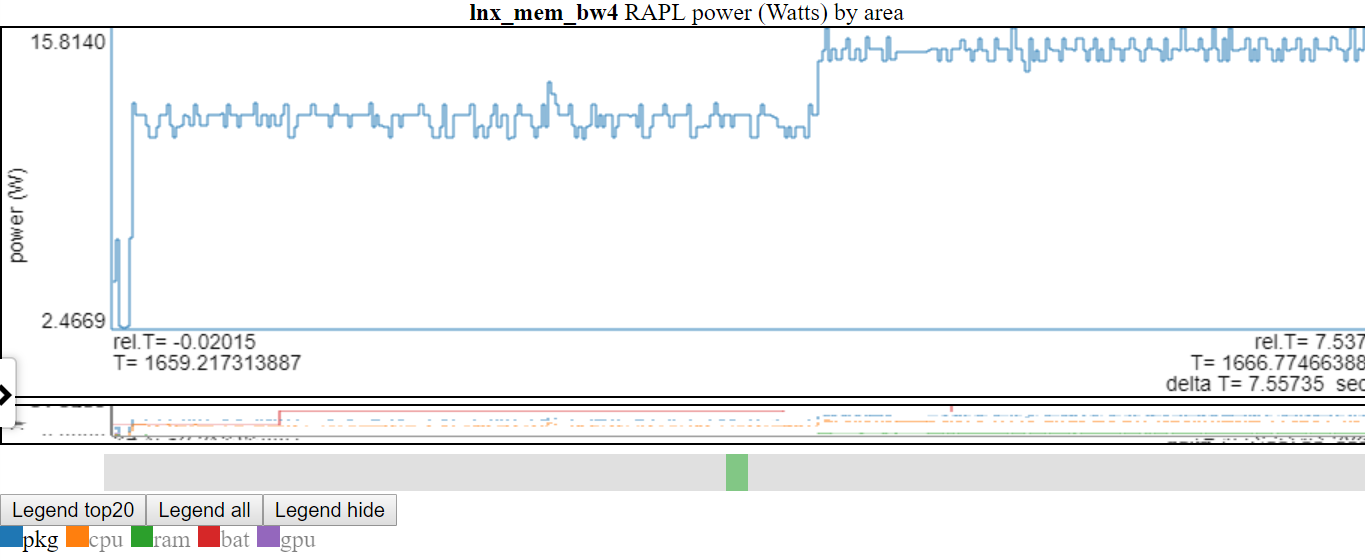
- Oben zeigt die y-Achse an min/max der angezeigten Variablen (en). Die "nicht gezeigten" Linien sind in der Legende ausgegraut. Wenn Sie in der Legende über eine "nicht gezeigte" Linie schweben, wird sie gezogen (während Sie auf dem Legend -Artikel schweben). Sie können alle Elemente erneut anzeigen lassen, indem Sie auf einen "nicht geeigneten" Legendeintrag doppelklicken. Dadurch werden alle Zeilen "Nicht gezeigt" angezeigt, aber es wird die gerade geklickte Zeile abschalteten ... Klicken Sie also auf das Element, mit dem Sie gerade doppelklickten. Ich weiß, dass es verwirrend klingt.
Wenn ein Legendeintrag versteckt ist und Sie darüber schweben, wird er angezeigt, bis Sie ausgehen
Diagrammtypen:
"CPU-Busy" -Dart: Ein Kernelshark-ähnliches Diagramm, das die CPU-Belegung von PID/Thread zeigt. Siehe Kernelshark Referenz http://rostedt.homelinux.com/kernelshark/
- Unten finden Sie einen Screenshot des CPU -geschäftigen Diagramms. Das Diagramm zeigt für jede CPU den Prozess/PID/TID zu einem beliebigen Zeitpunkt. Der Leerlaufprozess wird nicht gezeichnet. Für 'CPU 1' auf dem Screenshot ist das grüne Oval um den Teil des Tabellens "Kontextschalter". Über jedem Kontextschalter von CPUs zeigt die CPU -Besetzung die Ereignisse, die in derselben Datei wie das Kontext -Switch -Ereignis vorhanden sind. Das Rote Oval in der CPU 1 -Linie zeigt den Ereignisteil des Diagramms.
- Das Diagramm basiert auf dem Kontextschalter -Ereignis und zeigt den Thread an, der auf jeder CPU zu einem bestimmten Zeitpunkt ausgeführt wird
- Das Kontext -Switch -Ereignis ist das Linux -Schedule: Sched_Switch oder das Windows Etw Cswitch -Ereignis.
- Wenn es mehr Ereignisse als den Kontextschalter in der Datendatei gibt, werden alle anderen Ereignisse als vertikale Striche über der CPU dargestellt.
- Wenn die Ereignisse Anrufstapel haben, wird der Anrufstapel auch im Popup -Ballon angezeigt
Zeilendiagramme
- Die Zeilendiagramme werden wahrscheinlich genauer bezeichnet, da jedes Ereignis (bisher) eine Dauer hat und diese „Dauer“ durch horizontale Segmente dargestellt und durch vertikale Segmente verbunden sind.
- Der vertikale Teil des Schrittdiagramms kann ein Diagramm ausfüllen, wenn Diagrammlinien eine Menge Variationen aufweisen
- Sie können (in der linken Navigationsleiste) auswählen, um die horizontalen Segmente jeder Zeile nicht zu verbinden ... damit das Diagramm zu einer Art "gestreuteter Dash" -Argabart wird. Die "Horizonatal -Striche" sind die tatsächlichen Datenpunkte. Wenn Sie von der Schrittkarte zum Dash -Diagramm wechseln, wird das Diagramm erst dann neu gezeichnet, wenn eine "erneute Raw" -Anforderung (wie Zoom/Pan oder Highlight (durch Überschwebung über einen Legendeintrag)).
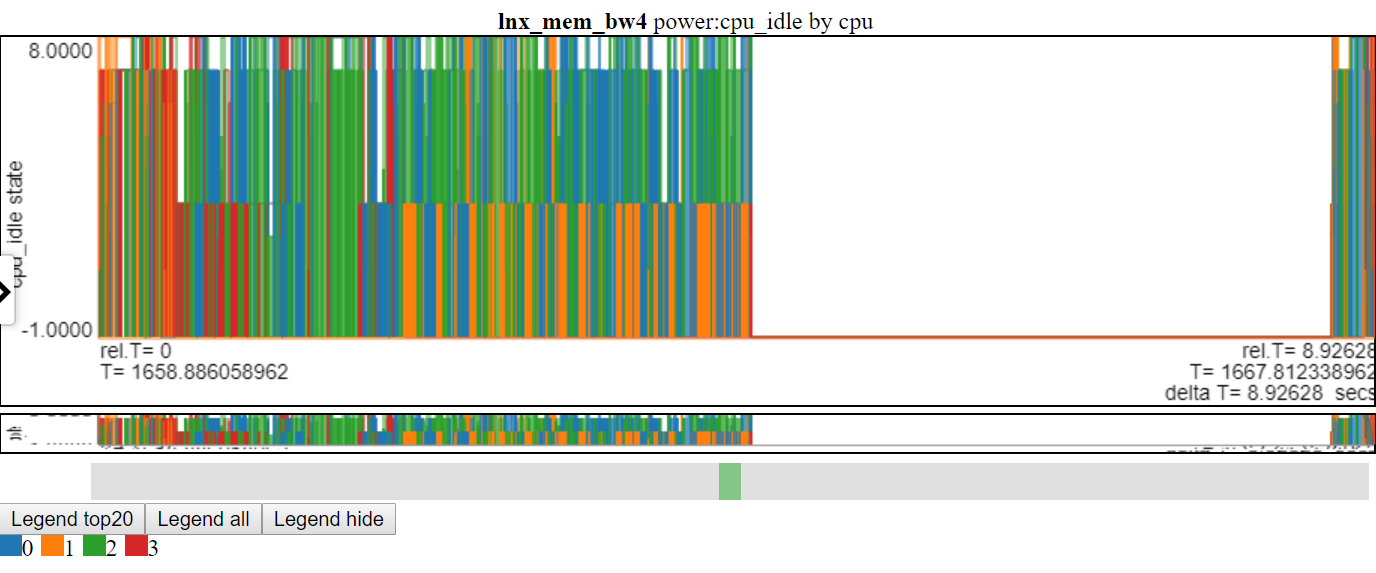
- Unten finden Sie einen Screenshot von CPU_IDLE -Leistungszuständen, die die Zeilendiagramme verwenden. Die Verbindungslinien streichen die Informationen im Diagramm aus.
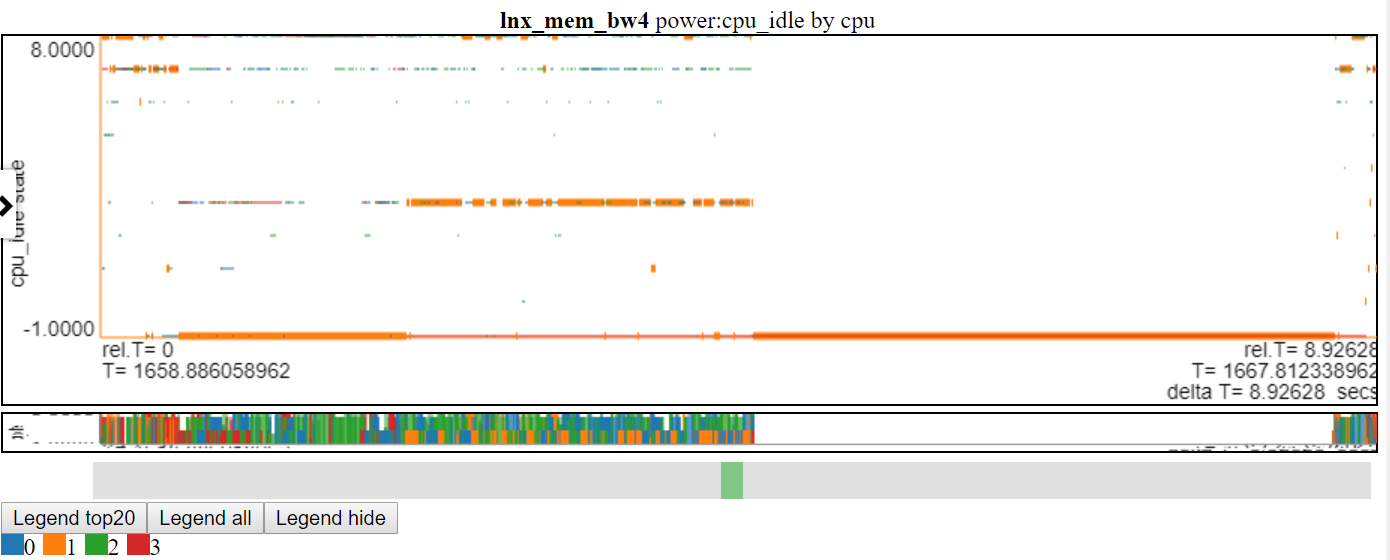
- Unten finden Sie einen Screenshot von CPU_IDLE-Leistungszuständen unter Verwendung von gestreuteter Dias-Diagramm. Das Diagramm zeigt nun einen horizontalen Armaturenbrett für den Datenpunkt (die Breite des Armaturenbretts ist die Dauer des Ereignisses). Jetzt können wir weitere Informationen sehen, aber dieses Diagramm zeigt auch einen Nachteil mit meiner Diagrammlogik: Viele der Daten sind am maximalen Wert und am minitischen Wert des Diagramms und es wird verdeckt.
gestapelte Diagramme
- Stapelte Diagramme können dazu führen, dass viel mehr Daten generiert werden als Zeilendiagramme. Beispielsweise hängt das Zeichnen eines Zeilendiagramms von, wenn ein bestimmter Thread ausgeführt wird, nur von diesem Thread ab. Das Zeichnen eines gestapelten Diagramms zum Ausführen von Threads ist unterschiedlich: Ein Kontextschalterereignis in jedem Thread ändert alle anderen laufenden Threads. Wenn Sie also N-CPUs haben, erhalten Sie N-1 mehr Dinge zum Zeichnen pro Ereignis für gestapelte Diagramme.
Flamgraphs. Für jedes Perf -Ereignis, das CallStacks hat und in derselben Datei wie das Ereignis ender_switch/cswitch befindet, wird ein Flamgraph erstellt.
- Unten finden Sie einen Screenshot eines typischen Standardflamegraphs. Normalerweise reicht die Standardhöhe des Flamegraph -Diagramms nicht aus, um den Text in jede Ebene des Flamegraphs anzupassen. Aber Sie erhalten immer noch die "schwebenden" CallStack -Informationen.
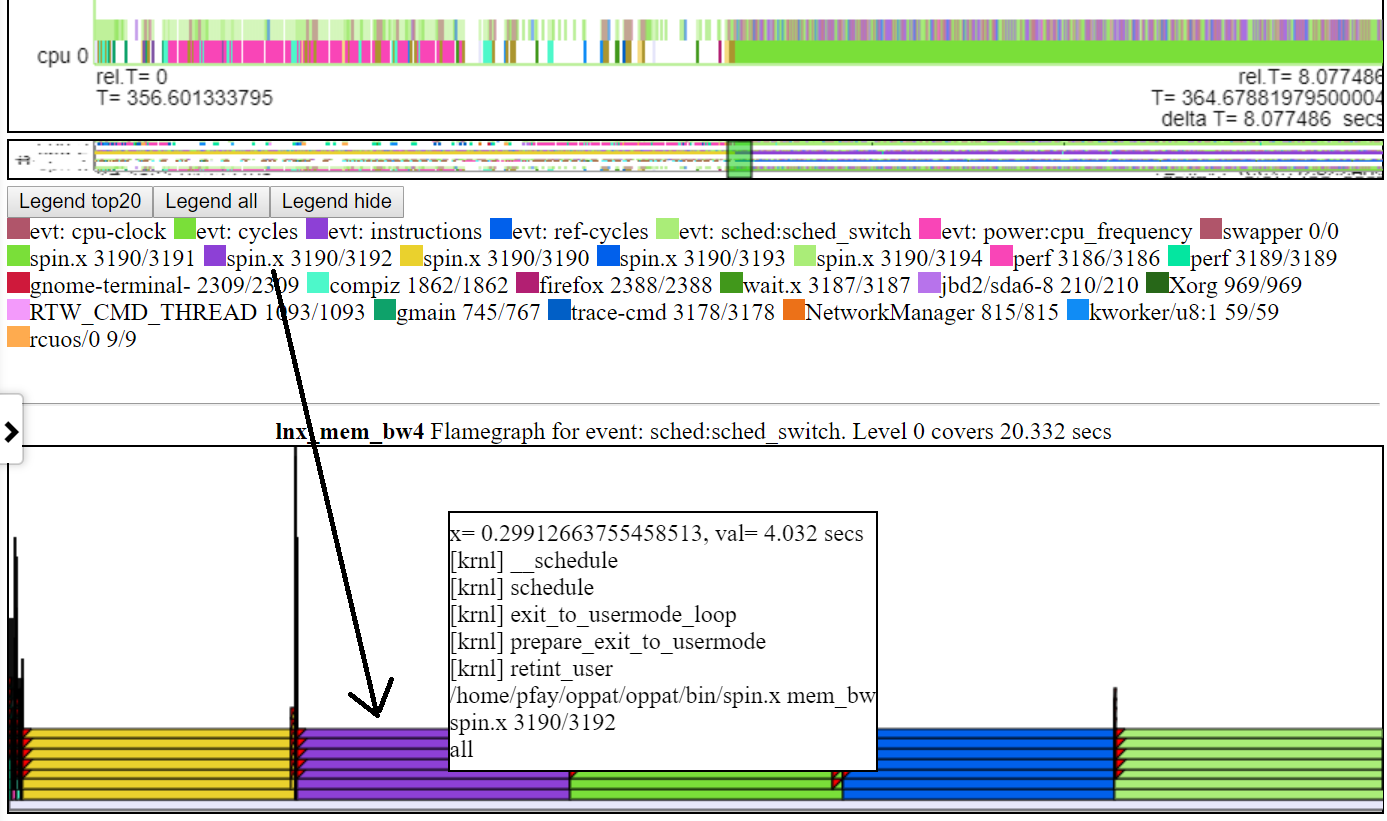 .
.- Wenn Sie auf die Ebene des Diagramms klicken, erweitert es höher, sodass der Text passt. Wenn Sie auf die niedrigste Ebene klicken, deckt es alle Daten für das Intervall des "Besitzkartens" ab.
- Unten finden Sie einen Screenshot eines vergrenzten Flampraphen (nachdem Sie auf eine der Schichten einer Flamme geklickt haben).
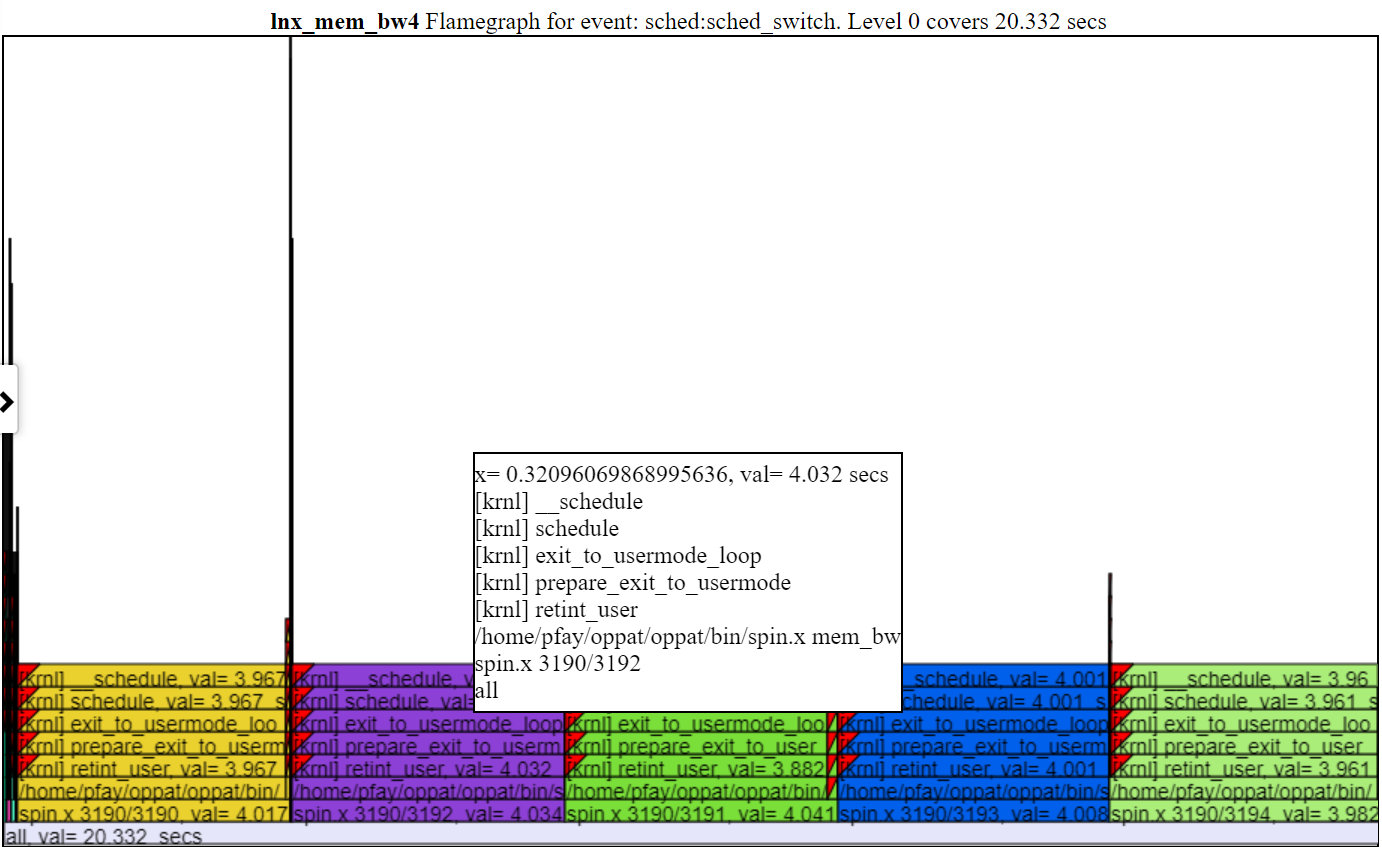 .
.- Normalerweise reicht die Standardhöhe des Flamegraph -Diagramms nicht aus, um den Text in jede Ebene des Flamegraphs anzupassen. Aber Sie erhalten immer noch die "schwebenden" CallStack -Informationen.
- Die Farbe des Flamgraph entspricht dem Prozess/PID/TID in der Legende von CPU_Busy -Diagramm ... es ist also nicht so hübsch wie ein Flamgraph, aber jetzt bedeutet die Farbe einer Flamme tatsächlich etwas.
- Der CPI (Uhren pro Anweisung) FlamGraph -Diagramm färbt den Prozess/PID/TID vom CPI für diesen Stapel.
- Im Folgenden finden Sie ein ungoomes CPI -Diagramm. Die linke Instanz von spin.x (in leichter Orange) hat einen CPI = 2,26 Zyklen/Anweisungen. Die 4 spin.x's rechts in hellgrün haben einen CPI = 6,465.
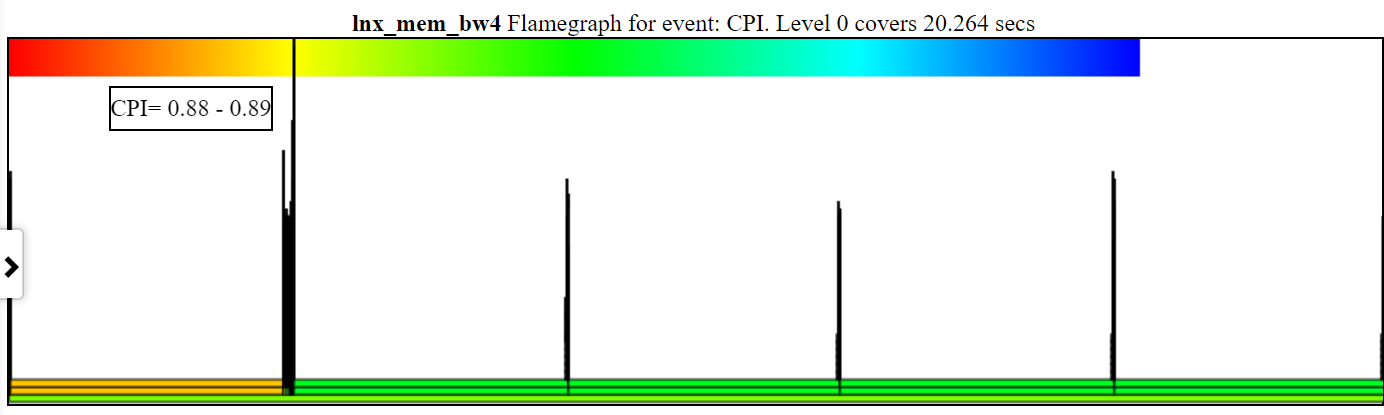
- Sie müssen Zyklen, Anweisungen und CPU-CLOCK (oder ender_switch) Callstacks haben
- Die Breite der CPI-Flamme basiert auf der CPU-Uhrzeit.
- Die Farbe basiert auf dem CPI. Ein rot bis grün bis blauer Gradient oben links im Diagramm zeigt die Färbung.
- Rot ist ein niedriger CPI (also viele Anweisungen pro Uhr ... ich betrachte es als "heiß")
- Blue ist ein hoher CPI (so wenige Anweisungen pro Uhr ... ich betrachte es als "kalt")
- Im Folgenden finden Sie ein zoomiertes CPI -Diagramm, das die Färbung und den CPI zeigt. Die "spin.x" -Threads wurden in der CPU_Busy -Legende abgewählt, sodass sie nicht im Flamgraph erscheinen.
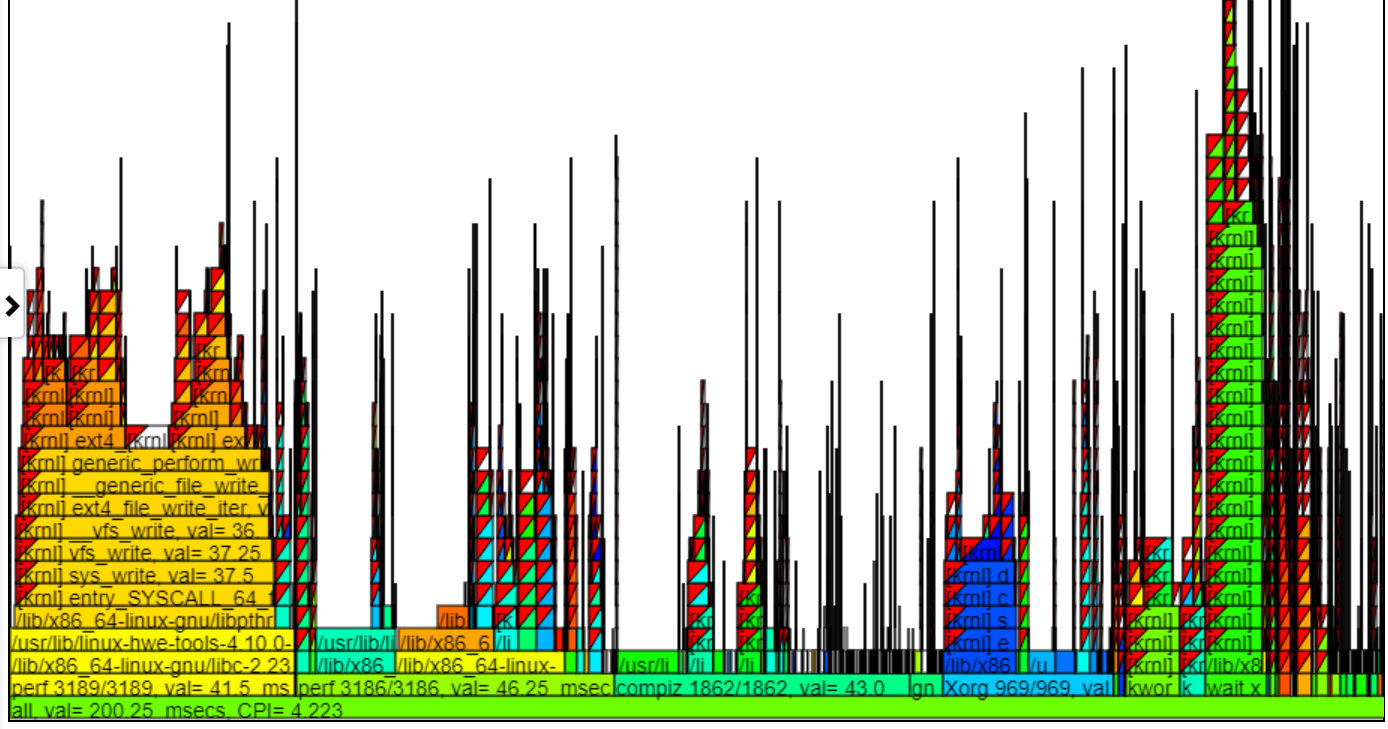
- Die GIPS (GIGA (Milliarden) Anweisungen pro Sekunde) Flamgraph Chart färben den Prozess/PID/TID von den GIPS für diesen Stapel.
- Im Folgenden finden Sie eine Probe, die ungoomierte GIPs (Giga/Milliarden -Anweisungen pro Sekunde) Diagramm sind. Die linke Instanz von spin.x (in hellgrün) hat einen GIP = 1,13. Die 4 spin.x's rechts in blau grün haben eine gips = 0,377. Der Callstack im Ballon ist für eine, die die Spike Callstacks links vom Ballon.

- Beachten Sie in der obigen Tabelle, dass der linke Stapel (für spin.x) eine höhere Anweisungen/Sekunden erhalten als die meisten 4 Instanzen von Spin.x. Diese erste Instanz von spin.x läuft von selbst (so erhält viele Speicher -BW) und rechte 4 spin.x -Threads, die parallel laufen und ein niedrigeres GIP (da ein Thread den Speicher -BW aus maximal maximal maximal kann).
- Sie müssen Anweisungen und CPU-Clock (oder plant_switch) callstacks haben
- Die Breite der Gips 'Flame' basiert auf der CPU-Glockzeit.
- Die Farbe basiert auf den Gips. Ein rot bis grün bis blauer Gradient oben links im Diagramm zeigt die Färbung.
- Rot ist ein hoher Gips (also viele Anweisungen pro Sekunde ... Ich denke, es als „heiß“, viel Arbeit zu machen)
- Blau ist ein niedriger Gips (so wenige Anweisungen pro Sekunde ... ich betrachte es als "kalt")
- Im Folgenden finden Sie ein Muster -Zoom -GIP -Diagramm, das die Färbung und die GIPS zeigt. Ich habe auf das 'Perf 3186/3186' geklickt, damit nur diese Flamme unten angezeigt wird.
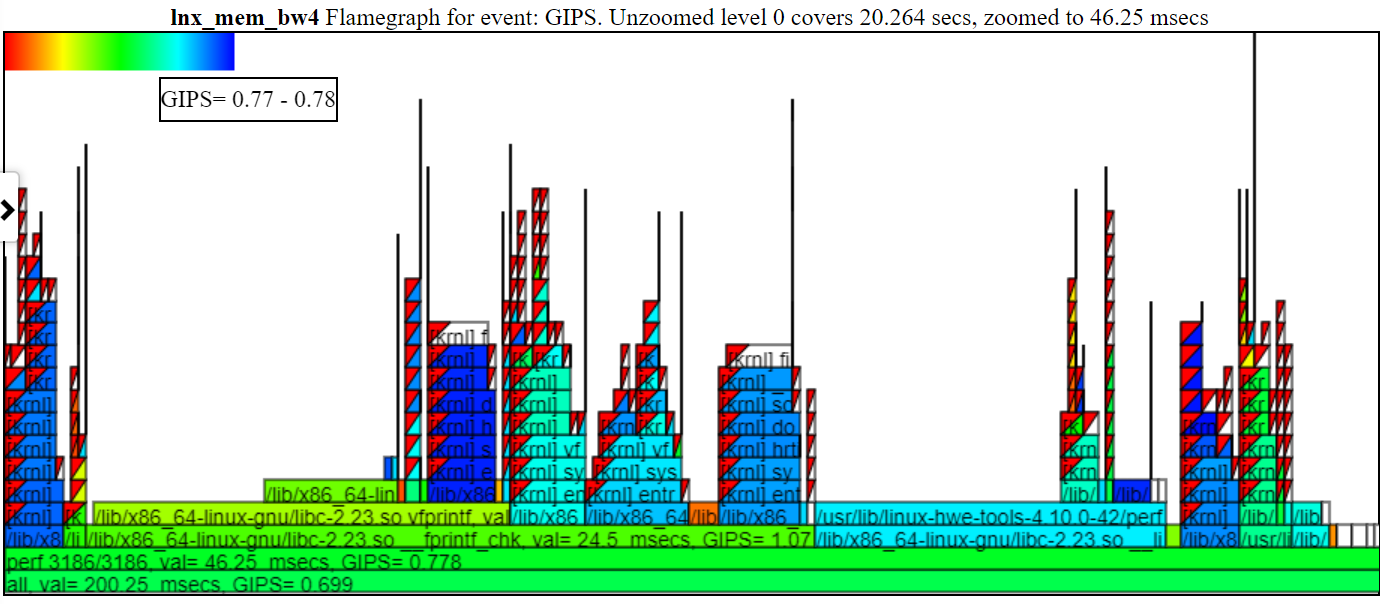
- Wenn Sie einen Prozess in der Legende ausblenden (klicken Sie auf den Legendeintrag ... er wird ausgegraut), wird der Vorgang nicht im Flamgraph angezeigt.
- Wenn Sie die Maus rechts in den Flamgraph ziehen, wird dieser Abschnitt des Flamgraphs gezoomt
- Klicken Sie auf eine "Flamme" Zoomen zu dieser Flamme
- Das Ziehen der Maus in den Flamegraph zoomen links
- Klicken
- Wenn Sie auf die niedrigste Ebene des Flamgraphen klicken, werden Sie den ganzen Weg zurückzoomen
- Wenn Sie auf die Flamgraph -Ebene klicken, wird das Diagramm so geändert, dass jede Ebene hoch genug ist, um den Text anzuzeigen. Dies führt dazu, dass das Diagramm die Größe der Größe ist. Um zu versuchen, dieser Größenänderung eine gewisse Gesundheit zu verleihen, positioniere ich die letzte Ebene der Größe der Größe des Größens an den sichtbaren Bildschirm.
- Wenn Sie in die Legende zurückkehren und über einen versteckten Eintrag schweben, wird dieser Eintrag im Flamegraph angezeigt, bis Sie ausgehen
- Wenn Sie auf eine obere Ebene "Flamme" klicken, wird nur dieser Abschnitt vergrenzt.
- Wenn Sie in der "Parent" -Dartin ein-/ausgehen, werden die Flamgraphs für das ausgewählte Intervall neu gezogen
- Wenn Sie nach links/rechts in der "Parent" -Abkarte schwenken, werden die Flamgraphs für das ausgewählte Intervall neu gezeichnet
- Standardmäßig passt der Text jeder Ebene des Flammendiagramms wahrscheinlich nicht. Wenn Sie auf Flamgraph klicken, wird die Größe erweitert, um auch den Text zu zeichnen
- Sie können (in der linken Navigationsleiste) auswählen, ob die Flamgraphs nach Prozess/PID/TID oder nach Prozess/PID oder per Verfahren gruppiert werden sollen.
- Sowohl "On CPU", "Off CPU" als auch "Run Queue" werden gezeichnet.
- 'On CPU' ist der CallStack für das, was der Thread tat, während er auf der CPU ausgeführt wurde.
- 'Off CPU' zeigt, dass Threads, die nicht lief, wie lange sie warteten und den Callstack, als sie ausgetauscht wurden.
- Unten finden Sie einen Screenshot des Off-CPU- oder Wartezeit-Diagramms. Das Popup zeigt (im Flamegraph), dass 'Wait.x' auf Nanosleep wartet.

- Der Swap -Zustand (und auf ETW der „Grund“) wird als Stufe über dem Prozess angezeigt. Normalerweise werden die meisten Themen schlafen oder nicht laufen, aber dies hilft man, die Frage zu beantworten: "Wenn mein Thread nicht ausgeführt hat ... worauf wartete es?".
- Mit dem "Status" für den Kontextschalter sehen Sie:
- Zum Beispiel, ob ein Thread auf einen nicht übertriebenen Schlaf wartet (Zustand == D auf Linux ... normalerweise io)
- Interruptibler Schlaf (Zustand = S ... häufig ein Nanosleep oder Futex)
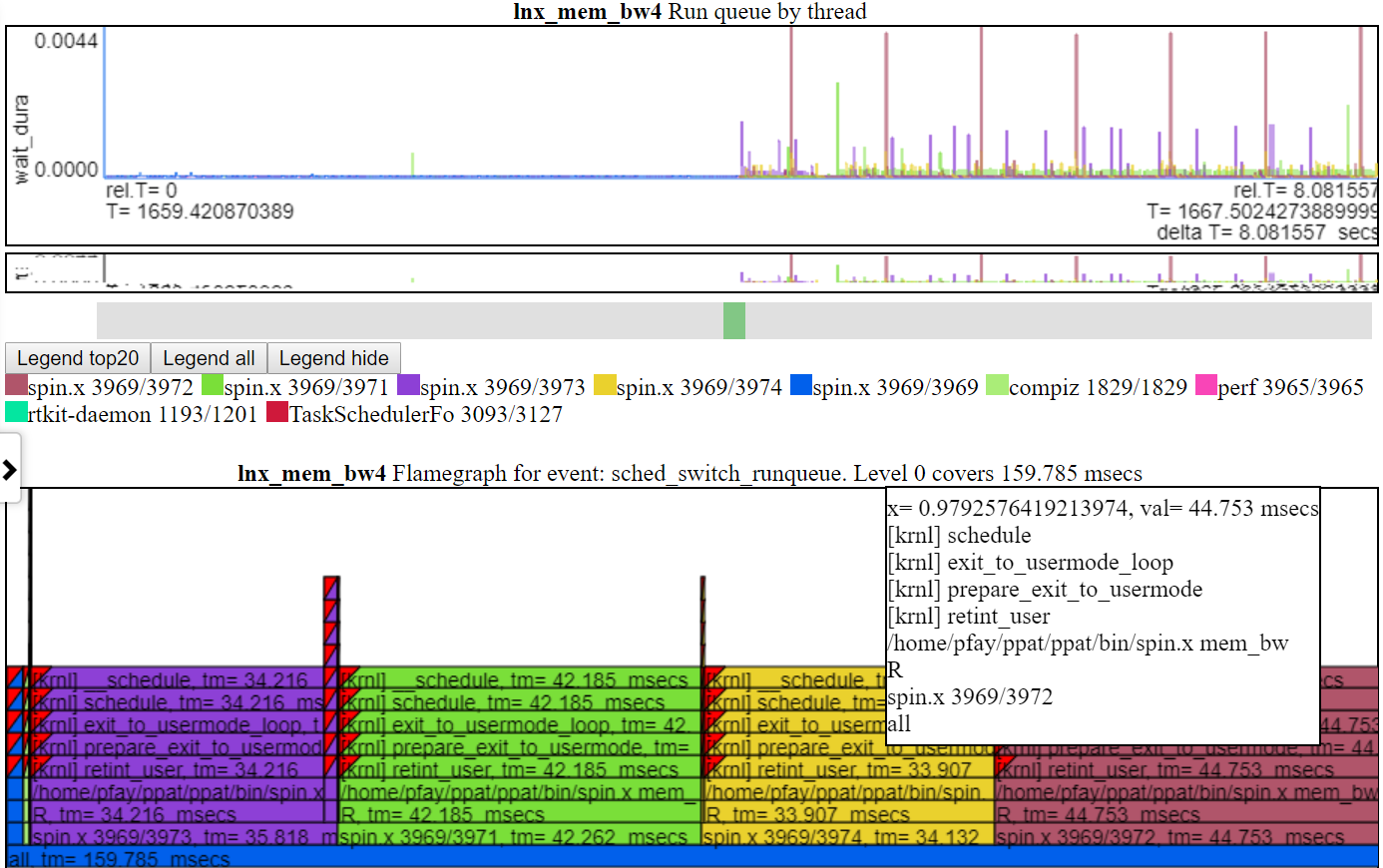
- 'Run Queue' zeigt die Threads, die ausgetauscht wurden und sich in einem laufenden oder laufbaren Zustand befanden. Dieses Diagramm zeigt also die Sättigung der CPU, wenn sich Threads in einem laufbaren Zustand, aber nicht ausgeführt haben.
- Unten finden Sie Screenshot des Run_queue -Diagramms. Dieses Diagramm zeigt die Menge, die ein Thread nicht ausgeführt hat, weil es nicht genug CPU nicht mehr gab. Das heißt, es war bereit zu rennen, aber etwas anderes benutzte die CPU. Jeder Flamgraph zeigt die Gesamtsumme im Diagramm. Im Fall des Run_queue -Diagramms werden ~ 159 ms in der Wartezeit angezeigt. Angesichts der Tatsache, dass Spin.x etwa 20 Sekunden lang Laufzeit und 0,159 Sekunden 'Wartezeit' hat, scheint das nicht schlecht zu sein.
Ich hatte keine Canvas-basierte Diagrammbibliothek zu verwenden, sodass die Diagramme irgendwie grob sind ... Ich wollte nicht zu viel Zeit damit verbringen, die Diagramme zu erstellen, wenn es etwas Besseres gibt. Die Diagramme müssen aufgrund der Datenmenge die HTML -Leinwand (nicht SVGs, D3.Js usw.) verwenden.
Datenerfassung für OPPAT
Das Sammeln der Leistungs- und Stromdaten ist sehr "situativ". Eine Person möchte Skripte ausführen, eine andere möchte mit einer Schaltfläche Messungen beginnen, dann ein Video starten und die Sammlung mit dem Drücken einer Taste beenden. Ich habe ein Skript für Windows und ein Skript für Linux, das zeigt:
- Datenerfassung, Datenerfassung,
- Ausführen einer Arbeitsbelastung,
- Datenerfassung stoppen
- Nachbearbeiten Sie die Daten (Erstellen einer Textdatei aus den Binärdaten Perf/Xperf/Trace-CMD))
- Wenn Sie alle Datendateien in eine Ausgabe einlegen
- Erstellen einer Datei von Datei_List.json in der Ausgabe -DIR (die Oppat den Namen und die Art der Ausgabedateien mitteilt)
Die Schritte für die Datenerfassung mithilfe der Skripte:
- Build Spin.exe (spin.x) und wait.exe (wait.x) Dienstprogramme
- Aus der Oppat Root Dir tun:
- unter Linux:
./mk_spin.sh - Unter Windows:
.mk_spin.bat (aus einem Visual Studio CMD -Box) - Die Binärdateien werden in den Subdir ./BIN gesteckt
- Beginnen Sie mit dem Ausführen der bereitgestellten Skripte:
- run_perf_x86_haswell.sh - Für die Datenerfassung von Haswell CPU_Diagram
- Unter Linux type:
sudo bash ./scripts/run_perf.sh - Standardmäßig wird das Skript die Daten in DIR ../OPPAT_DATA/LNX/MEM_BW7 eingerichtet
- run_perf.sh - Sie müssen Trace -CMD und Perf installiert haben
- Unter Linux type:
sudo bash ./scripts/run_perf.sh - Standardmäßig wird das Skript die Daten in DIR ../OPPAT_DATA/LNX/MEM_BW4 eingerichtet
- run_xperf.bat - Sie müssen Xperf.exe installieren lassen.
- Geben Sie unter Windows aus einem CMD -Feld mit Administratorrechten ein
.scriptsrun_xperf.sh - Standardmäßig wird das Skript die Daten in Dir .. oppat_data win mem_bw4 eingerichtet
- Bearbeiten Sie das Skript aus, wenn Sie die Standardeinstellungen ändern möchten
- Zusätzlich zu den Datendateien erstellt das Skript ausführen eine Datei von Datei_List.json in der Ausgabe -DIR. OPPAT verwendet die Datei file_list.json, um die Dateinamen und die Art der Dateien in der Ausgabe -DIR zu ermitteln.
- Die 'Workload' für das Run -Skript ist spin.x (oder spin.exe), der einen Speicherbandbreitentest auf 1 CPU für 4 Sekunden und dann für weitere 4 Sekunden auf allen CPUs durchführt.
- Ein weiteres Programm Wait.x/wait.exe wird ebenfalls im Hintergrund gestartet. Warten Sie. CPP liest die Batterieinformationen für meinen Laptop. Es funktioniert auf meinem Dual -Boot -Windows 10/Linux Ubuntu Laptop. Die SYSFS -Datei hat möglicherweise einen anderen Namen auf Ihrem Linux und ist auf Android fast sicherlich anders.
- Unter Linux können Sie wahrscheinlich nur eine prf_trace.data und prf_trace.txt -Datei mit derselben Syntax generieren wie in run_perf.sh, aber ich habe dies nicht ausprobiert.
- Wenn Sie auf einem Laptop laufen und die Batterieleistung erhalten möchten, denken Sie daran, das Stromkabel zu trennen, bevor Sie das Skript ausführen.
PCM -Datenunterstützung
- OPPAT kann PCM -.csv -Dateien lesen und zeichnen.
- Unten finden Sie eine Momentaufnahme der Liste der erstellten Diagramme.
- Leider müssen Sie einen Patch zu PCM durchführen, um eine Datei mit einem absoluten Zeitstempel für den Prozess zu erstellen.
- Dies liegt daran, dass die PCM -CSV -Datei keinen Zeitstempel hat, mit dem ich mit den anderen Datenquellen korrelieren kann.
- Ich habe den Patch hier PCM -Patch hinzugefügt
Bauen von Oppat
- Unter Linux type
make in das oppat root dir- Wenn alles funktioniert, sollte es eine bin/oppat.x -Datei geben
- Unter Windows müssen Sie:
- Installieren Sie die Windows -Version von GNU Make. Siehe http://gnuwin32.sourceforge.net/packages/make.htm oder verwenden
- Setzen Sie diesen neuen "Make" binär auf dem Weg
- Sie benötigen einen aktuellen Visual Studio 2015 oder 2017 C/C ++ - Compiler (ich habe sowohl den VS 2015 Professional als auch die VS 2017 Community Compiler verwendet)
- Starten Sie ein natives CMD -Eingabeaufforderung für das Windows Visual Studio X64
- Typ
make in der Oppat Root Dir. - Wenn alles funktioniert, sollte es eine bin oppat.exe -Datei geben
- Wenn Sie den Quellcode ändern
- Sie müssen Perl installieren lassen
- Unter Linux, im Oppat Root dir Dir do:
./mk_depends.sh . Dadurch wird eine Abhängigkeitsdatei abhängig_lnx.mk erstellt. - on Windows, in the OPPAT root dir do:
.mk_depends.bat . This will create a depends_win.mk dependency file.
- If you are going to run the sample run_perf.sh or run_xperf.bat scripts, then you need to build the spin and wait utilities:
- On Linux:
./mk_spin.sh - On Windows:
.mk_spin.bat
Running OPPAT
- Run the data collection steps above
- now you have data files in a dir (if you ran the default run_* scripts:
- on Windows ..oppat_datawinmem_bw4
- on Linux ../oppat_data/lnx/mem_bw4
- You need to add the created files to the input_filesinput_data_files.json file:
- Starting OPPAT reads all the data files and starts the web server
- on Windows to generate the haswell cpu_diagram (assuming your data dir is ..oppat_datalnxmem_bw7)
binoppat.exe -r ..oppat_datalnxmem_bw7 --cpu_diagram webhaswell_block_diagram.svg > tmp.txt
- on Windows (assuming your data dir is ..oppat_datawinmem_bw4)
binoppat.exe -r ..oppat_datawinmem_bw4 > tmp.txt
- on Linux (assuming your data dir is ../oppat_data/lnx/mem_bw4)
bin/oppat.exe -r ../oppat_data/lnx/mem_bw4 > tmp.txt
bin/oppat.exe -r ../oppat_data/lnx/mem_bw4 --web_file tst2.html > tmp.txt
- Then you can load the file into the browser with the URL address:
file:///C:/some_path/oppat/tst2.html
Derived Events
'Derived events' are new events created from 1 or more events in a data file.
- Say you want to use the ETW Win32k InputDeviceRead events to track when the user is typing or moving the mouse.
- ETW has 2 events:
- Microsoft-Windows-Win32k/InputDeviceRead/win:Start
- Microsoft-Windows-Win32k/InputDeviceRead/win:Stop
- So with the 2 above events we know when the system started reading input and we know when it stopped reading input
- But OPPAT plots just 1 event per chart (usually... the cpu_busy chart is different)
- We need a new event that marks the end of the InputDeviceRead and the duration of the event
- The derived event needs:
- a new event name (in chart.json... see for example the InputDeviceRead event)
- a LUA file and routine in src_lua subdir
- 1 or more 'used events' from which the new event is derived
- the derived events have to be in the same file
- For the InputDeviceRead example, the 2 Win32k InputDeviceRead Start/Stop events above are used.
- The 'used events' are passed to the LUA file/routine (along with the column headers for the 'used events') as the events are encountered in the input trace file
- In the InputDeviceRead lua script:
- the script records the timestamp and process/pid/tid of a 'start' event
- when the script gets a matching 'Stop' event (matching on process/pid/tid), the script computes a duration for the new event and passes it back to OPPAT
- A 'trigger event' is defined in chart.json and if the current event is the 'trigger event' then (after calling the lua script) the new event is emitted with the new data field(s) from the lua script.
- An alternate to the 'trigger event' method is to have the lua script indicate whether or not it is time to write the new event. For instance, the scr_lua/prf_CPI.lua script writes a '1' to a variable named ' EMIT ' to indicate that the new CPI event should be written.
- The new event will have:
- the name (from the chart.json evt_name field)
- The data from the trigger event (except the event name and the new fields (appended)
- I have tested this on ETW data and for perf/trace-cmd data
Using the browser GUI Interface
TBD
Defining events and charts in charts.json
TBD
Rules for input_data_files.json
- The file 'input_files/input_data_files.json' can be used to maintain a big list of all the data directories you have created.
- You can then select the directory by just specifying the file_tag like:
- bin/oppat.x -u lnx_mem_bw4 > tmp.txt # assuming there is a file_tag 'lnx_mem_bw4' in the json file.
- The big json file requires you to copy the part of the data dir's file_list.json into input_data_files.json
- in the file_list.json file you will see lines like:
{ "cur_dir" : " %root_dir%/oppat_data/win/mem_bw4 " },
{ "cur_tag" : " win_mem_bw4 " },
{ "txt_file" : " etw_trace.txt " , "tag" : " %cur_tag% " , "type" : " ETW " },
{ "txt_file" : " etw_energy2.txt " , "wait_file" : " wait.txt " , "tag" : " %cur_tag% " , "type" : " LUA " }- don't copy the lines like below from the file_list.json file:
- paste the copied lines into input_data_files.json. Pay attention to where you paste the lines. If you are pasting the lines at the top of input_data_files.json (after the
{"root_dir":"/data/ppat/"}, then you need add a ',' after the last pasted line or else JSON will complain. - for Windows data files add an entry like below to the input_filesinput_data_files.json file:
- yes, use forward slashes:
{ "root_dir" : " /data/ppat/ " },
{ "cur_dir" : " %root_dir%/oppat_data/win/mem_bw4 " },
{ "cur_tag" : " win_mem_bw4 " },
{ "txt_file" : " etw_trace.txt " , "tag" : " %cur_tag% " , "type" : " ETW " },
{ "txt_file" : " etw_energy2.txt " , "wait_file" : " wait.txt " , "tag" : " %cur_tag% " , "type" : " LUA " }- for Linux data files add an entry like below to the input_filesinput_data_files.json file:
{ "root_dir" : " /data/ppat/ " },
{ "cur_dir" : " %root_dir%/oppat_data/lnx/mem_bw4 " },
{ "cur_tag" : " lnx_mem_bw4 " },
{ "bin_file" : " prf_energy.txt " , "txt_file" : " prf_energy2.txt " , "wait_file" : " wait.txt " , "tag" : " %cur_tag% " , "type" : " LUA " },
{ "bin_file" : " prf_trace.data " , "txt_file" : " prf_trace.txt " , "tag" : " %cur_tag% " , "type" : " PERF " },
{ "bin_file" : " tc_trace.dat " , "txt_file" : " tc_trace.txt " , "tag" : " %cur_tag% " , "type" : " TRACE_CMD " },- Unfortunately you have to pay attention to proper JSON syntax (such as trailing ','s)
- Here is an explanation of the fields:
- The 'root_dir' field only needs to entered once in the json file.
- It can be overridden on the oppat cmd line line with the
-r root_dir_path option - If you use the
-r root_dir_path option it is as if you had set "root_dir":"root_dir_path" in the json file - the 'root_dir' field has to be on a line by itself.
- The cur_dir field applies to all the files after the cur_dir line (until the next cur_dir line)
- the '%root_dir% string in the cur_dir field is replaced with the current value of 'root_dir'.
- the 'cur_dir' field has to be on a line by itself.
- the 'cur_tag' field is a text string used to group the files together. The cur_tag field will be used to replace the 'tag' field on each subsequent line.
- the 'cur_tag' field has to be on a line by itself.
- For now there are four types of data files indicated by the 'type' field:
- type:PERF These are Linux perf files. OPPAT currently requires both the binary data file (the bin_file field) created by the
perf record cmd and the perf script text file (the txt_file field). - type:TRACE_CMD These are Linux trace-cmd files. OPPAT currently requires both the binary dat file (the bin_file field) created by the
trace-cmd record cmd and the trace-cmd report text file (the txt_file field). - type:ETW These are Windows ETW xperf data files. OPPAT currently requires only the text file (I can't read the binary file). The txt_file is created with
xperf ... -a dumper command. - type:LUA These files are all text files which will be read by the src_lua/test_01.lua script and converted to OPPAT data.
- the 'prf_energy.txt' file is
perf stat output with Intel RAPL energy data and memory bandwidth data. - the 'prf_energy2.txt' file is created by the wait utility and contains battery usage data in the 'perf stat' format.
- the 'wait.txt' file is created by the wait utility and shows the timestamp when the wait utility began
- Unfortunately 'perf stat' doesn't report a high resolution timestamp for the 'perf stat' start time
Einschränkungen
- The data is not reduced on the back-end so every event is sent to the browser... this can be a ton of data and overwhelm the browsers memory
- I probably should have some data reduction logic but I wanted to get feedback first
- You can clip the files to a time range:
oppat.exe -b abs_beg_time -e abs_beg_time to reduce the amout of data- This is a sort of crude mechanism right now. I just check the timestamp of the sample and discard it if the timestamp is outside the interval. If the sample has a duration it might actually have data for the selected interval...
- There are many cases where you want to see each event as opposed to averages of events.
- On my laptop (with 4 CPUs), running for 10 seconds of data collection runs fine.
- Servers with lots of CPUs or running for a long time will probably blow up OPPAT currently.
- The stacked chart can cause lots of data to be sent due to how it each event on one line is now stacked on every other line.
- Limited mechanism for a chart that needs more than 1 event on a chart...
- say for computing CPI (cycles per instruction).
- Or where you have one event that marks the 'start' of some action and another event that marks the 'end' of the action
- There is a 'derived events' logic that lets you create a new event from 1 or more other events
- See the derived event section
- The user has to supply or install the data collection software:
- on Windows xperf
- See https://docs.microsoft.com/en-us/windows-hardware/get-started/adk-install
- You don't need to install the whole ADK... the 'select the parts you want to install' will let you select just the performance tools
- on Linux perf and/or trace-cmd
sudo apt-get install linux-tools-common linux-tools-generic linux-tools- ` uname -r `
- For trace-cmd, see https://github.com/rostedt/trace-cmd
- You can do (AFAIK) everything in 'perf' as you can in 'trace-cmd' but I have found trace-cmd has little overhead... perhaps because trace-cmd only supports tracepoints whereas perf supports tracepoints, sampling, callstacks and more.
- Currently for perf and trace-cmd data, you have to give OPPAT both the binary data file and the post-processed text file.
- Having some of the data come from the binary file speeds things up and is more reliable.
- But I don't want to the symbol handling and I can't really do the post-processing of the binary data. Near as I can tell you have to be part of the kernel to do the post processing.
- OPPAT requires certain clocks and a certain syntax of 'convert to text' for perf and trace-cmd data.
- OPPAT requires clock_monotonic so that different file timestamps can be correlated.
- When converting the binary data to text (trace-cmd report or 'perf script') OPPAT needs the timestamp to be in nanoseconds.
- see scriptsrun_xperf.bat and scriptsrun_perf.sh for the required syntax
- given that there might be so many files to read (for example, run_perf.sh generates 7 input files), it is kind of a pain to add these files to the json file input_filesinput_data_files.json.
- the run_xperf.bat and run_perf.sh generate a file_list.json in the output directory.
- perf has so, so many options... I'm sure it is easy to generate some data which will break OPPAT
- The most obvious way to break OPPAT is to generate too much data (causing browser to run out of memory). I'll probably handle this case better later but for this release (v0.1.0), I just try to not generate too much data.
- For perf I've tested:
- sampling hardware events (like cycles, instructions, ref-cycles) and callstacks for same
- software events (cpu-clock) and callstacks for same
- tracepoints (sched_switch and a bunch of others) with/without callstacks
- Zooming Using touchpad scroll on Firefox seems to not work as well it works on Chrome



